In ML, attention is the mechanism that lets a model decide which pieces of information deserve focus at each step. This idea became central in modern NLP after Bahdanau attention, Luong attention, and especially the Transformer. Since then, the phrase “types of attention” has started to mean many different things. Sometimes people mean different scoring rules such as additive versus dot-product attention. Sometimes they mean different communication patterns such as self-attention versus cross-attention. In long-context models, they may instead mean sparse, local, or linearized attention.
That is why it is useful to group attention mechanisms from different points of view instead of memorizing a flat list.
If you want the detailed walkthrough of self-attention in Transformers, including queries, keys, values, scaling, masking, and multi-head attention, see Self-Attention in Transformers. This note stays focused on the taxonomy of attention mechanisms and keeps only the minimum background needed to make the categories clear.
This note organizes attention along six practical viewpoints:
- How relevance is scored.
- Which tokens or features are allowed to interact.
- How wide the receptive field is.
- How computation and memory are reduced.
- How parameters and heads are shared.
- Whether selection is soft or hard.
The goal is to help you build a clean mental map: two methods may look different in code while solving the same problem, and two methods with similar names may actually differ at a much deeper level.
1. Why attention matters
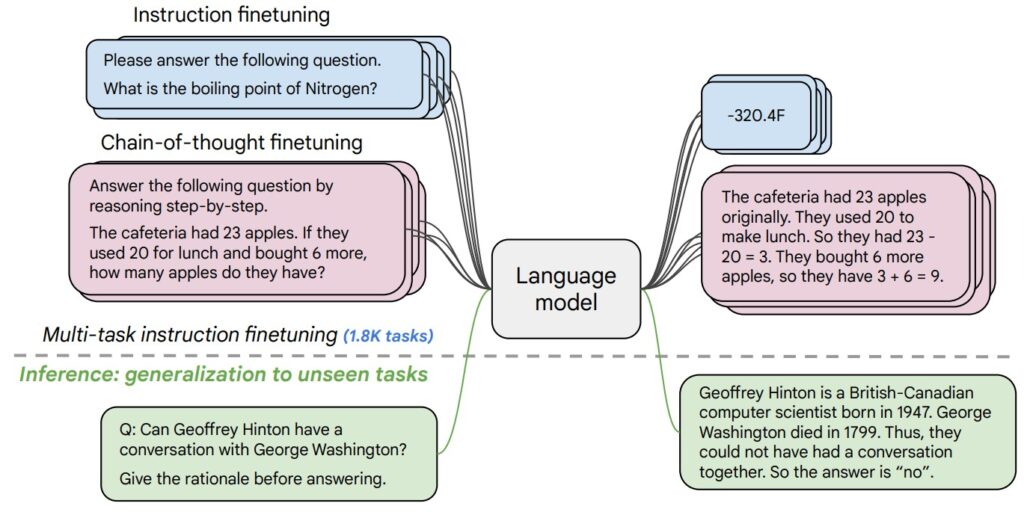
Attention matters because it replaces one-shot compression with selective retrieval. Instead of forcing a model to pack all relevant information into a single vector, it lets the current computation look back at the most relevant parts of the available context.
That shift gives three practical benefits:
- Better long-range dependency handling.
- More interpretable information flow because weights can sometimes be inspected.
- Greater flexibility, especially in encoder-decoder systems, long-context models, and multimodal architectures.
2. The common mathematical template
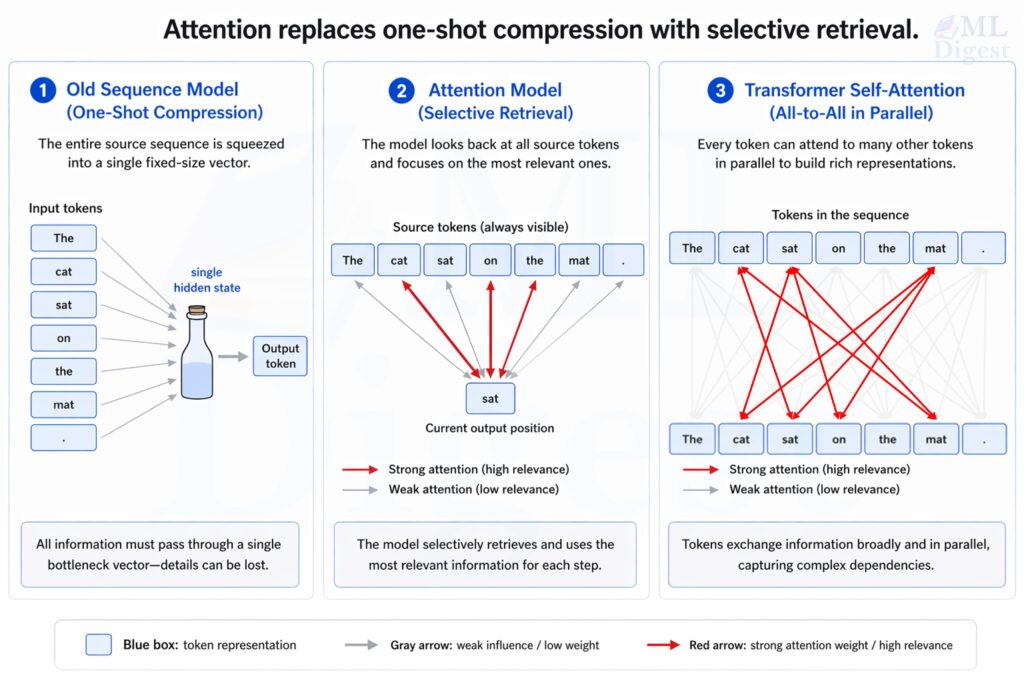
Most attention mechanisms can be understood as a weighted aggregation rule. A query asks what is relevant, keys describe what is available, and values carry the information that will actually be combined. (see details in Self-Attention in Transformers).
Given a query vector $q$, keys $k_i$, and values $v_i$, attention computes a score for each key,
$$
e_i = \text{score}(q, k_i)
$$
turns those scores into weights,
$$
\alpha_i = \frac{\exp(e_i)}{\sum_j \exp(e_j)}
$$
and then produces a weighted sum,
$$
\text{Attention}(q, K, V) = \sum_i \alpha_i v_i
$$
where $K = [k_1, \dots, k_n]$ and $V = [v_1, \dots, v_n]$.
In matrix form, the Transformer version is
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}} + M\right)V
$$
where:
- $Q$ is the query matrix.
- $K$ is the key matrix.
- $V$ is the value matrix.
- $d_k$ is the key dimension.
- $M$ is an optional mask, for example a causal mask.
This single equation already contains most of the design axes discussed later:
- The scoring function could be additive, bilinear, or dot-product.
- The normalization might be softmax, sparsemax, entmax, or something else.
- The mask decides which positions are visible.
- The structure of $Q$, $K$, and $V$ determines whether the layer is self-attention or cross-attention.
3. Grouping attention by scoring function
The first viewpoint asks a simple question: how do we measure relevance between the query and a candidate key?
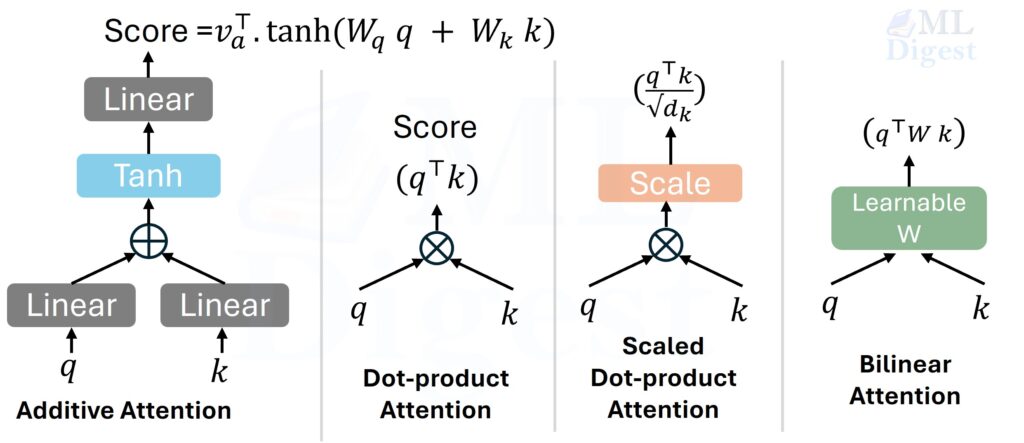
3.1 Additive attention
Additive attention (Bahdanau attention) computes relevance with a small neural network:
$$
e_i = v_a^\top \tanh(W_q q + W_k k_i)
$$
Intuition: instead of directly multiplying two vectors, the model first mixes them through learnable projections and a nonlinearity, then asks a small scorer to judge compatibility.
Why it matters:
- It was historically important in neural machine translation.
- It can work well when query and key spaces are not naturally aligned.
- It is expressive, but less hardware-friendly than simple matrix multiplication.
When it is useful:
- Encoder-decoder architectures.
- Settings where flexibility matters more than raw throughput.
Trade-off:
- More flexible scoring.
- Usually slower than pure dot-product attention on modern accelerators.
3.2 Multiplicative or dot-product attention
Luong attention and later Transformer variants popularized dot-product style scoring:
$$
e_i = q^\top k_i
$$
This is the simplest compatibility test: if the query and key point in similar directions, their dot product is large.
Why it became dominant:
- It maps naturally to fast matrix multiplication.
- It scales well on GPUs and TPUs.
- It integrates cleanly with multi-head attention.
The weakness is that large vector dimensions can make dot products grow in magnitude, which pushes softmax into saturated regions.
3.3 Scaled dot-product attention
The Transformer fixes the saturation issue by dividing by $\sqrt{d_k}$:
$$
e_i = \frac{q^\top k_i}{\sqrt{d_k}}
$$
This scaling keeps the variance of scores under better control, which stabilizes optimization.
When people say “attention” in modern NLP, they usually mean scaled dot-product attention unless stated otherwise.
3.4 Bilinear attention
Bilinear attention introduces a learnable matrix between query and key:
$$
e_i = q^\top W k_i
$$
This sits between additive and plain dot-product attention.
- More expressive than a raw dot product.
- Still fairly structured.
- Less common in mainstream large language model implementations today.
3.5 Sparse probability variants
The score function is only half the story. The normalization step also changes behavior.
With sparsemax or entmax, some attention weights can become exactly zero. This can make the distribution sharper and sometimes more interpretable than softmax.
Why this matters:
- Softmax always assigns some positive mass to every visible token.
- Sparse alternatives can force real selection.
- They are useful when you want a few clear sources instead of a dense blur of small weights.
3.6 Position-biased scoring
The raw dot-product score can also be shifted by a position-dependent bias before the softmax step. ALiBi (Attention with Linear Biases) is a notable example: instead of learning positional embeddings, it adds a fixed linear penalty proportional to the relative distance between tokens. This naturally biases each token toward its neighbors and often improves generalization to longer sequences than those seen during training.
4. Grouping attention by what attends to what
The second viewpoint asks: where do the queries come from, and where do the keys and values come from?
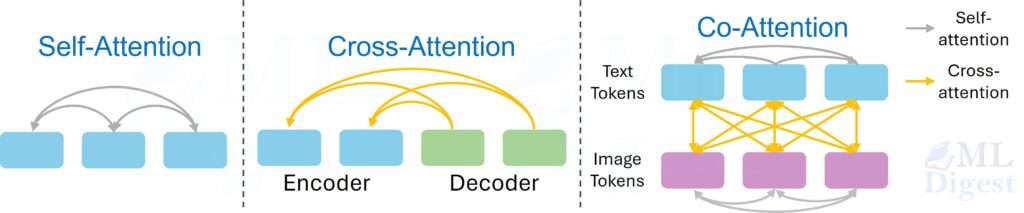
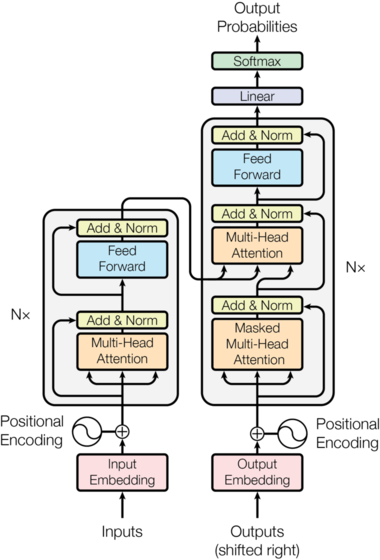
4.1 Self-attention
In self-attention, queries, keys, and values all come from the same sequence.
$$
Q = XW_Q, \quad K = XW_K, \quad V = XW_V
$$
Each token can inspect other tokens in the same input.
Examples:
- Bidirectional encoders (like BERT) use self-attention to mix information across the whole sentence.
- Decoder-only models (like GPT) use masked self-attention so that a token can only look left.
- Encoder-decoder models (like T5) use self-attention in both the encoder and decoder, with cross-attention from the decoder to the encoder.
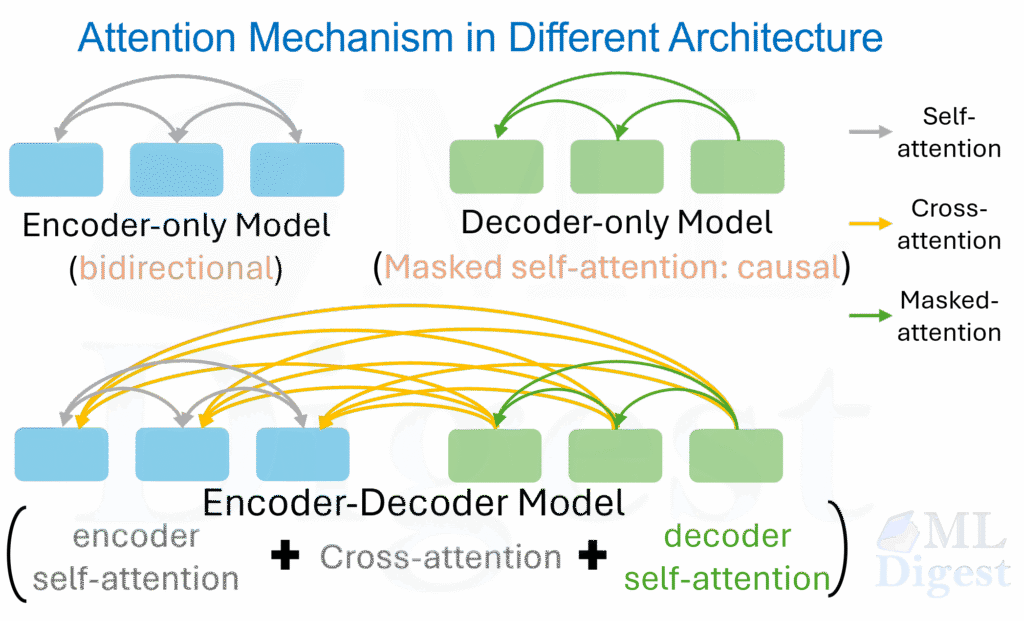
4.2 Cross-attention
In cross-attention, the query comes from one sequence and keys and values come from another:
$$
Q = XW_Q, \quad K = YW_K, \quad V = YW_V
$$
In encoder-decoder architectures, the query $(Q)$ typically comes from the decoder, while the keys $(K)$ and values $(V)$ come from the encoder.
This is how a decoder consults an encoded source sentence in machine translation, or how a text decoder consults image features in multimodal systems.
Examples:
- Encoder-decoder Transformers.
- Vision-language models, including multi-modal Transformers that combine image and text representations.
- Retrieval-augmented generation systems where a query representation attends over retrieved document embeddings.
4.3 Co-attention and multimodal attention
Some architectures let two modalities attend to each other repeatedly. For example, text features may attend to image patches while image patches also attend back to text features. This is often described as co-attention or bidirectional cross-attention. The key idea is symmetric interaction across modalities.
In most common co-attention, each modality has self-attention within itself and cross-attention to the other modality.
So you will often see something like:
- Text : self-attention + cross-attend to image
- Image : self-attention + cross-attend to text
Different papers implement co-attention differently:
- Cross-attention only (minimal co-attention)
- One modality attends to the other (or both do), without explicit self-attention layers
- Internal structure may already be encoded beforehand (e.g., via CNN or pretrained encoder)
- Asymmetric co-attention
- Only one modality attends to the other
- Example: text queries attending to image features, but not vice versa
- Fused attention variants
- Some models mix modalities early and run a single shared attention instead of separate self + cross steps
5. Grouping attention by visibility pattern and receptive field
Now the question becomes: even if a token could attend to others in principle, which positions are actually visible?
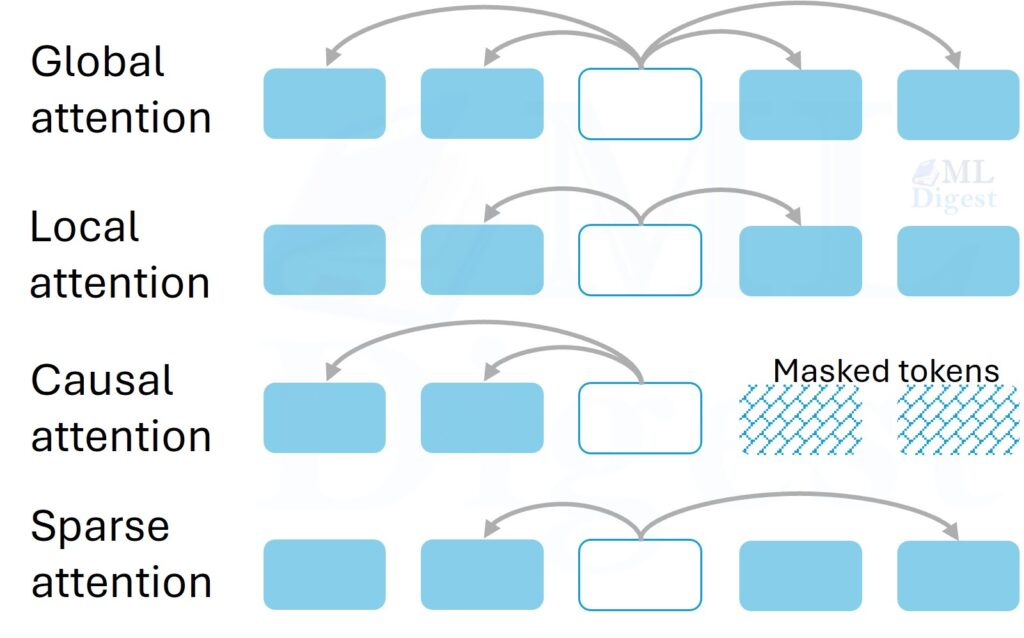
5.1 Global attention
In global attention, every query can attend to every key that is not masked.
This is the standard full attention pattern. Its strength is flexibility. Its weakness is the $O(n^2)$ score matrix for sequence length $n$.
Use it when:
- Sequences are moderate in length.
- You need unrestricted pairwise interaction.
- Accuracy matters more than efficiency.
5.2 Causal or masked attention
Causal attention is the same full attention pattern with a mask that blocks future tokens.
$$
M_{ij} =
\begin{cases}
0 & \text{if } j \le i \\
-\infty & \text{if } j > i
\end{cases}
$$
This is essential for autoregressive language modeling because token $i$ must not read future tokens during training.
5.3 Local or windowed attention
Local attention restricts each token to a neighborhood, for example the previous $w$ and next $w$ tokens, or only the previous $w$ tokens in a decoder.
Intuition: when reading a paragraph, nearby words often matter most.
Benefits:
- Lower computational and memory cost.
- Strong inductive bias for locality.
Risk:
- Distant dependencies can be lost unless the model has enough layers or additional global routes.
5.4 Block attention
Block attention partitions the sequence into contiguous chunks and applies attention at the block level instead of across every token pair.
There are two common meanings in practice:
- Block-sparse attention, where tokens attend densely within a block and only to selected neighboring or global blocks.
- Blockwise processing, where computation is tiled into chunks for better memory behavior even if the underlying attention remains exact.
The first meaning changes the visibility graph. The second meaning changes the implementation. It is worth separating them because papers and libraries sometimes use the same phrase for both.
Why block attention is useful:
- It gives a structured compromise between full attention and narrow local windows.
- It maps well to accelerator-friendly tiled computation.
- It can preserve medium-range context better than a tiny sliding window.
5.5 Sliding-window and other sparse attention patterns
Long-context models often use carefully designed sparse patterns. Examples include Longformer and BigBird.
Common sparse patterns:
- Sliding-window attention: each token sees a nearby window.
- Global tokens: a small set of special tokens see everything and are visible to all.
- Dilated attention: tokens skip positions with a stride, which widens coverage without full density.
- Random sparse links: used to create shortcuts between distant regions.
The core design idea is to keep important information paths while avoiding the full quadratic interaction graph.
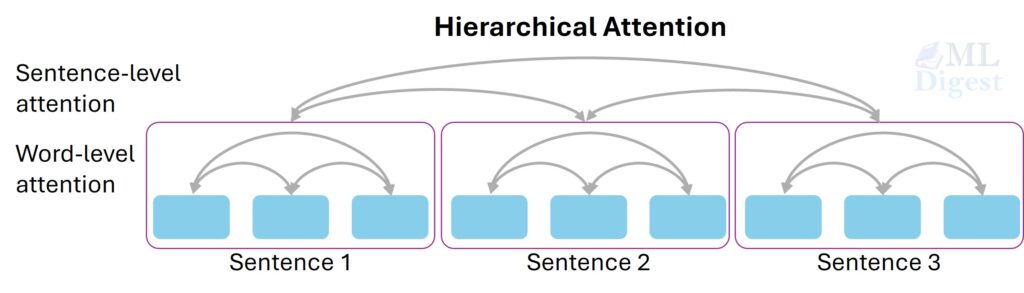
5.6 Hierarchical attention
Hierarchical attention aggregates information in stages, for example from words to sentences and then from sentences to documents.
This is useful when the data itself has a nested structure. Instead of attending globally at the finest level all the time, the model summarizes locally and then reasons at a higher level.
6. Grouping attention by efficiency strategy
This viewpoint is especially important in long-context models. Two methods may both be called “attention”, but one changes the semantics while another changes only the implementation.
6.1 Exact but hardware-aware attention
FlashAttention is a good example of a method that keeps exact attention but changes how it is computed.
Important distinction:
- It does not change the mathematical function of scaled dot-product attention.
- It changes the IO pattern and kernel fusion so that memory traffic is reduced.
This means FlashAttention is best understood as an implementation optimization, not a new semantic type of attention.
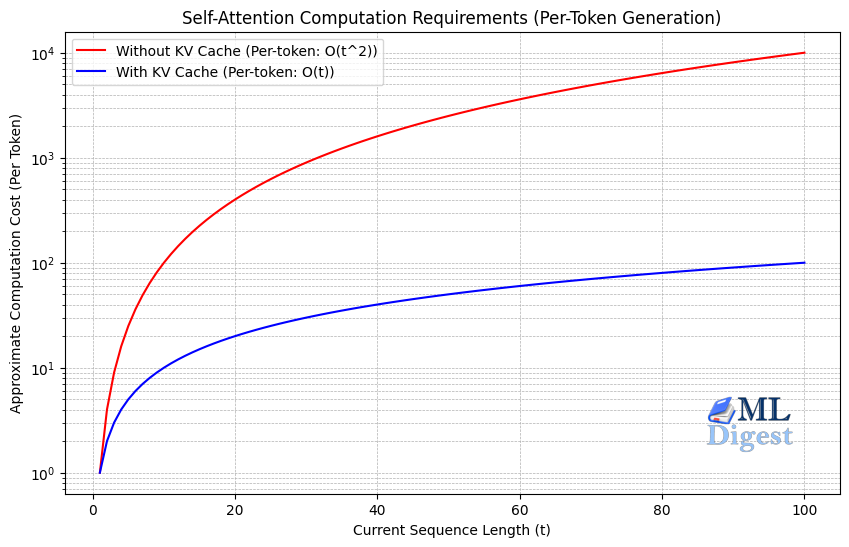
6.2 Paged attention
PagedAttention is another implementation-oriented idea, popularized by vLLM. It reorganizes the KV cache into fixed-size blocks, then uses a page-table-like indirection layer so generated tokens do not require one large contiguous memory region.
Why this matters:
- It reduces memory fragmentation during LLM serving.
- It makes batching requests with different sequence lengths easier.
- It improves serving efficiency without redefining the attention score itself.
The right mental model is similar to virtual memory in operating systems. The model still performs the same causal attention computation, but the runtime stores and retrieves KV states more efficiently.
6.3 Low-rank and projection-based approximations
Linformer reduces cost by projecting the sequence dimension before computing full interactions.
Idea:
- The full attention matrix may have exploitable low-rank structure.
- If that approximation is good enough, memory and compute decrease.
Trade-off:
- Faster and lighter.
- Approximation quality depends on the task and context length.
6.4 Kernelized or linear attention
Performer approximates softmax attention using kernel feature maps so that the computation can be reorganized into a form that scales roughly linearly with sequence length.
High-level intuition: instead of explicitly comparing every query to every key, the model summarizes keys and values through a kernel trick that allows cheaper accumulation.
Use this family when:
- Sequence length is very large.
- Exact full attention is too expensive.
Be careful:
- Linear in theory does not automatically mean better in wall-clock time.
- Approximation error and implementation overhead matter.
6.5 Hashing and routing-based attention
Reformer uses locality-sensitive hashing to group similar tokens, reducing the number of pairwise comparisons.
This is a routing idea: instead of everyone talking to everyone, similar participants are placed at the same table first.
6.6 Memory-compressed and recurrent variants
Some long-context methods compress previous context into memory slots, summaries, or recurrence states rather than allowing unrestricted full attention. The trade-off is usually a mix of better scalability and more constrained information access.
Practical lesson: ask whether a method is exact, approximate, sparse, or just kernel-optimized. Those are not interchangeable claims.
7. Grouping attention by head and parameter-sharing design
The next viewpoint asks how many separate attention subspaces the model uses and how much parameter sharing happens across them.
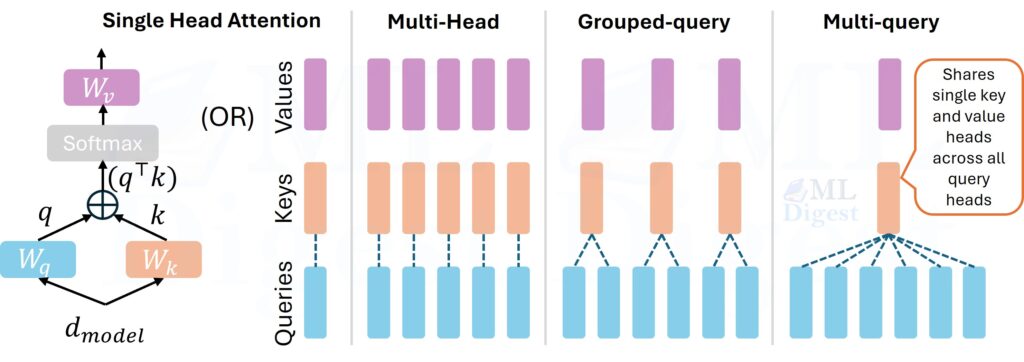
7.1 Single-head attention
Single-head attention computes one relevance pattern. It is easier to understand, but limited because the model has only one interaction subspace at a time.
7.2 Multi-head attention
Multi-head attention splits attention into several parallel heads:
$$
\text{head}_h = \text{Attention}(QW_Q^{(h)}, KW_K^{(h)}, VW_V^{(h)})
$$
$$
\text{MHA}(Q,K,V) = \text{Concat}(\text{head}_1, \dots, \text{head}_H)W_O
$$
Intuition: instead of forcing one conversation channel, the model runs multiple smaller conversations in parallel.
Why it matters in this taxonomy:
- Different heads can specialize.
- The model can represent several relation types at once.
- It is the baseline that later variants such as multi-query and grouped-query attention modify.
7.3 Multi-query attention
Multi-query attention keeps separate query projections per head but shares keys and values across heads.
Why people use it:
- Reduces KV-cache size during decoding.
- Improves inference efficiency for large language models.
The trade-off is that fewer distinct key-value subspaces are available.
7.4 Grouped-query attention
Grouped-query attention is a compromise between full multi-head attention and multi-query attention.
- Several query heads share one key-value group.
- This keeps some diversity while reducing memory bandwidth and cache size.
This design is now common in production language models because it balances quality and inference cost well.
8. Grouping attention by decision style
So far, attention has been a soft weighted average. But not all attention mechanisms behave that way.
8.1 Soft attention
Soft attention produces differentiable weights over all visible candidates. It is the standard choice because it trains well with gradient descent.
8.2 Hard attention
Hard attention selects one or a small number of positions discretely. Instead of averaging over all candidates, it commits to a selection.
Benefits:
- Clear selection behavior.
- Potential efficiency gains.
Costs:
- Harder optimization because selection is discrete.
- Often needs reinforcement learning, relaxations, or special estimators.
8.3 Monotonic attention
Monotonic attention is important in streaming tasks such as online speech recognition. It enforces a left-to-right alignment, which matches the structure of the problem.
This is a good reminder that the best attention mechanism often reflects the geometry of the data and the deployment setting.
9. Attention beyond text-only Transformers
Although the core idea is shared, the dimension along which attention operates can change.
9.1 Spatial attention
In vision models, attention may operate over image patches or spatial locations. Vision Transformer (ViT), for example, treats an image as a sequence of fixed-size non-overlapping patches and applies standard self-attention across them. A query at one patch asks which other patches matter.
9.2 Channel attention
Squeeze-and-Excitation Networks and CBAM use attention-like gating across channels, asking which feature maps should be emphasized.
9.3 Axial attention
Axial attention decomposes high-dimensional attention across axes, for example attending along image height first and width second, which reduces cost compared with full 2D attention.
The reason to mention these in an NLP note is conceptual: “type of attention” can refer not only to the scoring rule but also to the axis of interaction.
10. A compact taxonomy table
The same model can belong to several categories at once. For example, a decoder block in a modern LLM usually uses scaled dot-product, masked self-attention, multi-head or grouped-query parameterization, and an optimized kernel such as FlashAttention.
| Viewpoint | Question | Common types | Main trade-off |
|---|---|---|---|
| Scoring | How is relevance computed? | Additive, dot-product, scaled dot-product, bilinear | Flexibility vs throughput |
| Source of Q, K, V | Who attends to whom? | Self-attention, cross-attention, co-attention | Internal mixing vs external retrieval |
| Visibility | Which positions are visible? | Global, causal, local, block, sparse, hierarchical | Context coverage vs cost |
| Efficiency | How is cost reduced? | FlashAttention, PagedAttention, Linformer, Performer, Reformer, sparse patterns | Exactness vs approximation vs implementation complexity |
| Head design | How are subspaces shared? | Single-head, multi-head, multi-query, grouped-query | Expressivity vs memory and inference speed |
| Decision style | Dense or selective? | Soft, hard, monotonic, sparse normalization | Trainability vs selectivity |
11. How to choose the right attention mechanism
There is no single best variant. The correct choice depends on what bottleneck dominates.
- If you are building a standard NLP model:
Start with scaled dot-product multi-head attention. It is the strongest default because:- It is well understood.
- Tooling is mature.
- It maps cleanly to modern accelerators.
- If your problem is autoregressive generation:
Use causal self-attention. If inference cost becomes the bottleneck, consider grouped-query or multi-query attention to reduce KV-cache pressure. - If context length is the bottleneck:
Decide first what kind of compromise you are willing to make:- No semantic approximation, only faster kernels: use FlashAttention.
- Serving-time KV-cache pressure and fragmentation: consider PagedAttention-style runtimes.
- Structured sparsity: use local or sparse patterns.
- Approximation for lower complexity: explore Linformer, Performer, or Reformer style methods.
- If the task is cross-modal or encoder-decoder:
Cross-attention is usually non-negotiable because one representation must query another. - If interpretability and sharp selection matter:
Experiment with sparse normalization or hard-attention-inspired designs, but validate whether the sharper distribution actually improves the target metric.
12. Common mistakes and best practices
- Do not mix up semantic changes and kernel optimizations:
FlashAttention and PagedAttention speed up exact attention system behavior. They are not the same kind of change as sparse attention or linear attention. - Do not assume all heads learn distinct patterns:
Multi-head attention can specialize, but some heads become redundant. Inspecting attention maps can be useful, but do not treat head diversity as guaranteed. - Do not equate attention weights with full explanation:
Attention weights can be informative, but they are not a complete explanation of model behavior. Downstream nonlinearities and residual pathways also matter. - Match the attention pattern to deployment constraints:
For training, your bottleneck may be activation memory. For inference, it may be KV-cache bandwidth. For streaming, causality and monotonicity may matter more than raw expressivity. - Start simple, then optimize the actual bottleneck:
In practice, a strong baseline often looks like this:- Scaled dot-product attention.
- Multi-head or grouped-query design.
- Causal masking for decoder models.
- FlashAttention-style kernels if supported.
Only move to more exotic sparse or approximate methods when the measured bottleneck justifies the additional complexity.
Concluding Thoughts
The phrase “attention mechanism” is overloaded because it mixes several independent design axes.
When you encounter a new paper or codebase, ask these questions in order:
- What is the scoring rule?
- Is it self-attention or cross-attention?
- What positions are visible?
- Is it exact, sparse, approximate, or only kernel-optimized?
- How are heads and key-value projections shared?
Once you ask those five questions, most attention variants become easier to place on the map.
That is the real skill. You do not need to memorize a long list of names. You need a clean taxonomy that tells you what changed, why it changed, and what trade-off it introduces.
This note is intentionally taxonomy-first. If you want the detailed mechanics of self-attention, masking, and multi-head computation inside a Transformer block, read Self-Attention in Transformers.
If you want production implementations, use tested libraries such as PyTorch, Hugging Face Transformers, xFormers, or the flash-attn project.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!