Imagine you have just hired a brilliant consultant. Highly experienced, available around the clock, knowledgeable across dozens of fields. You are thrilled.
On the first day, you ask: “Write me a market analysis.”
After some time, the consultant produces a report. It covers the wrong market segment, assumes a competitive landscape you have already moved past, and targets an audience you have no interest in serving.
You are confused. The consultant is clearly capable. What went wrong?
The answer has nothing to do with their intelligence. You failed to explain the target geography, the customer segment, the decisions this analysis needed to support, the format your leadership team expects, and the three assumptions already baked into your strategy. No amount of rephrasing “Write me a market analysis” would have fixed this. The problem was not communication style. It was a failure of collaboration.
Working with AI is exactly like this.
Most people approach AI as though the only skill that matters is crafting the right prompt. They collect lists of “100 Best ChatGPT Prompts.” They learn to say “Act as an expert in…” or “Think step by step.” They treat prompt engineering as the core discipline.
It is one useful skill inside a much larger practice.
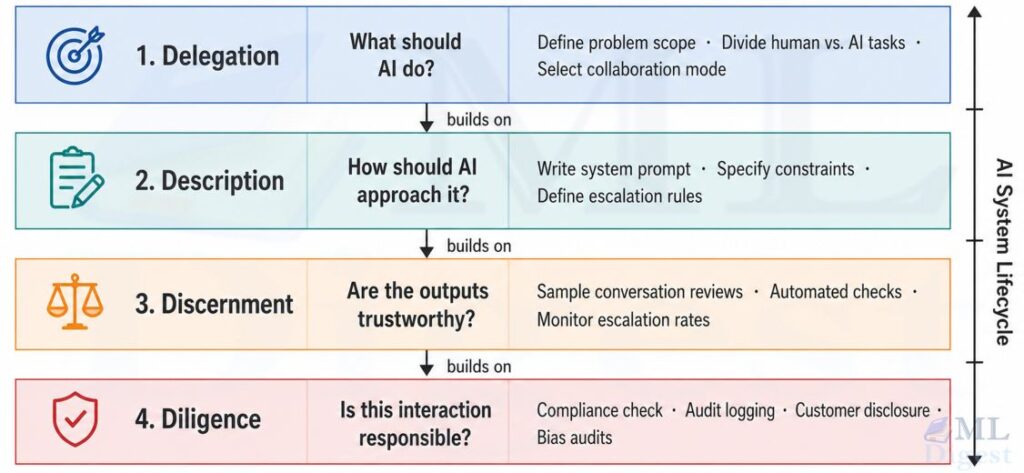
That larger practice is called AI fluency: the ability to collaborate with AI systems effectively, efficiently, ethically, and safely. And the most practical framework for building it is the 4D Framework, which organizes AI fluency into four competencies: Delegation, Description, Discernment, and Diligence.
This article walks through the entire framework. By the end, you will have a mental model that applies equally well to a simple ChatGPT conversation and a fully autonomous AI agent operating inside an enterprise.
What AI Fluency Actually Means
Before exploring the framework, it helps to be precise about what AI fluency is and, more importantly, what it is not.
The AI Fluency Framework defines AI fluency as the ability to work with AI effectively, efficiently, ethically, and safely. Notice what this definition does not require:
- Understanding transformer architectures
- Building or training neural networks
- Writing production Python or knowing anything about GPU memory
- Fine-tuning large language models
Those skills are valuable. They are not prerequisites.
AI fluency is also not synonymous with prompt engineering. That distinction matters because the tools and techniques of prompt engineering will change as AI systems evolve. AI fluency is designed to remain relevant as models improve, interfaces shift, and agentic workflows become mainstream.
to see why a new mental model is needed, consider what makes large language models (LLMs) different from the software you have used before.
Traditional software is usually designed to behave deterministically for a given input and environment. LLMs are probabilistic generative systems. They generate the statistically most plausible continuation of your input based on patterns learned from vast amounts of text during training. This makes them remarkably flexible. The same model can draft emails, explain machine learning concepts, write software, summarize legal documents, and brainstorm product strategy. But it also means they can hallucinate facts, misinterpret instructions, and express incorrect conclusions with complete confidence.
Plausible-sounding output is not the same as correct output. That single distinction changes everything about what it means to use AI well.
Three Modes of Human-AI Collaboration
To appreciate the full scope of AI fluency, it helps to understand the three primary modes through which humans collaborate with AI. These modes exist on a spectrum of autonomy, and real workflows typically blend all three.
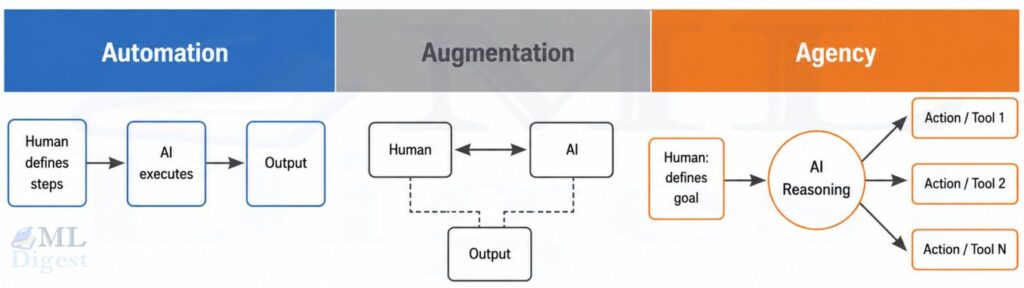
Automation
Automation is the most familiar mode. You define a task. AI executes it within predefined boundaries.
Examples: summarize this document, translate this email, extract structured data from this report, generate image captions.
Think of automation as: Execute this process.
The workflow is human-designed. AI performs specific steps within constraints you specify.
Augmentation
Augmentation transforms AI from a task executor into a thinking partner. Instead of handing off a fully defined task, you explore ideas together, challenge each other’s reasoning, and refine outputs through multiple turns.
Consider designing a cloud architecture. Rather than saying “Design my system,” you engage iteratively: “Compare these two database designs given our traffic patterns.” “What failure modes do you foresee in my current approach?” “Challenge the assumption I just made about consistency requirements.”
AI enhances your thinking rather than replacing it. Think of augmentation as: Let us figure this out together.
Agency
Agency is the most misunderstood of the three modes. Many people assume it simply means advanced automation. It does not.
Agency is goal-oriented autonomy: you specify an objective, and the AI determines how to achieve it, adapting its approach as conditions change. Frameworks like ReAct (Reasoning + Acting) formalize this pattern by interleaving reasoning steps with tool calls to enable goal-directed execution.
Compare these two instructions:
Automation:
Read today’s emails. Summarize them. Send the summary to Slack.Agency:
Keep my inbox manageable. Reply to routine messages, flag important ones, schedule meetings when appropriate, and ask for my approval whenever you are not confident.
In the automation example, every step is pre-specified. In the agency example, AI must continuously decide what qualifies as routine, what is important, when scheduling is appropriate, and when to escalate. The process emerges through reasoning rather than following a fixed script.
| Automation | Agency | |
|---|---|---|
| What you specify | Each workflow step | The objective |
| AI autonomy level | Low | High |
| Adaptation | Fixed sequence | Dynamic planning |
| Human role | Designer of every step | Director of goals |
| Common failure mode | Wrong execution | Misinterpretation of the goal |
In practice, most real-world AI systems blend all three modes. A customer support system might automate FAQ responses, collaborate with an agent to handle edge cases, and operate autonomously for ticket routing. Understanding which mode applies in a given situation is itself a core skill.
The 4D Framework: A Mental Model for Human-AI Collaboration
Regardless of which collaboration mode you are using, effective AI use requires four core competencies. The AI Fluency Framework organizes these into the 4Ds:
- Delegation: Deciding what AI should do
- Description: Communicating how AI should approach the task
- Discernment: Evaluating whether the results are trustworthy
- Diligence: Ensuring the interaction is responsible and ethical
These competencies form a continuous operating loop rather than a linear sequence.
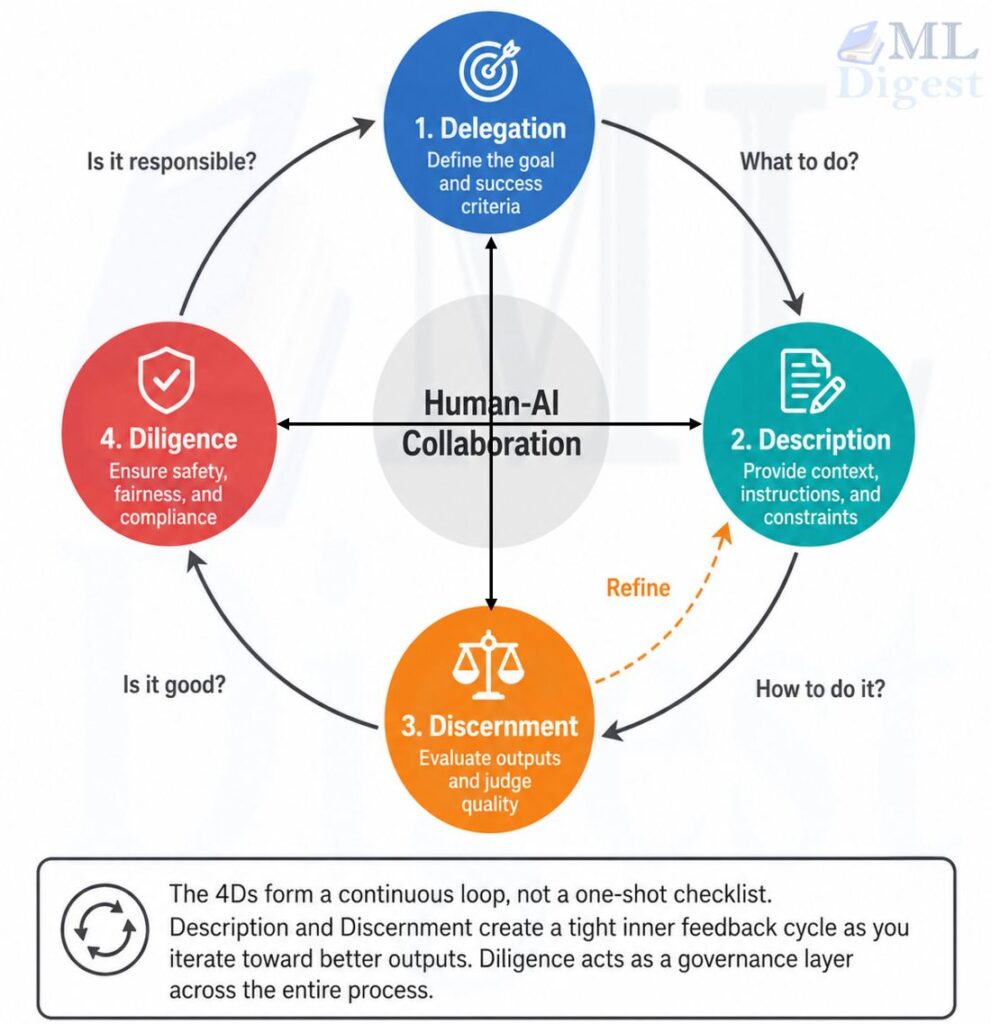
AI performs the work. Humans manage the collaboration.
Let us now examine each competency in depth.
1. Delegation: Deciding What AI Should Do
If description teaches you how to talk to AI, delegation teaches you whether AI or agents should be involved at all and which parts of the work it should handle.
Most people skip this step. They open a chat window and start typing before they have a clear picture of what they actually need.
Fluent AI users pause first and ask:
“Which parts of this problem require my expertise and judgment, and which parts can AI handle more efficiently?”
This single question often determines whether AI becomes a force multiplier or a source of wasted effort and rework.
The framework describes delegation as understanding what work needs to be done, what must remain human, and what can be assigned to AI through automation, augmentation, or agency. Crucially, good delegation begins not with AI but with a clear understanding of the problem itself.
The best AI collaborators are domain experts first and AI delegators second. AI accelerates expertise. It rarely replaces it.
1.1 Problem Awareness
Delegation begins before you open an AI assistant. It begins with clearly defining the problem you are solving.
Consider building a fraud detection system for a bank. An inexperienced practitioner might prompt: “Design a fraud detection system.” AI will produce an architecture. But experienced engineers know this skips the hardest step: problem definition.
What type of fraud? Real-time or batch processing? What are the regulatory constraints? What is the tolerance for false positives? What existing infrastructure must be integrated? What latency is acceptable? What budget is available?
These questions have nothing to do with AI. They are domain questions. They must be answered before any AI interaction begins.
A useful habit is to decompose work before delegating any of it. Consider a literature review — before sending a single prompt, map out the actual work and decide where human versus AI contributions belong:
| Task | Owner | Rationale |
|---|---|---|
| Define research question | Human | Requires domain judgment |
| Search relevant papers | AI | Can use tools at scale |
| Summarize individual papers | AI + Human | AI drafts, human validates |
| Compare methodologies | AI + Human | AI identifies patterns, human evaluates |
| Identify research gaps | Human | Requires deep field knowledge |
| Draw conclusions | Human | Accountability stays with the researcher |
| Write the final report | AI + Human | AI drafts, human edits and finalizes |
Running this before writing any prompt forces you to think clearly about which tasks require your expertise and which ones AI can legitimately accelerate. That clarity often turns a frustrating AI interaction into a productive one.
AI cannot define your business objectives for you. It can help you execute once those objectives are clear. Problem awareness is what creates that clarity.
1.2 Platform Awareness
Not all AI systems are equivalent. One of the most common mistakes newcomers make is assuming that a single model excels at every task.
Today’s AI ecosystem spans reasoning-focused models, coding assistants, image generators, search-augmented research tools such as Perplexity, retrieval-augmented generation (RAG) enterprise assistants, and autonomous agents. Each has distinct strengths, context window limitations, supported modalities, and intended use cases.
| Task | Recommended Capability |
|---|---|
| Complex software development | Code-specialized LLM |
| Creative image generation | Diffusion model (e.g., DALL-E, Midjourney) |
| Scientific literature search | Search-augmented LLM (e.g., Perplexity) |
| Enterprise knowledge retrieval | RAG-based copilot |
| Long document reasoning | Large-context reasoning model |
| Multi-step autonomous tasks | Agent-capable system |
Selecting the right AI for a task is increasingly a professional skill, comparable to selecting the right cloud service for a given workload. Five years ago, engineers chose libraries and frameworks. Today, they also choose AI systems. Questions now include: Should I use a reasoning model? Should this use retrieval? Should it run locally or in the cloud? Does this task require tool use?
1.3 Task Delegation
Once you understand the problem and the available AI capabilities, you can divide the work intelligently.
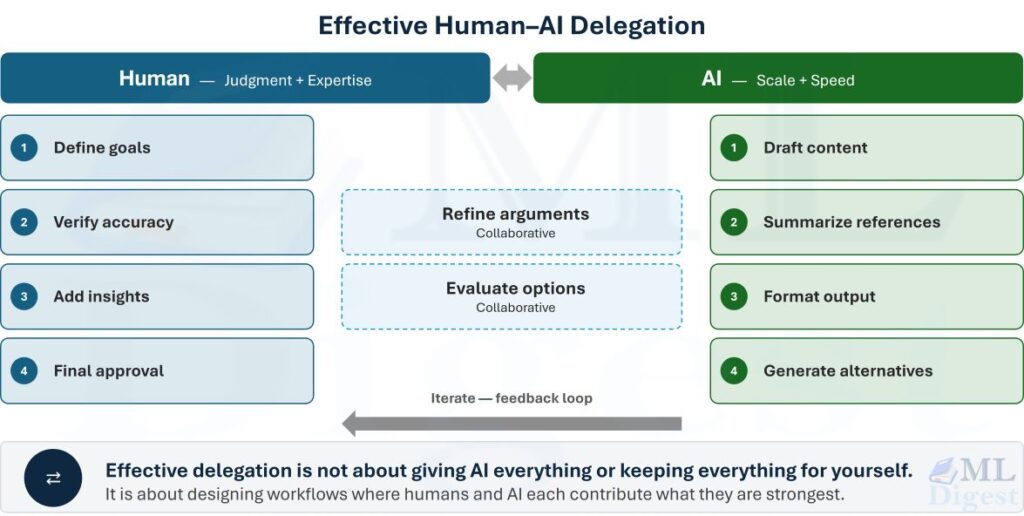
Consider writing a technical book. Rather than asking AI to write the entire thing (which typically produces generic, shallow content), a fluent workflow divides responsibilities deliberately:
| Human Responsibilities | AI Responsibilities |
|---|---|
| Define the audience and objectives | Brainstorm chapter ideas and titles |
| Decide the overall structure | Expand section outlines into draft prose |
| Verify all technical accuracy | Summarize and synthesize reference materials |
| Add personal insights and stories | Improve grammar, flow, and clarity |
| Final editorial review and approval | Suggest alternative phrasings |
The human retains judgment, domain expertise, creative direction, and accountability. AI handles repetition, first drafts, formatting, and information organization. This is delegation as workflow design, not task offloading.
Think of it the way a software architect thinks about system design. Architects rarely spend most of their time writing code. They define system boundaries, component responsibilities, communication interfaces, and ownership. Delegation plays the same role in AI collaboration: it is the architecture of the human-AI partnership.
2. Description: Beyond Prompt Engineering to Context Engineering
If delegation determines what AI should work on, description determines how AI understands and approaches that work.
This is the competency most people conflate with prompt engineering. And while prompting techniques such as chain-of-thought prompting, few-shot examples, and role assignment fall within description, they represent only one layer of a much richer skill.
The AI Fluency Framework defines description broadly: it is the discipline of communicating your intent, context, expectations, and constraints to AI throughout the entire collaboration, not just in a single opening message. Think of it less as writing prompts and more as building the thinking environment in which both you and the AI do your best work.
Here is the analogy that makes this click. Imagine onboarding a new team member to a complex project. You would not say “build the dashboard” and walk away. You would explain the business context, the users, the existing codebase conventions, the performance constraints, and the design principles. The more context they receive, the better they perform. AI is no different, except that it cannot infer unstated background knowledge. Everything relevant must be communicated explicitly.
AI cannot read your mind. Unless context is stated, AI must infer it. Sometimes those inferences are correct. Sometimes they produce confidently wrong outputs.
The framework divides description into three complementary dimensions: product description, process description, and performance description.
2.1 Product Description
Product description defines the desired output. Think of it as writing a specification.
Compare these two approaches to the same task:
Vague:
Summarize this report.
Specified:
Summarize this quarterly financial report for senior executives who have 10 minutes to read it.
Focus on: business risks, key revenue trends, and strategic recommendations.
Format: bullet points, maximum one page.
Highlight any figures that differ significantly from last quarter.
Avoid technical financial jargon.
The habit of explicitly specifying audience, format, priorities, constraints, and exclusions before sending any prompt consistently produces more useful outputs than any clever prompt phrasing.
2.2 Process Description
Beyond specifying what you want, experienced AI users frequently specify how AI should reason to get there.
Suppose you are using AI as a mathematics tutor. You do not want it to simply hand you answers. You want it to guide your thinking:
tutoring_process_prompt = """
You are tutoring me through this problem. Follow this process exactly.
1. If anything in my question is ambiguous, ask one clarifying question first.
Do not proceed until I answer it.
2. Break the problem into numbered steps. Show me only the first step.
3. Wait for my attempt before revealing whether I am correct.
4. If my attempt is wrong, give one targeted hint rather than the solution.
5. Only reveal the full solution after I have worked through each step myself.
Your goal is to build my understanding, not to solve the problem for me.
"""The desired output has not changed. The process has. This matters because different processes produce very different learning outcomes.
Similarly, when requesting a code review, specifying an evaluation sequence prevents important feedback from being buried:
code_review_process = """
Review this Python function in the following order.
For each category, state: OK / Needs Improvement / Critical Issue,
followed by a brief explanation.
1. Correctness: Does it behave as the docstring describes?
2. Security: Are there input validation gaps or injection risks?
3. Performance: Are there obvious algorithmic inefficiencies?
4. Readability: Would a junior engineer understand this in 60 seconds?
Do not suggest style changes unless they meaningfully affect readability.
End with a one-sentence overall assessment.
"""Process description is most powerful in iterative, high-judgment workflows: code review, mathematical derivation, architectural design, legal analysis, and strategic planning.
2.3 Performance Description
Performance description defines what kind of collaborator you want AI to be during the interaction itself. Not what it should produce, not how it should reason, but how it should behave toward you.
collaboration_behavior = """
During our conversation, please observe these behaviors:
- Challenge my assumptions when you believe I am reasoning incorrectly.
- Ask one clarifying question before answering if my request is ambiguous.
- Keep responses under 200 words unless I explicitly ask for more detail.
- When you are uncertain about a factual claim, mark it as uncertain.
- Do not revise your recommendation simply because I push back on it.
Only update your position if I provide new information or a better argument.
- If you suspect I am solving the wrong problem, say so before answering.
"""This set of instructions changes the character of the interaction. AI systems have a well-documented tendency toward excessive agreeableness: they validate what users say, shift positions under social pressure, and rarely volunteer disagreement. Explicitly instructing AI to challenge you produces a significantly more useful thinking partner, especially for creative or strategic work.
2.4 From Prompt Engineering to Context Engineering
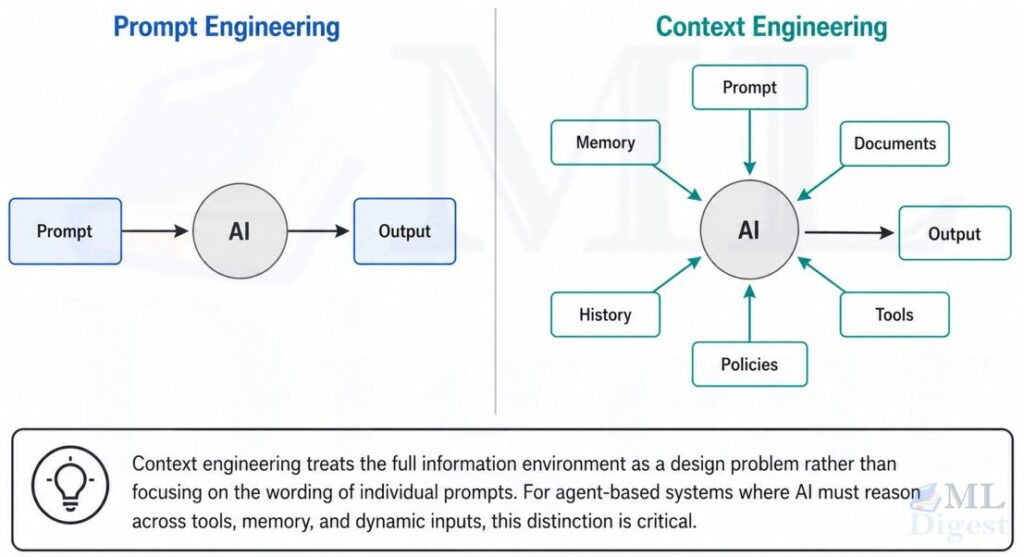
One of the most consequential shifts in modern AI practice is the move from prompt engineering to context engineering.
Prompt engineering focuses on the wording of individual messages: how do I phrase this instruction more effectively?
Context engineering focuses on the entire information environment AI reasons within: what does AI need in order to perform this task well?
In production settings, this often means externalizing prompts, policies, and reusable instructions rather than hiding them inside a single message, which is why prompt development, externalization, and management becomes an operational concern rather than just a writing trick.
| Prompt Engineering | Context Engineering |
|---|---|
| Wording of a single message | Full reasoning environment |
| “How should I phrase this?” | “What does AI need to succeed?” |
| A single instruction | Documents, memory, tools, history, policies, examples |
| Fits inside one prompt | Spans the entire system design |
For AI agents in particular, context engineering is far more important than prompt wording. An agent with well-structured context and mediocre prompt phrasing will typically outperform one with beautifully crafted prompts but poor information. In practice, that also means designing memory in agentic systems carefully so the model receives the right history and state at the right time.
Description is also inherently iterative. Professional AI users rarely achieve their goal in a single exchange. They iterate: describe, review, refine, describe again. Each iteration narrows the gap between what AI produced and what was actually needed.
3. Discernment: Critical Thinking as a Core Competency
Even with excellent delegation and clear description, AI will sometimes fail. It will hallucinate facts, misinterpret instructions, and express incorrect conclusions with total confidence.
This creates what researchers call automation bias: the tendency to over-trust automated systems. In practice, people often give confident computer-generated answers more weight than they deserve, especially when the system presents them without visible hesitation or uncertainty.
Discernment is the antidote. The AI Fluency Framework defines it as the ability to evaluate AI outputs, reasoning processes, and interactive behavior. It serves as the quality control system for human-AI collaboration.
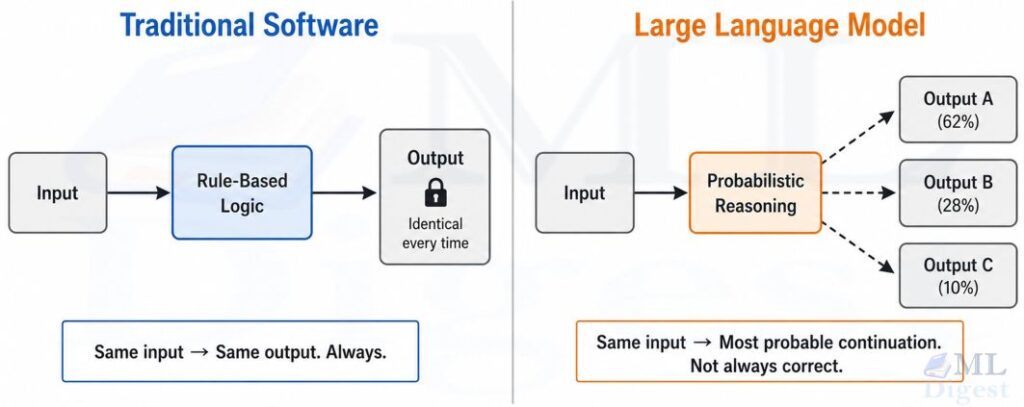
Why AI Makes Mistakes
To evaluate AI well, it helps to understand why it fails. LLMs generate the statistically most probable continuation of your input. They do not retrieve facts from a verified database. This means the same model can accurately recall information, accurately generalize from related patterns, and also generate plausible-sounding but completely fabricated content, all with identical confidence. Additionally, every model has a fixed training data cutoff: it has no awareness of events, publications, or updates that occurred after training concluded unless it is paired with a retrieval tool.
Every output from an LLM should be treated as an informed recommendation, not as verified fact.
3.1 Product Discernment
Product discernment is the most familiar form of evaluation: examining the final output for accuracy, completeness, and fitness for purpose.
Different domains require different evaluation criteria. This is why discernment amplifies domain expertise rather than replacing it. Regardless of domain, five questions anchor a thorough evaluation:
| Criterion | Question to ask |
|---|---|
| Factual accuracy | Are all claims verifiable against authoritative sources? |
| Completeness | Does the output address every stated requirement? |
| Internal coherence | Is the reasoning consistent throughout, without contradictions? |
| Domain validity | Would a subject-matter expert find this credible under scrutiny? |
| Accountability | Would you confidently put your name on this output? |
A journalist asks whether every cited source exists and accurately represents what AI claims. A physician asks whether the recommendation aligns with clinical guidelines and whether it could harm the patient. A software engineer asks whether the algorithm introduces security vulnerabilities or race conditions. The better your domain expertise, the more precise your evaluation.
3.2 Process Discernment
Sometimes the final answer appears reasonable while the reasoning that produced it is flawed.
Consider a mathematical derivation where AI makes an invalid logical assumption midway through but arrives at the numerically correct answer due to compensating errors. The output passes product discernment. The reasoning fails process discernment.
This matters especially because you will likely apply the same reasoning pattern to future problems where the compensating errors will not occur.
Beginners ask: “Is this answer correct?”
Experts ask: “Does this reasoning make sense?”
A practical technique is to ask AI for an explicit rationale before you act on its conclusion:
rationale_review_request = """
Before giving your final recommendation, explain your rationale in a reviewable way.
For each step:
1. State the assumption you are relying on.
2. Explain why you believe that assumption is valid in this context.
3. State the conclusion that follows from it.
After completing all steps, state your final recommendation clearly.
I need enough justification to evaluate your recommendation, not just the conclusion.
"""If a step contains an unsupported assumption or a logical leap, you can identify it before acting on the conclusion. The key point is to inspect a model’s stated justification, not to assume you are seeing its hidden internal reasoning in full. This discipline is especially important in high-stakes domains: security analysis, financial modeling, clinical decision support, and legal review.
3.3 Performance Discernment
Performance discernment evaluates the quality of the collaboration itself, independent of any specific output.
Imagine using AI as a long-term design partner across multiple sessions. After a while, you notice a pattern: AI never challenges your proposals, consistently validates your ideas regardless of their merit, and occasionally reintroduces design decisions you explicitly rejected in earlier conversations.
Individual responses might still pass product and process evaluation. But the collaboration is subtly degrading the quality of your work by reinforcing your existing assumptions rather than pressure-testing them.
Performance discernment asks:
- Is AI adapting to my feedback across the conversation?
- Is it challenging my reasoning when appropriate?
- Does it ask useful questions or does it just produce answers?
- Is this interaction producing better work than I would produce alone?
- Should I change my Description to improve the collaborative dynamic?
3.4 The Description-Discernment Feedback Loop
The most elegant structural insight in the 4D Framework is that description and discernment are inseparable. Description tells AI what you want and how you want it to work. Discernment evaluates what you received. That evaluation then improves your next description.
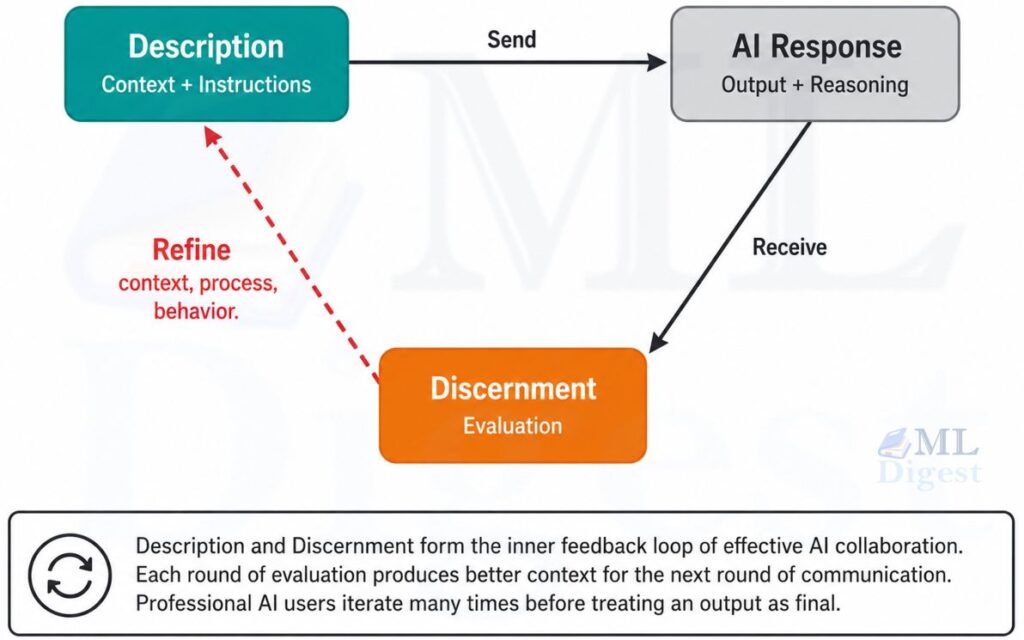
Professional AI collaboration rarely succeeds in a single exchange. It converges through iteration. Each round narrows the gap between what AI produced and what you actually needed.
4. Diligence: The Responsibility That Comes with AI
Even if you delegate thoughtfully, describe clearly, and evaluate carefully, there is a fourth question that must be answered before any AI output reaches the real world: Should this AI interaction happen this way in the first place?
This is what separates responsible AI practitioners from merely productive ones.
Imagine you use AI to draft a performance review for a direct report. The writing is polished, the feedback is clear, and it reads exactly like something you would say. Everything looks good.
Then you realize you pasted the employee’s personal details and salary history into a consumer AI tool not approved for sensitive data, and the employee was never told that AI played any role in writing their review.
Technically excellent. Professionally and ethically disastrous.
Diligence evaluates not the quality of AI’s outputs but the appropriateness, transparency, and accountability of the entire AI interaction. While the other three competencies focus on effectiveness, diligence broadens the scope to include organizational, societal, and personal responsibilities. In operational terms, this is where guardrails for LLMs and broader principles for responsible AI start to matter.
The framework divides diligence into three complementary dimensions: creation diligence, transparency diligence, and deployment diligence.
4.1 Creation Diligence
Creation diligence occurs before AI generates anything. It asks whether you are using the right AI system, with the right data, in the right context. Three areas deserve a check before you send a single prompt:
Data sensitivity
- Does this prompt contain personally identifiable information (PII)?
- Does it contain confidential business data or trade secrets?
- Could this data be retained by the provider for model training?
Policy compliance
- Is this AI service approved by my organization?
- Does this use case comply with applicable laws and regulations?
- Have I checked the relevant data processing agreements?
Model selection
- Is this the most appropriate model for this specific task?
- Do I understand its known failure modes and biases?
- Does it meet the privacy and performance requirements of this context?
The fastest solution, which in a healthcare context might mean copying production patient data directly into a prompt, is frequently not the responsible one. Creation diligence, informed by sound privacy practices in AI, slows you down just enough to prevent the category of mistake that ends careers and destroys organizational trust.
4.2 Transparency Diligence
Transparency diligence asks: should other people know that AI contributed to this work?
The answer depends on context and stakes. Using AI to brainstorm a meeting agenda requires little disclosure. Using AI to draft a performance evaluation, generate a legal brief, produce academic work, or make recommendations that affect other people’s lives almost certainly requires transparency.
Transparency is fundamentally about trust. People deserve to know when AI played a material role in decisions that affect them.
Consider two versions of the same report attribution:
Version A:
Prepared by: [Author Name]
Version B:
Prepared by: [Author Name]
Note: Initial draft and data synthesis were AI-assisted. All analysis, conclusions, and recommendations were reviewed, validated, and revised by the author.Version B is not a confession of weakness. In most professional contexts, it is actually more credible. It demonstrates both technical competency and intellectual honesty. Transparency often strengthens trust rather than undermining it.
4.3 Deployment Diligence
Deployment diligence is the final gate before AI-assisted work enters the real world. It asks one question that encompasses everything else: Would you confidently put your name on this?
If the answer is no, it should not be published, submitted, or acted upon.
Deployment diligence includes fact-checking all claims AI made, verifying that cited sources exist and are accurately represented, reviewing for demographic bias in recommendations, checking for copyright or intellectual property concerns, confirming security and regulatory compliance, and ensuring organizational policies were followed throughout. For systems that consume untrusted external content, it also means defending against failures such as prompt injection.
The framework is emphatic on a point that is easy to overlook: accountability cannot be delegated to AI. If an autonomous AI agent approves a loan that later proves discriminatory, the organization is accountable. If a coding assistant introduces a critical security vulnerability, the engineer is responsible. AI automates work. It does not automate moral or professional responsibility for outcomes.
The 4Ds in Practice: A Complete Example
Let us trace the full framework through one practical scenario: building an AI-powered customer support assistant for a software company.
Delegation
Before any AI interaction, the team defines the division of work:
- AI handles: FAQ responses, documentation lookup, first-draft replies to common queries
- Humans handle: refund approvals above a threshold, account disputes, legal escalations
- AI agents route: incoming tickets to the appropriate queue based on category and urgency
Description
The team writes a system prompt encoding all relevant context:
system_prompt = """
You are a customer support assistant.
Your role:
- Answer questions about our products using only the provided documentation.
- Write replies in a professional, empathetic tone at a grade-10 reading level.
- If a question falls outside your knowledge base, say so clearly
and offer to connect the customer with a human specialist.
Escalate to a human agent when:
- The customer mentions legal action or regulatory complaints.
- A refund request exceeds $500.
- The customer requests account termination.
- You are not confident in your answer.
You must NOT:
- Make commitments about unreleased features.
- Access or discuss payment card details.
- Speak negatively about competing products.
When uncertain, use this exact phrase:
'Let me connect you with a specialist who can help you with that.'
"""Discernment
The team establishes ongoing evaluation processes:
- Automated checks for responses that contradict the product documentation
- Human sampling of 5% of conversations for quality review
- Monitoring of escalation rate (too low may indicate AI is not recognizing edge cases correctly)
- Customer satisfaction scores correlated with response type and agent
At scale, these checks grow into a formal agentic system evaluation practice rather than an ad hoc review habit.
Diligence
The team ensures responsible deployment:
- Customer data remains within approved, compliant infrastructure
- All AI interactions are logged for audit purposes
- Customers are informed at the start of each conversation that they are interacting with AI
- A human review process exists for any policy violations flagged by monitoring
- Quarterly bias audits on routing decisions and response quality across customer segments
All four competencies span the full lifecycle, from initial planning through ongoing production operation.
Common Mistakes in AI Collaboration
Certain failure patterns appear consistently as more people begin working with AI in professional contexts.
Delegating before defining the problem. Opening an AI chat before you understand what you are actually trying to accomplish almost guarantees poor results and wasted iteration. Spend five minutes on clear problem definition first. It saves hours of frustrating back-and-forth.
Treating description as a one-shot prompt. Professional AI collaboration is iterative. The first response is rarely the final answer. Plan for multiple rounds of description and refinement rather than expecting a single prompt to produce polished, production-ready work.
Accepting plausible outputs without evaluation. AI is optimized to produce fluent, confident, and plausible text. Plausible is not the same as correct, complete, or appropriate. Domain expertise remains irreplaceable for meaningful evaluation.
Ignoring governance until something goes wrong. Diligence is not a post-incident checklist. It is a pre-flight requirement. Build privacy reviews, compliance checks, and transparency practices into your workflow from the beginning, before the first prompt is sent.
Final Thoughts
When personal computers became widely accessible in the 1980s, “computer literacy” became a valued professional skill. When the web reshaped commerce and communication in the 1990s and 2000s, “digital literacy” became essential. We are now in the early stages of a similar transition with AI.
Like earlier forms of literacy, AI fluency is not about mastering a particular tool. Today’s leading models will be surpassed. Prompting techniques will evolve. New architectures, interfaces, and agentic systems will emerge. What will endure are the human capabilities that make intelligent collaboration possible regardless of which AI system sits on the other side of the conversation.
The 4D Framework captures those enduring capabilities:
- Delegation teaches you to think before you automate, and to design workflows rather than offload tasks.
- Description teaches you to communicate with depth and context, not just with clever phrasing.
- Discernment reminds you that critical thinking cannot be outsourced, no matter how confident the AI sounds.
- Diligence ensures that productivity never comes at the expense of responsibility, transparency, or accountability.
Together, these competencies shift your focus away from mastering prompts and toward mastering the human side of human-AI collaboration.
The professionals who thrive in this environment will not necessarily be those who can write the most sophisticated prompts or build the most advanced models. They will be those who know how to orchestrate human judgment and machine intelligence into a single, effective partnership.
As AI systems become increasingly autonomous, planning multi-step tasks, invoking tools, coordinating with other agents via multi-agent systems, and taking actions on our behalf, the importance of the 4D Framework grows rather than diminishes. The more autonomously AI operates, the more critical it becomes that the humans directing it are fluent in delegation, communication, evaluation, and responsibility. Readers who want to go deeper on multi-agent coordination and workflow design can continue with agentic ecosystems and single-agent architecture patterns.
The future does not belong to people who simply use AI. It belongs to people who know how to collaborate with it.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!