Imagine debugging a modern ML product without observability. It is like managing an airport where planes keep arriving late, bags go missing, and passengers complain, but the control tower only tells you, “something is wrong.” You do not know whether the delay came from ground operations, weather, security, or the gate assignment.
A single prediction or generation request in ML can travel through an API gateway, a feature store, a cache, a model server, a vector database, and an external LLM provider before the user sees a response. When latency spikes, costs rise, or output quality slips, the root cause is rarely one broken function. It is usually spread across data, infrastructure, model logic, and downstream dependencies.
OpenTelemetry is an observability framework and toolkit that enables the generation, export, and collection of telemetry data, including traces, metrics, and logs.
OpenTelemetry (OTel) gives you the control-tower view. It is an open standard and ecosystem for collecting telemetry. In practice, it helps teams answer questions like these:
- Where did this request actually spend time?
- Which dependency failed first?
- Did the regression affect one model version, one prompt shape, or one traffic segment?
- Did the rollout increase latency, token usage, or error rate?
One of OpenTelemetry’s primary goals is to simplify the instrumentation of applications and systems, regardless of the programming language, infrastructure, or runtime environment involved. The storage (backend) and visualization (frontend) of telemetry data are intentionally delegated to other tools.
For ML systems, that difference is not cosmetic. It is the difference between guessing and knowing.
1. Why observability feels harder in ML systems
Traditional software systems are already complex. ML systems add a second layer of uncertainty: even when the software path is stable, the behavior of the system can still shift.
There are four recurring reasons for this:
- Data changes even when code does not:
Schemas evolve, fields disappear, null rates climb, and value distributions drift. A serving stack can remain technically healthy while the model receives data it was not prepared for. - Model behavior is part of the production surface:
A new model version may be more accurate but slower. A quantized model may reduce cost but behave differently on certain hardware. An LLM prompt change may improve one class of queries while sharply increasing tokens per request. - Infrastructure shapes output quality and latency:
Autoscaling lag, GPU contention, cold starts, network jitter, and cache eviction policies all change the user experience. In ML systems, infrastructure is not a background detail. It directly changes what users observe. - Dependencies multiply quickly:
Modern ML systems often depend on feature stores, vector databases, artifact registries, workflow schedulers, model gateways, safety filters, and third-party inference APIs. Each dependency adds both latency and new failure modes.
This is why debugging is so uncomfortable: symptoms and causes are often separated in both time and place. A slow response may be caused by an upstream cache miss. A bad output may be caused by stale features produced hours earlier. A rollout may look healthy in aggregate while failing only for a specific region, tenant tier, or context length bucket.
OpenTelemetry does not magically fix these problems. It makes them visible enough to debug.
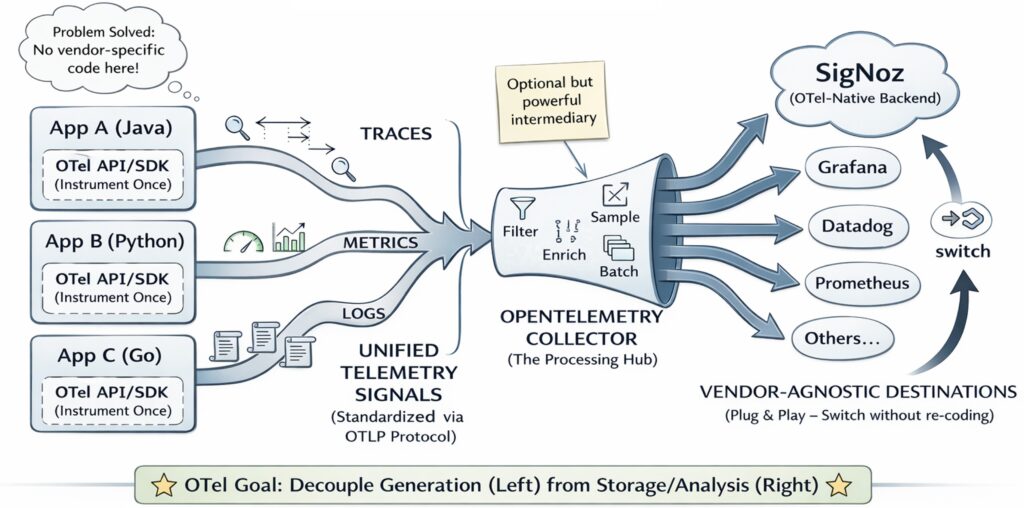
Visualizing the Logging Architecture Evolution
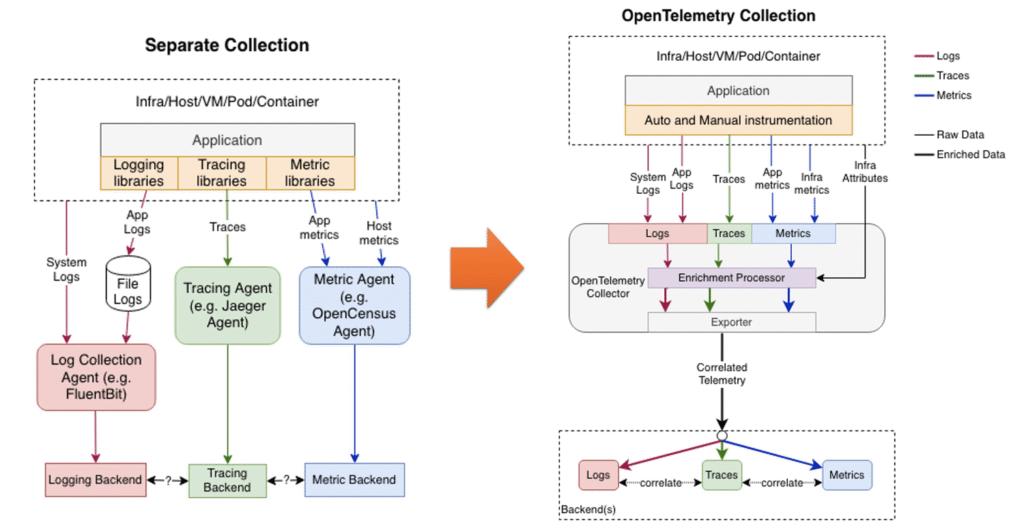
Looking at this diagram, you would see a clear transition from chaos to order. On the left side representing the “old way,” imagine a tangled web where logs, metrics, and traces are completely siloed. Each telemetry type has its own agent, its own collection pipeline, and its own backend.
On the right side, the OpenTelemetry architecture introduces a unified pipeline. The central piece is the OpenTelemetry Collector—acting as a universal translator and router. Instead of managing logs, traces, and metrics through separate channels as in traditional setups, OpenTelemetry centralizes data collection. By using the OpenTelemetry Collector, all telemetry is funneled into a unified backend, enabling seamless data association and visibility.
What OpenTelemetry is, and what it is not
It helps to think of OpenTelemetry as three layers working together:
- A standard for representing telemetry data.
- APIs and SDKs for instrumenting applications and services.
- A Collector for receiving, processing, and exporting telemetry.
OpenTelemetry is not a dashboarding or storage product. You still need a backend such as Grafana, Prometheus, Datadog, Honeycomb, New Relic, Elastic, or OpenSearch to store, query, and visualize the data.
That separation is one of OTel’s strongest advantages: instrument once, keep backend options open.
2. The Three Pillars of Observability
The easiest way to remember OpenTelemetry is this:
- Traces tell the story of one request.
- Metrics summarize the health of many requests.
- Logs capture the detailed evidence at important moments.
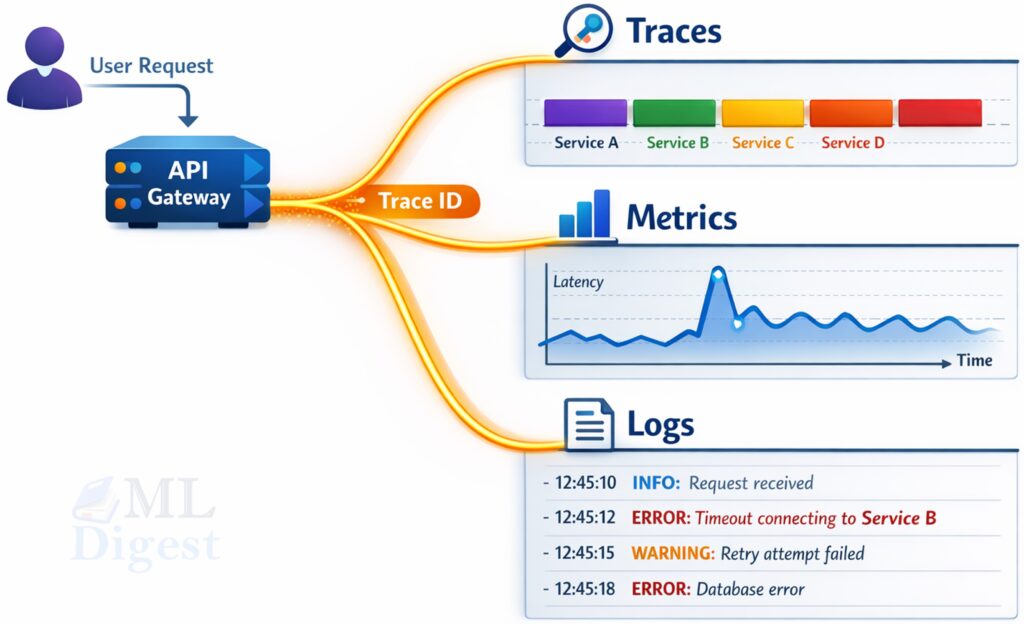
Used together, these signals let you move from “something is wrong” to “this specific dependency caused this specific class of failures.”
2.1 Traces: the path of a single request
A trace represents the lifecycle of a single request or workflow. It is composed of spans, and each span represents one unit of work, such as:
- receiving an HTTP request
- fetching features from an online store
- querying a vector database
- calling an external LLM provider
- running model inference
- writing output to storage
Traces are the best tool for answering questions about:
- latency breakdowns
- dependency bottlenecks
- timeout propagation
- retry behavior
- where a failure first appeared
If p99 latency jumps, traces help you determine whether the time is being spent in retrieval, preprocessing, model inference, prompt construction, or a downstream provider call.
2.2 Metrics: the shape of system health over time
Metrics are numeric time series. In practice, the most useful metric types are counters, gauges, and histograms.
For ML systems, common metrics include:
- request rate
- error rate
- inference latency histograms
- queue depth
- cache hit rate
- GPU memory utilization
- tokens per request and tokens per second
- retrieval hit rate or reranker latency
Metrics are what you use for dashboards, alerting, service-level indicators, and capacity planning. They answer questions like, “Is this system healthy right now?” and “Is it getting worse?”
2.3 Logs: the detailed local evidence
Logs record discrete events with richer local context than metrics usually carry. Good ML-system logs often capture:
- validation failures
- exception traces
- model loading warnings
- feature schema mismatches
- provider response codes
- business decisions with structured fields
On their own, logs can become noisy very quickly. Their real value appears when they are correlated with traces using shared trace and span IDs. Then you can move from a latency spike to the exact request and the exact warning or exception that explains it.
2.4 A practical debugging sequence
In mature systems, the three signals usually work in this order:
- Metrics tell you that a problem exists.
- Traces show where the time or failure accumulated.
- Logs explain the local condition that caused it.
That sequence is worth remembering because it mirrors how most production investigations unfold.
3. How OpenTelemetry connects everything under the hood
The most important technical idea in OpenTelemetry is context propagation. Returning to our airport analogy, imagine context propagation as the unique barcode assigned to a passenger’s checked luggage. No matter which conveyor belt, security scanner, or baggage handler touches the suitcase, they all scan the barcode. This ensures the bag can always be traced back to the specific passenger and flight.
When a request enters your system, it carries tracing context, usually through the W3C traceparent header. Each service extracts that context, creates its own spans, and injects the updated context into downstream requests. That is how one logical request remains connected even as it moves across many physical services.
Without context propagation, telemetry fragments into isolated pieces. You still have spans, but you no longer have a coherent story.
3.1 A useful mathematical model: a trace as a graph
Formally, we can represent a trace $T$ as a directed acyclic graph (DAG):
$$
T = (S, E)
$$
where:
- $S = {s_1, s_2, \dots, s_n}$ is the set of spans representing discrete units of work.
- $E$ is the set of parent-child edges between spans, denoting causality. If $(s_i, s_j) \in E$, then span $s_i$ triggered span $s_j$.
Each span $s_i$ has at least:
- a globally unique
trace_id - a locally unique
span_id - a start time $t_i^{start}$
- an end time $t_i^{end}$
- optional attributes, events, and status
Its duration is calculated simply as:
$$
d_i = t_i^{end} – t_i^{start}
$$
But end-to-end user latency is not simply the sum of all span durations, because some branches run in parallel. What matters operationally is the critical path: the longest dependency chain that determines the final response time.
That distinction matters a great deal in ML systems. If feature fetch and prompt templating run in parallel, optimizing the shorter branch may produce no user-visible improvement at all.
3.2 Spans, attributes, events, resources, and status
These terms are easy to blur together, so it is worth separating them clearly.
Span attributes
Attributes are key-value metadata attached to a span. They make traces filterable and analyzable. Common examples include:
http.methodhttp.routedb.systemml.model.nameml.model.versiongen_ai.request.model
For ML systems, attributes should answer questions that operators repeatedly ask, but they should remain low-cardinality.
Span events
Events are timestamped annotations within a span. They are ideal for important moments that do not deserve their own span, such as:
cache_missretry_startedschema_validation_failedfallback_model_invokedguardrail_blocked_output
Events add narrative detail without turning traces into forests of tiny spans.
Resource attributes
Resource attributes describe the process, service, or runtime producing telemetry. These are critical for grouping and filtering:
service.nameservice.versiondeployment.environment- cloud, host, container, or Kubernetes metadata
If service.name is inconsistent across deployments, dashboards and traces become difficult to interpret almost immediately.
Status
Span status indicates whether an operation succeeded or failed. Status is especially useful for debugging, alerting logic, and selective sampling strategies that retain a higher fraction of failures.
3.3 Where context propagation breaks in practice
Context propagation sounds simple in diagrams, but many real-world trace gaps come from a few recurring breakpoints:
- asynchronous task queues where trace context is not forwarded in message headers
- background threads or worker pools that start work without the current context
- service boundaries implemented with custom HTTP or RPC wrappers that forget to inject headers
- batch jobs that fan out work across partitions without preserving parent-child relationships
This is important in ML platforms because pipelines often combine synchronous APIs, asynchronous workers, and scheduled jobs. If trace context is dropped at any handoff, you still collect telemetry, but you lose the end-to-end narrative. In practice, this often feels like opening a detective novel and discovering that every third chapter is missing.
The Solution: Span Links
To solve this, OpenTelemetry provides Span Links. While parent-child edges are for synchronous or immediate execution, Links are used to associate a span with one or more spans in entirely different traces. For example, when a batch inference job runs, it cannot have thousands of HTTP requests as direct “parents.” Instead, the batch span links to the trace IDs of all the individual messages it pulled off the queue, preserving the narrative without violating the strict parent-child time boundaries.
4. The OpenTelemetry architecture in practice
At a high level, the OTel data path is straightforward:
- Your application, job, or service emits telemetry through an SDK or auto-instrumentation.
- Telemetry is exported over OTLP (the OpenTelemetry Protocol).
- An OpenTelemetry Collector receives, processes, and forwards that data to one or more backends.
4.1 Why the Collector matters so much
The Collector is often the most underestimated part of the stack. In practice, it acts as the operational control plane for observability.
It centralizes concerns such as:
- batching
- retries
- enrichment
- redaction
- routing to multiple backends
- head or tail sampling
- rate limiting and buffering
This separation matters even more in ML environments, where prompts, feature values, and user-generated content can easily leak into telemetry unless they are cleaned or dropped before export.
4.2 Common deployment patterns
There is no universal best deployment pattern. The right choice depends on scale, isolation requirements, and operational maturity.
- Sidecar Collector: strong per-workload isolation, but higher resource overhead.
- DaemonSet or node agent: common in Kubernetes and often a good balance between control and cost.
- Central gateway Collector: simpler to manage centrally, but it becomes shared infrastructure and therefore a potential bottleneck.
4.3 Manual instrumentation and auto-instrumentation solve different problems
This distinction is easy to miss when teams first adopt OpenTelemetry.
Auto-instrumentation is excellent for standard boundaries such as HTTP requests, outgoing client calls, SQL queries, and message consumers. It gives you broad coverage quickly.
Manual instrumentation is what adds business meaning. It is how you mark steps like feature_retrieval, rerank_candidates, llm_guardrail_check, or fraud_rule_evaluation.
For ML systems, the strongest pattern is usually to combine both:
- let auto-instrumentation capture commodity infrastructure interactions
- add manual spans around ML-specific stages that matter for debugging and cost analysis
That combination keeps setup practical while still preserving the domain context that makes traces useful.
5. Where to instrument ML systems
The most common instrumentation mistake is to trace code structure instead of system structure. The most valuable spans usually align with dependency boundaries, not helper functions.
5.1 Online inference APIs
For real-time inference, operators usually need fast answers to questions such as:
- What are p50, p95, and p99 latencies?
- Which model version is serving traffic?
- How much time is spent in feature retrieval, preprocessing, inference, and postprocessing?
- Are failures isolated to one region, one tenant tier, or one dependency?
Useful span boundaries often include:
- request parsing
- authentication and rate limiting
- cache lookup
- feature store fetch
- preprocessing
- model inference
- postprocessing or policy rules
- response serialization
5.2 Batch inference and ETL pipelines
Batch systems need observability just as much as online systems, but the useful granularity is different. Here, you usually care about:
- job duration
- stage-level duration
- retry counts
- rows processed, dropped, or quarantined
- read and write throughput
- data quality failures
A batch job that “succeeds” while quietly processing malformed data is still a production incident. That is why data quality failures deserve first-class treatment as metrics, events, or structured logs.
5.3 Training and fine-tuning pipelines
Training already has specialized tooling such as MLflow and Weights & Biases. OpenTelemetry does not replace those tools; it complements them.
OpenTelemetry is especially useful for:
- orchestration step timings
- dataset load bottlenecks
- storage and registry dependencies
- cluster and GPU utilization
- artifact movement across services
Loss curves, evaluation plots, and experiment comparisons belong in experiment-tracking tools. Pipeline observability and infrastructure observability fit naturally in OTel.
5.4 LLM and RAG applications
LLM systems are especially good candidates for OpenTelemetry because the user-visible response often depends on several chained components:
- prompt construction
- retrieval
- reranking
- tool calls
- provider latency
- output parsing
- safety checks and guardrails
Good instrumentation helps answer subtle but important questions:
- Did latency come from retrieval or generation?
- Did a prompt-template change increase token usage?
- Did one provider or one deployment fail more often?
- Are failures correlated with long contexts, large tool outputs, or specific model families?
6. A concrete example: from symptom to root cause
Suppose a fraud-scoring endpoint becomes slower after a rollout. From the outside, it looks like one API call. Inside, it is several smaller steps stitched together:
- fetch features
- preprocess the feature vector
- run model inference
- apply business rules
If you wrap the entire flow in one giant span, you only learn that the request was slow. If you instrument each meaningful boundary, you learn why it was slow.
6.1 Instrumented Python example
A python example is available here and here. A python project is available here.
Below is a simplified example of how to instrument a fraud inference API. The code is intentionally simple to focus on the instrumentation patterns rather than the business logic.
import random
import time
# `trace` is the high-level OpenTelemetry API used to create spans.
from opentelemetry import trace
# `Resource` describes the service that emits telemetry.
from opentelemetry.sdk.resources import Resource
# `TracerProvider` holds tracing configuration for this process.
from opentelemetry.sdk.trace import TracerProvider
# A span processor decides how spans are buffered and exported.
from opentelemetry.sdk.trace.export import BatchSpanProcessor, ConsoleSpanExporter
# Resource attributes identify the service independently of individual requests.
resource = Resource.create(
{
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev",
}
)
# The provider owns the tracer configuration for the current process.
provider = TracerProvider(resource=resource)
# Batch exporting is closer to production behavior than exporting every span immediately.
# The console exporter is useful for learning because you can inspect spans locally.
provider.add_span_processor(BatchSpanProcessor(ConsoleSpanExporter()))
# Register this provider globally so future calls to `trace.get_tracer(...)` use it.
trace.set_tracer_provider(provider)
# A tracer is the object that creates spans for a specific module or subsystem.
tracer = trace.get_tracer("fraud_inference")
def fetch_features(user_id: str) -> dict:
# Simulate an I/O-bound dependency such as Redis or an online feature store.
time.sleep(random.uniform(0.01, 0.05))
return {"age": 30, "transaction_count": 5, "country": "US"}
def preprocess(features: dict) -> list[float]:
# Simulate lightweight feature transformation before inference.
time.sleep(0.01)
return [features["age"], features["transaction_count"]]
def predict_proba(x: list[float]) -> float:
# Simulate model execution latency and return a fake probability.
time.sleep(random.uniform(0.08, 0.20))
return random.uniform(0.0, 1.0)
def handle_inference_request(user_id: str) -> dict:
# The root span represents the full user-visible request.
with tracer.start_as_current_span("inference.request") as request_span:
# These attributes make the trace searchable by model identity and request type.
request_span.set_attribute("ml.model.name", "fraud_detection_xgboost")
request_span.set_attribute("ml.model.version", "v2.1.0")
request_span.set_attribute("ml.inference.framework", "xgboost")
request_span.set_attribute("ml.request.type", "single")
# Child spans break the request into meaningful operational stages.
with tracer.start_as_current_span("features.fetch") as feature_span:
features = fetch_features(user_id)
# Prefer stable, low-cardinality attributes that help debugging.
feature_span.set_attribute("feature.store", "redis_online_store")
feature_span.set_attribute("feature.count", len(features))
# Preprocessing is its own stage because it can regress independently.
with tracer.start_as_current_span("features.preprocess"):
x = preprocess(features)
# Model inference is often the dominant latency contributor in ML APIs.
with tracer.start_as_current_span("model.infer") as infer_span:
score = predict_proba(x)
infer_span.set_attribute("ml.inference.batch_size", 1)
# Bucketed outputs are often safer than logging raw values at large scale.
infer_span.set_attribute(
"ml.output.score_bucket",
"high" if score > 0.8 else "normal",
)
# Postprocessing captures business logic that turns scores into decisions.
with tracer.start_as_current_span("postprocess") as post_span:
decision = score > 0.8
post_span.set_attribute("ml.decision", "block" if decision else "allow")
if decision:
# Events annotate an important moment inside a span without creating a new span.
post_span.add_event(
"rule_triggered",
{"rule_name": "high_risk_threshold"},
)
return {"score": score, "decision": decision}
if __name__ == "__main__":
result = handle_inference_request("user_12345")
print(result)
# Force a flush so buffered spans are exported before the script exits.
provider.force_flush()Click to see the output.
{'score': 0.9170080536451304, 'decision': True}
{
"name": "features.fetch",
"context": {
"trace_id": "0xa25279d6bd4a89a1864acf3093591a8c",
"span_id": "0xdd3b3d3c745b5192",
"trace_state": ""
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x77931b30d77dc765",
"start_time": "2026-03-10T15:06:49.911350Z",
"end_time": "2026-03-10T15:06:49.927409Z",
"status": {
"status_code": "UNSET"
},
"attributes": {
"feature.store": "redis_online_store",
"feature.count": 3
},
"events": [],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.38.0",
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev"
},
"schema_url": ""
}
}
{
"name": "features.preprocess",
"context": {
"trace_id": "0xa25279d6bd4a89a1864acf3093591a8c",
"span_id": "0xb587cbed0d7653fa",
"trace_state": ""
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x77931b30d77dc765",
"start_time": "2026-03-10T15:06:49.927624Z",
"end_time": "2026-03-10T15:06:49.937842Z",
"status": {
"status_code": "UNSET"
},
"attributes": {},
"events": [],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.38.0",
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev"
},
"schema_url": ""
}
}
{
"name": "model.infer",
"context": {
"trace_id": "0xa25279d6bd4a89a1864acf3093591a8c",
"span_id": "0x9a1bd4fa51abae66",
"trace_state": ""
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x77931b30d77dc765",
"start_time": "2026-03-10T15:06:49.938102Z",
"end_time": "2026-03-10T15:06:50.039371Z",
"status": {
"status_code": "UNSET"
},
"attributes": {
"ml.inference.batch_size": 1,
"ml.output.score_bucket": "high"
},
"events": [],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.38.0",
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev"
},
"schema_url": ""
}
}
{
"name": "postprocess",
"context": {
"trace_id": "0xa25279d6bd4a89a1864acf3093591a8c",
"span_id": "0x2ccf1fc03fd57a49",
"trace_state": ""
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x77931b30d77dc765",
"start_time": "2026-03-10T15:06:50.039566Z",
"end_time": "2026-03-10T15:06:50.039639Z",
"status": {
"status_code": "UNSET"
},
"attributes": {
"ml.decision": "block"
},
"events": [
{
"name": "rule_triggered",
"timestamp": "2026-03-10T15:06:50.039614Z",
"attributes": {
"rule_name": "high_risk_threshold"
}
}
],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.38.0",
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev"
},
"schema_url": ""
}
}
{
"name": "inference.request",
"context": {
"trace_id": "0xa25279d6bd4a89a1864acf3093591a8c",
"span_id": "0x77931b30d77dc765",
"trace_state": ""
},
"kind": "SpanKind.INTERNAL",
"parent_id": null,
"start_time": "2026-03-10T15:06:49.911217Z",
"end_time": "2026-03-10T15:06:50.039657Z",
"status": {
"status_code": "UNSET"
},
"attributes": {
"ml.model.name": "fraud_detection_xgboost",
"ml.model.version": "v2.1.0",
"ml.inference.framework": "xgboost",
"ml.request.type": "single"
},
"events": [],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.38.0",
"service.name": "fraud-inference-api",
"service.version": "2.1.0",
"deployment.environment": "dev"
},
"schema_url": ""
}
}Reading the trace as a tree
One useful way to read this example is to picture the emitted trace as a small tree rather than as a flat list of function calls:
inference.request
├── features.fetch
├── features.preprocess
├── model.infer
└── postprocessThat picture matters because trace viewers usually present latency as a hierarchy. The root span tells you the end-to-end latency seen by the caller. The child spans explain where that time accumulated. In a real system, one of those child spans could itself contain deeper spans such as a Redis call, an HTTP request, or a GPU execution step.
6.2 What this example gets right
This code is intentionally simple, but it demonstrates several habits that scale well:
- the root span models one user-visible request
- each meaningful dependency boundary gets its own child span
- resource attributes identify the service and environment
- ML-specific attributes add model and decision context
- the code records an event for a business-rule trigger
- it avoids attaching raw user identifiers or raw feature values to telemetry
That last point is crucial. Telemetry should help you debug production systems, not quietly create privacy, security, or cardinality problems.
6.3 What a real investigation would reveal
Imagine that p95 latency rises after a deployment. A healthy debugging path might look like this:
- a latency histogram shows that only the new model version regressed
- traces show that
model.inferdominates the critical path - correlated logs show repeated warm-up messages on newly scaled pods
- the team concludes that autoscaling plus model cold starts caused the regression
Notice what changed: the team did not stop at “the endpoint is slow.” It located the exact stage, the exact traffic segment, and the likely reason.
6.4 What you would change in production
In production, you would usually make four changes:
- replace the console exporter with an OTLP exporter that sends data to a Collector
- combine manual spans with automatic instrumentation for HTTP frameworks, database clients, and RPC libraries
- add metrics such as latency histograms and error counters alongside traces
- define a small, stable vocabulary for ML-specific attributes
6.5 Failure handling and status capture you would likely add next
There is one more improvement worth calling out explicitly: the example shows the happy path, but most production value comes from how traces behave on unhappy paths.
In a real inference service, you would usually also:
- record exceptions on spans when feature fetch, inference, or postprocessing fails
- set span status to error so failed requests are easy to filter
- add timeout or retry events when a dependency becomes slow
- attach low-cardinality failure metadata such as
error.type,dependency.name, orretry.count
This matters because a trace without success or failure semantics is like a flight recorder without altitude data. You can still inspect it, but the fastest route to the root cause is missing.
7. Metrics and logs that pair well with traces
Tracing is often the first place teams start, but the strongest observability setups use all three signals together.
7.1 Metrics worth tracking for model-serving systems
For an inference API, a compact but effective metrics set often includes:
- request count
- error count
- latency histogram
- request count by model version
- cache hit rate
- queue depth
- dependency-specific error count
- token usage for LLM systems
The key point is that averages are not enough. Average latency can look fine while p99 becomes unacceptable. Histograms are more useful because they let you compute percentiles and reason about tail behavior.
7.2 Logs worth correlating
Structured logs are most helpful when they capture state transitions and unusual conditions, such as:
- validation errors
- retry attempts
- upstream rate-limit responses
- model load and warm-up messages
- schema or feature availability warnings
- fallback-model activation
The rule of thumb is simple: log enough to explain failures, but not so much that the signal disappears into noise.
7.3 The missing bridge: exemplars and correlation fields
One advanced but highly practical idea is to make it easy to jump from an aggregate metric to an individual trace.
There are two common ways to do that:
- Exemplars: some observability backends can attach representative trace references to histogram buckets or metric points.
- Correlation fields in logs: including trace and span identifiers in structured logs lets operators pivot from a suspicious request trace to the exact log lines emitted during that request.
This bridge is powerful because investigations rarely begin with a trace. They usually begin with a chart, an alert, or a log search. The easier it is to pivot across signals, the faster teams move from symptom to root cause.
8. Production practices that matter
8.1 Instrument dependency boundaries, not every function
The best spans usually mark boundaries like these:
- external network calls
- storage lookups
- model invocations
- expensive CPU or GPU stages
- orchestration transitions
If every helper function becomes a span, traces become dense but not informative.
8.2 Control cardinality aggressively
One of the fastest ways to make observability expensive and hard to query is to attach highly unique values to attributes. Common mistakes include:
- raw user IDs
- full prompts
- full completion text
- session IDs
- unbounded URLs with query strings
High-cardinality attributes explode storage costs, degrade query performance, and make metrics backends harder to operate.
Prefer bounded alternatives such as:
- prompt length buckets
- token counts
- tenant tier instead of tenant ID
- route templates instead of full URLs
- model version instead of run-specific artifact paths
8.3 Keep naming consistent
OpenTelemetry already defines semantic conventions for HTTP, databases, messaging, and RPC. Use them where they exist.
For ML- and LLM-specific metadata, establish a small internal vocabulary and keep it consistent. Teams quickly get into trouble when one service emits model.version, another emits ml_model_version, and a third emits modelVersion.
8.4 Sample traces deliberately
At scale, keeping every trace may be too expensive. Sampling is the practical answer, but it should reflect how incidents are investigated.
A common pattern is:
- sample a small percentage of healthy requests
- retain a much larger fraction of error traces
- keep full traces for important tenants, rollout canaries, or debugging windows
In other words, do not optimize only for volume. Optimize for investigative value.
8.5 Redact sensitive information early
ML systems often handle prompts, documents, features, and outputs that may contain private or proprietary information. The safest pattern is to redact, hash, or drop sensitive fields before export, ideally in the Collector or before telemetry leaves the process.
8.6 Separate observability from evaluation
This distinction is easy to miss. Observability tells you what happened in production. Evaluation tells you whether the model behavior is good.
You need both, but they answer different questions. A request can be fast and fully traced while still being semantically wrong. Conversely, an accurate model can still create incidents if retrieval is slow or a provider is unstable.
8.7 Common anti-patterns that quietly reduce observability value
There are several failure modes that look like instrumentation progress but produce weak operational outcomes:
- creating many tiny spans for helper functions instead of a few spans for dependency boundaries
- attaching raw prompts, documents, or user identifiers as searchable attributes
- changing span names across services for the same logical stage
- capturing traces but not retaining enough failed traces to debug incidents
- instrumenting latency but ignoring queueing, retries, and fallback behavior
These anti-patterns are costly because they increase telemetry volume faster than they increase understanding. Good observability is not just about collecting more data. It is about collecting the right structure.
9. A pragmatic rollout plan
The best OTel adoption plans are incremental.
9.1 Start with one critical path
Instrument one workflow that matters to users or revenue, such as:
- one online inference endpoint
- one batch scoring pipeline
- one RAG request path
This keeps scope small while still generating useful feedback.
9.2 Add only high-value metadata first
Begin with a minimal set of attributes that you know will help investigations:
service.nameservice.versiondeployment.environmentml.model.nameml.model.version- low-cardinality dependency metadata
Then add more only when the extra fields clearly improve debugging.
9.3 Connect traces, metrics, and logs early
Many teams instrument traces first and stop there. That is useful, but incomplete. The real payoff appears when the three signals reinforce one another.
An ideal investigation flow looks like this:
- an alert fires because p99 latency increased
- metrics narrow the affected service and time window
- traces reveal the slow dependency or critical-path stage
- correlated logs explain the exact failure mode
That is what observability maturity looks like in practice.
9.4 A minimal starter checklist
If a team wanted to operationalize this article with minimal overhead, a strong first version would be:
- instrument one user-facing path with a root span and three to five child spans
- add
service.name,service.version,deployment.environment, and one or two stable ML attributes - emit one latency histogram and one error counter per critical endpoint
- ensure logs include trace identifiers for correlation
- verify that failed requests are sampled at a higher rate than healthy ones
- review exported fields for privacy and cardinality before broad rollout
That checklist is small on purpose. In observability, a narrow system that teams actually use is better than an ambitious design that never becomes part of incident response.
10. Summary
OpenTelemetry gives ML teams a shared language for understanding complex systems in production. It helps you see one request end to end, understand aggregate health over time, and connect incidents to the events that caused them.
The core ideas are simple:
- traces explain one request
- metrics summarize many requests
- logs preserve detailed evidence
- context propagation keeps distributed work connected
- the Collector keeps instrumentation operationally manageable and vendor-neutral
For ML systems, the most important habit is to instrument the boundaries that actually matter: feature retrieval, model inference, vector search, batch stages, and external providers. Start with one critical path, keep metadata low-cardinality and privacy-aware, and grow the system only where it improves investigations.
That is usually enough to turn observability from an afterthought into an engineering advantage.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!