Imagine you need to write a detailed technical report on a topic you know nothing about yet. You could ask one highly capable researcher to do everything: find sources, read them, extract relevant quotes, cross-check facts, write the draft, check the math, and proof-read the final version. That researcher would spend hours and would likely make mistakes they cannot catch in their own work.
Alternatively, you could build a small team: one person searches the literature, one synthesizes the findings, one writes, and one reviews. The team finishes faster, catches more errors, and produces a more reliable result. This team-based approach is the essence of a multi-agent system (MAS).
This article walks you through the full picture: the intuition, the math, the architecture patterns, and the practical implementation details you need to build and operate MAS in the real world.
1. Single Agent vs. Multi-Agent System
Before diving into MAS, it helps to understand what a single agent is and where it breaks down. For details of single-agent, see architecture patterns of single-agent.
The key point is that a single agent is a monolithic decision-maker. It perceives, reasons, and acts in one continuous loop. This simplicity has advantages but also predictable failure points. MAS is the natural evolution when you need more reliability, specialization, or parallelism than a single agent can provide.
1.1 The Single Agent
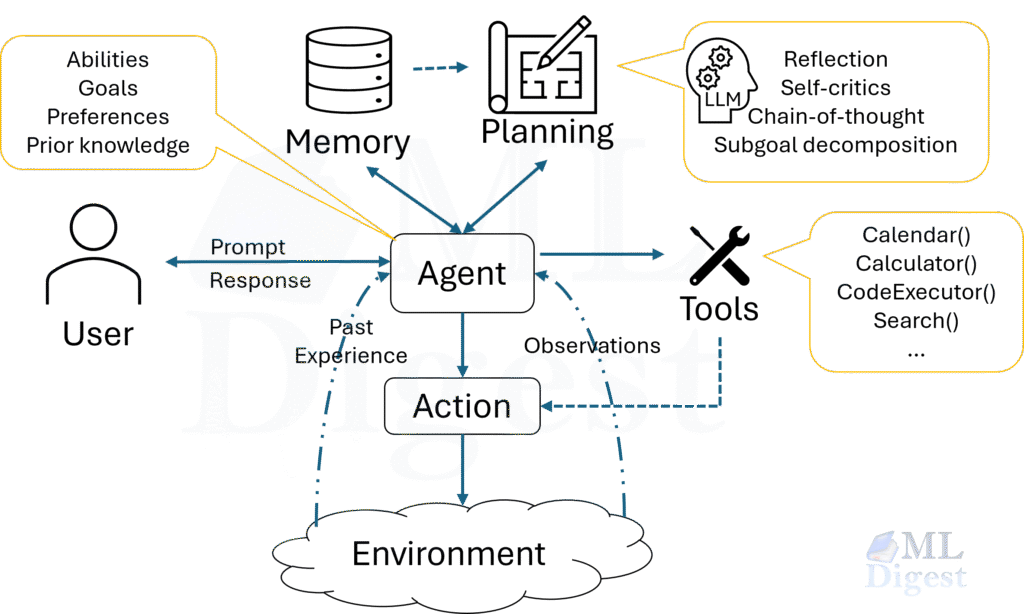
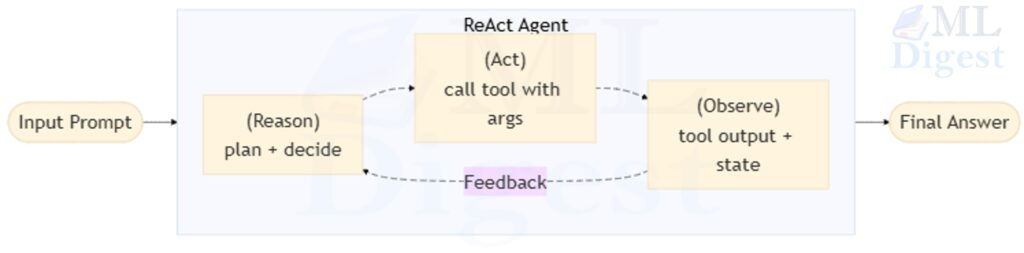
A single agent perceives its environment, maintains some internal state, chooses actions, and pursues a goal. In the world of LLMs, a single agent might be a language model with access to a handful of tools such as a web search, a code interpreter, or a file reader. It reasons step-by-step (in a ReAct or chain-of-thought loop) and iterates until it has an answer.
Single agents work well when:
- The problem fits within one context window.
- The reasoning path is mostly linear.
- There is no need for adversarial self-checking.
- Latency and cost constraints prohibit multiple LLM calls.
1.2 Where the Single Agent Breaks Down
Single agents have predictable failure points:
- Hallucinations and overconfidence. There is no independent voice to push back on a wrong assumption.
- Context overflow. Long tasks exhaust the context window; the agent loses track of early evidence.
- Role conflict. One agent asked to both propose and critique its own work will almost always be lenient on itself.
- Sequential bottleneck. Every step waits for the previous one. There is no parallelism.
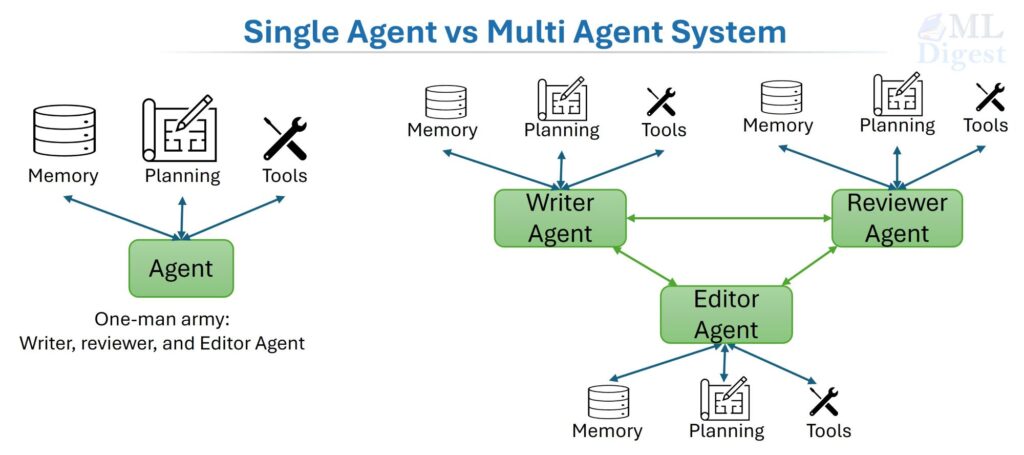
1.3 The Multi-Agent System
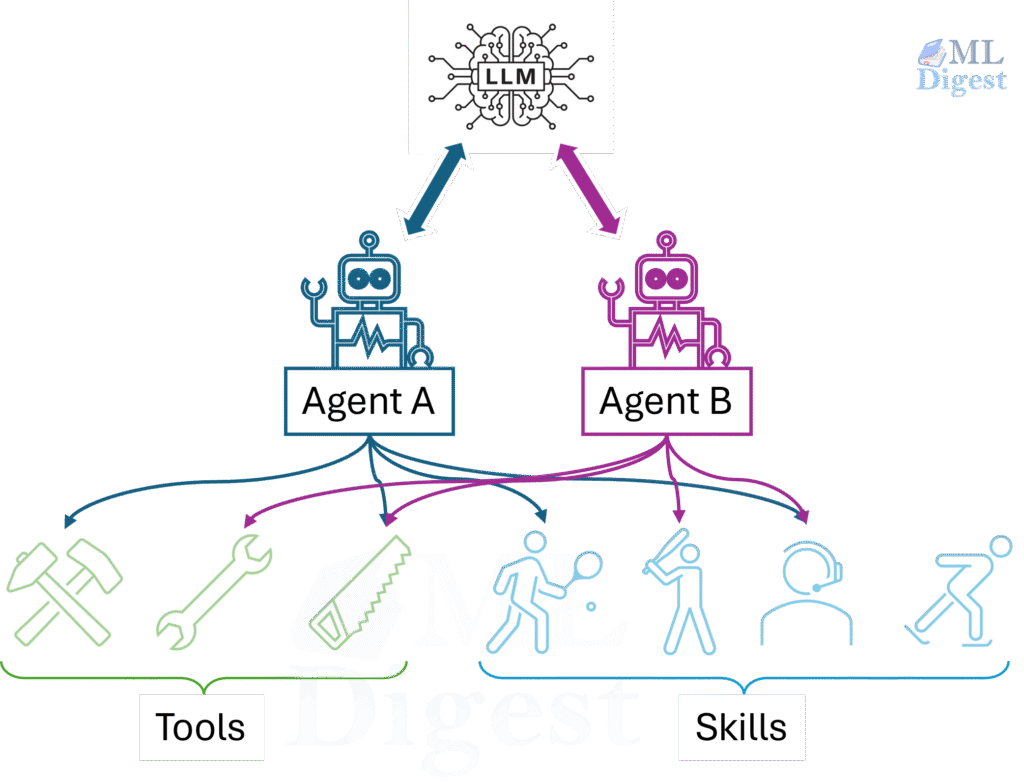
A multi-agent system (MAS) is a computational system in which multiple autonomous agents interact in a shared environment. Each agent has its own observations, internal state, actions, policy, and communication channel. The key idea is that global behavior emerges from local decisions plus coordination; no single agent needs to know everything.
| Dimension | Single-Agent Architecture | Multi-Agent Architecture |
|---|---|---|
| Definition | A single AI agent independently attends to the task. | Multiple AI agents collaborate to attend to the task. |
| Reasoning scope | One context window and one control loop. | Distributed across agents with role-specific context. |
| Error checking | Self-review only, which is often weaker. | Independent verifier or critic agents can provide stronger checks. |
| Parallelism | Mostly sequential. | Concurrent subtasks are possible. |
| Specialization | One generalist agent handles multiple responsibilities. | Role-specific agents can specialize by function. |
| Strengths | Low complexity, easier to develop and manage. No coordination needed. Requires fewer resources. | Handles complex and dynamic tasks better. Supports parallel processing for efficiency. Can often use smaller models because each agent handles a narrower task. |
| Weaknesses | May struggle with complex or dynamic environments. Limited for tasks that require collaboration or diverse expertise. May require a larger model to handle multiple reasoning steps. | Increased complexity and coordination overhead. Requires robust mechanisms to manage interactions. Requires more resources overall. |
| Use when | The task is straightforward and well-defined. Resource constraints dominate. | The task is complex, dynamic, or requires specialized knowledge and collaboration. Scalability and adaptability matter. |
| Cost per task | One LLM call chain. | Multiple LLM call chains. |
| Operational complexity | Low. | Higher. |
The right choice is always task-dependent. If a single agent and a checklist suffice, use them. MAS is worth the complexity only when the task genuinely benefits from specialization, parallelism, or independent verification.
2. Why Multi-Agent Systems Matter
- Reliability through Redundancy and Independent Verification:
When a reviewer agent is structurally separated from the writer agent, it cannot share the same blind spots. It reviews the artifact with fresh eyes, without the investment in the reasoning that produced it. This mirrors the way peer review works in science, or how a code reviewer catches bugs the author missed. - Parallelism and Specialization:
Many tasks have separable subtasks. A retriever agent can be fetching sources at the same time as the planner is laying out the outline. A writer can begin drafting section 1 while section 2 sources are still being retrieved. The wall-clock time shrinks, and each agent can be tuned (in prompting, tooling, or even model size) for its specific role. - Natural Match for Real-World Problems:
Many of the problems worth solving are inherently multi-actor: markets, supply chains, distributed systems, scientific teams, robotic swarms. MAS is the natural modeling framework for these domains, and the same conceptual vocabulary (agents, messages, shared state, coordination) applies whether you are building an LLM pipeline or deploying a fleet of autonomous vehicles. - The Bridge Between LLM Orchestration and Classical MARL:
A modern LLM pipeline with a “planner → tool-user → critic” structure is a multi-agent system. The same foundational ideas (partial observability, credit assignment, incentive alignment) appear in multi-agent reinforcement learning (MARL), just with different training machinery. A useful survey starting point is Hernandez-Leal et al., 2019. Understanding both sides makes you a better practitioner of either.
3. When to Use MAS (and When Not To)
Use MAS when
- The task decomposes into roles with clear, checkable interfaces.
- Verification is critical : finance, medicine, security, production code.
- The environment is partially observed and benefits from distributed sensing.
- You need to negotiate between competing objectives (resource allocation, scheduling).
Avoid MAS when
- The problem is small and linear; a single agent and a checklist suffice.
- Latency and cost are strict; each agent hop multiplies both.
- You cannot define who is responsible for what, or how success is measured. Coordination then amplifies confusion rather than reducing it.
A practical rule of thumb: if you cannot write down the acceptance criteria for each agent’s output before you build the system, do not build the system yet.
4. MAS Taxonomy: Cooperation, Competition, and Mixed Motives
The relationship between agents’ objectives shapes the entire design.
Cooperative MAS: All agents share a single global objective. Multiple robots coordinating to move warehouse boxes. Multiple LLM agents collaborating to produce a research report. Design choices: value decomposition, centralized training with decentralized execution.
Competitive MAS: Agents have opposing objectives. Adversarial games (chess engines competing), auction bidding strategies. Design choices: minimax optimization, equilibrium concepts.
Mixed-motive MAS: Agents share some goals but also have private incentives. Traffic routing with selfish drivers is the classic example. Design choices: mechanism design, incentive engineering, multi-objective optimization.
This classification is not just taxonomic; it drives algorithm selection, safety design, and how you think about failure modes.
| Cooperative | Competitive | Mixed-Motive | |
|---|---|---|---|
| Shared objective | All agents optimize the same reward. | Agents have opposing objectives. | Agents share some goals; diverge on others. |
| Typical algorithm | VDN, QMIX | Minimax, self-play | MADDPG, Multi-objective RL, mechanism design |
| Key failure mode | Free-riding (one agent coasts on others’ effort). | Arms race or reward hacking. | Collusion or defection depending on incentive alignment. |
| LLM MAS example | Planner–retriever–writer pipeline | Red-team attacker vs. safety defender | Agent marketplace with shared task revenue and competing specializations |
5. Mathematical Foundations
The math here provides a precise vocabulary for the concepts above. Even if you never implement a MARL training loop, the formalism helps you ask sharper design questions.
5.1 Single-Agent Baseline: the MDP
A Markov Decision Process (MDP) is the standard model for a single agent in a fully observable environment:
$$\mathcal{M} = (\mathcal{S}, \mathcal{A}, P, R, \gamma)$$
- $\mathcal{S}$: the set of possible states.
- $\mathcal{A}$: the set of possible actions.
- $P(s’ \mid s, a)$: the probability of transitioning to state $s’$ after taking action $a$ in state $s$.
- $R(s, a)$: the reward received.
- $\gamma \in [0, 1)$: the discount factor — how much the agent values future rewards relative to immediate ones.
The agent seeks a policy $\pi(a \mid s)$ that maximizes the expected discounted return:
$$J(\pi) = \mathbb{E}_\pi \left[ \sum_{t=0}^{\infty} \gamma^t r_t \right]$$
Intuition: The MDP is a math-ified version of a single agent navigating a chess board. It knows the full board state, has a clear reward signal (win/lose), and learns which moves lead to victory.
5.2 Partial Observability: the POMDP
In practice, agents rarely see the full state. An LLM agent does not know what is in the user’s head, what documents exist that were not retrieved, or what a web page said before it was behind a paywall. The Partially Observable MDP (POMDP) handles this:
$$\mathcal{P} = (\mathcal{S}, \mathcal{A}, P, R, \Omega, O, \gamma)$$
Two additions:
- $\Omega$: the observation space (what the agent actually sees).
- $O(o \mid s, a)$: the observation model — the probability of observing $o$ given true state $s$ and action $a$.
Because the agent cannot see the true state, it maintains a belief state $b(s)$ (a probability distribution over all possible true states) and updates it via Bayes’ rule as new observations arrive:
$$b'(s’) \propto O(o \mid s’, a) \sum_s P(s’ \mid s, a) \, b(s)$$
For LLM agents, the “belief state” is roughly the agent’s working memory: the set of hypotheses it holds about what is true, weighted by the evidence it has seen.
5.3 Multi-Agent MDP: Stochastic (Markov) Games
Extend the MDP to $N$ agents. Each agent $i$ maintains its own action space $\mathcal{A}_i$. All agents act simultaneously, forming a joint action $\mathbf{a} = (a_1, \ldots, a_N)$. The formal object is a stochastic Markov game:
$$\mathcal{G} = \left(\mathcal{S}, {\mathcal{A}_i}_{i=1}^{N}, P, {R_i}_{i=1}^{N}, \gamma\right)$$
Transitions and rewards depend on the joint action:
$$s’ \sim P(s’ \mid s, \mathbf{a}), \qquad r_i = R_i(s, \mathbf{a})$$
In cooperative settings, there is a single shared reward: $R_1 = R_2 = \cdots = R_N = R$. In competitive settings, rewards are in opposition (often summing to zero). In mixed settings, rewards partially overlap.
5.4 Decentralized POMDP (Dec-POMDP)
The most general model for cooperative, partially observed multi-agent settings is the Dec-POMDP formalism (Bernstein et al., 2002):
$$\text{Dec-POMDP} = \left(\mathcal{S}, {\mathcal{A}_i}, P, R, {\Omega_i}, O, \gamma\right)$$
Each agent $i$ has its own local observation space $\Omega_i$ and observation model $O_i(o_i \mid s, \mathbf{a})$. Agents choose actions based on their individual observation histories. There is no global coordinator at execution time.
The hard truth: optimal planning in Dec-POMDPs is NEXP-complete in the general case. This is why practical systems rely on approximations: hierarchical decomposition, role constraints, explicit gating, and coordination via shared state rather than exact joint planning.
5.5 Equilibria and Solution Concepts
For competitive or mixed-motive settings, a useful concept is the Nash equilibrium: a joint policy $(\pi_1^*, \ldots, \pi_N^*)$ from which no individual agent can improve its return by unilaterally changing its policy.
$$\forall i, \quad J_i(\pi_i^*, \pi_{-i}^*) \geq J_i(\pi_i, \pi_{-i}^*) \quad \forall \pi_i$$
For two-player zero-sum games, minimax provides a tractable solution:
$$\pi^* = \arg\max_\pi \min_{\pi’} J(\pi, \pi’)$$
For LLM-based MAS, you rarely compute equilibria explicitly. But the intuition matters for safety design: agents must be built so that their incentives do not lead to harmful behaviors, such as reward hacking, collusion, or misrepresentation.
5.6 Consensus and Aggregation
Many MAS architectures combine the outputs of multiple agents. If each agent produces a scalar estimate $x_i$ with associated uncertainty $\sigma_i^2$ (under a Gaussian noise model), the optimal linear fusion is:
$$\hat{x} = \frac{\sum_i w_i x_i}{\sum_i w_i}, \qquad w_i = \frac{1}{\sigma_i^2}$$
In plain language: weight each agent’s estimate by how reliable it is. Agents with lower uncertainty get more influence.
For LLM judgment tasks (which agent’s answer is correct?), analogous ideas appear as:
- Majority vote (simple baseline, no uncertainty modeling).
- Weighted vote (agents with higher historical accuracy get more weight).
- Bayesian model averaging (when you can model each agent’s calibration).
6. Common MAS Architectures
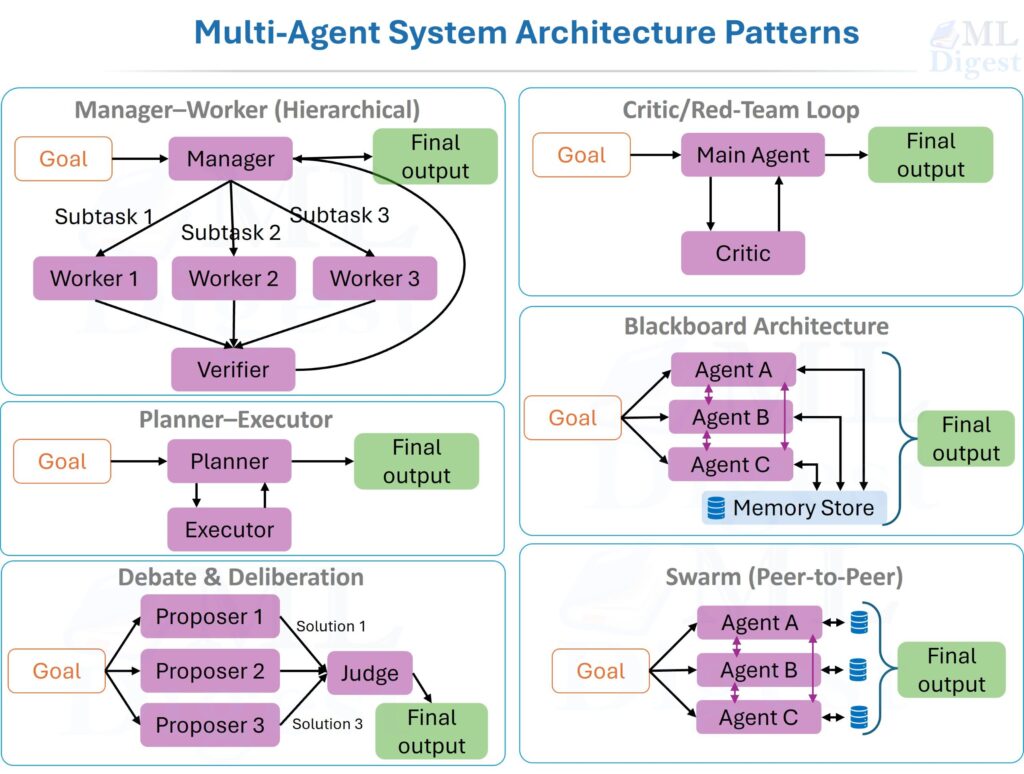
6.1 Manager–Worker (Hierarchical)
The canonical LLM MAS pattern. A manager decomposes the task into subtasks and assigns them to specialized worker agents. An optional verifier checks outputs before the manager assembles the final result.
This architecture works well when tasks decompose into orthogonal roles with clear interfaces. Start with the smallest viable team: planner, executor, and verifier. Add new agent roles only when benchmarks demonstrate an actual bottleneck.
6.2 Planner–Executor
The planner generates a step-by-step plan and a tool strategy before any execution begins. The executor then carries out the plan, logging evidence and returning structured results.
The separation reduces planning drift (the tendency of a single agent to revise its plan mid-execution in response to each small surprise from the environment, even when the original plan was correct).
6.3 Debate and Deliberation
Multiple proposer agents independently generate solutions. A judge agent evaluates, ranks, and synthesizes.
In the adversarial variant, one agent argues for a conclusion while a red-team agent argues against it. This mirrors the “devil’s advocate” technique in consulting and is particularly effective for surfacing hidden assumptions in plans.
6.4 Critic / Red-Team Loop
A main agent generates an artifact (code, a plan, an analysis). A critic agent reviews it for failures, edge cases, security issues, or logical gaps. The main agent revises. The loop repeats until the verifier approves or the iteration budget is exhausted.
This pattern often improves output quality more than adding extensive prose instructions to the main agent’s system prompt. The critic externalizes the verification step, making it observable and measurable.
6.5 Blackboard Architecture
Agents post partial results to a shared blackboard (a structured, shared memory store). Other agents read, extend, and refine what is there. There is no fixed execution order; agents activate when their preconditions are satisfied in the blackboard.
This is well-suited for knowledge-intensive tasks where information accumulates incrementally from many heterogeneous sources.
6.6 Swarm (Peer-to-Peer)
No central manager. Agents communicate with local neighbors, and global behavior emerges from local interactions. Swarms are useful for exploration and coverage tasks, but they are harder to control, debug, and cost-manage. Most production systems use hierarchical or semi-hierarchical patterns with explicit coordination points rather than pure swarms. Exceptions include multi-drone search-and-rescue missions, distributed web crawlers, and sensor-network anomaly detection. These are all settings where there is no natural central coordinator and physical or network locality is the dominant constraint.
7. Core Mechanisms: Communication, Memory, and Coordination
7.1 Communication Protocols
Three primary models:
- Direct messaging: Sender routes a message directly to the receiver. Simple and debuggable.
- Publish/subscribe: Agents subscribe to topics. Decouples producers from consumers; scales to many agents.
- Shared state: A database or vector store that all agents can read and write. Best for artifacts that multiple agents incrementally build.
In practice, use structured messages. The schema below is a good template:
{
"type": "task_result",
"task_id": "retrieve_papers_01",
"summary": "Found 6 relevant sources on Dec-POMDP and MADDPG",
"artifacts": ["url1", "url2"],
"confidence": 0.78,
"open_questions": ["Need publication year for original Dec-POMDP complexity result"]
}A confidence field and an open_questions list are high-value additions. They tell downstream agents where to focus verification effort.
7.2 Memory Types
Agentic systems rely on multiple memory types that include different tradeoffs in latency, capacity, and retrievability. The three main types are: 1) Episodic memory: a log of all interactions, tool calls, and messages; 2) Semantic memory: a structured knowledge base of facts, concepts, and relationships; and 3) Procedural memory: a library of skills, workflows, and tool-use patterns.
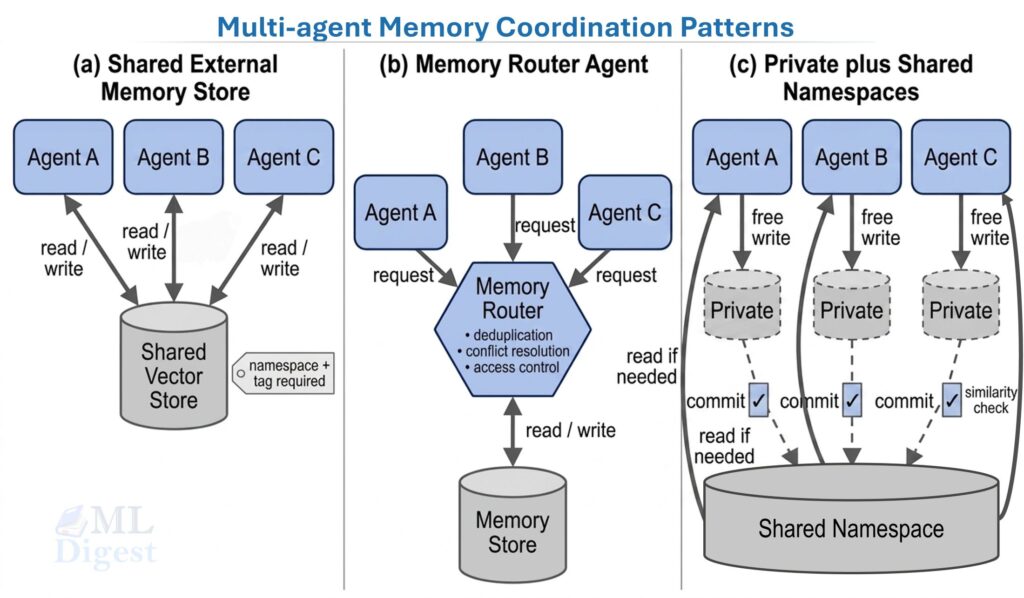
Apart from these functional distinctions, another important design axis is coordination: whether memory is private to each agent or shared across agents. Three common patterns are: 1) Shared External Memory, where all agents read and write to the same store; 2) Memory Router Agent, which manages all reads and writes and handles deduplication, conflict resolution, and access control; and 3) Hybrid Memory, where agents have private memories but can post summaries or relevant facts to a shared store for others to read. For details of memory architectures, see the post on memory in agentic systems.
7.3 Coordination Strategies
- Explicit planning: The manager assigns tasks with clear acceptance criteria and ownership.
- Market-based allocation: Agents bid for tasks; the task goes to the highest-utility bidder. Used in distributed resource scheduling.
- Role constraints: Each agent can only perform specific action types, enforced at the orchestrator level.
- Gating: A verifier must approve an artifact before downstream agents can consume it. This prevents error propagation.
8. Implementation: Step-by-Step
This section assumes you are building an MAS for tasks such as research, question answering, coding, or document writing.
Step 1: Specify the Output Contract
Before writing any code, define success in a checkable form:
- Output format (for example, a markdown document with a specific section structure).
- Constraints (sources required, forbidden tool categories).
- Agent Evaluation metrics (factual accuracy, citation coverage, latency, cost per run).
Step 2: Define Agent Roles
Start with three to five roles:
- Planner: Decomposes the task and defines acceptance criteria for each subtask.
- Retriever: Gathers sources, extracts quotes, and returns structured evidence.
- Writer: Drafts the final artifact, citing the retrieved evidence.
- Verifier: Checks claims, runs tests, and validates constraints.
- Safety/Policy agent (optional): Checks for compliance, risk, and policy violations before any output is finalized.
Each role should be orthogonal. If two agents do the same thing, document why; either it is deliberate redundancy or it is a design smell.
Step 3: Choose the Communication Substrate
- In-memory message queue: Fast to prototype, not durable.
- Durable queue (Redis, RabbitMQ): Required when agents run in separate processes or on separate machines.
- Shared database: For artifacts and traces that multiple agents need to access asynchronously.
Step 4: Implement the Orchestrator
The orchestrator is the “control plane.” It should:
- Route messages between agents.
- Track task state (pending, running, done, failed).
- Enforce budgets (token count, wall-clock time, cost).
- Apply retries with exponential backoff for flaky tools.
- Log everything with sufficient detail for post-hoc debugging.
Step 5: Add Tool Permissioning
Apply the principle of least privilege to tools:
- Retriever: web search, document fetch.
- Executor: code execution, file read.
- Writer: no destructive tools.
- Verifier: test runners, linters, fact-check APIs.
This limits the blast radius of a misbehaving or compromised agent.
Step 6: Add Verification Gates
Typical gates in production systems:
- Every external factual claim requires a citation or evidence snippet.
- Every code change requires unit tests to pass.
- Every final output requires a verifier’s summary and approval.
Step 7: Build an Evaluation Harness
You need repeatable tests before you can iterate reliably:
- A fixed set of benchmark prompts.
- Golden outputs or rubric-based scoring functions.
- Trace inspection tooling (view every message and tool call per run).
- Regression tracking over time.
9. Example Implementation: A Minimal MAS Loop
Below is a minimal manager–worker–verifier orchestration loop. The code is intentionally simplified to focus on structure.
from dataclasses import dataclass, field
from typing import Any, Dict, List
@dataclass
class Message:
sender: str
receiver: str
type: str
payload: Dict[str, Any]
class Orchestrator:
def __init__(self, agents: Dict[str, Any], max_rounds: int = 10):
self.agents = agents
self.max_rounds = max_rounds
self.queue: List[Message] = []
self.shared_state: Dict[str, Any] = {}
def send(self, msg: Message) -> None:
self.queue.append(msg)
def run(self, initial_msg: Message) -> Dict[str, Any]:
self.send(initial_msg)
rounds = 0
while self.queue and rounds < self.max_rounds:
msg = self.queue.pop(0)
# Reject messages to unknown agents rather than silently failing.
if msg.receiver not in self.agents:
raise ValueError(f"No agent registered with name '{msg.receiver}'")
agent = self.agents[msg.receiver]
outgoing: List[Message] = agent.handle(msg, self.shared_state)
self.queue.extend(outgoing)
rounds += 1
return self.shared_state
# --- Example agents (stubs)
class PlannerAgent:
def handle(self, msg: Message, state: Dict[str, Any]) -> List[Message]:
# Decompose task and dispatch to Retriever
state["plan"] = ["retrieve_sources", "write_draft", "verify"]
return [
Message("planner", "retriever", "task", {"query": msg.payload["task"]})
]
class RetrieverAgent:
def handle(self, msg: Message, state: Dict[str, Any]) -> List[Message]:
# Simulate retrieval and pass evidence to Writer
state["sources"] = ["source_A", "source_B"]
return [
Message("retriever", "writer", "evidence", {"sources": state["sources"]})
]
class WriterAgent:
def handle(self, msg: Message, state: Dict[str, Any]) -> List[Message]:
# Produce a draft and send to Verifier
state["draft"] = f"Draft using {msg.payload['sources']}"
return [
Message("writer", "verifier", "review_request", {"draft": state["draft"]})
]
class VerifierAgent:
def handle(self, msg: Message, state: Dict[str, Any]) -> List[Message]:
# Approve or reject the draft
draft = msg.payload["draft"]
state["verified"] = "sources" in draft # simple heuristic for illustration
state["final_output"] = draft if state["verified"] else None
return [] # No further messages; the loop terminates
# --- Run it
agents = {
"planner": PlannerAgent(),
"retriever": RetrieverAgent(),
"writer": WriterAgent(),
"verifier": VerifierAgent(),
}
orchestrator = Orchestrator(agents, max_rounds=20)
result = orchestrator.run(
Message("user", "planner", "task_request", {"task": "Explain Dec-POMDP"})
)
print("Verified:", result["verified"])
print("Output:", result["final_output"])The key design choices embedded in this small loop:
- Shared state design: What gets persisted versus kept in messages.
- Message schema: What is communicated between agents.
- Stopping criteria: The
max_roundsbudget and the empty queue condition. - Verification gates: The verifier is the only agent that can write to
final_output.
10. Multi-Agent Reinforcement Learning (MARL): A Practical View of Training
When your agents are learned policies rather than prompted LLMs, you face a set of challenges that do not arise in static orchestration:
- Non-stationarity: From the perspective of any one agent, the other agents are part of the environment — but they are also changing during training. This violates the stationarity assumption underlying most single-agent RL convergence guarantees.
- Credit assignment: When a team of agents collectively produces an outcome, how do you assign credit (or blame) to individual agents?
- Partial observability: Each agent sees only local observations, yet must learn policies that work well at the team level.
10.1 Centralized Training, Decentralized Execution (CTDE)
The most widely adopted practical strategy. During training, a centralized critic has access to global state and joint actions — this stabilizes learning by resolving non-stationarity from the critic’s perspective. During execution, each agent acts only on its local observations, which keeps the system scalable and deployment-friendly. In modern deep MARL, this pattern is exemplified by MADDPG.
10.2 Credit Assignment and Difference Rewards
One principled approach to credit assignment is the difference reward. Given a global reward $R$ from the joint action $\mathbf{a} = (a_1, \ldots, a_N)$, the difference reward for agent $i$ is:
$$D_i = R(\mathbf{a}) – R(\mathbf{a}_{-i}, c_i)$$
Where $\mathbf{a}_{-i}$ denotes all other agents’ actions unchanged, and $c_i$ is a default (counterfactual) action for agent $i$.
Intuition: Reward agent $i$ not for the total outcome, but for how much it improved the outcome relative to what would have happened had it done something neutral. This isolates each agent’s individual contribution.
10.3 Value Decomposition (Cooperative MARL)
Rather than learning a single monolithic $Q_{tot}(s, \mathbf{a})$ over the joint action space (which grows exponentially with $N$), value decomposition methods approximate it as a function of per-agent values:
$$Q_{tot}(s, \mathbf{a}) \approx f \left(Q_1(o_1, a_1), \ldots, Q_N(o_N, a_N)\right)$$
VDN uses the simplest form: $f$ is a plain sum, $Q_{tot} = \sum_i Q_i$, which trivially allows each agent to maximize its own $Q_i$ independently. QMIX generalizes this by learning a non-linear mixing network constrained to be monotonically non-decreasing in each $Q_i$. The key insight is that when $f$ satisfies this monotonicity condition, the global argmax over $\mathbf{a}$ can still be computed by each agent independently maximizing its own $Q_i$. This gives you richer joint-action modeling without the exponential joint-action search.
11. Practical Tips
11.1 Start with the Smallest Useful Team
For production-quality LLM work, begin with three agents: planner, executor, and verifier. Add roles only when you have empirical evidence of a bottleneck.
11.2 Write Explicit Acceptance Criteria
Instead of: “Find papers about MAS.”
Write: “Return five sources from 2020–2026. For each, include two to three bullet-point contributions and one direct quote. Include a full citation in BibTeX format.”
The second form is checkable by a verifier without any ambiguity.
11.3 Trace Everything
Log, at minimum:
- Every message (sender, receiver, type, payload, timestamp).
- Every tool call and its raw output.
- Every intermediate draft produced by the writer.
- Every verifier decision and its reasoning.
Traces are your debugging microscope. Without them, diagnosing a multi-hop failure is nearly impossible.
11.4 Put Budgets Everywhere
Budgets prevent runaway loops:
- Maximum rounds per task.
- Maximum tool calls per agent per run.
- Maximum tokens per agent per message.
- Maximum wall-clock time per task.
11.5 Handle Disagreement Explicitly
If two proposer agents produce conflicting conclusions, do not average them. Instead:
- Require each agent to provide supporting evidence.
- Ask the verifier to compare evidence quality using a structured rubric.
- Select the conclusion with stronger evidentiary backing.
A Concrete Example: MAS for Technical Writing
Suppose you want to produce a high-quality technical tutorial on a new paper. Here is the five-agent pipeline:
- Planner reads the task description and produces a structured outline with required sections, acceptance criteria per section, and a list of questions that must be answered.
- Retriever collects references, extracts relevant quotes, and returns structured evidence keyed to each section.
- Writer drafts the tutorial, citing the evidence by key.
- Verifier checks:
- Every factual claim has a linked citation.
- All mathematical expressions are consistent throughout the document.
- Any code snippets execute without error.
- Editor improves prose clarity, heading structure, and flow without changing factual content.
The pipeline is intentionally minimal. It demonstrates the core MAS value proposition: specialization plus sequential verification. Each agent is responsible for a narrow slice of quality, and each slice is checkable.
Best Practices Checklist
- Architecture: Separate the control plane from the data plane; apply least-privilege tooling per role; prefer deterministic gates over LLM-based gates.
- Prompting: Standardize message schemas; require citations for factual claims; write role-specific instructions that explicitly limit scope.
- Safety: Treat all tool outputs as untrusted; sanitize paths, URLs, and shell commands; isolate retrieved external text from agent instructions.
- Evaluation: Maintain a benchmark suite covering typical and adversarial cases; track success rate, cost, and latency; run red-team prompts periodically.
- Operations: Add structured observability with per-agent metrics; use retries with exponential backoff; ensure write operations are idempotent.
12. Common Failure Modes and Fixes
- Endless Loops: An agent keeps producing “needs more work” without ever converging to “approved.” Cost and latency spiral out of control.
- Fixes: Strict round budgets. Require the verifier to mark tasks as “approved” or “abandoned” (not just “needs more work”).
- “Phone Game” Distortion: A message passes through several agents, each paraphrasing the previous. The original evidence is lost by the time the final agent acts.
- Fixes: Use structured messages and attach artifacts (direct quotes, raw tool outputs, log snippets) rather than paraphrases.
- Evidence-Free Conclusions: An agent produces a conclusion without citing any evidence. This is common when the agent is incentivized to produce an answer but not to justify it.
- Fixes: Enforce a hard requirement that every claim must have an attached citation or evidence snippet. Reject outputs that lack them.
- Overlapping Responsibilities: Two agents both try to write the final answer. One overwrites the other.
- Fixes: Define clear contracts. Each non-trivial decision should have exactly one owner. Make the ownership explicit in the role description and in the message schema.
- Tool Misuse: An agent runs a destructive tool (file deletion, database write) when it should only be reading.
- Fixes: Tool permissioning at the orchestrator level. Add a dry-run mode for destructive actions. Route any write operation through a verifier gate.
13. LLM Agent Frameworks at a Glance
Several open-source frameworks implement the patterns described in this article. The right choice depends on how much control you need over the execution graph and how dynamic your agent interactions are.
| Framework | Primary Pattern | Key Strength | Practical Trade-off |
|---|---|---|---|
| AutoGen (Microsoft) | Manager–Worker, Debate, Critic loop | Flexible conversation-style multi-agent interactions; strong tool-use and human-in-the-loop support | Configuration complexity grows quickly with larger teams |
| CrewAI | Manager–Worker with declarative role assignments | Minimal boilerplate for sequential pipelines; readable role and task definitions | Less flexible for dynamic graphs or complex branching logic |
| LangGraph | Stateful graph (nodes = agents, edges = transitions) | Precise control over execution flow; native support for cycles and conditional branching | Steeper learning curve; requires explicit graph design upfront |
Practical guidance: For a quick prototype with a small, fixed team, CrewAI reduces boilerplate. For precise control over the execution graph, cycles, or critic loops, LangGraph is the better fit. AutoGen excels when you need rich, conversation-driven multi-agent interactions or want to keep a human in the loop at defined checkpoints. Regardless of framework, the principles in this article apply: define clear roles, gate outputs with a verifier, trace every message, and enforce budget limits. For details of other frameworks and a more comprehensive comparison, see the Agentic Systems Frameworks Landscape.
14. Best Practices Checklist
Architecture
- Separate the control plane (the orchestrator) from the data plane (the agents and their tools).
- Apply least-privilege tooling per agent role.
- Prefer deterministic gates (schema validation, unit tests) over subjective LLM-based gates wherever possible.
Prompting and Interfaces (LLM MAS)
- Standardize message schemas (use JSON with explicit required fields).
- Require citations or evidence snippets for factual claims; reject outputs that lack them.
- Write role-specific system instructions that explicitly describe what the agent should not do, preventing scope creep.
Safety and Security
- Treat all tool outputs as untrusted input. Validate and sanitize before passing to downstream agents.
- Sanitize file paths, URLs, and shell commands to prevent injection.
- Isolate retrieved external text from agent instructions to prevent prompt injection attacks.
Evaluation
- Maintain a benchmark suite covering both typical cases and adversarial edge cases.
- Track success rate, cost, latency, and regression across versions.
- Run red-team prompts periodically to probe for emergent failure modes.
Operations
- Add structured observability: distributed traces, per-agent token and cost metrics, and alerting on budget exhaustion.
- Implement retries with exponential backoff for flaky external tools.
- Ensure write operations are idempotent so that retries do not produce duplicate side effects.
References
Mathematical foundations
- Puterman, M. L. (1994). Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley.
- Kaelbling, L. P., Littman, M. L., & Cassandra, A. R. (1998). Planning and acting in partially observable stochastic domains. Artificial Intelligence.
Multi-agent RL
- Bernstein, D. S., et al. (2002). The complexity of decentralized control of Markov decision processes. Mathematics of Operations Research. (Establishes NEXP-completeness of Dec-POMDPs.)
- Lowe, R., et al. (2017). Multi-agent actor-critic for mixed cooperative-competitive environments (MADDPG). NeurIPS.
- Sunehag, P., et al. (2018). Value-decomposition networks for cooperative multi-agent learning (VDN). AAMAS.
- Rashid, T., et al. (2018). QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. ICML.
LLM agent systems
- Park, J. S., et al. (2023). Generative agents: Interactive simulacra of human behavior. UIST. (Demonstrated emergent social behavior in LLM MAS.)
- Du, Y., et al. (2023). Improving factuality and reasoning in language models through multi-agent debate. arXiv preprint. (Empirical evidence for the debate pattern.)

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!