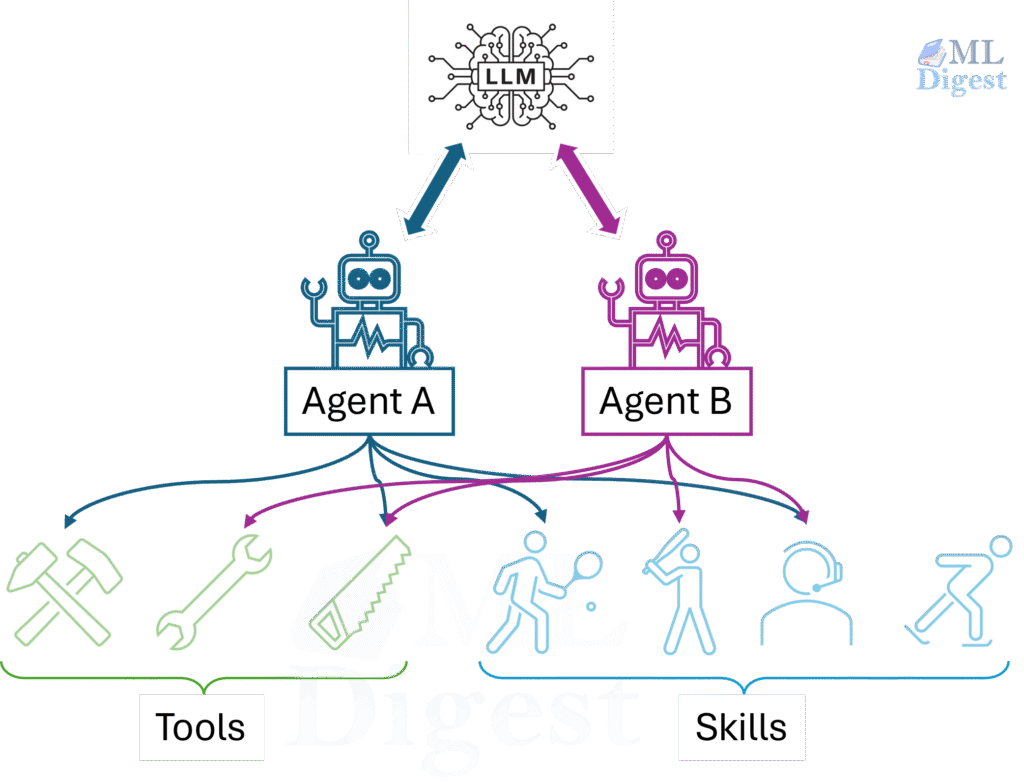
Think about your first week at a new job. Every new piece of information lands on a sticky note. By the end of the week your desk is buried. Over the months that follow, some facts migrate into your head (the important keyboard shortcuts, the team’s preferred libraries, the quirks of the codebase). Years in, the procedures do not feel like procedures anymore; they feel like instinct. The sticky notes are long gone. The company wiki still exists, but you open it rarely. The deep experience lives somewhere you cannot point to—it has become part of how you think.
What changed over those years is your memory architecture. Different kinds of knowledge live in different places, follow different rules about how they are stored and retrieved, and decay at different rates.
An AI agent faces exactly the same challenge. Its “active desk” — the context window — is finite. Complex tasks outlast any single session. Users expect the agent to remember past conversations, preferences, and context across weeks and months. Making agents genuinely useful over time means building this layered memory architecture deliberately.
This article walks through the full picture: what the layers of memory are, why each one exists, how information moves between them, and how to implement each layer in a working system.
1. Why Memory Is a First-Class Concern
A transformer-based language model, at its core, does one thing: given a sequence of tokens, predict the next token. Everything the model “knows” during a forward pass must be present in the context window. Once the window is full, nothing older is accessible.
This is not a bug; it is the design. But it creates a fundamental tension for agentic systems:
- Finite window, infinite tasks. Context windows have grown dramatically — from a few thousand tokens to hundreds of thousands — but tasks can still outlast them. A week-long coding project, a research synthesis spanning dozens of papers, or a customer-service agent with years of conversation history cannot fit in any single window.
- Personalization requires persistence. An assistant that does not remember a user’s preferences after the second conversation is not an assistant; it is a stateless form. Useful agents must maintain a persistent model of the user, their goals, and their ongoing work.
- Reasoning quality degrades at long range. Even within the context window, attention is not uniform. Relevant facts buried deep in a 100K-token context can be missed. Explicit memory retrieval is often more reliable than hoping the model attends to the right fragment of a very long context.
- Multi-agent coordination needs shared state. When multiple agents collaborate on a task, they need a shared understanding of what has happened, what is known, and what has been decided. That shared state is, again, memory.
The good news is that these challenges have well-understood solutions, drawn in part from cognitive science. It turns out that the way the human mind organizes memory offers a surprisingly useful blueprint.
2. The Memory Landscape: A Cognitive Blueprint
Cognitive scientists organize human memory into a hierarchy. At the top is working memory (the small, temporary workspace where information is held and manipulated right now). Below that is long-term memory, which splits into three major kinds: episodic (memories of specific past events), semantic (general world knowledge), and procedural (knowing how to do things). Underlying all of these is parametric memory, the deep associations learned through years of experience, sitting implicit in every skill and habit.
AI agents have an almost direct analog to each of these:
| Cognitive System | Agentic Equivalent | Where It Lives |
|---|---|---|
| Working memory | In-context memory (context window) | Active prompt / KV cache |
| Episodic memory | Event logs, conversation history | Vector DB / document store |
| Semantic memory | Facts, user profiles, world knowledge | Vector DB / key-value store |
| Procedural memory | Skills, workflows, tool-use patterns | Skill files, retrieval store |
| Implicit / parametric | Knowledge from pre-training | Model weights |
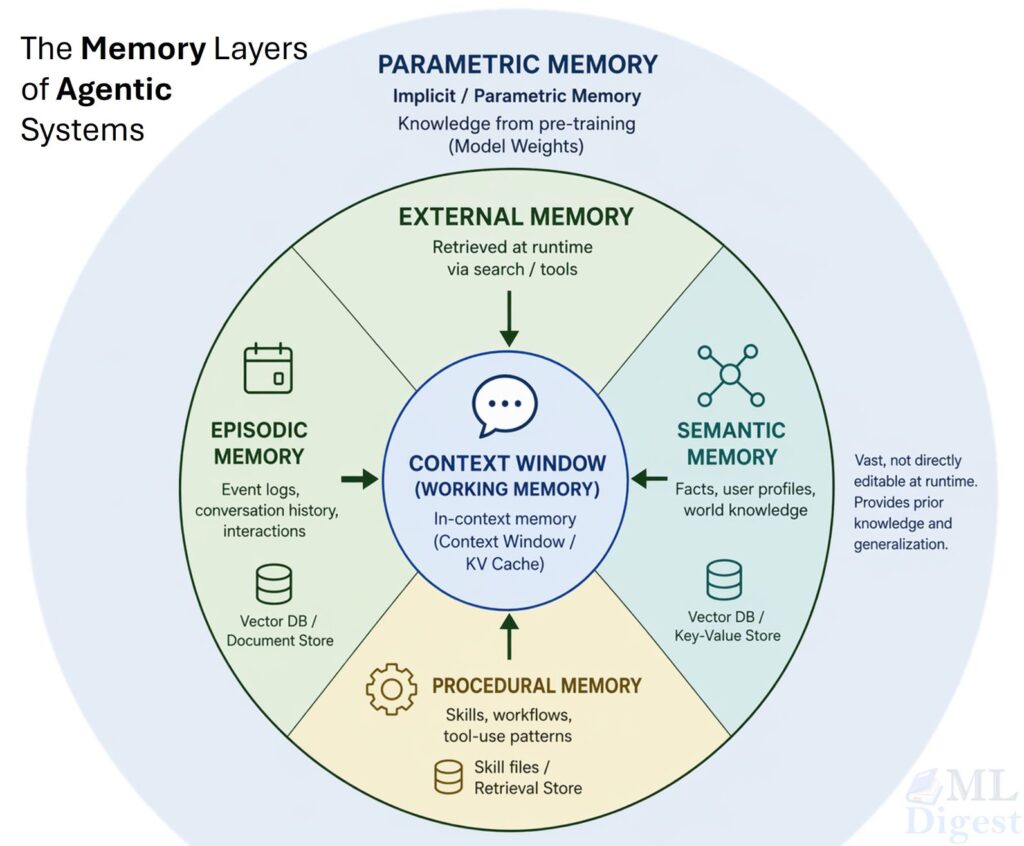

The “context window” is fully visible to the model at every step, but limited in size. The agent reaches into the “External Memory” (Episodic, Semantic, and Procedural) via retrieval at each step, pulling what is relevant into the inner circle. The “Parametric Memory” is the knowledge baked into the model’s weights that came with the model and cannot be changed at runtime.
3. In-Context Memory: The Working Desk
The context window is the only memory the model can directly “see.” Everything else must be retrieved and placed here before the model can use it. In-context memory has four defining properties:
- Fast: No retrieval step required; the model attends to it directly during the forward pass.
- Flexible: Any kind of content — text, code, structured data, tool outputs — can live here.
- Temporary: It is cleared at the end of a session unless explicitly persisted.
- Limited: Modern frontier models support windows ranging from 128K to over 1M tokens, but agentic tasks that involve many tool calls, long documents, and multi-step reasoning chains fill that budget quickly.
3.1 What Lives in the Context Window
At any given moment, the context window holds a structured conversation that typically contains:
- System prompt: The agent’s role, instructions, and any injected memory summaries.
- Retrieved memories: The top-$k$ items pulled from external memory for this turn.
- Tool definitions: The JSON schema for all available tools.
- Conversation history: The recent exchange between the user and the agent.
- Intermediate reasoning: Chain-of-thought or scratchpad content generated mid-step.
- Tool call results: Raw outputs from the tools invoked in the current step.
3.2 Managing Context Window Overflow
When a long-running task pushes the context to its limit, the agent must decide what to evict. Three main strategies exist:
- Truncation: Drop the oldest messages. Fast and simple, but it risks losing important early context; for instance, the user’s original goal.
- Summarization: Use the model itself to compress older messages into a short summary. This preserves semantics at the cost of one extra LLM call per compression step.
- Sliding window with retrieval: Keep a fixed-size window of recent messages, and move older content to external memory. On each turn, retrieve the most relevant older content and inject it back. This is the approach behind MemGPT, which treats the context window as analogous to RAM in an operating system and uses paging to move content in and out.
The key insight from MemGPT is elegant: just as an OS pages data to disk when physical memory is exhausted, an agent should proactively move older context to external store and retrieve pages on demand.
4. External Memory: The Filing Cabinet
External memory is anything that lives outside the context window but can be retrieved and injected when needed. It is the agent’s persistent knowledge store, surviving across sessions, conversations, and even model versions.
External memory is typically backed by a vector database (for semantic retrieval), a key-value store (for structured lookup), or a document store (for full-text search). The three functional categories — episodic, semantic, and procedural — map to distinct store and retrieval patterns.
4.1 Episodic Memory: The Diary
Episodic memory stores records of specific past events with their context: what happened, when, and who was involved. In agentic systems:
- Summaries of past conversations (“On April 10th the user asked me to redesign the data pipeline. The final design uses DuckDB.”)
- Actions the agent took and their outcomes
- Errors encountered and the strategies that resolved them
- User-specific events with enough temporal context to interpret them correctly
The critical feature of episodic memory is its temporal structure. When retrieving, combining semantic relevance (what is related to the current query?) with recency (what happened most recently?) is important. A piece of information from yesterday is more likely to be relevant than the same information from two years ago, even if their semantic similarity scores are identical.
A standard scoring formula combines the two signals:
$$\text{score}(m) = \alpha \cdot \text{sim}(q, m) + (1 – \alpha) \cdot \exp\left(-\lambda \cdot \Delta t\right)$$
Where:
- $q$ is the query embedding
- $m$ is the memory embedding
- $\text{sim}(q, m)$ is the cosine similarity between query and memory vectors
- $\Delta t$ is the age of the memory (in hours, days, or another unit)
- $\lambda$ controls how quickly recency weight decays with age
- $\alpha \in [0, 1]$ balances semantic relevance against recency (a typical value is $0.7$)
Generative Agents paper extended this with a third dimension — importance — computed by prompting the model to rate how significant each memory is on a scale from 1 to 10:
$$\text{score}(m) = w_1 \cdot \text{recency}(m) + w_2 \cdot \text{importance}(m) + w_3 \cdot \text{relevance}(m)$$
This three-way weighting allows the retrieval system to surface truly significant old memories over trivially similar but unimportant recent ones.
4.2 Semantic Memory: The Fact Sheet
Semantic memory stores general, factual knowledge that is not tied to any specific event. Unlike episodic memory, it has no inherent temporal structure — a fact is a fact regardless of when it was recorded. In agentic systems, semantic memory holds:
- User profiles (“the user is a senior ML engineer at a fintech company who prefers Python 3.11”)
- Domain knowledge the parametric model does not reliably cover
- System configuration and environment facts (“the production API endpoint is
https://api.internal/v2“) - Named entity information (“Dr. Cooper is the project lead for the recommendation system”)
The boundary between episodic and semantic memory is blurry in practice. A useful heuristic: episodic memory is what happened; semantic memory is what is true. Episodic entries carry a timestamp and an event context; semantic entries are timeless facts.
In implementation, both types share the same vector database — distinguished by a memory_type metadata field.
4.3 Procedural Memory: The Playbook
Procedural memory stores how to do things. It is the memory type most directly linked to the concept of agent skills — portable, retrievable packages of operational know-how. In agentic systems:
- Tool-use instructions (“to create a GitHub issue, first search for duplicates using the search tool before posting”)
- Multi-step workflows (“deployment checklist: 1. run tests, 2. build Docker image, 3. push to registry, 4. update Helm chart”)
- Domain-specific reasoning strategies (“when answering questions about GDPR compliance, always cite the specific article”)
Retrieval of procedural memory works somewhat differently from the other two types. Rather than semantic similarity to the current query text, retrieval is often better triggered by the current task type or active tool context. An agent beginning a deployment workflow should retrieve the deployment procedure because it is beginning a deployment; not purely because its query embedding happens to be close to the stored procedure. A practical implementation adds an explicit trigger_keywords field to each procedural memory entry.
5. Parametric Memory: Knowledge Baked Into the Weights
Parametric memory is the knowledge encoded in the model’s weights during pre-training and fine-tuning. It is the broadest form of memory, covering the full breadth of human text, but also the least flexible:
- It cannot be edited at inference time. Correcting a wrong fact in parametric memory requires a retraining or fine-tuning run.
- It has a knowledge cutoff. A model trained on data up to a given date does not know about events after that date.
- It is unreliable for narrow, specific facts. The model may confidently hallucinate a specific API call signature, a paper citation, or a product specification because it is extrapolating from similar-looking patterns in training data rather than recalling an actual fact.
- It cannot be personalized without fine-tuning. The model’s weights do not change based on individual user interactions.
The relationship between parametric memory and external memory is what makes Retrieval-Augmented Generation (RAG) so important. Rather than trusting parametric memory for specific, up-to-date, or user-specific facts, a RAG system retrieves those facts from an external store and injects them into the context. This is the dominant production pattern for supplementing parametric memory.
6. Memory Operations: Encoding, Store, Retrieval, and Forgetting
Four fundamental operations govern the full lifecycle of information in a memory system.
6.1 Encoding
Encoding is the process of converting raw information into a representation that supports efficient retrieval. For vector-backed memory, this means embedding — converting text into a dense vector that captures its semantic meaning.
import numpy as np
from openai import OpenAI
client = OpenAI()
def embed(text: str, model: str = "text-embedding-3-small") -> np.ndarray:
"""Convert text into a unit-normalized semantic embedding vector."""
response = client.embeddings.create(input=text, model=model)
vec = np.array(response.data[0].embedding, dtype=np.float32)
# Normalize to unit length so cosine similarity reduces to a dot product
return vec / (np.linalg.norm(vec) + 1e-9)The choice of embedding model matters because it determines what the retrieval system considers “similar.” A model trained on general web text may not capture domain-specific similarity well. For specialized domains, fine-tuned embedding models — such as Cohere Embed with domain adaptation — are worth considering.
6.2 Store
Once encoded, a memory is stored alongside its metadata: timestamp, source, importance score, type, and any tags. This metadata is critical for every downstream retrieval and eviction decision.
import uuid
from datetime import datetime, timezone
from dataclasses import dataclass, field
@dataclass
class Memory:
content: str
embedding: np.ndarray
memory_type: str # "episodic" | "semantic" | "procedural"
importance: float = 0.5 # 0.0 (trivial) → 1.0 (critical)
created_at: datetime = field(
default_factory=lambda: datetime.now(timezone.utc)
)
id: str = field(default_factory=lambda: str(uuid.uuid4()))
tags: list[str] = field(default_factory=list)6.3 Retrieval
Retrieval is the process of finding the stored memories most relevant to the current context. The standard approach is approximate nearest neighbor (ANN) search in embedding space.
Given a query embedding $q$ and stored memory embeddings ${m_1, m_2, \ldots, m_n}$, the cosine similarity between two unit-normalized vectors is:
$$\text{sim}(q, m_i) = \frac{q \cdot m_i}{|q| \cdot |m_i|}$$
Because embeddings from most models are already approximately unit-normalized, this reduces to the dot product $q \cdot m_i$, which is very fast to compute and enables SIMD-accelerated batch search.
For production systems, libraries like FAISS (Facebook AI Similarity Search), ChromaDB, Pinecone, and Qdrant provide efficient ANN search over millions of vectors.
Hybrid retrieval — combining dense vector search with sparse keyword search (BM25) — is often more robust than either method alone. The scores from the two systems are fused with a convex combination:
$$\text{hybrid_score}(q, m) = \beta \cdot \text{dense}(q, m) + (1 – \beta) \cdot \text{sparse}(q, m)$$
A typical starting value is $\beta = 0.6$, favoring semantic retrieval while retaining some weight on exact keyword matching for queries with specific technical terms (model names, error codes, identifiers) that embeddings can blur together. Both Weaviate and Qdrant support hybrid search natively.
6.4 Forgetting
Not all memories should live forever. Forgetting is not a failure; it is a deliberate design decision. Without an eviction policy, the memory store grows without bound, and retrieval quality degrades as relevant memories must compete with an ever-growing pile of stale, low-value, or near-duplicate entries. Three sensible eviction strategies:
- Time-based expiry: Episodic memories older than $N$ days are archived or deleted.
- Importance-based pruning: Memories with importance scores below a threshold are removed during a periodic cleanup pass.
- LRU (Least Recently Used): Memories not accessed in the last $N$ retrieval cycles are evicted, analogous to an LRU cache in systems programming.
7. Implementation: A Simple External Memory System
The following is a minimal but complete external memory system. It uses numpy for embedding similarity and an in-memory list as the backing store — replaceable with any vector database in production without changing the interface.
import uuid
import numpy as np
from datetime import datetime, timezone
from dataclasses import dataclass, field
from openai import OpenAI
client = OpenAI()
# ── Data model ──────────────────────────────────────────────────────────────────
@dataclass
class Memory:
content: str
embedding: np.ndarray
memory_type: str # "episodic" | "semantic" | "procedural"
importance: float = 0.5 # 0.0 (trivial) → 1.0 (critical)
created_at: datetime = field(
default_factory=lambda: datetime.now(timezone.utc)
)
id: str = field(default_factory=lambda: str(uuid.uuid4()))
tags: list[str] = field(default_factory=list)
# ── Embedding helper ─────────────────────────────────────────────────────────────
def embed(text: str) -> np.ndarray:
"""Embed text and return a unit-normalized float32 vector."""
resp = client.embeddings.create(
input=text, model="text-embedding-3-small"
)
vec = np.array(resp.data[0].embedding, dtype=np.float32)
return vec / (np.linalg.norm(vec) + 1e-9)
# ── Memory store ─────────────────────────────────────────────────────────────────
class AgentMemory:
"""
An in-memory store with semantic + recency retrieval.
Replace `self._store` with a vector DB client (Chroma, Qdrant, FAISS, etc.)
for production use without changing the public interface.
"""
def __init__(self, recency_decay_rate: float = 0.01):
self._store: list[Memory] = []
# λ in the scoring formula — controls how fast recency decays with age
self._decay = recency_decay_rate
def add(
self,
content: str,
memory_type: str = "episodic",
importance: float = 0.5,
tags: list[str] | None = None,
) -> Memory:
"""Embed and store a new memory entry."""
mem = Memory(
content=content,
embedding=embed(content),
memory_type=memory_type,
importance=importance,
tags=tags or [],
)
self._store.append(mem)
return mem
def retrieve(
self,
query: str,
k: int = 5,
memory_type: str | None = None,
alpha: float = 0.7,
) -> list[tuple[Memory, float]]:
"""
Retrieve the top-k memories most relevant to `query`.
Scoring formula:
score = α · cosine_sim(query, memory)
+ (1 − α) · exp(−λ · age_in_hours)
Parameters
------- query : The current user message or task description.
k : Number of memories to return.
memory_type : If set, restrict retrieval to this memory type.
alpha : Weight for semantic similarity (0 = pure recency, 1 = pure semantic).
"""
if not self._store:
return []
candidates = self._store
if memory_type is not None:
candidates = [m for m in candidates if m.memory_type == memory_type]
query_vec = embed(query)
now = datetime.now(timezone.utc)
scored = []
for mem in candidates:
# Semantic score: dot product of unit vectors = cosine similarity
sim = float(np.dot(query_vec, mem.embedding))
# Recency score: exponential decay over age
age_hours = (now - mem.created_at).total_seconds() / 3600.0
recency = float(np.exp(-self._decay * age_hours))
score = alpha * sim + (1.0 - alpha) * recency
scored.append((mem, score))
scored.sort(key=lambda x: x[1], reverse=True)
return scored[:k]
def format_for_context(self, memories: list[tuple[Memory, float]]) -> str:
"""Format retrieved memories as a string ready to inject into the system prompt."""
if not memories:
return ""
lines = ["[Retrieved Memories]"]
for mem, score in memories:
ts = mem.created_at.strftime("%Y-%m-%d %H:%M UTC")
lines.append(
f"- [{mem.memory_type.upper()} | {ts} | score={score:.3f}]: {mem.content}"
)
return "\n".join(lines)With this in place, an agent turn that draws on memory looks like the following. Notice how memory retrieval happens before the LLM call, not after — the retrieved context must land in the prompt.
memory_store = AgentMemory()
# Seed with memories from past sessions
memory_store.add(
"The user prefers Python 3.11 and manages packages with uv.",
memory_type="semantic",
importance=0.9,
)
memory_store.add(
"User asked me to redesign the data pipeline on 2025-04-10. Final design uses DuckDB.",
memory_type="episodic",
importance=0.8,
)
memory_store.add(
"Deployment steps: 1) run tests, 2) build Docker image, 3) push to registry, 4) update Helm chart.",
memory_type="procedural",
importance=0.85,
)
def agent_turn(user_message: str, system_prompt: str) -> str:
"""A single agent turn: retrieve relevant memories, build context, call LLM."""
retrieved = memory_store.retrieve(user_message, k=3)
memory_context = memory_store.format_for_context(retrieved)
full_system = system_prompt
if memory_context:
full_system += f"\n\n{memory_context}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": full_system},
{"role": "user", "content": user_message},
],
temperature=0,
)
return response.choices[0].message.content
answer = agent_turn(
user_message="What do I need to do to deploy my model?",
system_prompt="You are a helpful engineering assistant.",
)
print(answer)When the user asks about deployment, the agent retrieves the deployment procedure from procedural memory and injects it into the system prompt — no hallucination, no reliance on parametric memory for a workflow specific to this team.
When multiple agents collaborate, memory becomes a coordination mechanism as much as a knowledge store. Consider a writer–reviewer–publisher pipeline. The writer drafts content, the reviewer critiques it, and the publisher formats and posts it. All three agents need access to a shared artifact history: what was written, what feedback was given, and what decisions were made.
Three patterns emerge in production systems:
- Shared external memory store. All agents read from and write to the same vector database. Simple and flexible, but it requires careful namespace and tag management to avoid agents overwriting each other’s memories, and conflicts can occur when two agents write about the same entity simultaneously.
- Memory router agent. A dedicated memory agent manages all reads and writes. Other agents send requests (“store this fact” or “retrieve context for task X”) to the memory agent, which handles deduplication, conflict resolution, and access control. This pattern is described in the Cognitive Architectures for Language Agents (CoALA) survey as a “memory controller.”
- Private plus shared namespaces. Each agent has a private memory namespace for its own working state, plus access to a shared namespace for inter-agent communication. Writes to the shared namespace require an explicit “commit” step, which can include a similarity check for near-duplicate entries. This mirrors how version control separates local branches from the main branch.
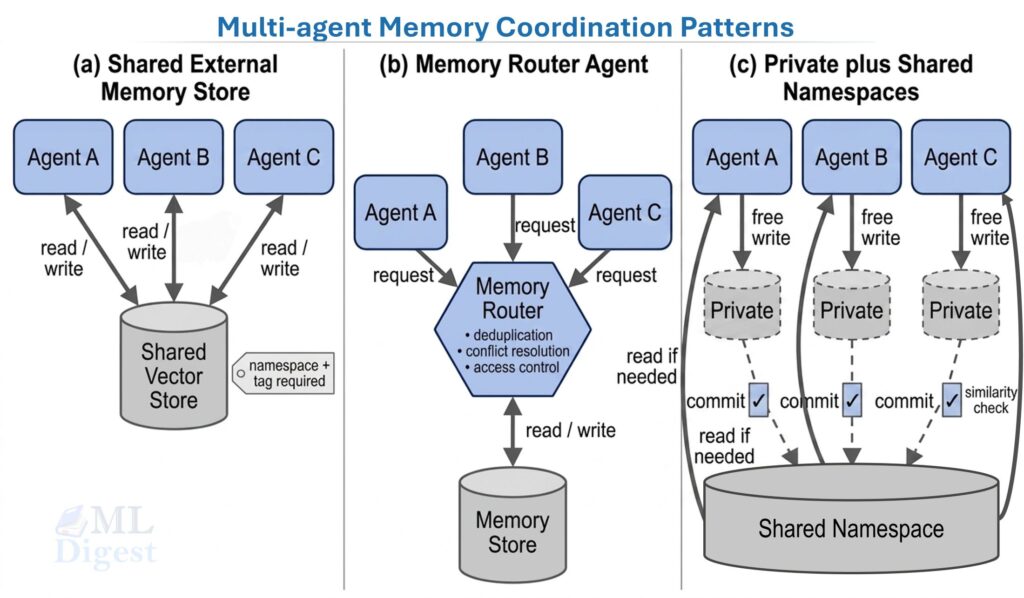
The right pattern depends on task structure. For tightly coupled pipelines where agents build directly on each other’s outputs, a shared store with a dedicated router works well. For loosely coupled systems where agents work largely in parallel, private namespaces with a shared broadcast channel are cleaner and less prone to write conflicts.
For a broader treatment of multi-agent coordination patterns, including manager–worker, critic, and verifier roles, see Multi-Agent Systems (MAS).
9. Practical Tips and Best Practices
9.1 Tag and Type Everything
Every memory should carry metadata: its type (episodic, semantic, procedural), its source (which agent or user created it), its timestamp, and its importance score. Without this metadata, retrieval is blind to structure. Retrieving a procedural memory in response to an episodic query adds noise and dilutes the quality of the injected context. A memory_type filter costs almost nothing at query time and pays a large dividend in retrieval precision.
9.2 Keep Memories Atomic
Long memories are harder to retrieve accurately. A 500-word paragraph storing a complex sequence of events will not embed well because a single vector must represent many distinct ideas. Instead, split compound information into multiple atomic memories, each covering one fact or event. A memory like “We met with the client, discussed the API redesign, decided to use REST over gRPC, and agreed on a Q3 deadline” should become four separate entries. This substantially improves recall at retrieval time.
9.3 Build a Memory Write Policy
Not every agent output should become a memory. Treating every LLM response as a candidate floods the store with low-value content. Define explicit write triggers instead:
- Explicit instruction: The user or a parent agent explicitly says “remember this.”
- Novelty check: Before writing, check whether a semantically similar memory already exists (cosine similarity above $0.95$) and update the existing entry rather than duplicating it.
- Importance threshold: Only write memories above a minimum importance score, computed by asking the model to rate the content.
9.4 Evaluate Memory Retrieval, Not Just Generation
The quality of an agent with memory depends not only on the quality of its LLM but on the quality of its retrieval. A standard evaluation procedure: given a set of seeded conversation histories, create a held-out test set of queries with known “correct” memories, and measure whether the correct entries land in the top-$k$ retrieved results. Track recall@k and mean reciprocal rank (MRR) as first-class metrics alongside generation quality. Retrieval failures cause hallucinations that are extremely difficult to diagnose without explicit retrieval telemetry.
More about Agent evaluation is covered in this post.
9.5 Mind the Injection Point
Where retrieved memories are placed in the context matters. Experiments across multiple systems suggest:
- System prompt injection works best for persistent user facts and personas. Information that should silently shape every response.
- Inline injection, i.e., placing retrieved context directly before the relevant user message, works best for episodic and procedural memories, because it anchors the retrieved content to the specific task at hand and prevents it from being “washed out” by a long conversation that follows.
9.6 Plan for Growth and Pruning
Memory stores grow over time, and retrieval quality degrades as the number of stored entries grows if there is no corresponding pruning strategy. Design for it from the start: implement TTL (time-to-live) for episodic memories, importance-based pruning for low-value entries, and periodic consolidation passes where the agent reviews its own memory and merges near-duplicate entries. The Voyager agent used a skill library that was continuously curated: skills that proved useful were refined, and skills that consistently failed were removed.
10. Putting It All Together
The full memory architecture for a production agent combines all of these layers (in-context, external, parametric), with each layer covering the gaps left by the others.
| Memory Layer | Speed | Capacity | Persistence | Editable? | Best For |
|---|---|---|---|---|---|
| In-context (working) | Instant | Tokens in window | Session only | Yes | Active reasoning, live conversation |
| External – Episodic | ~10–100 ms | Unlimited | Persistent | Yes | Past events, conversation history |
| External – Semantic | ~10–100 ms | Unlimited | Persistent | Yes | Facts, user profiles, knowledge base |
| External – Procedural | ~10–100 ms | Unlimited | Persistent | Yes | Skills, workflows, tool-use patterns |
| Parametric | Instant | Model capacity | Permanent | Requires retraining | General language and world knowledge |
The key discipline in building memory systems is intentionality: deciding deliberately what should be remembered, where it should live, how it should be retrieved, and when it should be forgotten. Memory is not a feature to bolt on after building the agent; it is part of the architecture from the beginning.
A useful mental checklist for any memory design decision:
- What is the expected lifetime of this information? (Session → in-context. Days → episodic. Permanent → semantic or parametric.)
- How specific and updatable does this fact need to be? (Specific and updatable → external. General background → parametric.)
- How will this information be retrieved? (By semantic similarity → vector store. By exact key → key-value store. By keyword → BM25 or full-text index.)
- How should old or stale versions of this information be handled? (Define eviction policy at write time, not after the store is full.)
For a practical guide to deploying the full agentic ecosystem that memory supports — including orchestration, tool integration, and multi-agent coordination — see The Agentic Ecosystem. For an introduction to agent fundamentals and the Observe–Think–Act control loop, see AI Agents and Agentic Systems. The cognitive architecture taxonomy used throughout this article — working, episodic, semantic, and procedural memory — is from the influential CoALA survey.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!