A production agentic AI system is like a well-run restaurant: success depends not on a single chef or dish, but on a carefully layered system (specialized stations, defined workflows, safety rules, and supply-chain management all working in concert). Remove any one layer and the kitchen struggles to function.
There is no single thing called “the agent.” There is an ecosystem of components, each with a defined role, and the quality of the whole depends on how well those layers are designed, integrated, governed, and operated together.
This article maps that ecosystem as a systems-engineering problem (covering agent reasoning patterns, the tooling and protocol layer, orchestration, the framework landscape, memory and context management, safety and governance, and production deployment). For the fundamentals, see AI Agents and Agentic Systems, Single-Agent Systems, and Multi-Agent Systems. For agent skills specifically, see Agent Skills.
1. The Building Blocks: A Layered Vocabulary
Before diving into architecture, it is worth drawing crisp lines between the most overloaded terms in this field. A kitchen analogy helps set the stage precisely.
Imagine a high-end restaurant. The head chef reads the order ticket, decides what to cook, and delegates to specialized stations. Each station (the sauté, the grill, the pastry corner) is a tool with a narrow, deterministic capability. The learned techniques a station follows (what temperature to use, when to flip, how to plate) are skills. The ticket rail is the standard protocol that any cook from any kitchen can understand without rewriting the ordering system. The recipe sequence is the workflow. The pre-measured mise en place is the data pipeline. And the physical layout and management system of the kitchen is the framework.
This maps directly to the vocabulary of agentic AI:
| Restaurant Component | Agentic AI Concept |
|---|---|
| Head chef and assistant chefs | AI Agents |
| Kitchen station | Tool |
| Learned technique | Skill |
| Ticket rail standard | MCP (Model Context Protocol) |
| Recipe sequence | Workflow |
| Mise en place | Data Pipeline |
| Kitchen layout and management | Agent Framework |
The sections that follow cover each layer in detail, starting from how individual agents reason and escalating to how ecosystems of agents are built and operated.
1.1 AI Agents
An AI agent is a software entity that perceives its environment, decides on actions, and executes those actions in a loop until a goal is reached. The distinguishing feature is the loop itself: unlike a plain LLM that completes a single forward pass, an agent runs multiple passes, updating its context with new observations at each step.
For a full treatment of agent fundamentals, the Observe–Think–Act control loop, and the taxonomy of agent types (reflex, model-based, goal-based, utility-based, learning), see AI Agents and Agentic Systems.
1.2 Agent Skills
Agent Skills are portable packages of instructions, scripts, and supporting resources that teach an agent how to perform a specific class of tasks. The key engineering principle is progressive disclosure: the agent loads only a lightweight skill catalog (name and description) at session start and loads the full instructions only when it determines a skill is relevant.
That distinction matters because teams often use “skill” to mean three different things: a model capability learned during training, a fine-tuned behavior, or a reusable runtime package of guidance. In this article, skills mean the third category: explicit, inspectable artifacts that shape how the agent performs a task at runtime. They are more like playbooks than weights.
For a deep guide to skills (how to author them, how to structure SKILL.md, how to evaluate them, and how to integrate them in VS Code), see Agent Skills.
2. Agent Architecture Patterns
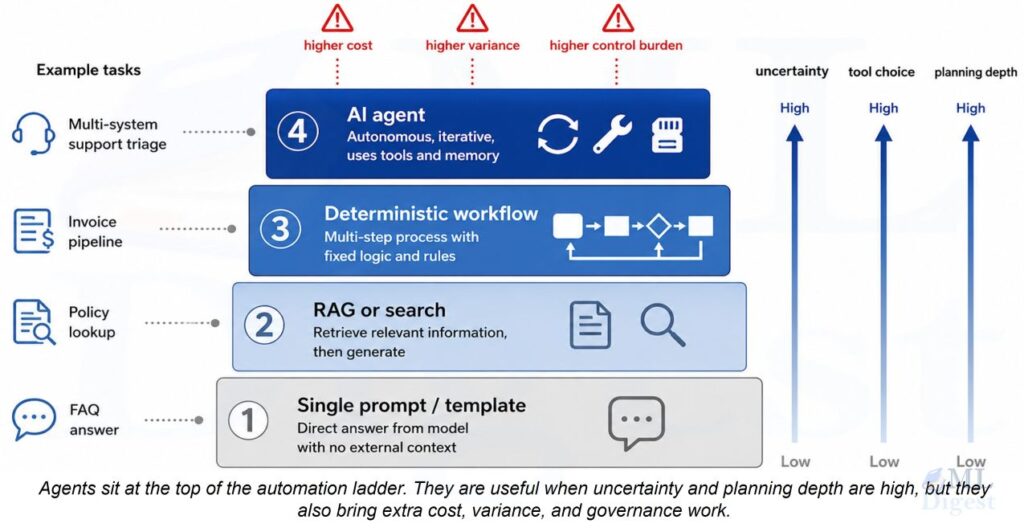
Architecture is the set of decisions that determine how an agent or a group of agents reasons and coordinates. The right pattern depends on task complexity, the cost of errors, whether the step sequence can be predicted in advance, and how important explainability is. In practice, architecture choice is mostly about where you want adaptivity and where you want constraint. The more expensive deviation is, the more of the system should be expressed as deterministic structure rather than free-form agent behavior.

2.1 Single-Agent Patterns
When a task can be handled by one agent, the choice of pattern determines how the agent reasons, plans, and recovers from errors. The five primary patterns and when to use each are summarized below. For in-depth treatment of each pattern (including implementation examples, trace walkthroughs, and failure modes), see Single-Agent Architecture Patterns.
| Pattern | Core idea | Best when |
|---|---|---|
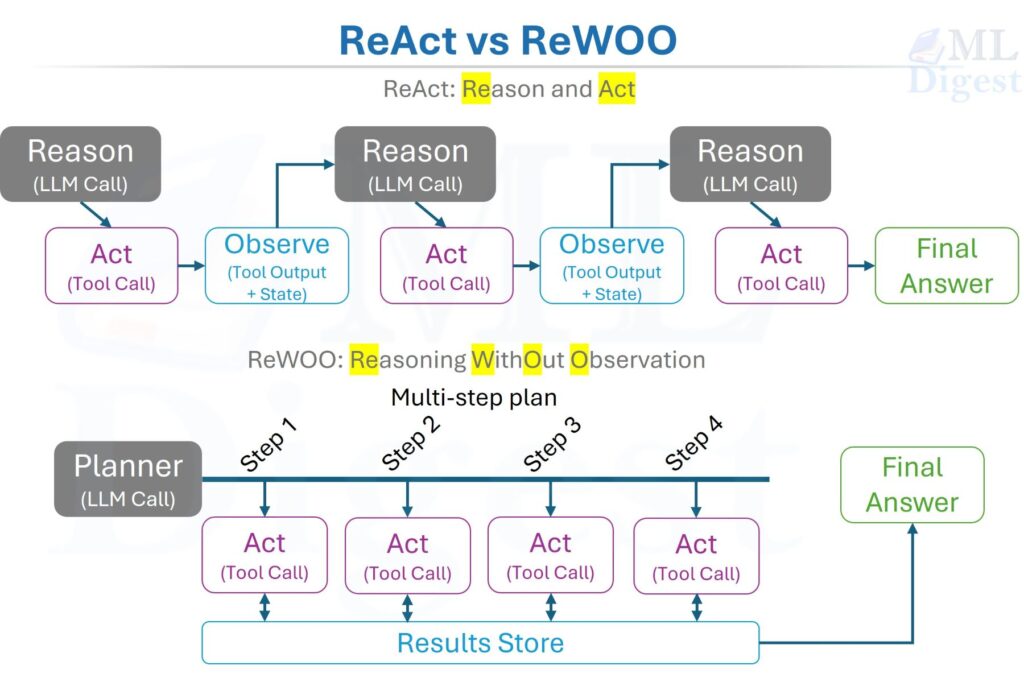
| ReAct | Interleaves reasoning traces with tool actions in a continuous Reason → Act → Observe loop. | Open-ended tasks where required steps are not known in advance. |
| Plan-then-Execute (ReWOO) | Generates a complete step plan in one LLM call, then executes each step sequentially. | Stable, well-understood environments where minimizing LLM calls matters. |
| Tree of Thought | Explores multiple reasoning branches in parallel; a scoring function prunes and selects the best path. | Tasks with deceptive dead ends (debugging, math reasoning, strategic planning) where beam-search-style exploration helps. |
| Reflection and Self-Critique | The agent evaluates its own output and iteratively revises using a second LLM call before finalizing. | Any output task where iterative self-correction improves quality without needing an independent reviewer. |
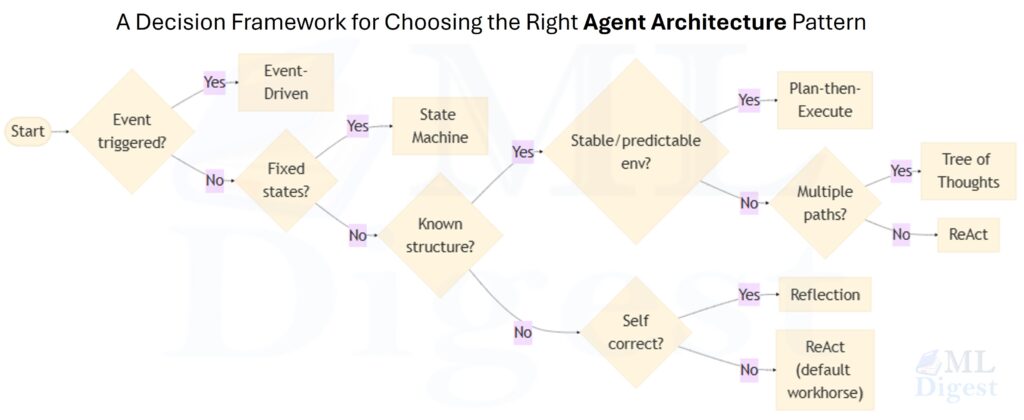
| Event-Driven / State Machine | Agent activates on discrete events (queue message, webhook, schedule); or execution is constrained to an explicit FSM with defined state transitions. | Continuous monitoring pipelines and multi-stage workflows requiring auditability and independent scalability. |
The single-agent patterns differ primarily in how much structure is imposed upfront. ReAct is maximally adaptive; Plan-then-Execute is maximally efficient for known tasks; Tree of Thought spends more compute to avoid local optima; Reflection adds a self-correction pass; and State Machine agents trade flexibility for predictability and explainability.
2.2 Multi-Agent Patterns
For tasks that are too large, too risky, or too ambiguous for a single agent to handle reliably, multi-agent systems (MAS) distribute the problem across specialized agents. Think of moving from a one-person workshop to an assembly line with a control tower: some agents build, some check quality, some plan, and a coordinator keeps the whole process on track.
The six primary patterns and when to use each are summarized below. For in-depth treatment of each pattern (including implementation pseudocode, communication protocols, memory types, coordination strategies, and MARL training considerations), see Multi-Agent Systems.
| Pattern | Core idea | Best when |
|---|---|---|
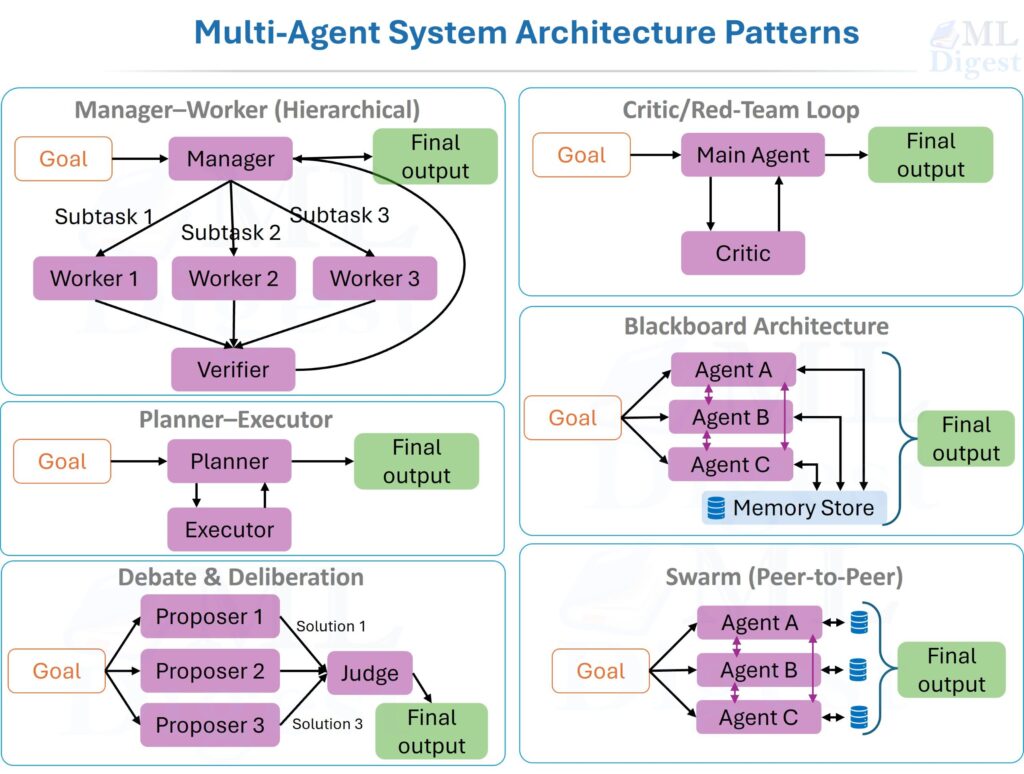
| Manager–Worker (Hierarchical) | A manager decomposes the task; specialized workers execute; a verifier checks outputs. | Tasks decompose into orthogonal roles with clear interfaces. |
| Planner–Executor | The planner generates a full step plan before execution begins; the executor follows it. | Stable, well-understood environments where planning drift is a risk. |
| Debate and Deliberation | Multiple proposer agents generate independent solutions; a judge synthesizes. | Problems with multiple plausible answers; surfaces overconfidence and hidden assumptions. |
| Critic / Red-Team Loop | A main agent generates; a critic finds failures; the main agent revises. | Any output where independent quality verification is higher-value than prompt tuning. |
| Blackboard Architecture | Agents post partial results to a shared store; others read and extend asynchronously. | Knowledge-intensive tasks where information accumulates incrementally from heterogeneous sources. |
| Swarm (Peer-to-Peer) | No central manager; global behavior emerges from local agent interactions. | Exploration and coverage tasks; harder to control and cost-manage than hierarchical patterns. |
A practical sizing rule: start with the smallest viable team of three (planner, executor, verifier), and add agent roles only when benchmarks demonstrate a concrete bottleneck. MAS multiplies both capability and coordination overhead; the cost is only justified when specialization or independent verification demonstrably improves outcomes.
2.3 Formal Grounding: From MDPs to Dec-POMDPs
The mathematical substrate of MAS helps clarify three design-level questions: what each agent can observe, whether objectives are shared or conflicting, and how to attribute success or failure (credit assignment) when multiple agents collaborate.
The hierarchy of formal models is:
- MDP (single agent, fully observable): $\mathcal{M} = (\mathcal{S}, \mathcal{A}, P, R, \gamma)$, policy optimizes $J(\pi) = \mathbb{E}{\pi}[\sum{t} \gamma^t R(s_t, a_t)]$.
- POMDP (single agent, partially observable): adds observation space $\Omega$ and observation model $O(o \mid s, a)$; the agent acts on a belief state $b(s)$ rather than the true state.
- Stochastic Markov game ($N$ agents, each with its own reward $R_i$): joint action $\mathbf{a} = (a_1, \ldots, a_N)$ drives shared transitions.
- Dec-POMDP (cooperative, partially observable, decentralized): each agent acts on local observations only; optimal joint planning is NEXP-complete, which is why production systems rely on structured approximations such as hierarchical decomposition, role constraints, and shared-state coordination.
3. The Tooling and Integration Layer
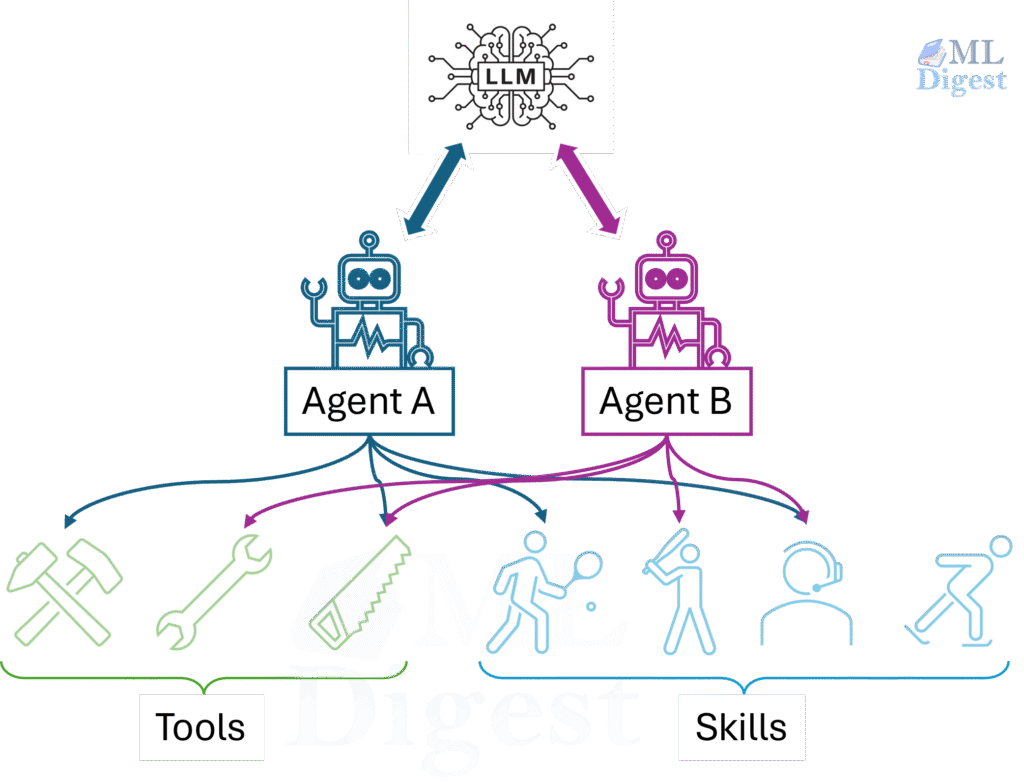
Tools are the agent’s connection to the outside world. Without tools, an agent is a powerful text generator: it can reason, plan, and write, but it cannot query live data, execute code, or cause any effect in an external system.
3.1 Function Calling: How Agents Touch the World
The dominant pattern for equipping an LLM with tools is function calling (also called tool use). The developer provides a JSON schema describing each callable function; the LLM decides mid-generation to emit a structured tool call instead of continuing with free text. The agent runtime intercepts the call, executes the real function, and injects the result back into the model’s context. For a practical API-level overview, see the OpenAI function calling guide.
A tool schema for a document search function:
{
"name": "search_documents",
"description": "Semantic search over the internal knowledge base. Use when the user needs facts, figures, or information from company documents.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query in natural language"
},
"top_k": {
"type": "integer",
"description": "Number of documents to return (default: 5)"
}
},
"required": ["query"]
}
}A critical design principle: the model never directly executes the tool. It emits a structured intent, and the runtime handles execution. This separation is the enforcement point for sandboxing, permissioning, and auditing (which are covered in the safety section).
The minimal agent loop implementing function calling:
import json
from openai import OpenAI
client = OpenAI()
def search_documents(query: str, top_k: int = 5) -> list[dict]:
# In production, this calls a real semantic search index or vector DB
return [{"id": "doc_01", "text": f"Relevant content for: {query}", "score": 0.92}]
TOOLS = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Semantic search over internal knowledge base.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"top_k": {"type": "integer", "default": 5}
},
"required": ["query"]
}
}
}
]
TOOL_REGISTRY = {"search_documents": search_documents}
def run_agent(user_message: str, max_steps: int = 10) -> str:
messages = [{"role": "user", "content": user_message}]
for _ in range(max_steps):
response = client.chat.completions.create(
model="gpt-4o", messages=messages, tools=TOOLS
)
choice = response.choices[0]
# Final answer: the model decided no more tools are needed
if choice.finish_reason == "stop":
return choice.message.content
# Execute the requested tool call
tool_call = choice.message.tool_calls[0]
function_name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
# Security boundary: verify the tool exists before running it
if function_name not in TOOL_REGISTRY:
raise ValueError(f"Unknown tool requested: {function_name}")
result = TOOL_REGISTRY[function_name](**args)
# Inject the tool result back into the conversation
messages.append(choice.message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result)
})
return "Budget exhausted: max steps reached without a final answer."Notice max_steps. This is not optional in production. Without an iteration budget, a failing tool or a confused model can spin indefinitely, consuming tokens and incurring cost without making progress.
3.2 MCP: The Universal Protocol
The central integration problem in multi-agent systems is combinatorial. If you have $N$ agent applications and $M$ tool providers (GitHub, Postgres, a web browser, a code interpreter, Slack), every agent needs a custom integration for every provider. That is $O(N \times M)$ integrations to build and maintain.
Model Context Protocol (MCP), introduced publicly by Anthropic in late 2024, addresses this. MCP is an open JSON-RPC standard that defines how any LLM application (the client) discovers, connects to, and uses capabilities provided by MCP servers. The integration surface collapses to $O(N + M)$: build each agent as a generic MCP client once, build each capability as an MCP server once, and they interoperate. The canonical specification lives at modelcontextprotocol.io.
It is important to be precise about what MCP does and does not standardize. MCP standardizes capability discovery, invocation, and context exchange. It does not automatically solve authorization, trust boundaries, tenancy, business policy, or output validation. Those remain application responsibilities, which is why the safety and governance sections later in this article still matter even in an MCP-native architecture.
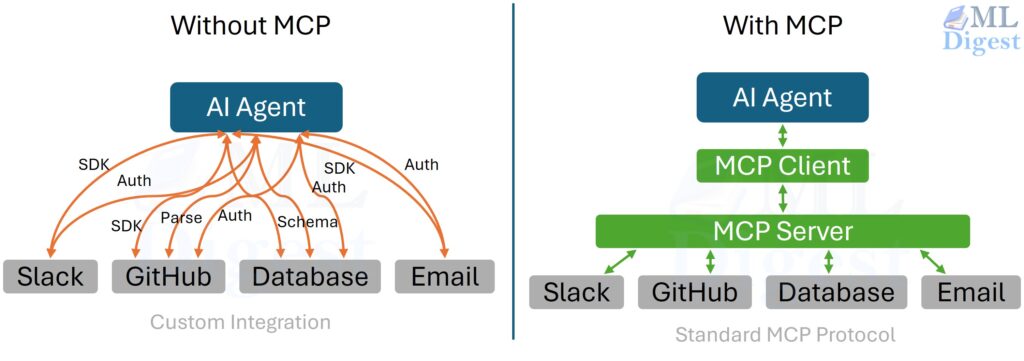
An MCP server can expose three categories of capability:
- Tools: callable functions like
read_file,create_issue,run_query - Resources: readable data sources such as file contents, database rows, API responses
- Prompts: reusable prompt templates the server pre-defines for common tasks
The practical implication: build a library of MCP servers once (GitHub, Slack, Postgres, a web browser, a code interpreter) and reuse every server across every agent, regardless of the underlying LLM provider or agent framework. This is the same composability principle that made Unix pipes powerful.
3.3 Designing Good Tools
Tool design is an underestimated engineering discipline. Poorly designed tools are a primary source of agent failures that are invisible in the LLM’s reasoning trace (the model thinks it succeeded, but the tool returned garbage).
Write descriptions as routing signals. The model selects tools based on their descriptions, not their names. The description "Search the web" is ambiguous. The description "Search the web for real-time news, current events, live prices, or any information that postdates the model's training cutoff. Do not use for questions answerable from internal documents." gives the model an explicit routing rule and a boundary condition.
Design tools to be narrow and idempotent. A tool that does one thing and has no side effects from being called twice is far safer to use in an agent loop than a tool that writes to a database. Separate read tools from write tools; require explicit confirmation for irreversible operations.
Return structured outputs. A tool returning "The search found 3 results about the topic." as a raw string is harder for the agent to parse reliably than a JSON object with results, total_count, and source_url fields.
Fail loudly. A tool that silently returns an empty list when a query fails causes the agent to proceed as though the search succeeded. Explicit error codes and human-readable error messages allow the agent to detect failures, adjust its approach, and avoid hallucinating data it never actually retrieved.
3.4 Knowledge Graphs as a Structured Retrieval Alternative
Vector databases are the most common retrieval backend for agent knowledge, but they are not the only option. For tasks that require relational reasoning, they are often not the best one. Knowledge graphs store information as typed entities connected by explicit, named relationships rather than dense vector embeddings.
Consider the question: “Which engineers who joined after 2022 have worked on products used by healthcare customers?” A vector similarity search struggles here because the answer requires traversing relationships across three entity types (engineers, products, customers) through a structured graph. A Cypher or SPARQL query over a properly maintained knowledge graph handles this in a single hop.
| Retrieval Backend | Best for |
|---|---|
| Vector database | Semantic similarity, open-ended text search, fuzzy matching over unstructured text |
| Knowledge graph | Structured entity lookups, multi-hop relationship traversal, constraint-driven queries |
| Hybrid | Most enterprise deployments: vector search for unstructured documents, graph for entity relationships |
In a hybrid system, the agent holds two retrieval tools: search_documents backed by a vector store and query_knowledge_graph backed by a graph database. The tool descriptions specify which is appropriate for which category of question, and the agent selects accordingly based on the nature of the query.
4. Workflows and Orchestration
An agent’s ability to adapt is a strength and a liability simultaneously. For tasks where the sequence of steps is known in advance and deviation is costly, you do not want the agent improvising. You want a workflow.
4.1 The Workflow vs. the Free Agent
The critical distinction is who controls the sequence:
| Dimension | Free Agent | Workflow |
|---|---|---|
| Sequence control | LLM decides at runtime | Developer defines upfront |
| Flexibility | High (adapts to surprises) | Low (follows the graph) |
| Predictability | Lower (non-deterministic paths) | Higher (auditable and testable) |
| Best use case | Open ended research, exploration | Repeated, well defined processes |
Many production systems are deliberately hybrid: a workflow orchestrates the high-level steps, and an agent handles each step that requires genuine judgment. Think of a clinical trial protocol: the steps are fixed (consent, dosing, observation, reporting), but a clinician interprets each observation. The fixed steps are the workflow; the interpretation is the agent.
The design principle: use deterministic logic for control flow decisions; use the LLM only for content generation at specific nodes.
Another way to phrase the rule is: if you can enumerate the branches ahead of time, you probably want a workflow. If you cannot enumerate them because the task genuinely requires exploration, then you want an agent. Many unstable systems come from using an agent where a DAG would have been simpler and safer.
4.2 Workflows as Directed Acyclic Graphs
A workflow is naturally modeled as a Directed Acyclic Graph (DAG). Each node is a step (which may delegate to an agent or call a tool directly); edges represent dependencies and control flow.
%%{init: {'themeVariables': { 'fontSize': '42px'}}}%%
flowchart LR
A([User <br>Research <br>Query]) --> B[Query <br>Rewriter <br>Agent]
B --> C[Retrieve <br>Documents]
C --> D[LLM <br>Synthesize <br>Answer]
D --> E{Factuality <br>Verifier}
E -- Pass --> F([Return <br>Answer to User])
E -- Fail --> G[Retrieve <br>More Documents]
G --> H[LLM <br>Retry]The [Factuality Verifier] node introduces a deterministic branch. The workflow handles both outcomes explicitly, rather than passively hoping the LLM will self-correct. This is the key pattern: encode reliability into the graph structure, not into prompts.
A LangGraph implementation of this workflow:
from langgraph.graph import StateGraph, END
from typing import TypedDict
class WorkflowState(TypedDict):
query: str
documents: list[str]
answer: str
verification_passed: bool
attempts: int
def rewrite_query(state: WorkflowState) -> WorkflowState:
improved_query = query_rewriter_llm.invoke(state["query"])
return {**state, "query": improved_query}
def retrieve_documents(state: WorkflowState) -> WorkflowState:
docs = vector_store.search(state["query"], top_k=5)
return {**state, "documents": docs}
def synthesize_answer(state: WorkflowState) -> WorkflowState:
answer = synthesis_llm.invoke(state["query"], context=state["documents"])
return {**state, "answer": answer, "attempts": state["attempts"] + 1}
def verify_answer(state: WorkflowState) -> WorkflowState:
passed = factuality_checker.check(state["answer"], state["documents"])
return {**state, "verification_passed": passed}
def route_after_verification(state: WorkflowState) -> str:
if state["verification_passed"]:
return "done"
if state["attempts"] >= 3:
return "done" # Enforce a retry budget
return "retry"
graph = StateGraph(WorkflowState)
graph.add_node("rewrite", rewrite_query)
graph.add_node("retrieve", retrieve_documents)
graph.add_node("synthesize", synthesize_answer)
graph.add_node("verify", verify_answer)
graph.set_entry_point("rewrite")
graph.add_edge("rewrite", "retrieve")
graph.add_edge("retrieve", "synthesize")
graph.add_edge("synthesize", "verify")
graph.add_conditional_edges(
"verify",
route_after_verification,
{"done": END, "retry": "retrieve"}
)
app = graph.compile()
result = app.invoke({"query": "What were the key findings?", "attempts": 0})This code is worth studying for a structural reason: the branching logic (route_after_verification) is a plain Python function, not a prompt. The LLM generates the content; the Python function controls the flow. This separation is what makes the workflow auditable and testable.
4.3 Pipelines: The Data-Centric Cousin of Workflows
A pipeline is primarily about data transformation: moving data through processing stages where each stage modifies or enriches data. A workflow is about task orchestration: coordinating steps that may involve branching, human interaction, retries, and external events. The two concepts are complementary rather than competing.
| Dimension | Pipeline | Workflow |
|---|---|---|
| Focus | Data transformation | Task orchestration |
| Decision-making | Minimal or none | Includes branching logic |
| State | Data flowing through stages | Task state, message history, tool results |
| Debugging approach | Inspect data at each stage | Inspect task state and control flow |
| Metaphor | Assembly line | Project management plan |
The most important pipeline in the agentic context is the RAG pipeline (Retrieval-Augmented Generation), which converts raw documents into agent-ready context. The foundational paper is Lewis et al., 2020.
The pipeline does not make decisions; it prepares context. The agent then uses that context to reason and act.
4.4 Streaming Workflows and Schedulers
Streaming workflows process data continuously as it arrives, rather than waiting to accumulate a full batch before processing. In agentic systems, streaming matters in two distinct ways.
The first is token-level streaming: the agent emits reasoning and response tokens to the user as they are generated, rather than waiting for the full response to complete. This dramatically improves perceived latency for long-form outputs and is supported natively by most modern LLM APIs and agent frameworks via server-sent events or websocket streams.
The second is event-stream orchestration: agent stages are connected through a real-time event stream rather than file writes or batch polling. Each stage processes an event, emits one or more downstream events, and terminates; the next stage activates as soon as the event arrives. Apache Kafka, AWS Kinesis, and Pulsar are common event backbones for this topology. The benefit is that end-to-end latency is bounded by the processing time of each individual stage rather than by batch accumulation delays across the entire pipeline.
Schedulers add a temporal dimension to agent orchestration. Rather than running in response to user requests, scheduled agents execute on a fixed cadence: hourly anomaly detection sweeps, daily data quality summaries, weekly compliance review reports. Production-grade schedulers (Apache Airflow, Prefect, Temporal) provide dependency-aware execution, retry logic with SLA monitoring, backfill capabilities for historical runs, and a visualization interface for workflow state across runs. The typical integration pattern is: the scheduler triggers the entry point of a workflow DAG on a time-based schedule, while the nodes inside the DAG remain genuine agent steps that adapt their behavior based on the data they encounter at each execution.
5. The Agent Framework Ecosystem
Building an agent from scratch means solving message-history management, tool-call parsing, retry logic, observability hooks, and context propagation before you can begin on the actual task logic. Agent frameworks solve this boilerplate. They provide abstractions for agents, tools, memory, and prompts, along with orchestration primitives and observability integrations.
5.1 General-Purpose Orchestration
LangChain is the most widely deployed general-purpose framework. It provides chains, agents, memory modules, and a large library of pre-built integrations with LLM providers, vector stores, and external APIs. Its strength is breadth; its weakness is that multiple layers of abstraction can make debugging difficult when something behaves unexpectedly.
LlamaIndex is retrieval-first: it excels at data ingestion, RAG pipeline construction, and turning diverse data sources into agent-ready context. It has expanded to support full agents and workflows but remains strongest at the data layer.
Haystack (by deepset) is production-oriented with a pipeline-first design. It has strong ML tooling integration and is a natural choice when a system mixes classical NLP components with LLM-based agents.
Semantic Kernel (Microsoft) is a framework designed for enterprise AI applications with first-class support for function calling, prompt templating, and multi-step plan execution. It follows a “kernel and plugins” model: the kernel manages LLM invocations and memory, while plugins are the callable tool and skill units. It provides native support for C#, Python, and Java, and integrates closely with the Azure AI and Azure OpenAI ecosystem. It is a natural choice for organizations standardized on Microsoft infrastructure.
5.2 Multi-Agent Coordination
AutoGen (Microsoft) is conversation-first and multi-agent by design. Agents exchange natural-language messages; the framework handles routing, turn-taking, and termination conditions. It is well-suited for systems where agents debate proposals, critique each other’s outputs, or collaborate on a shared artifact through conversation.
CrewAI uses a role-based model where each agent has a defined role, goal, and explicit tool set. It is opinionated but ergonomic for building team-style systems (researcher + writer + editor) where the separation of responsibilities is clear upfront.
LangGraph models agent execution as a state machine on a directed graph. Every node is a function that transforms state; edges define transitions, including conditional routing. It is the best choice when you need deterministic control flow with LLM-driven content generation at specific nodes (the pattern demonstrated in the workflow example above).
5.3 Model-Native and Lightweight
OpenAI Agents SDK is a lightweight SDK that makes function calling and agent handoffs first-class without adding significant abstraction overhead. It stays close to the raw API surface, which is useful when you want full control over behavior with minimal hidden complexity.
Strands Agents (AWS) is tool-use focused and designed to integrate naturally with AWS infrastructure (Bedrock, Lambda, DynamoDB). It is the natural choice for teams already operating within the AWS ecosystem.
5.4 Choosing a Framework
The question is not which framework is best in the abstract, but which framework is best fitted to this task at this stage.
Task is highly structured? → LangGraph or Haystack
Multiple agents must collaborate? → AutoGen or CrewAI
Retrieval is the core need? → LlamaIndex
Broad integrations needed? → LangChain
Minimal abstraction desired? → OpenAI Agents SDK
AWS infrastructure? → Strands Agents
Azure infrastructure? → Semantic KernelOne practical rule applies universally: start with the simplest framework that gives reliable tool calling, state management, and observability. Change only when you encounter a concrete, measured bottleneck. The maintenance burden of a custom agent runtime is routinely underestimated by teams building their first production system.
Another practical rule is to keep your business logic one layer below the framework wherever possible. If prompt templates, state schemas, and tool contracts are deeply entangled with one framework’s proprietary abstractions, migration becomes expensive. Frameworks should reduce boilerplate, not become the place where your product logic is trapped.
A concrete example of what a framework abstracts: without a framework, implementing one tool call and feeding the result back into the conversation requires 15–20 lines of message-management code. With LangGraph:
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
@tool
def search_documents(query: str) -> str:
"""Search internal knowledge base for facts and figures."""
return f"Top result for '{query}': Revenue FY2025 was $4.2B."
llm = ChatOpenAI(model="gpt-4o")
# The framework handles the tool-call loop, message management,
# state tracking, and termination condition automatically.
agent = create_react_agent(llm, tools=[search_documents])
result = agent.invoke({"messages": [("user", "What was the revenue in FY2025?")]})
print(result["messages"][-1].content)The developer provides the tools and the model. The framework handles everything else.
5.5 Prompt Engineering and Template Systems
Every agent framework provides a mechanism for storing, parameterizing, and composing prompts (variously called prompt templates, prompt registries, or prompt catalogs). These serve the same role as function signatures in software: they capture reusable invocation patterns and separate the stable structure of a prompt from the dynamic values injected at runtime.
A parameterized extraction prompt in LangChain:
from langchain_core.prompts import ChatPromptTemplate
extraction_prompt = ChatPromptTemplate.from_messages([
("system", "You are an expert data extractor. Return only valid JSON."),
("human",
"Extract the following fields from the text:\n"
"Fields: {fields}\n\n"
"Text: {input_text}")
])
# At runtime, fill in the dynamic values
filled = extraction_prompt.format_messages(
fields="name, date, amount, currency",
input_text="Invoice from Acme Corp dated March 2025 for $1,450 USD."
)Beyond templates, prompt engineering covers the design of system instructions, few-shot examples, chain-of-thought scaffolding, and output format specifications that shape agent behavior. The core discipline principle is that prompts are code: they should be version-controlled, benchmarked against evaluation cases, and modified in response to measured performance regressions rather than intuition alone. In production, a prompt regression in a high-traffic agent is as damaging as a code regression, and harder to detect without a dedicated evaluation harness tied to a representative test suite.
6. Data and Context Management
An agent is only as good as the information available to it at each reasoning step. Managing what goes into the context window, when it arrives, and how long it persists is one of the most consequential engineering decisions in an agentic system.
6.1 The Three Memory Layers
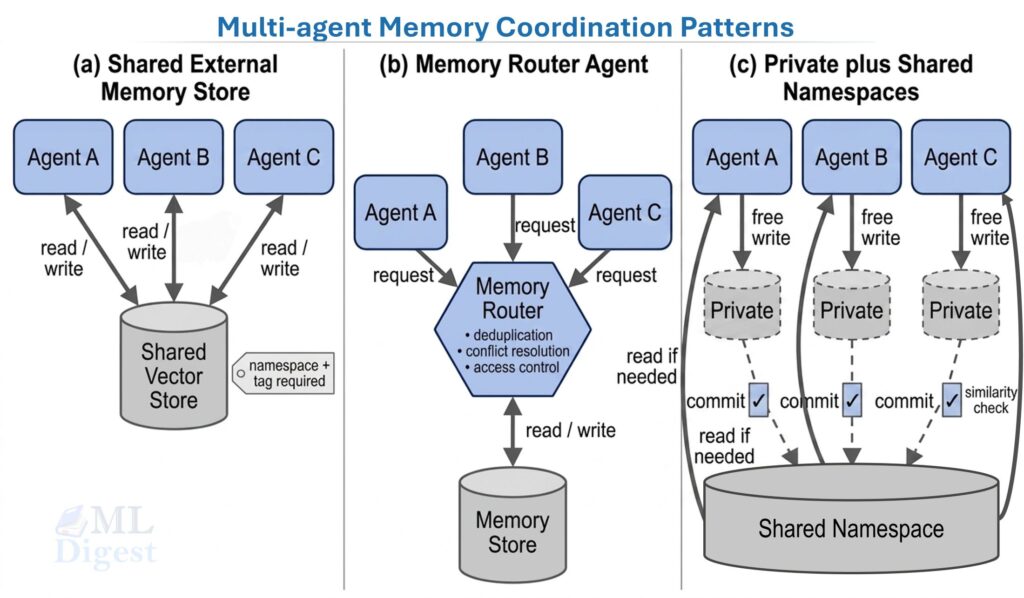
The practical memory stack is simpler than the terminology makes it sound:
flowchart TB
A[Short-term<br>context window] <--> B[Episodic<br>past runs and events]
A <--> C[Semantic<br>facts and documents]| Layer | Typical contents | Lifetime | Main failure mode |
|---|---|---|---|
| Short-term | Current conversation, tool outputs, scratch state | Session | Overflow |
| Episodic | Past runs, decisions, traces | Cross-session | Stale or irrelevant recall |
| Semantic | Documents, facts, knowledge base | Persistent | Retrieval miss or stale source data |
The engineering point is that each layer needs a different control policy: context management for short-term memory, recency-aware retrieval for episodic memory, and RAG quality work for semantic memory.
Session management bridges short-term and episodic memory. A session is the bounded execution context for one user interaction, which may span multiple conversation turns or agent steps. Managing session state means deciding: what to persist when a session ends (for later retrieval as episodic memory), what to discard, and what context to restore at the start of a subsequent session with the same user. In multi-user deployments, session state must be strictly isolated per user to prevent cross-session context leakage, and session stores must handle concurrent access without data races.
For the full architecture, retrieval math, and implementation patterns, see Memory in Agentic Systems.
6.2 Context Window Economics
Treat the context window as a scarce budget, not a dumping ground.
flowchart TD
A[System instructions] --> E[Context window]
B["Skill context <br>(SKILL.md)"] --> E
C[Task state] --> E
D[Retrieved context] --> E| Zone | What belongs there | Control rule |
|---|---|---|
| System instructions | Role, policies, safety rules | Keep small and stable |
| Skill context | Only the active workflow or skill | Load on demand |
| Task state | Recent conversation and tool results | Summarize as it grows |
| Retrieved context | External facts, docs, code | Retrieve only when needed |
| Compression tactic | Why it helps |
|---|---|
| Summarization | Preserves older state in compact form |
| Retrieval gating | Prevents unused documents from filling the window |
| Context pruning | Removes raw outputs after their conclusions are captured |
For a detailed treatment of memory paging and long-context management, see Memory in Agentic Systems.
6.3 RAG Pipeline Design
For agents, the RAG layer must be repeatable because both the user and the agent itself may issue retrieval queries during the same task.
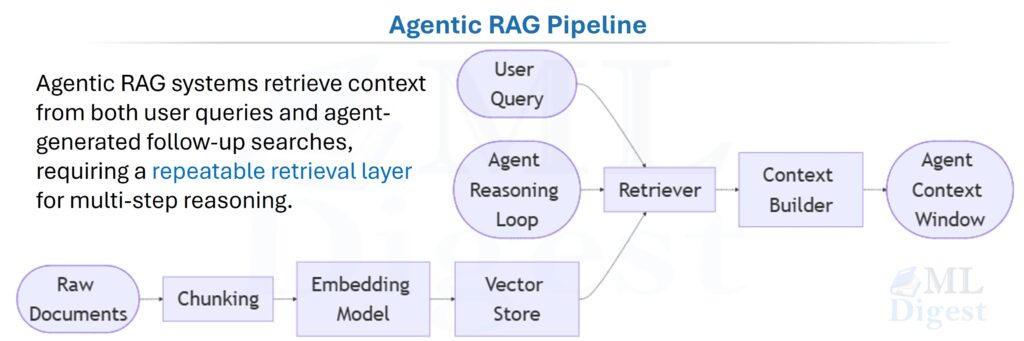

(Agentic RAG Pipeline: Agentic RAG systems retrieve context from both user queries and agent-generated follow-up searches, requiring a repeatable retrieval layer for multi-step reasoning.)
In production agentic RAG systems, queries originate from both sources: the initial user request enters the pipeline, and the agent itself generates additional retrieval queries as it reasons through multi-step tasks. The agent may refine search terms, retrieve follow-up information based on intermediate results, or disambiguate incomplete initial queries (all without returning to the user). This dual-source pattern is why the retrieval layer must be declarative and repeatable: the agent may call the same retriever multiple times with different queries within a single reasoning trace.
| Design choice | Good default | Why it matters |
|---|---|---|
| Chunking | Structure-aware when possible; overlap when needed | Preserves coherent evidence |
| Embeddings | Domain-matched model | Usually the biggest quality lever |
| Retrieval | Bi-encoder first pass + reranker | Balances speed and precision |
| Filtering | Metadata constraints before final selection | Prevents semantically similar but wrong-era or wrong-source results |
| If this goes wrong | Typical symptom |
|---|---|
| Poor chunking | Relevant fact split across chunks |
| Weak embeddings | Top results are on-topic but not answer-bearing |
| No reranking | Correct passage retrieved but ranked too low |
| No metadata filters | Outdated or wrong-scope source wins |
For the full retrieval architecture, math, prompt design, and code walk-through, see Retrieval-Augmented Generation (RAG).
Knowledge graph based RAG (KG-RAG) often helps with with global reasoning and multi-hop relationship traversal. Follow this post for additional info.
7. Safety, Control, and Governance
This section is intentionally short because the full treatment lives in Safety, Control, and Governance of Agentic Systems (Coming soon). Use this section as the ecosystem-level summary and the linked article for the detailed risk model, implementation patterns, and rollout guidance.
7.1 The Core Distinction
In agentic systems, the problem is no longer only whether the model says something wrong. The system can now call tools, change state, and trigger real-world side effects. That shifts the design target from safe text generation to safe closed-loop operation.
| Layer | Core question | Typical mechanism |
|---|---|---|
| Safety | Does the system avoid harmful actions and outcomes? | Risk scoring, action gating, evaluation suites, prompt-injection defense |
| Control | Can operators shape, pause, or override behavior reliably? | Allowlists, approvals, budgets, sandboxing, kill switches |
| Governance | Can the organization prove the system is operated responsibly? | Policies, ownership, audit logs, incident playbooks, review records |
7.2 Main Risks and Default Controls
| Risk category | Typical failure | Default control response |
|---|---|---|
| Tool misuse | Wrong tool, wrong arguments, wrong sequence | Narrow tool schemas, precondition checks, allowlists |
| Scope creep | Agent does more than the user intended | Explicit task scope, approval thresholds, operator-visible plans |
| Data exfiltration | Sensitive content leaves the trusted boundary | Least-privilege credentials, output filters, egress controls |
| Prompt injection | Retrieved content overrides system intent | Trust-segmented memory, content sanitization, execution-time validation |
| Uncontrolled side effects | Irreversible actions happen without review | Reversibility tiers, human approval, rollback planning |
| Tool tier | Example | Default enforcement |
|---|---|---|
| Read-only | Search, retrieval, file read, API GET | Allow; log for audit |
| Reversible write | Create draft, update metadata, create ticket | Allow with monitoring and traceability |
| Irreversible | Send email, push to production, delete record, refund money | Require approval or block by policy |
7.3 What Good Runtime Control Looks Like
| Design choice | Why it matters |
|---|---|
| Least-privilege tool access | Reduces blast radius when the agent is wrong |
| Allowlists over blocklists | Makes unknown actions fail closed rather than slip through |
| Structured actions | Makes policy checks inspectable before execution |
| Budget ceilings | Prevents runaway loops, excessive spend, and denial-of-service behavior |
| Human-in-the-loop on high-impact actions | Inserts a hard stop before irreversible side effects |
| Sandboxed execution | Contains code-generation and tool failures inside an isolated boundary |
| Trust-segmented memory | Prevents retrieved content from quietly becoming operational authority |
The implementation rule is simple: the model may propose, but the runtime decides. If the model can directly exercise broad authority, the control boundary is already broken.
7.4 Governance and Evaluation Checklist
| Area | Minimum production artifact |
|---|---|
| Ownership | Named owner for policy, tools, and incident response |
| Policy | Written statement of allowed, review-required, and forbidden actions |
| Evidence | Versioned prompt, model, tool schema, and policy records |
| Monitoring | Complete traces of prompts, tool calls, outputs, and control decisions |
| Response | Incident taxonomy, escalation path, and kill-switch procedure |
| Review | Periodic red-team tests and policy refresh cycle |
| Metric family | Example metric |
|---|---|
| Safety | Unsafe action rate, prompt-injection success rate |
| Control | Approval recall, kill-switch latency, budget overrun rate |
| Governance | Trace completeness, reproducibility rate, policy freshness |
For the formal risk framing, prompt-injection defenses, uncertainty handling, reversibility design, and rollout stages, read Safety, Control, and Governance of Agentic Systems.
8. Infrastructure and Deployment
The difference between a demonstration agent and a production agent is largely an infrastructure question: observability, reliability, and cost control at scale. This article keeps that layer intentionally brief. For the full treatment of architecture, latency and throughput math, Kubernetes deployment, queues, storage, and observability patterns, read Infrastructure and Deployment of Agentic Systems (Coming soon).
flowchart LR
A["Operations Plane<br/>(traces, metrics, <br/>budgets, alerts)"] -.observes.-> B["Control Plane<br/>(API, workflow, <br/>scheduler, policy)"]
A -.observes.-> C["Data Plane<br/>(models, tools, retrieval, memory, storage)"]
B --> C(A useful mental model: keep orchestration, execution, and operations as separate concerns
even when they share the same runtime.)
8.1 Observability: Tracing Agent Behavior
Standard application monitoring is necessary but insufficient for agents. Production systems need queryable traces that reconstruct a full run across model calls, tool steps, retries, and verification.
| Operational question | Trace fields that must exist |
|---|---|
| Which prompt version caused this failure? | Run ID, prompt/template version, model version, active system context |
| Which tool call preceded the bad output? | Tool name, normalized arguments, result payload, latency, retry count |
| Why did the cost jump after a change? | Prompt tokens, completion tokens, per-step cost, per-run budget status |
| Can we reproduce the incident? | Ordered state transitions, retrieved context, final output, verifier result |
Tools like LangSmith, Arize Phoenix, Weights and Biases Weave, and OpenTelemetry exporters are useful because they make this run history inspectable rather than leaving it scattered across logs.
8.2 Production Hardening
The easiest production failures are also the most preventable.
| Control | Why it matters in agent loops |
|---|---|
| Idempotency | Safe retries prevent duplicate side effects when a worker or tool fails |
| Timeouts + backoff | External dependencies fail slowly unless the runtime enforces deadlines |
| Circuit breakers | Persistent downstream failure should stop traffic instead of amplifying it |
| Progress tracking | A loop that changes nothing should replan or fail rather than spend tokens forever |
| Hard budgets | Token, tool-call, and dollar ceilings must be enforced in code, not only dashboards |
8.3 Scaling Agentic Systems
Scaling adds coordination cost, so the runtime should be explicit about what is stateless, what is durable, and what is budget-constrained.
| Scaling concern | Production default |
|---|---|
| Horizontal execution | Stateless workers operating on an explicit task state object |
| Reliability across restarts | Durable queues with at-least-once delivery plus idempotent tools |
| Long-running tasks | Asynchronous orchestration with persisted checkpoints |
| Spend control | Per-user, per-team, and per-run quotas with caching where responses are stable |
8.4 Deployment Topologies
Production systems usually land in one of these topology families.
| Topology | Best fit | Main trade-off |
|---|---|---|
| Serverless | Spiky, event-triggered, short-lived tasks | Tight execution limits and externalized state |
| Queue + workers | Long-running, stateful, or retry-heavy tasks | Higher operational complexity and latency |
| Edge inference | Low-latency or offline workloads | Smaller models and stricter task scoping |
| GPU/TPU serving | High concurrent traffic and throughput-sensitive systems | Highest operational complexity and cost concentration |
For platform-level deployment details, capacity planning, and implementation blueprints, use the dedicated guide: Infrastructure and Deployment of Agentic Systems (Coming soon).
9. Putting It All Together
The concepts in this article form a layered dependency structure:
- An agent needs tools to act on the world.
- Tools can be unified behind MCP to eliminate redundant integration work.
- Skills guide how an agent uses those tools for a specific domain.
- A RAG pipeline prepares the data context that agents consume.
- A workflow sequences multiple agents and enforces control flow.
- A framework provides the runtime that implements all of the above.
- Safety and governance enforce correctness and authorization at every external-action boundary.
- Observability supplies the information needed to debug, improve, and audit the system over time.
These are not competing ideas. They are complementary layers in a stack. Skipping any one of them shifts its complexity onto the others.
A Concrete End-to-End Example
To make this concrete, consider a technical research assistant that retrieves papers, summarizes them, and drafts a grounded literature review.
The framework (LangGraph) instantiates four agents and defines the workflow graph: Retriever → Summarizer → Writer → Verifier.
The workflow routes the user’s research query to the Retriever first. If the Verifier finds the draft insufficiently supported by the retrieved sources, the workflow re-routes back to the Retriever for additional documents before the Writer retries.
The Retriever agent uses a [retrieve-papers] skill that specifies how to formulate search queries, what fields to extract from each result, and how to handle ambiguous queries. It calls a semantic_scholar_search tool registered through a custom MCP server.
The RAG pipeline ingests retrieved paper texts, chunks them, embeds them with a domain-specific embedding model, and stores them in a vector database. At synthesis time, a two-stage retriever (bi-encoder followed by cross-encoder re-ranking) surfaces the top-K most relevant chunks for the Summarizer.
The Summarizer agent uses a [summarize-paper] skill and produces structured JSON summaries with required fields: title, key contributions, limitations, and a verbatim quote.
The Writer agent assembles summaries into a draft. It uses a write_file tool exposed by the filesystem MCP server. The Writer role’s tool set explicitly excludes the ability to read the vector database directly; it may only accept content passed from the Summarizer.
The Verifier agent checks that every claim in the draft is supported by a quote or citation from the summaries. It holds a reject_draft tool but no write tools; it can block the result but cannot modify it.
The safety layer presents a HITL checkpoint before the write_file operation executes, logging the proposed file path and the draft content. Paper abstracts are injected in the user role (not the system role) to structurally defend against prompt injection from adversarial paper contents. Every agent step is traced with full token counts and tool arguments.
Every architectural decision in this example corresponds directly to a layer described in this article.
10. Practical Guidance: Starting Points and Common Mistakes
10.1 Match the Architecture to the Task
A software engineer asked to fix a single bug does not need three senior consultants. Most agent tasks do not need a six-agent system. A reliable progression:
- Simple, structured task with predictable steps. Use a deterministic workflow with LLM nodes only where judgment is genuinely required.
- Open-ended research or exploration. A single ReAct agent with a well-designed tool set and a retry budget is usually sufficient.
- High-stakes output requiring verification. Add one critic or verifier agent. Start there before adding more.
- Large task with natural role decomposition. Move to a hierarchical manager-worker pattern with explicit interfaces between roles.
Add complexity only when measurements show a bottleneck, not in anticipation of future needs.
10.2 Common Failure Modes and Fixes
Tool misuse. The agent calls a tool with wrong arguments or in the wrong context. Fix: strengthen tool descriptions with explicit use-case examples and boundary conditions; add a validation wrapper that checks arguments against the schema before execution reaches the actual function.
Invisible failures. A tool returns an empty result or a soft error; the agent proceeds as if it succeeded and fabricates data it never retrieved. Fix: tools must return explicit success and failure status; the agent should treat any ambiguous result as a failure requiring investigation, not a reason to continue.
Infinite loops. The agent retries the same action repeatedly without acquiring new information. Fix: a progress detector that compares state before and after each step; a maximum-iterations hard limit; a “try a different approach” instruction triggered when progress stalls.
Context poisoning. Stale, incorrect, or adversarially crafted content corrupts subsequent reasoning steps. Fix: time-stamp all retrieved memory; apply recency decay in RAG scoring; structurally separate trusted instructions from untrusted retrieved data.
Over-architecture. A six-agent system for a task that one agent handles easily adds latency, cost, debugging surface, and coordination overhead without benefit. Fix: start smaller; add components only after benchmarks demonstrate that the additional complexity improves measured outcomes.
10.3 A Sensible Build Order
Teams often understand the architecture conceptually and still build it in the wrong order. A pragmatic implementation sequence is:
- Start with the tool boundary. Make the tools reliable, typed, auditable, and idempotent before adding agent autonomy on top.
- Add the single-agent loop next. Prove that one agent with a small tool set can solve the task class at acceptable quality and cost.
- Introduce a workflow graph only when you can name stable stages or explicit retry branches that should not be left to model judgment.
- Add verification and guardrails before scaling traffic. A system that works in a demo but cannot reject unsafe or unsupported actions is not production-ready.
- Add multi-agent specialization only after measurements show that role separation improves outcomes enough to justify the coordination overhead.
- Expand memory, caching, and deployment topology last, once the behavior is correct and the main bottlenecks are visible in traces.
This order looks conservative, but it prevents a common failure pattern: teams investing heavily in elaborate orchestration before they have trustworthy tools, clear success criteria, or a baseline single-agent system to compare against.
The agentic ecosystem is not a single technology. It is a layered system of interoperable components: intelligence in the LLM, capability in the tools, expertise in the skills, coordination in the workflow, efficiency in the pipeline, reliability in the safety layer, and insight in the observability infrastructure. The coherence of the whole is the framework’s job.
Build each layer deliberately, test it independently, and integrate it incrementally. The head chef, the kitchen stations, the ticket rail, the recipe sequence, and the kitchen layout are always there (regardless of what the restaurant calls them). What changes from system to system is not whether those layers exist, but how explicitly you design them, and how much operational discipline you bring to the seams between them.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!