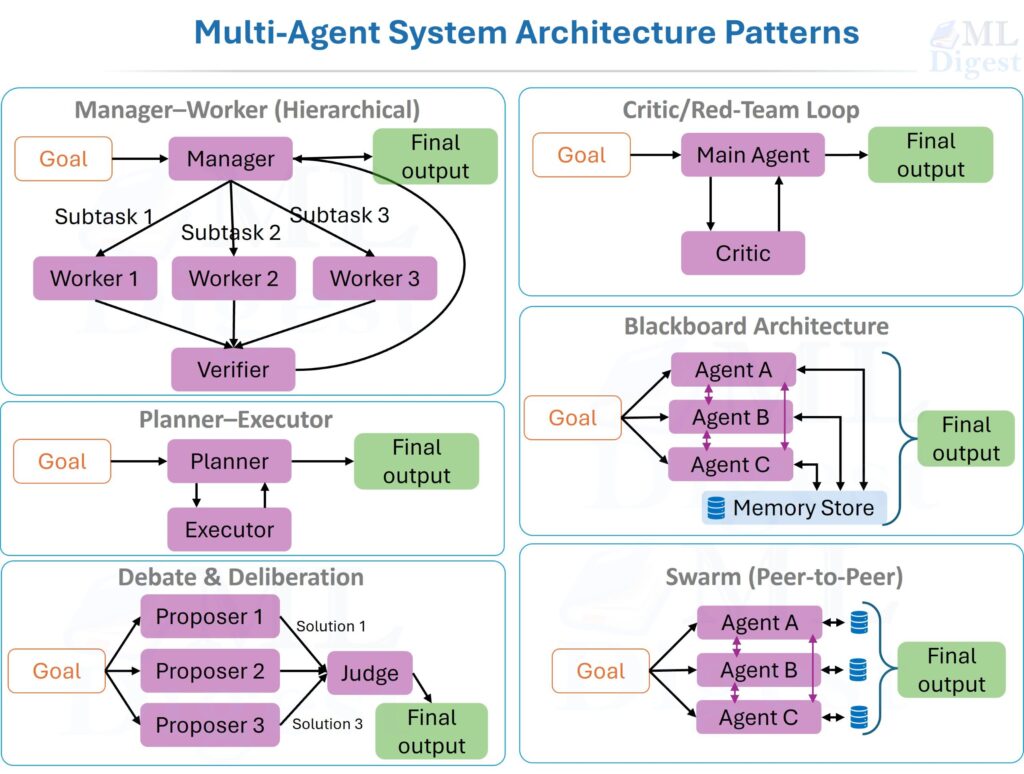
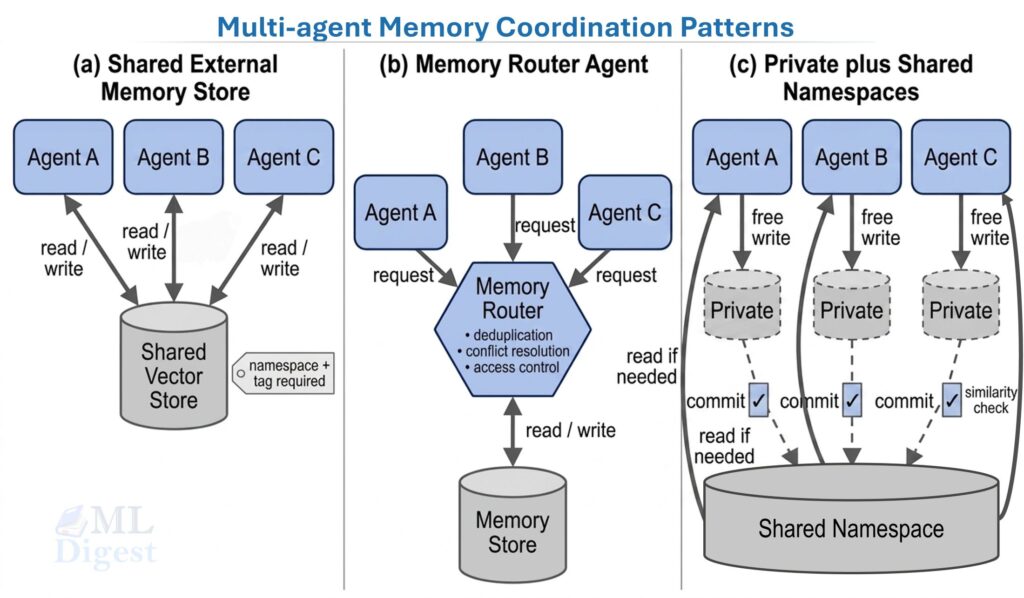
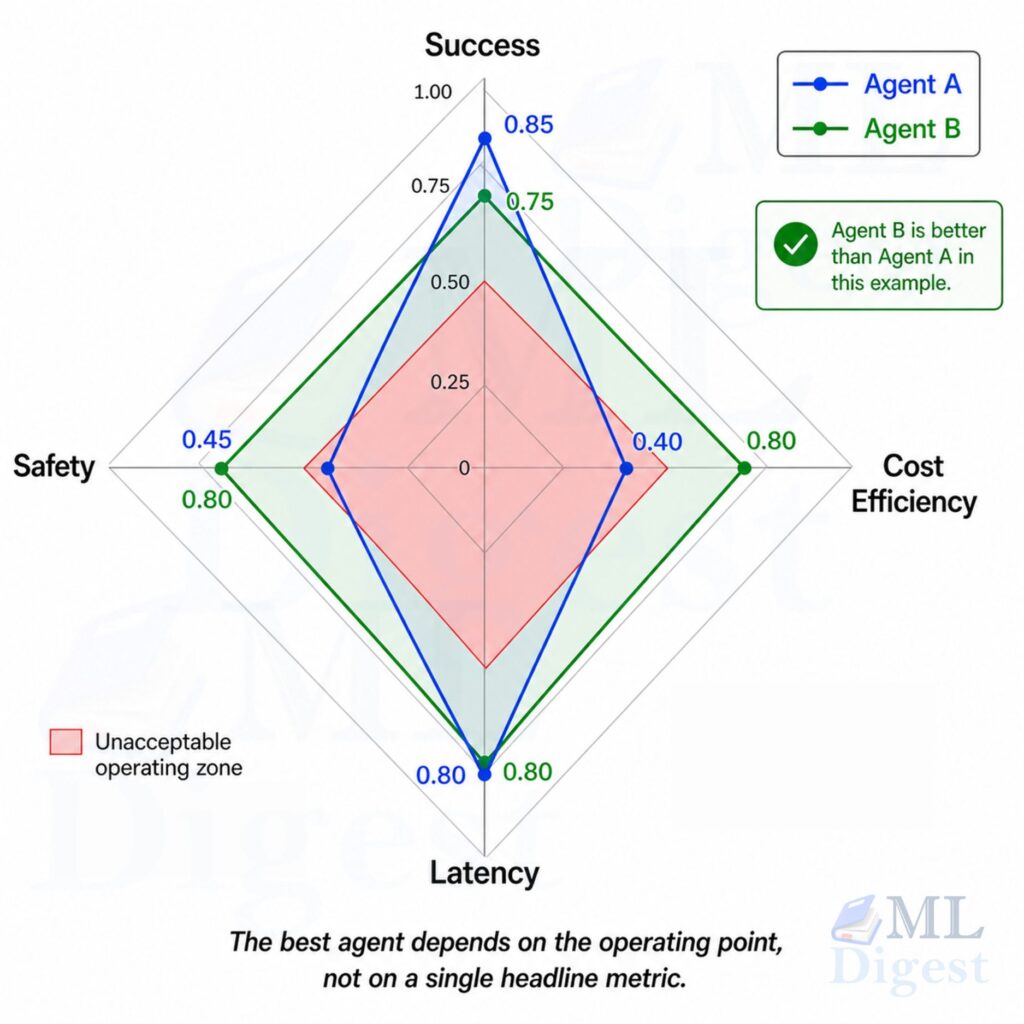
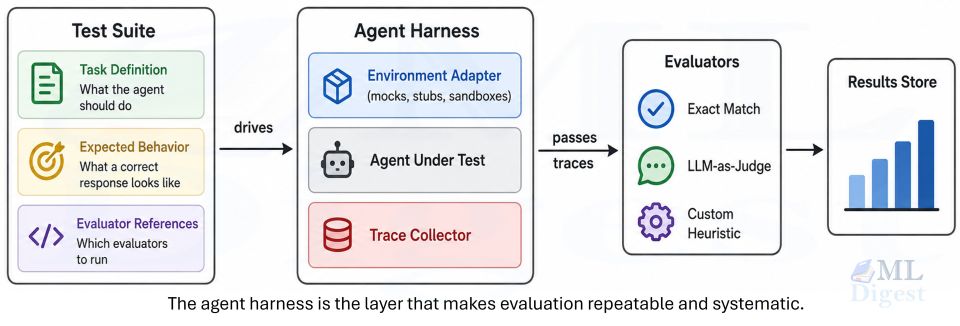
AI agents are often used where a script, workflow, or simpler model would do the job better. If the task is deterministic, tightly constrained, or high risk, adding an agent usually increases cost and variance without adding real capability.
This article makes that boundary concrete. It explains when agents are the wrong abstraction and how to recognize when a simpler system is the better design.
1. What an AI Agent Actually Is
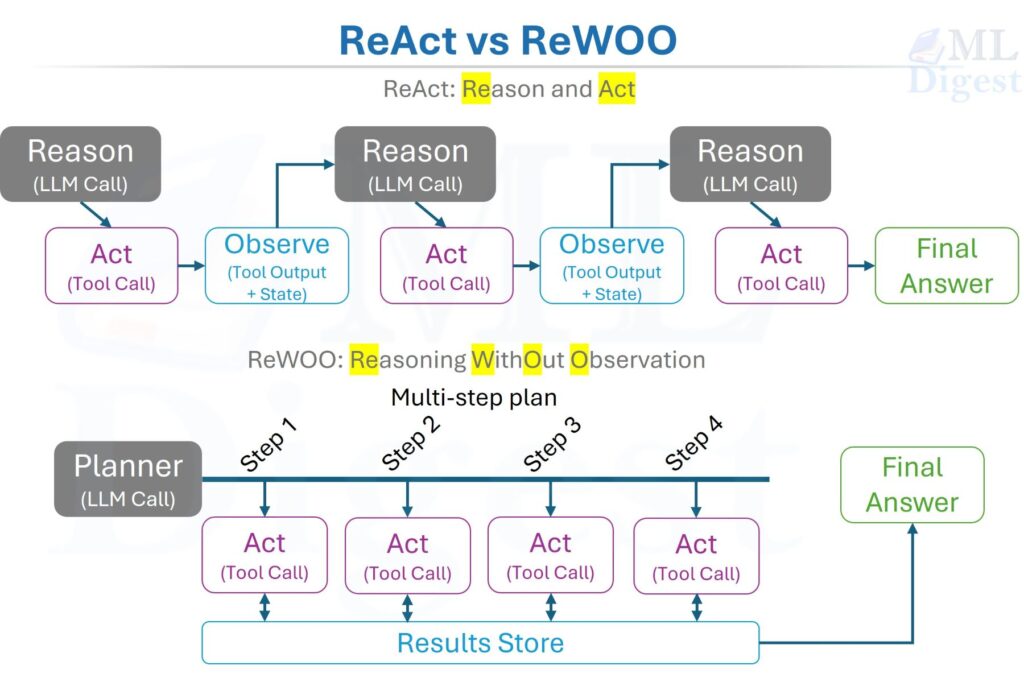
The term “agent” is often used loosely. A modern AI agent is usually a language model wrapped in a control loop, often following a ReAct-style pattern: it observes context, reasons about the next step, chooses a tool or action, inspects the result, and continues until it reaches a stopping condition.
That is very different from:
- a plain chatbot that answers once
- a retrieval system that fetches documents but does not act
- a deterministic workflow that always follows the same graph (like a script that calls one or two APIs in a fixed order)
This distinction matters because agents introduce three things at once:
- probabilistic decision-making
- larger action surfaces through tools and memory
- longer error chains, where one bad step can pollute the next five
If your problem does not need those extra degrees of freedom, an agent is usually the wrong abstraction.
2. The Simple Rule of Thumb
You should not use an AI agent when a cheaper, simpler, and more controllable system can solve the problem with similar quality.
That rule sounds obvious, but it is easy to ignore because agent demos are persuasive. They look flexible, and flexibility feels powerful. However, flexibility is not free. Every extra degree of freedom increases one or more of the following:
- latency
- token cost
- integration complexity
- debugging difficulty
- safety and compliance burden
- the chance of silent failure
I like to phrase it this way: if you already know the path, do not pay for a planner.
3. The Main Cases Where You Should Not Use an Agent
3.1 The task is deterministic
If the task can be described as a fixed sequence of steps, an agent is usually unnecessary. A script, rule engine, or workflow orchestrator will be faster and more reliable.
Examples:
- resize all uploaded images, then store them in object storage
- read a CSV, validate schema, and load rows into a warehouse
- send a password reset email after verifying the user token
- classify support tickets into a small stable label set with a well-tested model
In these cases, the system does not need to deliberate. It needs to execute.
The technical reason is straightforward. If the policy is already known, replacing a fixed policy with a learned or prompted policy only adds variance:
$$
\mathrm{Deterministic\ workflow} \rightarrow a_t = f(s_t)
$$
$$
\mathrm{Agentic\ workflow} \rightarrow a_t \sim \pi_\theta(a_t \mid h_t)
$$
When $f(s_t)$ already exists and performs well, introducing $\pi_\theta$ does not buy you capability. It buys you uncertainty.
3.2 The action is high stakes and hard to reverse
Agents are a poor fit when the consequences of a wrong action are severe and rollback is difficult or impossible.
Examples:
- approving loans or insurance claims without a strong deterministic policy layer
- executing financial trades directly from model output
- modifying production infrastructure without sandboxing and approvals
- sending legal, medical, or regulatory advice as final output without expert review
This is where many teams confuse “the model is often correct” with “the system is safe enough.” Those are not the same statement.
For high-stakes actions, expected performance is not the only quantity that matters. Tail risk matters more. A system with a 95 percent success rate can still be unacceptable if the remaining 5 percent produces catastrophic outcomes.
If an agent must operate in such a domain, it should usually be reduced to a recommendation engine, not given direct authority.
3.3 The task has strict latency or cost budgets
Agents often require multiple model calls, tool calls, retrieval steps, retries, and reflection loops. That means they are structurally slower than a single-call system or a deterministic service.
Do not use an agent when:
- the user experience requires sub-second response time
- the request volume is high and margins are thin
- each extra second has measurable churn or abandonment cost
- most requests are simple enough that a fixed handler would work
For a production system, the total cost is not just token cost. It is closer to:
$$
\mathrm{Total\ cost} = C_{model} + C_{tools} + C_{engineering} + C_{oversight} + C_{incidents}
$$
That last term, incident cost, is the one teams routinely forget.
3.4 The goal is underspecified
Agents perform poorly when success criteria are vague. If you cannot clearly define what a good trajectory looks like, the agent will often optimize a weak proxy.
Examples of underspecified goals:
- “improve customer satisfaction”
- “do growth research”
- “handle this operations task intelligently”
- “optimize our onboarding funnel”
These instructions sound ambitious, but they are not operational. They do not define:
- what actions are allowed
- what evidence is trustworthy
- what success metric matters most
- what tradeoffs are acceptable
- when the task is complete
This often leads to what reinforcement learning literature would call reward hacking or proxy gaming. The agent appears productive while quietly optimizing the wrong thing.
If your objective is vague, your first task is not building an agent. Your first task is designing a measurable workflow.
3.5 The environment is adversarial or untrusted
Agents are especially fragile when they consume untrusted text and can take external actions. This is the setting where LLM guardrails and prompt injection defenses become a real systems problem rather than a prompt-writing curiosity.
Do not use an autonomous agent when it:
- reads arbitrary webpages or emails
- writes to databases or ticketing systems
- holds broad credentials
- can call tools based on instructions hidden inside retrieved content
The core issue is that the observation channel is contaminated. In such settings, a constrained workflow with strong separation between data and instructions is often much safer than an open-ended agent loop.
3.6 You do not have observability, approval gates, or rollback
An agent that can act without traceability is not an automation system, it is an incident generator.
You should not deploy an agent if you cannot answer these questions clearly:
- Which prompt, model version, and tool schema produced this action?
- What exact arguments were sent to the tool?
- What policy checks ran before execution?
- Who can pause or kill a live run?
- How do you undo a bad action?
If the answers are missing, you are not ready for agents. At minimum, you need traces, structured tool logs, rate limits, approval gates, and a kill switch. A proper agentic system evaluation framework and an agent harness for regression testing make these requirements more tractable in practice. Frameworks such as LangGraph, typed validation libraries such as Pydantic, and tracing systems such as OpenTelemetry can help, but the architecture matters more than the library.
3.7 The task is rare, low value, or both
Sometimes the best technical decision is to not automate at all.
If a task:
- happens once a month
- takes a human three minutes
- has a high cost of validation
- does not create reusable infrastructure value
then an agent is often pure overhead.
This is where many teams violate a basic product principle: automation should eliminate meaningful recurring cost, not create a maintenance burden larger than the original work.
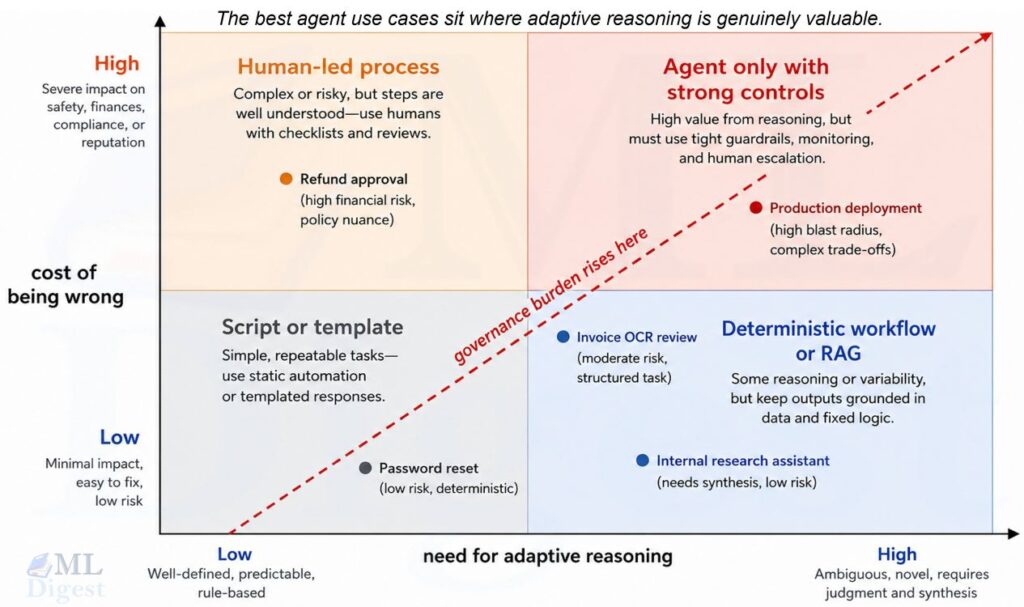
4. A Quantitative Decision Framework
The intuitive advice above is useful, but teams usually need a sharper decision rule. A simple approach is to model the expected net value of using an agent versus a simpler baseline.
Let:
- $B$ be the business value when the task is completed correctly
- $p_s$ be the probability the agent succeeds
- $p_m$ be the probability of a minor failure
- $p_c$ be the probability of a critical failure
- $C_t$ be the operational cost of tokens, tools, and infrastructure
- $C_h$ be the human review cost
- $C_m$ be the cost of a minor failure
- $C_c$ be the cost of a critical failure
Then a basic expected-net formula is:
$$
\mathbb{E}[\text{Net}_{agent}] = p_s B – p_m C_m – p_c C_c – C_t – C_h
$$
You should prefer the agent only if:
$$
\mathbb{E}[\text{Net}_{agent}] > \mathbb{E}[\text{Net}_{baseline}]
$$
where the baseline could be a deterministic workflow, or human review.
This is still incomplete because it ignores variance, compliance, and reputational cost, but it is already far better than deciding from a demo. For a broader decision tool that covers rules-based systems, traditional ML, and generative AI together, the AI solution compass provides a useful complement.
In practice, I recommend scoring a candidate task on five dimensions:
- workflow determinism
- action reversibility
- latency sensitivity
- environment trustworthiness
- value of flexible reasoning
The stronger the first four are, the less attractive an agent becomes. The stronger the last one is, the more attractive the agent becomes.
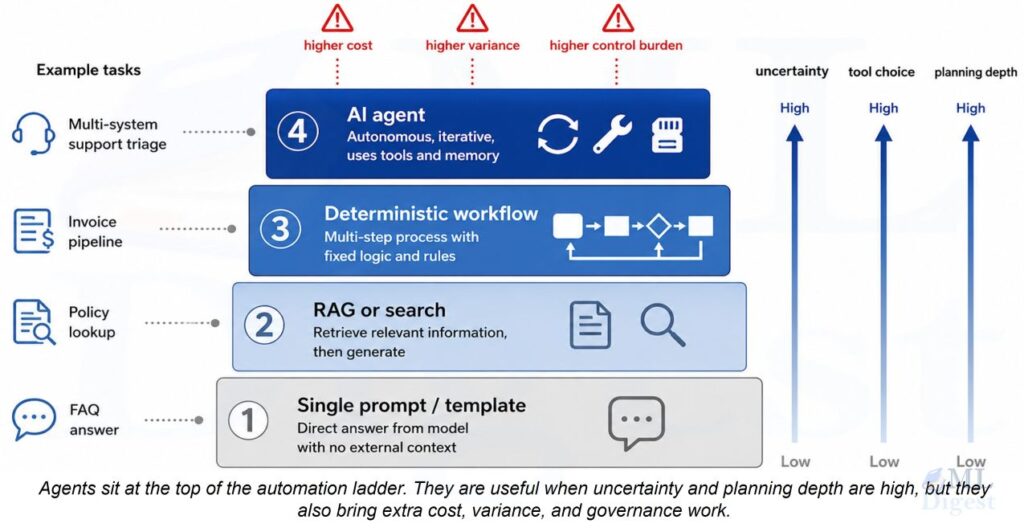
5. Build a Router Before You Build an Agent
One of the best implementation patterns is to route tasks through a hierarchy of increasingly flexible systems.
That staged escalation is part of a broader agent workflow: keep the deterministic path as the default, then escalate only when adaptive reasoning is genuinely needed.
5.1 The routing order
Use this order by default:
- Fixed rule or script
- Retrieval or lookup
- Deterministic workflow
- Human-in-the-loop workflow
- Agent with bounded tools and approvals
This architecture has two advantages.
First, it protects you from wasting agent calls on easy cases. Second, it lets you reserve autonomy for the narrow slice of tasks that truly benefit from it.
Anthropic’s Building Effective Agents makes a similar point in practice: simple patterns often outperform ambitious agent designs once reliability and operational burden are included in the comparison.
5.2 A practical checklist
Before you approve an agentic design, ask:
- Can I encode this as a fixed graph instead?
- Do I really need tool choice, or only tool execution?
- Can I remove write access and keep the model read-only?
- Do I have enough logs to replay failures?
- Is the cost of a wrong action acceptable?
- Is this frequent enough to justify operational complexity?
If most answers point toward simplicity, trust that signal.
Summary
The question is not whether AI agents are powerful. They are. The real question is whether your task actually benefits from autonomous reasoning enough to justify the added variance, cost, and control burden.
Do not use an AI agent when the workflow is deterministic, the action is high stakes, the latency budget is tight, the environment is untrusted, the objective is vague, or the task is too small to justify operational complexity. In those cases, scripts, retrieval systems, deterministic workflows, and human review are usually better engineering choices.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!