Imagine you are starting a new job as a research analyst. On your first day, your manager hands you a task with only one instruction: “Produce a report on the competitive landscape of the electric vehicle battery market.” No step-by-step instructions. No template to fill in.
How do you approach it? You probably spend the first few minutes thinking about what you need to find out. You open a browser, search for some recent news, read a few pages, realize one of the sources mentions a company you did not know about, search for that company, revise your mental picture of the problem, and then — after several such loops of reading and thinking — you start writing. When your draft is done, you read it back. Something feels off in the third section. You revise. You read it again. You submit it.
You just ran a single-agent system. You planned, acted, observed, and reflected. You did not spawn a team of colleagues to help you. You did it alone, in loops, using a mix of external tools (a browser, documents) and internal reasoning.
An AI agent works in much the same way. It has a goal, a set of tools it can invoke, and an LLM that provides the reasoning capability. The architecture pattern is the blueprint that governs how those elements are arranged and how the agent decides what to do at each step.
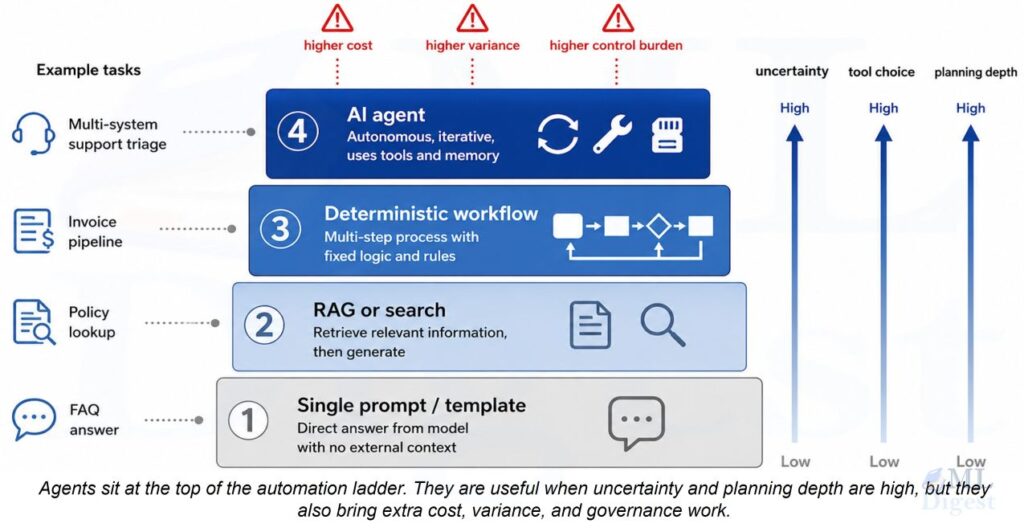
This article is a practical field guide to six recurring single-agent patterns. Some of them are control-loop patterns. Some are workflow-constraining patterns. One is primarily an activation pattern. Grouping them together is useful because, in production, you choose among all of them when deciding how one agent should behave.
1. The Anatomy of a Single Agent
Before examining individual patterns, it is worth establishing a clear picture of what a single agent is made of. Think of it as learning the rules of chess before studying openings. The pieces move the same way regardless of the opening; the architecture patterns govern the strategy, not the mechanics.
1.1 A Note on Taxonomy
Not every pattern in this guide operates at the same level.
- ReAct, Plan-then-Execute, Tree of Thoughts, and Reflection describe how the agent reasons over time (control-loop patterns).
- State Machine Agents describe how the developer constrains that reasoning inside an explicit workflow (workflow-constraining patterns).
- Event-Driven Agents describe when the agent wakes up and how it is invoked inside a larger system (activation patterns).
This distinction matters. If your agent is triggered by a webhook, that does not tell you whether the handler should use ReAct or Plan-then-Execute internally. Likewise, a State Machine Agent may still run a reflection loop in one state. Treat these patterns as composable building blocks rather than mutually exclusive ideologies.
If you are interested in learning about Tree-Of-Thought Prompting, see Tree of Thoughts Prompting.
1.2 The Core Control Loop
At the lowest level, every agent (regardless of pattern) executes a perceive → think → act → observe cycle.
In code, this loop is deceptively simple:
def run_agent(goal: str, tools: dict, llm, max_steps: int = 20) -> str:
context = [{"role": "user", "content": goal}]
for step in range(max_steps):
# Think: ask the LLM what to do next
response = llm.invoke(context)
if response.is_final_answer:
return response.content
# Act: execute the chosen tool
tool_name = response.tool_call.name
tool_args = response.tool_call.arguments
observation = tools[tool_name](**tool_args)
# Observe: add result to context
context.append({"role": "tool", "content": str(observation)})
return "Max steps reached without a final answer."The architecture patterns in the sections ahead are all variations on this loop. Some constrain the thinking step (state machines), some expand it (Tree of Thoughts), and some add a layer of self-evaluation between observation and the next action (reflection). But the loop itself is always present.
1.3 Formal Grounding: MDPs and POMDPs
To reason precisely about agent behavior, it helps to ground the system in the Markov Decision Process (MDP) framework. An MDP is defined by the tuple $\mathcal{M} = (\mathcal{S}, \mathcal{A}, P, R, \gamma)$, where:
- $\mathcal{S}$ is the state space (all possible configurations of the world the agent can be in).
- $\mathcal{A}$ is the action space (every action the agent can take, such as tool calls, text generation, or no-op).
- $P(s’ \mid s, a)$ is the transition function (the probability that taking action $a$ in state $s$ leads to state $s’$).
- $R(s, a)$ is the reward function (the scalar signal that tells the agent how good a transition was).
- $\gamma \in [0, 1)$ is the discount factor (how much the agent prefers immediate rewards over future ones).
The agent’s goal is to learn a policy $\pi(a \mid s)$ that maximizes the expected discounted cumulative reward:
$$J(\pi) = \mathbb{E}_{\pi}\left[\sum_{t=0}^{\infty} \gamma^t R(s_t, a_t)\right]$$
In practice, LLM-based agents rarely receive explicit scalar reward signals during inference. Instead, the “reward” is implicit: the agent terminates when it decides the goal is achieved, or is trained (via RLHF or DPO) so that the LLM’s learned distribution over actions aligns with high-quality trajectories.
Most real-world agent tasks are not fully observable — the agent cannot see every piece of information at once. A more realistic model is the Partially Observable MDP (POMDP), defined as $(\mathcal{S}, \mathcal{A}, P, R, \Omega, O, \gamma)$, where $\Omega$ is an observation space and $O(o \mid s’, a)$ is the probability of receiving observation $o$ after transitioning to state $s’$ via action $a$. The agent does not act on the true state $s$ but on a belief state $b(s)$ — a probability distribution over all possible states given the history of observations:
$$b'(s’) = \eta \cdot O(o \mid s’, a) \sum_{s} P(s’ \mid s, a) \, b(s)$$
where $\eta$ is a normalizing constant chosen so that $\sum_{s’} b'(s’) = 1$. In LLM-based agents, the context window is the belief state: it encodes the history of observations from which the agent reasons, without ever having access to the full ground truth of the environment.
This observation has a practical consequence: the quality of an agent’s context management — what it puts in the window, in what order, and whether it compresses or discards stale information — directly determines the quality of its “beliefs” and therefore the quality of its decisions.
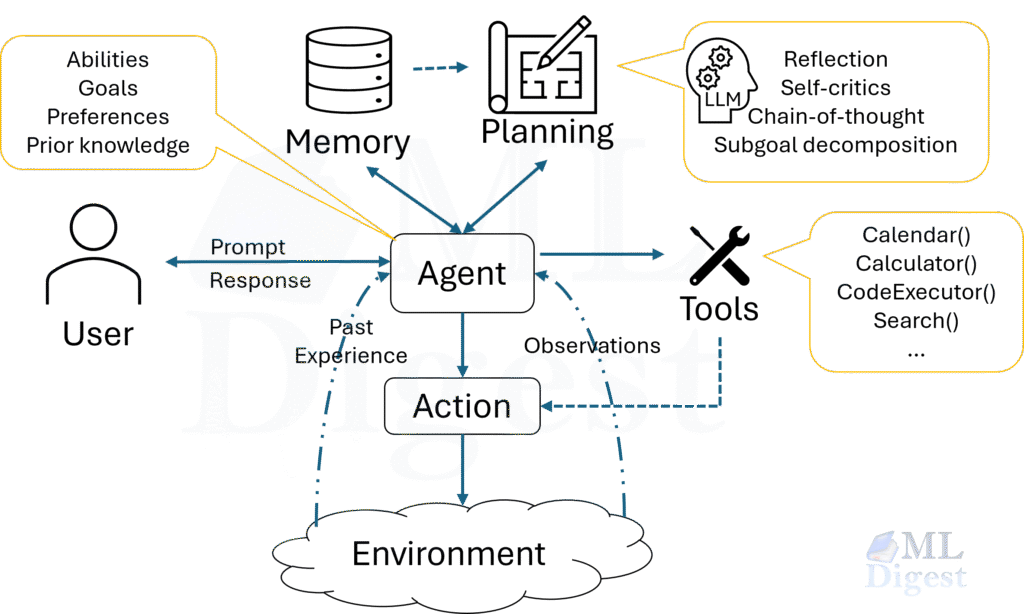
1.4 Memory: What the Agent Knows and How It Stores It
An agent’s memory can be thought of as existing in four forms, each with different latency, capacity, and durability:
| Memory Type | Analogy | Mechanism | Capacity | Durability |
|---|---|---|---|---|
| In-context (working) | Whiteboard | The active context window | Limited (tens of thousands to millions of tokens) | Session only |
| External (episodic) | Filing cabinet (what happened) | Vector store, database query | Effectively unlimited | Persistent |
| External (semantic) | Library (what is true) | Knowledge base, RAG, Knowledge graph based RAG | Effectively unlimited | Persistent |
| In-weights (semantic) | A university education | LLM pre-training and fine-tuning | Fixed (model size) | Permanent (until retrained) |
| In-cache (KV-cache) | Cached computation | KV-cache from shared prompt prefixes (avoids recomputation) | Bounded by context window and GPU VRAM | Ephemeral |
For single-agent systems, the most commonly engineered memory is the interplay between in-context memory (prompt engineering, context truncation, summarization) and external memory (RAG, key-value store). The other two forms are properties of the model itself rather than the agent’s runtime architecture.
1.5 Tools: The Agent’s Actuators
An agent without tools can reason, plan, and write — but it cannot act on the world. Tools are the actuators: they grant the agent the ability to read live information (search engines, databases, APIs) and to write effects into the world (send an email, execute code, update a record).
In many modern agent frameworks, tools are exposed as structured schemas — often JSON-based descriptions of a function’s name, purpose, and parameters — and the LLM is prompted or fine-tuned to emit structured tool call requests mid-generation.
# A representative tool schema (OpenAI / Anthropic compatible JSON)
search_tool_schema = {
"name": "search_web",
"description": (
"Search the web for recent information. Use this when the user's question "
"requires up-to-date facts not available in the model's training data."
),
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query, written as a natural-language question."
},
"num_results": {
"type": "integer",
"description": "Number of results to retrieve. Default is 5.",
"default": 5
}
},
"required": ["query"]
}
}With this foundation in place, we can now examine each architecture pattern in depth.
2. ReAct: Reason and Act
2.1 The Intuition
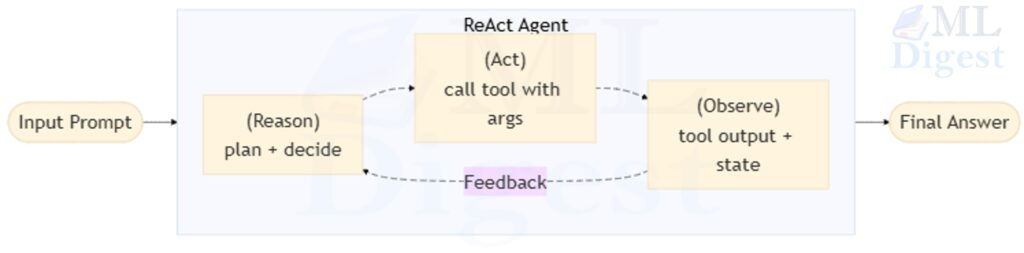
Think of a detective working a case — not from a pre-written checklist, but by asking questions, following leads, and updating their mental model after each discovery. They do not know at the outset which clues will matter; the answer emerges through a chain of targeted actions and the observations those actions produce. ReAct works exactly this way.
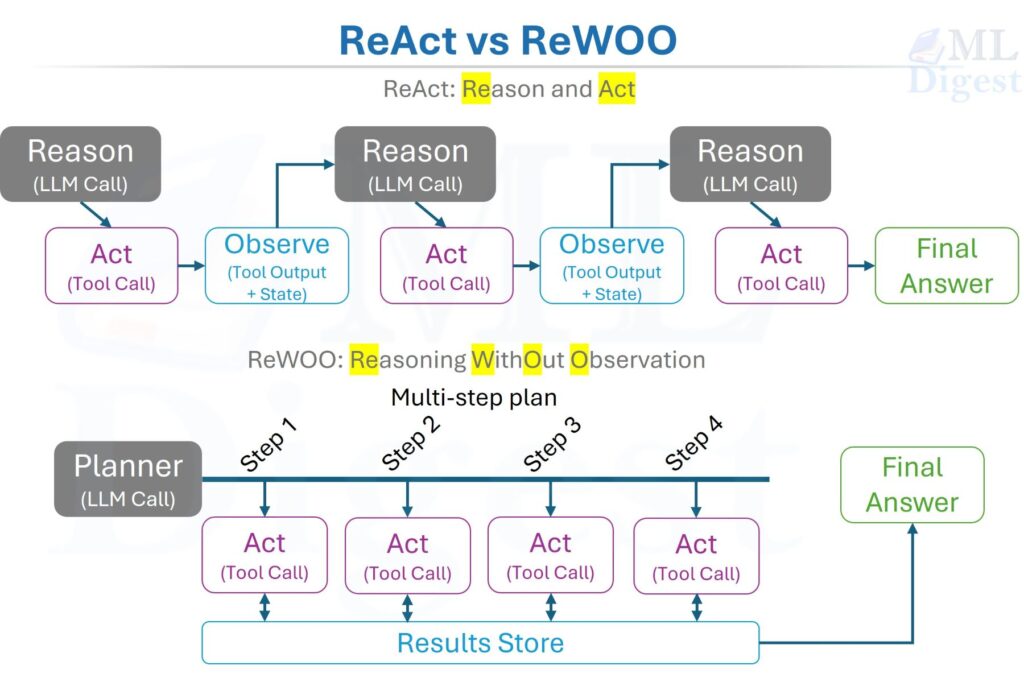
ReAct (Yao et al., 2022) is the foundational single-agent pattern and the default workhorse for open-ended tasks. It interleaves explicit reasoning steps (a scratchpad) with Action steps (tool calls) and Observation steps (tool results), creating a tight feedback loop:
2.2 How It Works
The key property is that the agent conditions each next step on the accumulated history of prior actions and observations rather than reasoning in a single shot. In some implementations, the intermediate reasoning trace is appended to the context; in others, it is summarized, hidden, or replaced by structured intermediate state while still guiding tool use. Either way, the pattern grounds the agent in actual observations rather than letting it drift into hallucination on long tasks. A compact way to write the policy at step $t$ is:
$$a_t = \pi_\theta\left(a_t \mid h_t\right), \quad h_t = (s_0, a_1, o_1, \ldots, a_{t-1}, o_{t-1})$$
ReAct is covered in depth including its POMDP formalization, production failure modes, evaluation strategy, and a full implementation in ReAct Framework. The discussion here focuses on where ReAct sits relative to the other five patterns.
2.3 Strengths, Weaknesses, and When to Use It
Use ReAct when the task is open-ended, the required steps are not known in advance, and the environment is dynamic (live search, APIs, file systems). Its explicit trace also makes it the easiest pattern to debug and audit.
Prefer a different pattern when:
- The task decomposes predictably upfront. Plan-then-Execute eliminates the per-step LLM overhead.
- Multiple competing reasoning paths need systematic exploration. Tree of Thoughts branches more rigorously.
- Iterative self-correction on the final output is the primary concern. Reflection provides a more targeted revision loop.
- The workflow must be strictly auditable at design time. A State Machine Agent makes every possible execution path explicit before deployment.
3. Plan-then-Execute (Including ReWOO-Style Variants)
3.1 The Intuition
A seasoned software architect does not write code, run it, fail, think about what to do, write more code, and continue indefinitely. Before touching a keyboard, she reads the requirements, sketches a design, writes pseudocode, and then implements. The planning and the execution are clearly separated.
The Plan-then-Execute pattern brings this same discipline to agents. ReWOO (Reasoning WithOut Observation, Xu et al., 2023) is one influential variant of this family. The core idea is simple: a planner first produces a multi-step plan, and an executor then carries out that plan with much less interleaved reasoning than a ReAct loop. Some implementations execute the full plan with no additional LLM calls between steps; others allow lightweight substitution, verification, or replanning when execution deviates from the original assumptions.
This separation yields two practical advantages: it often reduces the total number of expensive LLM calls compared with a fully interleaved ReAct loop, and it makes the plan an inspectable, loggable artifact before any tool is invoked. Its main weakness is equally important: if the planner makes a bad early assumption, the rest of the run may execute that mistake very efficiently.
3.2 How It Works
The pattern separates the loop into two distinct phases.
Phase 1 — Planning:
$$\text{Plan} = \pi_\theta^{\text{planner}}(\text{goal}, \text{context})$$
The planner LLM receives the goal and produces an ordered list of steps, each of which names a tool, its input, and the expected output type. Crucially, the plan can include variable references like $step_2.output to express dependencies between steps before any tool is actually called.
Phase 2 — Execution:
$$o_t = \text{tool}_t\left(\text{fill}\left(s_t,\; \text{results}_{1:t-1}\right)\right)$$
The executor iterates through the plan, resolves variable references with actual results from prior steps as they become available, and calls each tool. In a strict ReWOO-style setup, the planner is not re-consulted between steps unless replanning is triggered. In broader plan-then-execute systems, additional verification or repair calls may be inserted when needed.
3.3 Implementation
import re
from dataclasses import dataclass, field
from typing import Any
from openai import OpenAI
client = OpenAI()
@dataclass
class PlanStep:
"""One step in the execution plan."""
index: int
tool: str
input_template: str # May contain $step_N.output placeholders
output: Any = None # Filled in after execution
def generate_plan(goal: str, available_tools: list[str]) -> list[PlanStep]:
"""Ask the planner LLM to produce a structured plan."""
tool_list = ", ".join(available_tools)
system_prompt = f"""You are a planning assistant. Given a goal and a list of available tools,
produce a step-by-step plan. Each step must specify:
- step number
- tool name (from: {tool_list})
- input (may reference prior step outputs as $step_N.output)
Format each step as:
Step N: tool_name | input_description
Produce a minimal plan. Use $step_N.output to reference earlier results.
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Goal: {goal}"}
],
temperature=0,
)
raw_plan = response.choices[0].message.content
steps = []
for line in raw_plan.strip().split("\n"):
match = re.match(r"Step (\d+):\s*(\w+)\s*\|\s*(.+)", line)
if match:
steps.append(PlanStep(
index=int(match.group(1)),
tool=match.group(2).strip(),
input_template=match.group(3).strip(),
))
return steps
def resolve_references(template: str, results: dict[int, Any]) -> str:
"""Replace $step_N.output placeholders with actual results."""
def replacer(match):
step_idx = int(match.group(1))
return str(results.get(step_idx, match.group(0)))
return re.sub(r"\$step_(\d+)\.output", replacer, template)
def execute_plan(
plan: list[PlanStep],
tools: dict[str, callable],
replanner=None,
goal: str = "",
) -> dict[int, Any]:
"""Execute the plan step by step, triggering replanning on failure."""
results = {}
for step in plan:
resolved_input = resolve_references(step.input_template, results)
tool_fn = tools.get(step.tool)
if tool_fn is None:
raise ValueError(f"Unknown tool: {step.tool}")
try:
results[step.index] = tool_fn(resolved_input)
except Exception as e:
if replanner:
remaining_plan = replanner(goal, results, failed_step=step, error=str(e))
results.update(execute_plan(remaining_plan, tools, replanner, goal))
break
else:
raise
return results
# --- Example usage
def search_web(query: str) -> str:
return f"[Search results for: {query}]" # stub: call a real search API
def python_repl(code: str) -> str:
result = {}
exec(code, {}, result) # stub: use a sandboxed executor
return str(result.get("answer", ""))
def summarize(text: str) -> str:
return f"[Summary of: {text[:60]}...]" # stub: call a summarization API
tools = {"search_web": search_web, "python_repl": python_repl, "summarize": summarize}
goal = "Find the population of Tokyo and calculate its share of Japan's total population."
plan = generate_plan(goal, list(tools.keys()))
results = execute_plan(plan, tools)
final_answer = results[max(results.keys())]
print(final_answer)3.4 Strengths, Weaknesses, and When to Use It
Use Plan-then-Execute when:
- The task has a known structure and the steps can be deduced from the goal before any tools are called.
- Minimizing total LLM calls matters (cost or latency constraints).
- You need the plan as an auditable artifact, for human review or logging before execution begins.
- The environment is stable and predictable (internal APIs, known databases).
Avoid Plan-then-Execute when:
- The environment is dynamic: early-step results substantially change what later steps should do. In that case, ReAct’s incremental reasoning adapts better.
- The planner LLM is not sufficiently capable of generating reliable multi-step plans. A weak planner paired with a strong executor is a dangerous combination.
- The task is exploratory and open ended; you genuinely do not know what you are looking for until you start looking.
4. Tree of Thoughts
4.1 The Intuition
When you are stuck on a hard puzzle — say, a difficult logic problem or a strategic chess position — you do not just follow the first idea that comes to mind. You hold multiple possibilities in your head at once. You think: “If I do this, then they might do that, and I would be stuck. But if I do this other thing first, then I have two good options next.” You are building a mental tree of possibilities and evaluating branches before committing to one.
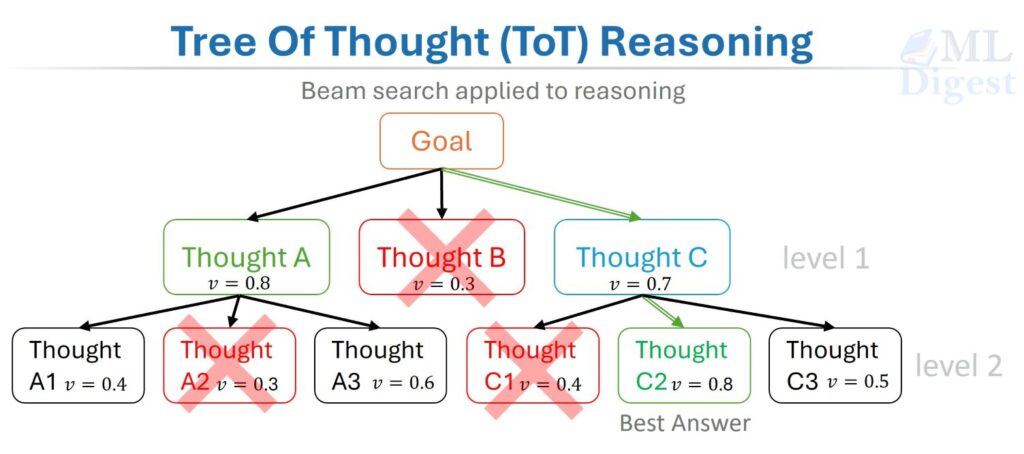
Tree of Thoughts (ToT, Yao et al., 2023) formalizes this natural problem-solving strategy. Instead of a single linear chain of reasoning steps, the agent maintains a tree of partial solutions. Multiple candidate thoughts are generated at each node; each candidate is evaluated by a scoring function; low-scoring branches are pruned; and the search expands the most promising branches. The agent then returns the best path found under its search procedure and evaluation rule.
This is, in essence, beam search applied to reasoning, with the “vocabulary” replaced by the space of possible thoughts and the “score” replaced by a value function that estimates the quality of a reasoning trajectory. It is most useful when the agent is likely to encounter plausible-looking but ultimately bad intermediate steps.
4.2 How It Works
Formally, define:
- $\mathcal{T}$: the tree of thought nodes, where each node $n$ represents a partial reasoning trajectory.
- $\text{thought_generator}(n)$: a function that proposes $k$ candidate next steps from node $n$.
- $v(n) \in [0, 1]$: a scalar value function that scores how promising node $n$ is toward solving the goal.
- $B$: the beam size — the number of nodes kept at each tree level.
At each depth level $d$, the algorithm:
- Expands each node in the beam by calling
thought_generator, producing up to $k \times B$ candidate nodes. - Scores all candidates with $v$.
- Retains only the top-$B$ candidates by score for depth $d+1$.
The total LLM cost is $O(D \cdot B \cdot k)$ calls for a tree of depth $D$, compared to $O(D)$ for ReAct. This cost is the price of exploration.
One common scoring objective is:
$$s^* = \arg\max_{s \in \mathcal{L}(\mathcal{T})} \sum_{n \in \text{path}(s)} v(n)$$
where $\mathcal{L}(\mathcal{T})$ denotes the leaf nodes of the tree and $\text{path}(s)$ is the sequence of nodes from the root to leaf $s$. In practice, implementations vary: some score only leaves, some combine stepwise scores, and some use a separate verifier rather than a simple additive objective.
4.3 Implementation
from dataclasses import dataclass, field
from typing import Optional
import heapq
from openai import OpenAI
client = OpenAI()
@dataclass
class ThoughtNode:
"""A node in the Tree of Thoughts."""
content: str
depth: int
score: float = 0.0
parent: Optional["ThoughtNode"] = field(default=None, repr=False)
children: list["ThoughtNode"] = field(default_factory=list, repr=False)
def __lt__(self, other: "ThoughtNode") -> bool:
return self.score > other.score # Reverse for max-heap behavior
def generate_thoughts(node: ThoughtNode, goal: str, k: int = 3) -> list[str]:
"""Generate k candidate next steps from the current node."""
history = _reconstruct_path(node)
prompt = f"""Goal: {goal}
Reasoning so far:
{history}
Generate {k} distinct, specific next steps. Each step should explore a different approach.
Separate steps with "---"."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0.8, # Higher temperature encourages diverse candidates
)
raw = response.choices[0].message.content
return [s.strip() for s in raw.split("---") if s.strip()][:k]
def evaluate_thought(node: ThoughtNode, goal: str) -> float:
"""Score how promising this node is on a 0-1 scale."""
history = _reconstruct_path(node)
prompt = f"""Goal: {goal}
Reasoning so far:
{history}
Rate how promising this reasoning path is for reaching the goal.
Reply with ONLY a number between 0.0 (hopeless) and 1.0 (definitely leads to the answer).
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
)
try:
return float(response.choices[0].message.content.strip())
except ValueError:
return 0.5 # Default neutral score if parsing fails
def _reconstruct_path(node: ThoughtNode) -> str:
"""Reconstruct the reasoning path from root to the current node."""
path = []
current = node
while current is not None:
path.append(current.content)
current = current.parent
return "\n".join(reversed(path))
def tree_of_thought(
goal: str,
max_depth: int = 4,
beam_size: int = 3,
k_thoughts: int = 3,
) -> str:
"""
Run Tree of Thoughts search.
Parameters
------- goal : The task or question to solve.
max_depth : Maximum depth to expand the tree.
beam_size : Number of best nodes to keep at each level (beam width).
k_thoughts : Number of candidate next steps to generate per node.
Returns
---- The best reasoning path found, expressed as a string.
"""
root = ThoughtNode(content=f"Initial goal: {goal}", depth=0)
beam = [root]
for depth in range(1, max_depth + 1):
candidates = []
for node in beam:
child_thoughts = generate_thoughts(node, goal, k=k_thoughts)
for thought in child_thoughts:
child = ThoughtNode(content=thought, depth=depth, parent=node)
child.score = evaluate_thought(child, goal)
node.children.append(child)
candidates.append(child)
if not candidates:
break
# Keep only the top beam_size candidates
beam = heapq.nsmallest(beam_size, candidates) # __lt__ reverses for max
# Check if any leaf is already a satisfying final answer
for node in beam:
if "final answer:" in node.content.lower():
return _reconstruct_path(node)
# Return the path to the highest-scoring leaf
best = beam[0]
return _reconstruct_path(best)4.4 Strengths, Weaknesses, and When to Use It
Use Tree of Thoughts when:
- The task has deceptive dead ends, such as problems where the locally best-looking step is not globally optimal (mathematical proof steps, strategic planning, complex debugging).
- You can afford the extra LLM calls (approximately $B \times k$ times more than ReAct).
- A reliable scoring function exists or can be built (another LLM, a unit test, a verifiable constraint).
Avoid Tree of Thoughts when:
- The task is sequential with little ambiguity; the cost of exploration is wasted.
- The scoring function is unreliable. If the evaluator itself is wrong, ToT can confidently march down the wrong branch.
- Low latency is required. Branch evaluation requires multiple concurrent or sequential LLM calls.
5. Reflection and Self-Critique
5.1 The Intuition
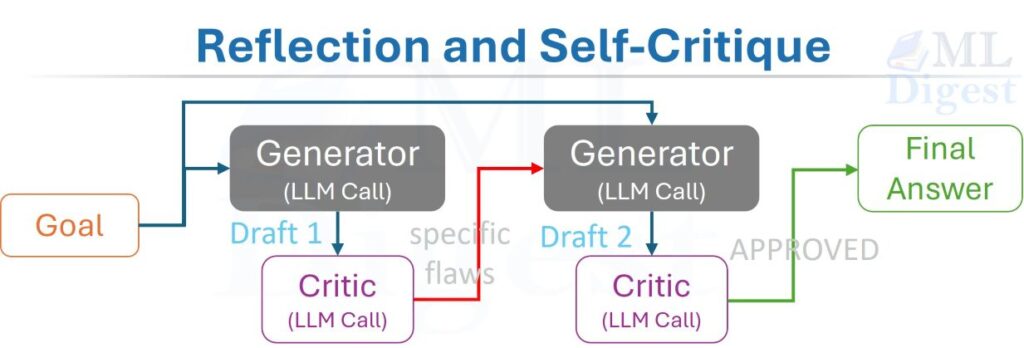
Good writers do not submit their first draft. They write, put the draft aside, return with fresh eyes, and ask: “Is this actually saying what I meant? Is anything missing? Is anything wrong?” The critique phase is often where the most important improvements happen — not during the initial generation, but during the honest self-evaluation afterward.
The Reflection pattern gives an agent this same editor mindset. After generating an initial output, the agent evaluates that output against the original goal, identifies specific flaws or gaps, and iterates. The correction is not random; it is grounded in a structured critique. This pattern is closely related to Reflexion (Shinn et al., 2023), but not identical to it: Reflexion uses verbal feedback and an episodic memory buffer across trials, whereas the simpler reflection loop here focuses on iterative critique-and-revision within a single task run.
5.2 How It Works
The loop has two LLM roles:
- Generator $G$: Produces an initial output given the goal and context.
- Critic $C$: Evaluates the output against the goal and outputs either an “APPROVED” signal or a structured critique explaining what is wrong and how to fix it.
The agent feeds the critique back to the Generator to produce a revised draft. This loop runs until the Critic approves or an iteration budget is exhausted.
$$\text{draft}_0 = G(\text{goal})$$
$$\text{critique}_t = C(\text{goal},\; \text{draft}_{t-1})$$
$$\text{draft}_t = G(\text{goal},\; \text{draft}_{t-1},\; \text{critique}_{t-1})$$
Note the critical design decision: the Generator and Critic can be the same LLM or different ones. Using the same model is simpler and cheaper, but it introduces self-assessment bias — the model tends to approve its own outputs or make only superficial edits. Using separate system prompts (or separate model instances) that explicitly instruct the critic to be skeptical provides more independent evaluation.
5.3 Implementation
from openai import OpenAI
from typing import NamedTuple
client = OpenAI()
class CritiqueResult(NamedTuple):
approved: bool
critique: str # Empty string when approved
GENERATOR_SYSTEM = """
You are an expert technical writer and analyst.
Given a task and any previous feedback, produce the best possible response.
If feedback is provided, address every point raised — do not repeat prior mistakes.
"""
CRITIC_SYSTEM = """
You are a rigorous technical reviewer.
Your job is to identify factual errors, logical flaws, missing information, and
violated constraints in a draft response. Be specific: quote the problematic part
and explain why it is wrong.
If the response fully meets the goal with no significant issues, reply with exactly:
APPROVED
Otherwise, return a numbered list of specific improvements required.
"""
def generate(goal: str, draft: str = "", critique: str = "") -> str:
"""Generate or revise a response to the goal."""
user_content = f"Task: {goal}"
if draft:
user_content += f"\n\nPrevious Draft:\n{draft}"
if critique:
user_content += f"\n\nCritique to address:\n{critique}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": GENERATOR_SYSTEM},
{"role": "user", "content": user_content},
],
temperature=0.3,
)
return response.choices[0].message.content
def critique(goal: str, draft: str) -> CritiqueResult:
"""Evaluate the draft against the goal."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": CRITIC_SYSTEM},
{"role": "user", "content": f"Task: {goal}\n\nDraft to review:\n{draft}"},
],
temperature=0,
)
content = response.choices[0].message.content.strip()
approved = content.upper() == "APPROVED"
return CritiqueResult(approved=approved, critique="" if approved else content)
def reflection_loop(
goal: str,
max_rounds: int = 3,
verbose: bool = True,
) -> str:
"""
Run the reflection loop.
Parameters
------- goal : The task or question.
max_rounds : Maximum number of generate-critique cycles.
verbose : Whether to print intermediate drafts and critiques.
"""
draft = generate(goal)
if verbose:
print(f"--- Draft 0 ---\n{draft}\n")
for round_num in range(1, max_rounds + 1):
result = critique(goal, draft)
if result.approved:
if verbose:
print(f"Critic approved after {round_num - 1} revision(s).")
return draft
if verbose:
print(f"--- Critique {round_num} ---\n{result.critique}\n")
draft = generate(goal, draft=draft, critique=result.critique)
if verbose:
print(f"--- Draft {round_num} ---\n{draft}\n")
if verbose:
print("Max rounds reached. Returning best draft.")
return draft
# Example
result = reflection_loop(
goal=(
"Explain why gradient vanishing is a problem in deep networks, "
"and describe two architectural solutions, each with a concrete example."
),
max_rounds=3,
verbose=True,
)
print("Final:\n", result)5.4 Strengths, Weaknesses, and When to Use It
Use Reflection when:
- Output quality is the primary objective (writing, analysis, code review).
- The correctness criteria are hard to specify upfront but easy to evaluate after the fact.
- You want to catch logical errors, omissions, or inconsistencies in generated content.
- You cannot afford a fully independent critic agent but want some quality gate.
Avoid Reflection when:
- The Generator and Critic share the same model and system prompt: self-assessment bias is strong, and the loop tends to converge quickly to “APPROVED” with minimal improvement.
- The task has a verifiable ground truth (unit tests, database queries): use external evaluation rather than LLM-based critique.
- Latency matters: each round approximately doubles the LLM call count.
6. State Machine Agents
6.1 The Intuition
Most everyday workflows are not open-ended. When you book a flight online, the process has a fixed set of states: Search → Select → Passenger Details → Payment → Confirmation. You cannot jump from Search directly to Confirmation. You cannot revisit Passenger Details after Confirmation. The system is in exactly one state at a time, and only specific transitions are allowed.
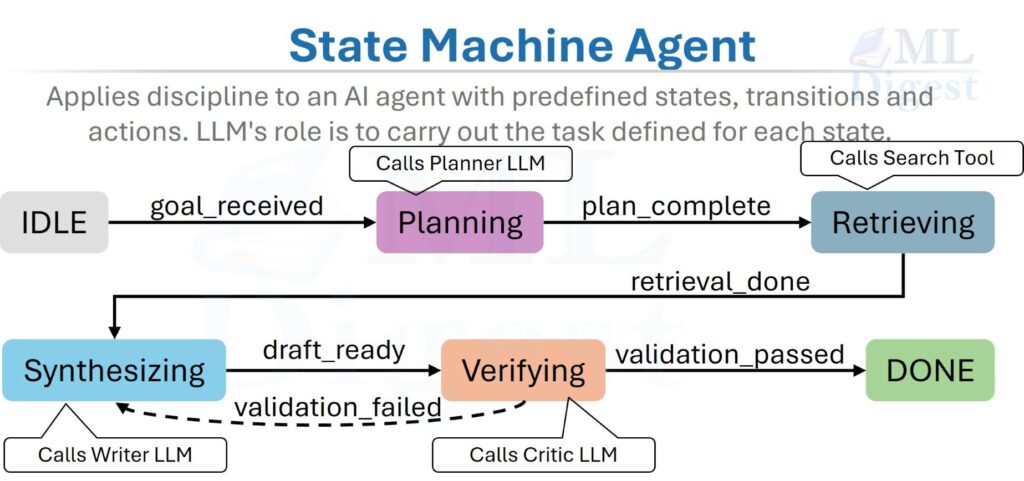
A State Machine Agent applies the same discipline to an AI agent. Instead of giving the LLM unconstrained freedom to decide its next action at every step, the developer pre-defines a set of states (each representing a bounded subtask), transitions (rules for when and how to move between states), and actions (what the agent does in each state). The LLM’s role is to carry out the task defined for each state, not to decide which states exist.
This shifts the source of reliability from the LLM’s emergent judgment to the developer’s explicit design. That is a fundamentally different risk model from ReAct: you give up some flexibility in exchange for stronger guarantees about what the system is allowed to do.
6.2 How It Works
Formally, the cleanest starting point is to model a State Machine Agent as a Deterministic Finite Automaton (DFA) extended with LLM-executable state actions:
$$M = (Q,\; \Sigma,\; \delta,\; q_0,\; F)$$
where:
- $Q$ is a finite set of states, e.g., $\{\text{IDLE},\, \text{PLANNING},\, \text{RETRIEVING},\, \text{SYNTHESIZING},\, \text{VERIFYING},\, \text{DONE}\}$.
- $\Sigma$ is the input alphabet — the set of possible trigger events (tool results, LLM flags, external signals).
- $\delta: Q \times \Sigma \to Q$ is the transition function — given the current state and trigger, it deterministically specifies the next state.
- $q_0 \in Q$ is the initial state.
- $F \subseteq Q$ is the set of terminal (accepting) states.
Each state $q_i$ also defines a state action $\alpha_i$: an LLM prompt (or tool call) that is executed when the agent enters that state. The state action produces an output that becomes the trigger event $\sigma$ driving the next transition. Real production systems are often better described as extended state machines, because they also carry context variables, counters, and guarded transitions in addition to the finite control state.
6.3 Implementation
from enum import Enum, auto
from dataclasses import dataclass, field
from typing import Any, Callable
from openai import OpenAI
client = OpenAI()
class State(Enum):
IDLE = auto()
PLANNING = auto()
RETRIEVING = auto()
SYNTHESIZING = auto()
VERIFYING = auto()
DONE = auto()
FAILED = auto()
@dataclass
class AgentContext:
"""Shared state store passed between state actions."""
goal: str
plan: str = ""
retrieved_docs: list[str] = field(default_factory=list)
draft: str = ""
verification_result: str = ""
final_answer: str = ""
revision_count: int = 0
max_revisions: int = 2
# One action function per state — each returns the trigger for the next transition
def action_planning(ctx: AgentContext) -> str:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": f"Create a concise step-by-step research plan for: {ctx.goal}"
}],
temperature=0,
)
ctx.plan = response.choices[0].message.content
return "plan_complete"
def action_retrieving(ctx: AgentContext) -> str:
# In production: call a real search / vector-store API
ctx.retrieved_docs = [
f"[Document about: {ctx.goal}]",
f"[Additional context supporting: {ctx.goal}]",
]
return "retrieval_done"
def action_synthesizing(ctx: AgentContext) -> str:
docs_text = "\n".join(ctx.retrieved_docs)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": (
f"Goal: {ctx.goal}\nPlan:\n{ctx.plan}\n"
f"Sources:\n{docs_text}\n\nWrite a comprehensive answer."
)
}],
temperature=0.3,
)
ctx.draft = response.choices[0].message.content
return "draft_ready"
def action_verifying(ctx: AgentContext) -> str:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": (
f"Goal: {ctx.goal}\n\nDraft:\n{ctx.draft}\n\n"
"Does this fully and accurately address the goal? "
"Reply with APPROVED or NEEDS_REVISION: [reason]."
)
}],
temperature=0,
)
verdict = response.choices[0].message.content.strip()
ctx.verification_result = verdict
if "APPROVED" in verdict.upper():
ctx.final_answer = ctx.draft
return "verification_passed"
elif ctx.revision_count >= ctx.max_revisions:
ctx.final_answer = ctx.draft # best effort
return "revision_limit_reached"
else:
ctx.revision_count += 1
return "verification_failed"
# Transition table: (current_state, trigger) → next_state
TRANSITIONS: dict[tuple[State, str], State] = {
(State.IDLE, "goal_received"): State.PLANNING,
(State.PLANNING, "plan_complete"): State.RETRIEVING,
(State.RETRIEVING, "retrieval_done"): State.SYNTHESIZING,
(State.SYNTHESIZING, "draft_ready"): State.VERIFYING,
(State.VERIFYING, "verification_passed"): State.DONE,
(State.VERIFYING, "verification_failed"): State.SYNTHESIZING,
(State.VERIFYING, "revision_limit_reached"): State.DONE,
}
ACTIONS: dict[State, Callable[[AgentContext], str]] = {
State.PLANNING: action_planning,
State.RETRIEVING: action_retrieving,
State.SYNTHESIZING: action_synthesizing,
State.VERIFYING: action_verifying,
}
def run_state_machine(goal: str, verbose: bool = True) -> str:
ctx = AgentContext(goal=goal)
current_state = State.IDLE
trigger = "goal_received"
while current_state not in (State.DONE, State.FAILED):
next_state = TRANSITIONS.get((current_state, trigger))
if next_state is None:
print(f"No transition from {current_state} on trigger '{trigger}'")
current_state = State.FAILED
break
current_state = next_state
if verbose:
print(f"→ Entering state: {current_state.name}")
action_fn = ACTIONS.get(current_state)
if action_fn:
trigger = action_fn(ctx)
if verbose:
print(f" Trigger: {trigger}")
return ctx.final_answer
# Example
answer = run_state_machine("Explain the key advantages of transformer architectures over RNNs.")
print("\nFinal Answer:\n", answer)6.4 Strengths, Weaknesses, and When to Use It
Use State Machine Agents when:
- The workflow has a known, fixed structure, such as customer support flows, form completion, or structured document generation.
- Auditability and reproducibility are non-negotiable: every possible execution path is enumerable at design time.
- You need to enforce invariants (e.g., “always verify before publishing”, “never skip retrieval”).
- You are building a production system where debugging ergonomics matter: state machines are straightforward to instrument, test, and step through.
Avoid State Machine Agents when:
- The problem is genuinely open-ended and the states themselves cannot be predicted in advance.
- The transition logic becomes so complex that the state diagram has dozens of edges. At that point, a learned policy (ReAct) is often easier to reason about than hundreds of explicit transition rules.
7. Event-Driven Agents
7.1 The Intuition
Not every task arrives as a single, synchronous request that must be solved immediately. Many of the most valuable AI applications are reactive systems: a document arrives in a monitored folder and must be summarized; a new customer support ticket appears and must be triaged; a sensor reading crosses a threshold and an alert must be drafted.
In these scenarios, it would be wasteful — and architecturally wrong — to keep a long-running agent loop spinning in idle mode, burning compute while waiting for something to happen. The correct model is the same one that powers event-driven software architectures: a lightweight event listener that activates an agent only when a relevant event occurs.
Event-Driven Agents are often not running continuously as a single interactive loop. Instead, they are idle until triggered by one or more event sources, then they wake, process, and terminate for that event. This makes them naturally scalable: independently stateless handlers can be deployed and scaled like serverless functions or queue consumers.
The important framing is that event-driven design answers a different question from ReAct or Reflection. It tells you how the agent is activated and embedded in the system, not necessarily how the agent reasons once invoked.
7.2 How It Works
The architecture has four components:
- Event Sources: Queues, webhooks, cron schedulers, file watchers, database triggers, or any external signal that emits a structured event payload.
- Event Router: A dispatcher that receives events and maps them to the appropriate agent handler. It may apply filtering, deduplication, and rate limiting.
- Agent Handler: A single-invocation agent that receives the event as its initial context, processes it using tools, and terminates. The handler is stateless — it reads from and writes to shared state stores rather than holding state in memory between invocations.
- State Store / Side-Effect Targets: A shared store (database, file system, message queue, notification service) where the agent writes its results or emits downstream events.
7.3 Implementation
import json
import time
import threading
import queue
from dataclasses import dataclass
from typing import Any, Callable
from openai import OpenAI
client = OpenAI()
@dataclass
class Event:
event_type: str # e.g., "document.uploaded", "ticket.created"
payload: dict[str, Any]
timestamp: float = 0.0
def __post_init__(self):
if self.timestamp == 0.0:
self.timestamp = time.time()
# Agent handlers — each is a short-lived function that processes one event
def handle_document_uploaded(event: Event) -> dict[str, Any]:
"""Summarize an uploaded document."""
doc_content = event.payload.get("content", "")
doc_name = event.payload.get("filename", "unknown")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": (
f"Summarize the following document in 3-5 bullet points.\n\n"
f"Document '{doc_name}':\n{doc_content}"
)
}],
temperature=0,
)
return {"filename": doc_name, "summary": response.choices[0].message.content, "status": "summarized"}
def handle_ticket_created(event: Event) -> dict[str, Any]:
"""Triage a new support ticket."""
title = event.payload.get("title", "")
description = event.payload.get("description", "")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": (
f"Classify this support ticket.\n\n"
f"Title: {title}\nDescription: {description}\n\n"
'Reply with JSON: {"priority": "low|medium|high", '
'"category": "billing|technical|account|other", '
'"summary": "one sentence"}'
)
}],
temperature=0,
response_format={"type": "json_object"},
)
triage = json.loads(response.choices[0].message.content)
triage["ticket_id"] = event.payload.get("ticket_id")
return triage
class EventRouter:
def __init__(self):
self._handlers: dict[str, Callable[[Event], dict]] = {}
self._results: list[dict] = []
self._event_queue: queue.Queue = queue.Queue()
self._running = False
def register(self, event_type: str, handler: Callable[[Event], dict]) -> None:
self._handlers[event_type] = handler
def emit(self, event: Event) -> None:
"""Put an event onto the internal queue for async processing."""
self._event_queue.put(event)
def _process_event(self, event: Event) -> None:
handler = self._handlers.get(event.event_type)
if handler is None:
print(f"[Router] No handler for event type: {event.event_type}")
return
try:
result = handler(event)
self._results.append(result)
print(f"[Router] Processed {event.event_type}: {result}")
except Exception as e:
print(f"[Router] Handler failed for {event.event_type}: {e}")
def run(self, block: bool = True) -> None:
"""Process all events in the queue."""
self._running = True
while self._running:
try:
event = self._event_queue.get(timeout=1.0)
self._process_event(event)
except queue.Empty:
if not block:
break
self._running = False
def stop(self) -> None:
self._running = False
# Wire it together
router = EventRouter()
router.register("document.uploaded", handle_document_uploaded)
router.register("ticket.created", handle_ticket_created)
router_thread = threading.Thread(target=router.run, daemon=True)
router_thread.start()
# Simulate incoming events
router.emit(Event(
event_type="document.uploaded",
payload={
"filename": "q3_report.txt",
"content": "Q3 revenue grew 15% YoY to $2.1B. Operating margin improved by 200bps..."
}
))
router.emit(Event(
event_type="ticket.created",
payload={
"ticket_id": "TKT-4821",
"title": "Cannot access dashboard after password reset",
"description": "After resetting my password, I am redirected to a blank page."
}
))
time.sleep(5) # Allow processing to complete
router.stop()7.4 Strengths, Weaknesses, and When to Use It
Use Event-Driven Agents when:
- The workload is bursty and unpredictable. Handlers scale to zero between events without wasting resources.
- Tasks arrive asynchronously from multiple sources (message queues, webhooks, cron jobs).
- Each task is independent and stateless, with no shared mutable state across invocations.
- You are building processing pipelines: document ingestion, email triage, monitoring and alerting, ETL-with-AI steps.
Avoid Event-Driven Agents when:
- The task requires multi-turn interaction or conversation history. Stateless handlers are a poor fit for dialogic agents; a persistently running ReAct or state machine agent is better.
- Event ordering matters and the system does not guarantee delivery order. Out-of-order events can corrupt stateful-looking operations unless explicit sequencing guarantees are added.
8. Choosing the Right Pattern: A Decision Framework
With six patterns in hand, the practical question is: which one do I use for my task? The following framework approaches the decision through a short sequence of questions.
Illustration: The decision tree below encodes the selection logic. The first two questions filter by system shape (event-driven systems and fixed-workflow automation are determined by their activation model or workflow constraints, not primarily by their reasoning strategy). The remaining branches select a reasoning pattern based on how much problem structure is known upfront and what the primary optimization target is.
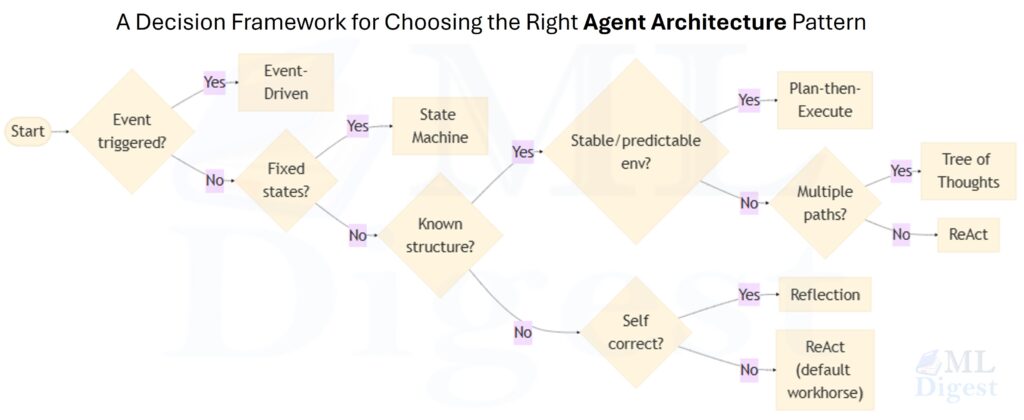
These patterns are not mutually exclusive. Production systems often combine them: a State Machine Agent may use a ReAct-style loop within its SYNTHESIZING state; an Event-Driven Agent may pass each processed document through a Reflection loop before writing to the store; a Plan-then-Execute pipeline may spawn a Tree of Thoughts search within one of its planning steps.
The practical rule is simple: first choose the outer operating model, then choose the inner reasoning policy.
- If the agent is activated by external signals, you are in Event-Driven territory.
- If the workflow is fixed and must obey hard invariants, start with a State Machine.
- Inside those constraints, pick ReAct, Plan-then-Execute, Tree of Thoughts, or Reflection based on the task’s uncertainty, search depth, and quality requirements.
Start with the simplest pattern that solves the problem, and layer in additional patterns only when benchmarks show a concrete reason to do so.
As a compact reference:
| Pattern | Best single-sentence trigger |
|---|---|
| ReAct | “I have an open-ended question and am not sure what steps it will take.” |
| Plan-then-Execute | “The task decomposes predictably; I want to minimize LLM calls.” |
| Tree of Thoughts | “There are multiple plausible approaches and I need to find the best one.” |
| Reflection | “Output quality matters most and I want iterative self-improvement.” |
| State Machine | “The workflow has a fixed, auditable set of steps with strict invariants.” |
| Event-Driven | “The agent should activate in response to external signals, not user prompts.” |
To aid in selecting patterns under specific constraints, the table below compares each pattern across the dimensions most relevant to production deployments:
| Pattern | LLM Overhead | Adaptability to Surprises | Auditability | Best For |
|---|---|---|---|---|
| ReAct | Medium (1 call per step) | High (each observation can redirect) | High (full trace) | Open ended tasks, dynamic environments |
| Plan-then-Execute | Low (plan once, execute without re-querying) | Low (plan is fixed upfront) | High (plan is an artifact) | Predictable multi-step tasks with known structure |
| Tree of Thoughts | High (O(B × k) calls per level) | Medium (explores branches before committing) | Medium | Problems with deceptive dead ends or many viable approaches |
| Reflection | Low to medium (~2× per revision round) | Low (same task, iterative polish) | Medium | Quality-critical generation: writing, analysis, code review |
| State Machine | Deterministic (one action per state) | None (transitions are hard coded) | Very High | Fixed-workflow production systems with strict invariants |
| Event-Driven | Minimal (1 invocation per event) | N/A (stateless per invocation) | Medium | Async, trigger-based processing pipelines |
9. Summary
The six single-agent architecture patterns in this article are best understood as a toolkit, not a ladder of maturity. They solve different problems.
ReAct is the default workhorse for open-ended tasks in changing environments. Plan-then-Execute is better when the structure is predictable and you want lower latency or lower cost. Tree of Thoughts is a deliberate search strategy for problems with meaningful branching and deceptive dead ends. Reflection improves output quality by inserting a critique-and-revision loop. State Machine Agents give developers tight control over workflows that must be auditable and policy-constrained. Event-Driven Agents make single-agent systems fit naturally into real production infrastructure where work begins with a trigger, not a user sitting in a chat loop.
Choosing among them is really an exercise in matching architecture to uncertainty, risk, and operating context. A patient-facing medical workflow, an internal research assistant, and an asynchronous ticket-triage system all need different guarantees. The right pattern is the one whose failure modes you can tolerate and whose operational shape matches the problem.
For a treatment of how single agents are composed into larger collaborative systems, see Multi-Agent Systems. For the broader ecosystem of tooling, orchestration, and production deployment that surrounds these patterns, see The Agentic Ecosystem.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!