
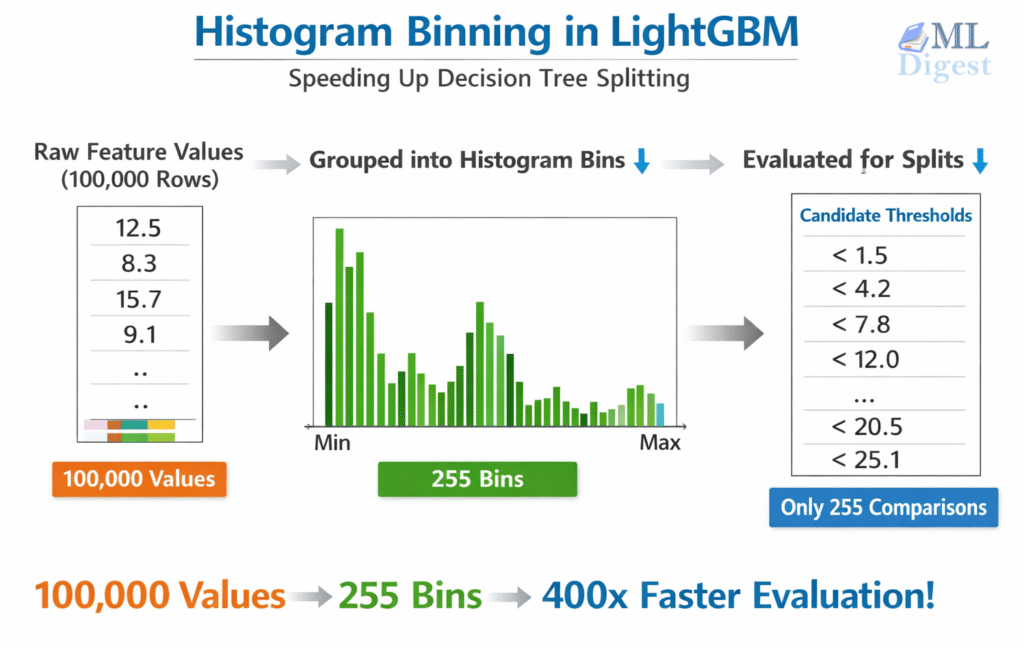
The Illustrated LightGBM: A Beginner-Friendly Guide
In tabular machine learning, the winning recipe is often not a flashy architecture but strong features plus a fast, reliable […]
The Illustrated LightGBM: A Beginner-Friendly Guide Read More »
In tabular machine learning, the winning recipe is often not a flashy architecture but strong features plus a fast, reliable […]
The Illustrated LightGBM: A Beginner-Friendly Guide Read More »
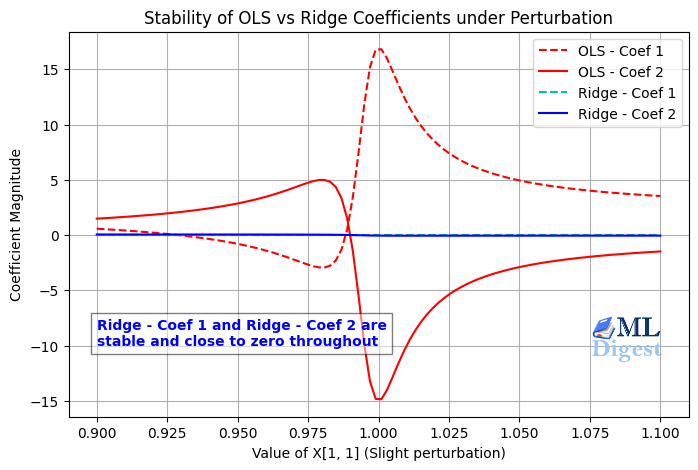
When two or more features in a regression model are highly correlated, it becomes difficult to determine their individual impact.
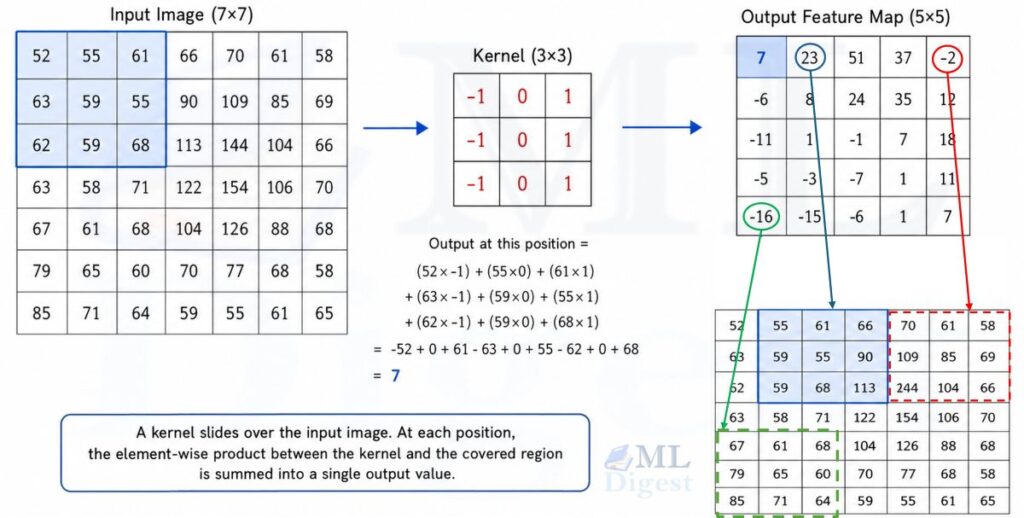
Imagine you are trying to recognize a cat in a photograph. You do not scan the entire image at once.
Convolutional Neural Networks (CNN) Made Easy: An Illustrated Deep Dive Read More »
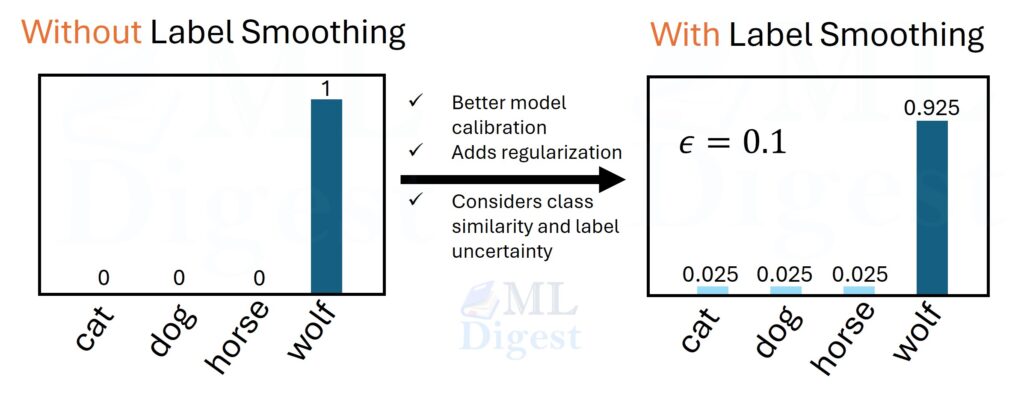
Imagine a teacher grading a multiple-choice exam. If the teacher says, “Only this one answer has any value, and all
Label Smoothing: Intuition, Mathematics, Gradients, and Practical Use Read More »
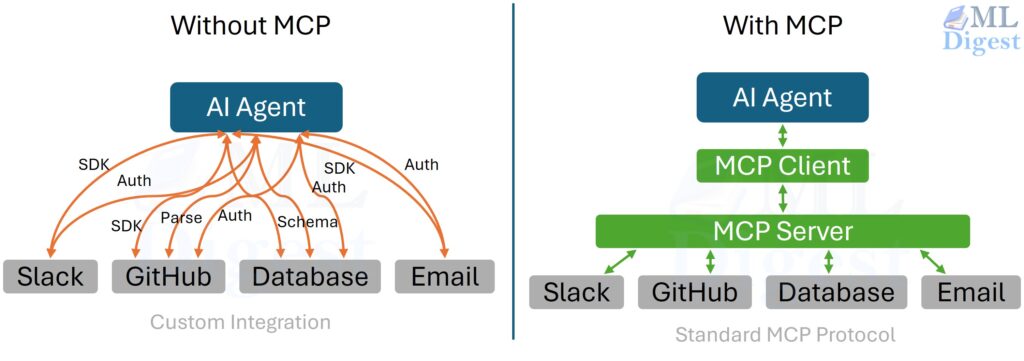
Imagine a desk full of devices with no common port standard. Your monitor needs one cable, your keyboard another, your
The Model Context Protocol (MCP): The USB-C Port for AI Tools and Data Read More »
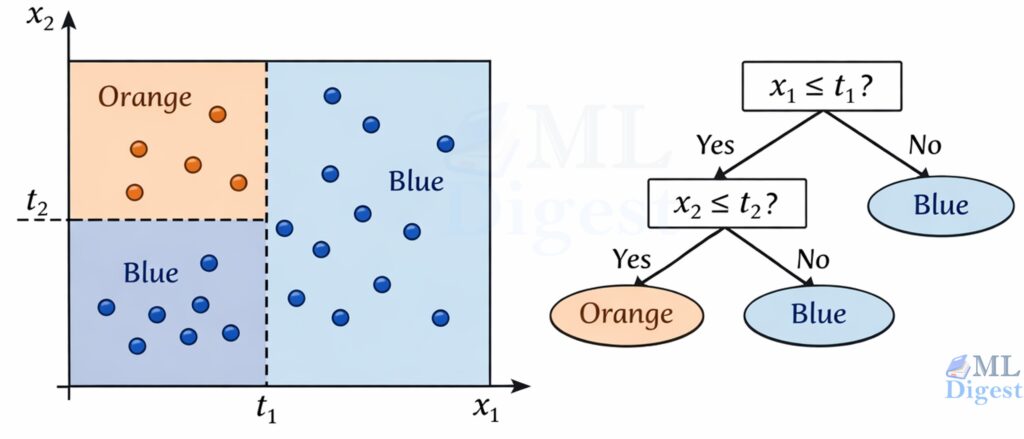
Decision trees are one of the simplest ways to turn data into a sequence of human-readable rules. You can think
How Decision Trees Work: A Practical Machine Learning Guide Read More »
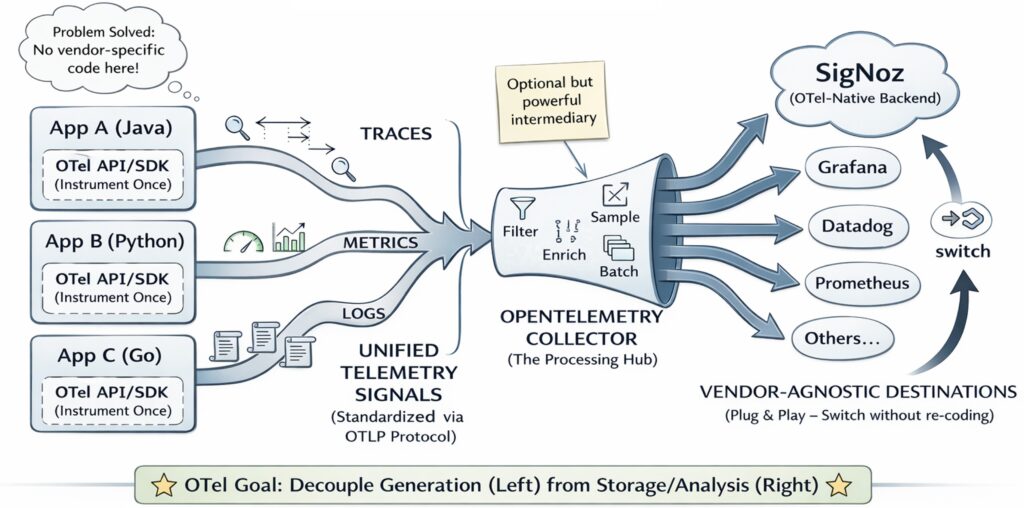
Imagine debugging a modern ML product without observability. It is like managing an airport where planes keep arriving late, bags
OpenTelemetry for ML Systems: Practical Observability That Explains What Happened Read More »
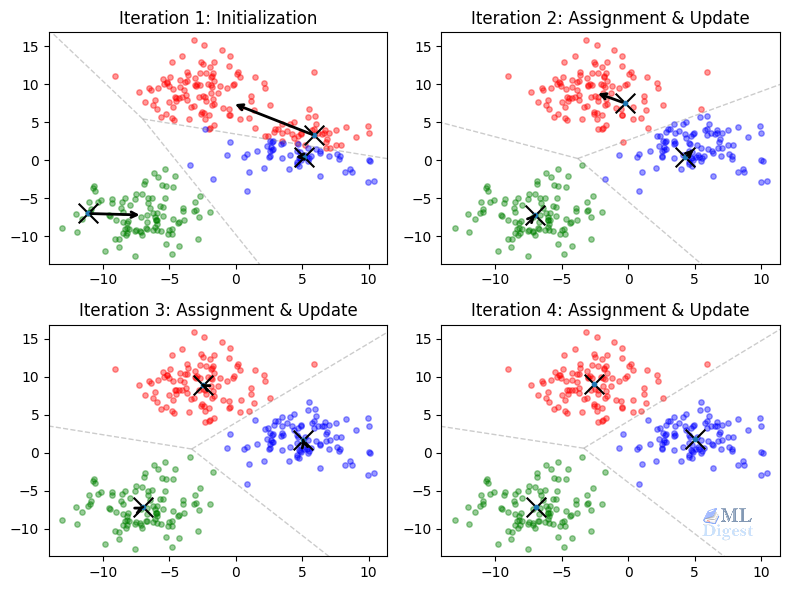
Imagine that you need to open $K$ new coffee shops in a city. You want each person to walk to
Understanding K-Means Clustering: Intuition, Math, and Practical Implementation Read More »
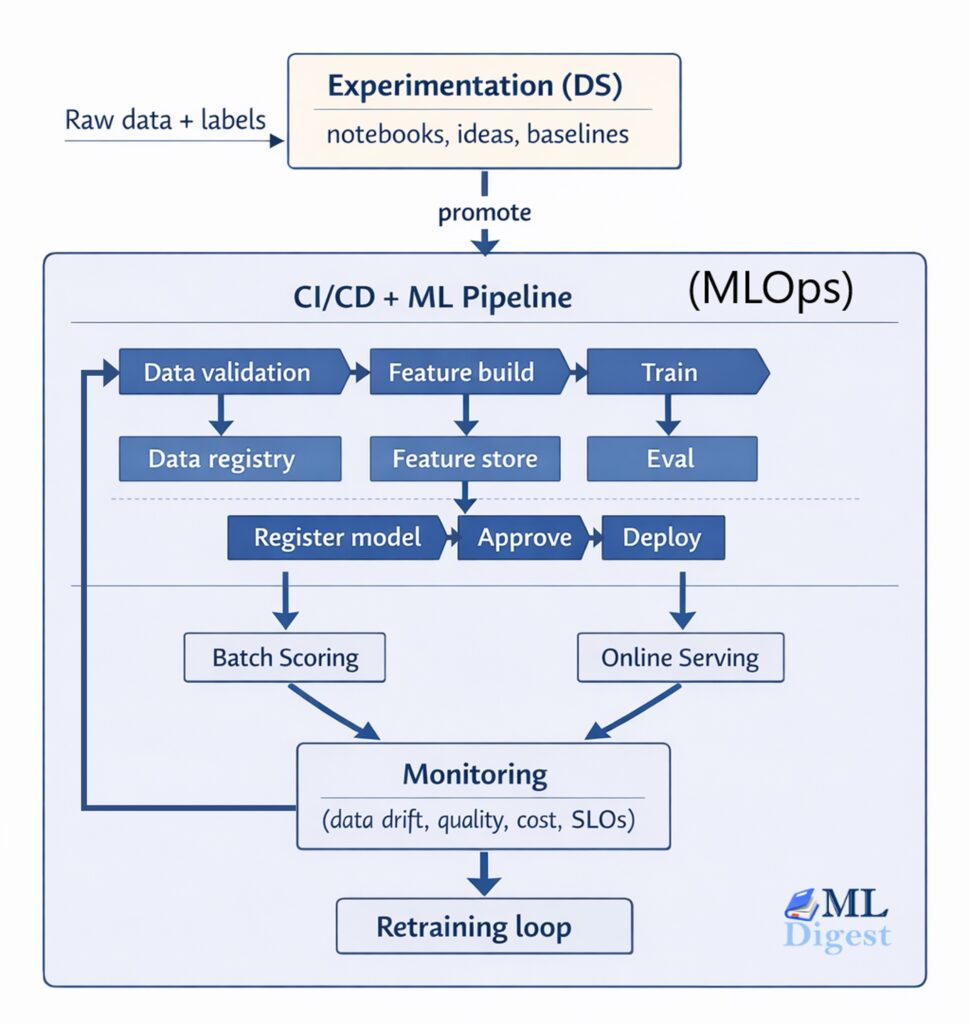
Think of a machine learning model as a high-performance engine prototype sitting on a pristine workbench. It might run beautifully
MLOps (Machine Learning Operations): From a Notebook to a Reliable Production System Read More »

Introduction: The Broken Yardstick Imagine you are a textile factory manager in the early 19th century. For years, your entire
Strategic Talent Evaluation in the Age of Artificial Intelligence Read More »
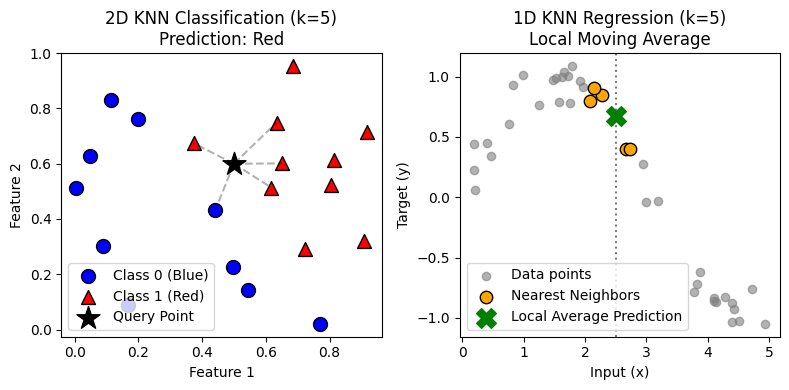
There is an old proverb that perfectly captures the intuition behind one of the most fundamental algorithms in machine learning:
k-Nearest Neighbors (KNN): From Geometry to Algorithms Read More »
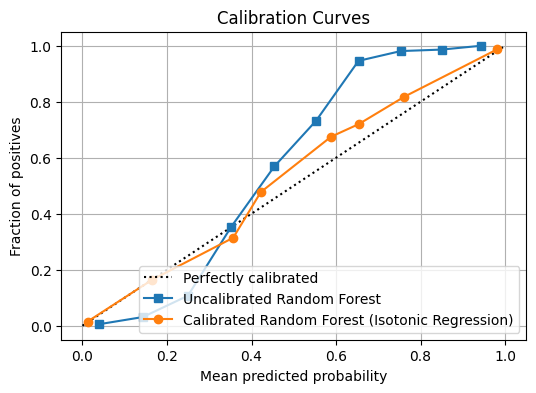
1. The Intuition: The Overconfident Weather Forecaster Imagine planning a weekend picnic. You check two weather applications. You cancel the
Model Calibration: When Your Model’s Confidence Actually Matters Read More »