SentencePiece is a language-independent subword tokenizer and detokenizer introduced by Google for neural text processing. Its open-source library is widely used in NLP systems that need a fixed-size vocabulary without relying on language-specific pre-tokenization.
Instead of splitting text into words first, SentencePiece treats the input as a raw sequence of Unicode characters and learns how to segment it into subword units. That design makes it useful for handling rare words, morphologically rich languages, and languages such as Chinese or Japanese where whitespace is not a reliable word boundary.
At a high level, SentencePiece helps reduce problems caused by out-of-vocabulary (OOV) tokens while still preserving recurring word fragments that are meaningful for downstream models.
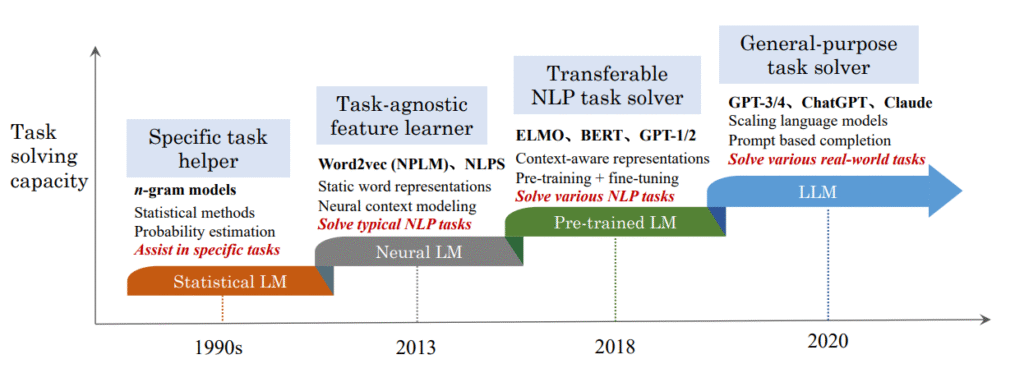
Why SentencePiece Matters
Traditional word-level tokenization creates a tradeoff. A very large vocabulary is expensive to train and serve, while a small vocabulary produces too many unknown words. Character-level tokenization avoids unknown words, but sequences become longer and often harder for the model to learn from efficiently.
SentencePiece sits between those extremes. It breaks text into subword pieces, which allows common words to remain compact while rare words can still be represented as smaller units. This makes it especially useful for neural machine translation, language modeling, and modern transformer-based pipelines.
How SentencePiece Works
SentencePiece supports multiple segmentation strategies, most notably byte-pair encoding (BPE) and the unigram language model. In practice, the tokenizer is trained on a corpus and learns a vocabulary of subword pieces that can be used consistently for both encoding and decoding.
Several design choices distinguish SentencePiece from older tokenization pipelines:
Fixed vocabulary size: SentencePiece trains toward a target vocabulary size such as 8k, 16k, or 32k. This is different from tools like subword-nmt, where the main control for BPE is the number of merge operations rather than the final vocabulary size.
Training from raw text: SentencePiece does not require whitespace tokenization or language-specific preprocessing before training. It can learn directly from raw sentences, which simplifies multilingual pipelines and makes it useful for scripts without explicit word boundaries.
Reversible tokenization: SentencePiece treats whitespace as a normal symbol by escaping it with the meta-symbol ▁ (U+2581). For example, a token such as ▁This indicates that the piece begins after a space. Because whitespace information is preserved, detokenization can reconstruct the original text without relying on external rules.
Subword regularization: SentencePiece also supports subword regularization and BPE-dropout. These methods sample alternative segmentations during training, which can improve robustness by exposing the model to multiple valid ways of splitting the same sentence.
SentencePiece vs Traditional Tokenizers
What makes SentencePiece particularly practical is that it combines tokenization and detokenization into a single learned system. Many older approaches assume that tokenization happens after language-specific preprocessing. SentencePiece moves that logic into the model itself.
This has three important consequences:
- The same tokenizer can be applied across many languages with fewer special rules.
- The vocabulary size is controlled directly, which aligns well with how neural models are configured.
- The encoded representation remains reversible, so preprocessing and postprocessing become simpler.
Implementation
SentencePiece provides C++ and Python interfaces, and the Python package is the easiest entry point for most NLP workflows.
# Installation
pip install sentencepieceTraining Example
The example below trains a tokenizer on a raw text corpus. By default, SentencePiece trains a unigram model unless a different model_type is specified.
import sentencepiece as spm
# Training SentencePiece model
spm.SentencePieceTrainer.Train('--input=data.txt --model_prefix=m --vocab_size=32000')This command reads data.txt and produces m.model and m.vocab. The learned model can then be reused to encode raw text into token IDs or into human-readable subword pieces.
Tokenization Example
Once the model is trained, it can be loaded to encode and decode text.
# Loading the model
sp = spm.SentencePieceProcessor(model_file='m.model')
# Encode and decode example
encoded = sp.encode('This is a test')
decoded = sp.decode(encoded)
tokens = sp.encode('This is a test', out_type=str)
print("Encoded:", encoded) # Output: [284, 47, 11, 4, 15, 400]
print("Decoded:", decoded) # Output: "This is a test"
print("Tokens:", tokens) # Output: ['▁This', '▁is', '▁a', '▁', 't', 'est']The output highlights an important detail of SentencePiece tokenization: pieces often include the leading whitespace marker ▁, which helps preserve the original spacing when text is decoded.
Closing Thoughts
SentencePiece is more than a convenience library. It is a practical tokenization framework designed for modern neural text systems, where fixed vocabularies, multilingual support, and reversible preprocessing matter. Its support for raw-text training, BPE and unigram segmentation, and stochastic subword sampling has made it a standard choice in many NLP and LLM training pipelines.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!