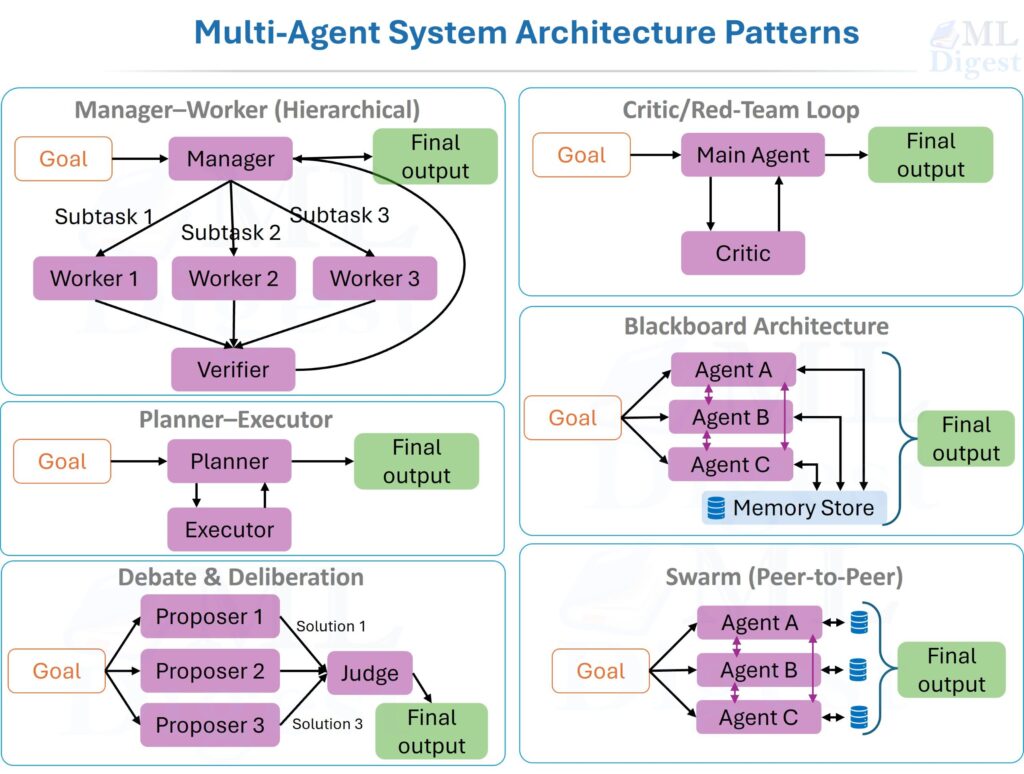
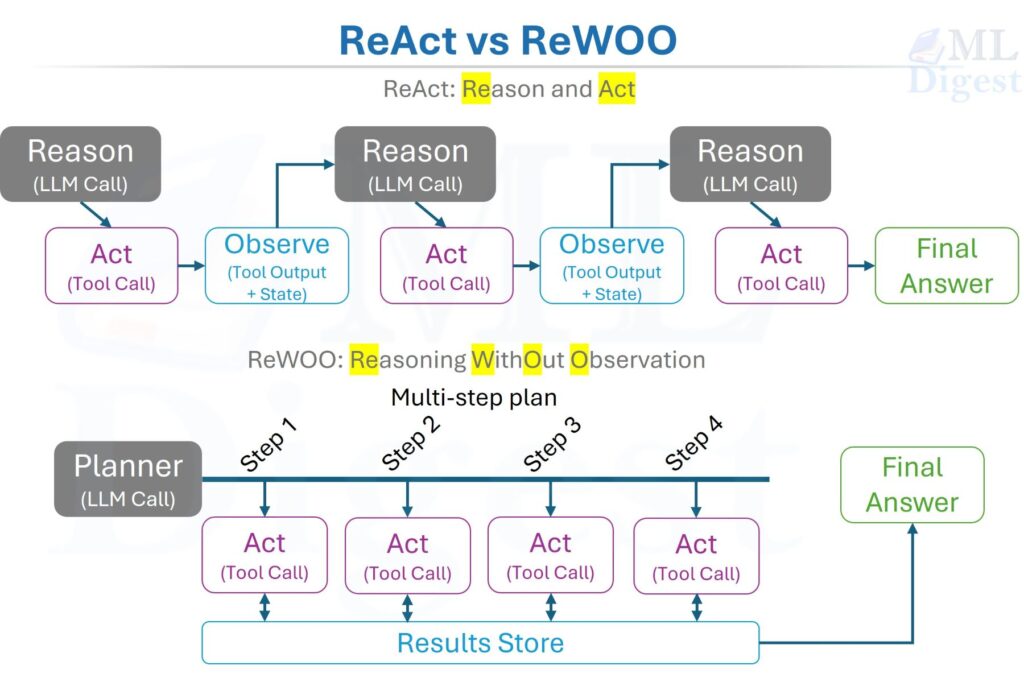
Imagine hiring a new teammate who can search the web, write code, call APIs, and make decisions without asking for permission at every step. You would not evaluate that teammate by grading a single final sentence. You would watch how they plan, what tools they choose, whether they recover from mistakes, how much time they spend, and whether they stay safe while working under pressure.
That is exactly why evaluating agentic systems is harder than evaluating a plain text generator. An agent does not simply produce an answer. It perceives, plans, acts, observes feedback, updates its internal state, and tries again. The final answer matters, but so does the path the system took to get there.
This article explains how to evaluate agentic systems rigorously. We will start with the intuition, move into the formal view, cover the metrics that actually matter in practice, and then build a small runnable evaluation harness in Python. Along the way, we will use examples from agent benchmarks such as AgentBench, GAIA, SWE-bench, and tooling such as OpenAI Evals, Inspect AI, and LangSmith.
If you want a broader architectural backdrop before diving into metrics, agentic ecosystems is a useful companion because it frames how planners, tools, memory, and orchestration combine into a working system.
Before collecting metrics, define three anchors clearly: the task contract, the operating budget, and the risk boundary. Most evaluation confusion comes from measuring the wrong thing, measuring it under the wrong budget, or ignoring the actual failure cost when the system is deployed.
1. Why Agent Evaluation Is Different
For a standard LLM task, evaluation often reduces to a simple mapping:
- input prompt
- model output
- reference answer or judge score
That is workable for translation, summarization, or short-form question answering. It breaks down for agents because agents interact with an environment over multiple steps.
An agentic system usually includes several moving parts:
- a planner or policy that decides what to do next
- tool calls such as search, retrieval, code execution, or API requests
- a memory mechanism that carries state across steps
- a stopping policy that decides when the task is complete
- safety rules that constrain behavior
This means a strong evaluation must answer several questions at once:
- Did the agent solve the task?
- Did it do so efficiently?
- Did it take a safe and policy-compliant route?
- Was the result reproducible across seeds, inputs, and environment variation?
- Can we explain why it failed when it failed?
In practice, many production regressions appear in the gaps between these questions. The base model may be capable enough to solve the task, while the tool wrapper is brittle. The planner may select a sensible strategy, while the stopping rule terminates too early. Good evaluation makes those failure boundaries visible.
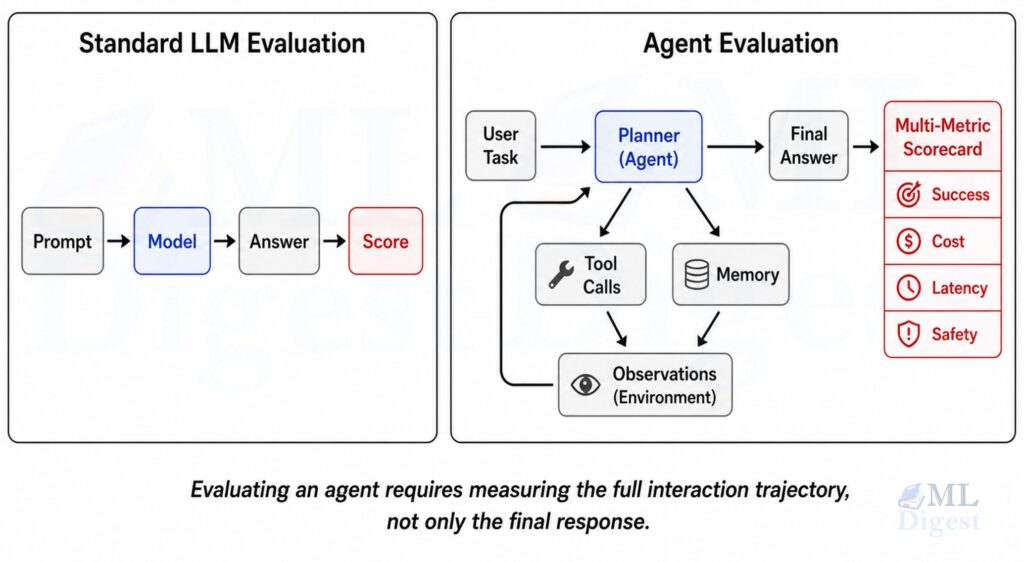
If you only measure final-answer accuracy, you will miss many important failure modes. A system can get the correct result for the wrong reason, or fail cheaply and safely versus fail expensively and dangerously. Those distinctions matter in production.
2. What Exactly Are We Evaluating?
Before picking metrics, define the object under evaluation. In practice, the term agentic system can refer to at least four different layers. Think of them as separate floors of a building: a structural crack on the ground floor is a fundamentally different problem from a broken fixture on the top floor, and diagnosing the right floor first is what makes a fix tractable.
2.1 Base Model Capability
This is the underlying language model’s raw competence: reasoning, coding, retrieval usage, instruction following, and tool calling reliability.
2.2 Agent Policy
This is the control logic that decides when to think, which tool to call, how to branch, when to retry, and when to stop. Many of those choices are concrete policy patterns, such as reflection and self-critique, and they should be evaluated differently from simple one-shot prompting.
2.3 System Integration
This includes prompts, memory, tool wrappers, parsers, retries, timeouts, and orchestration. Many real failures live here rather than in the base model.
2.4 Deployment Behavior
This is how the full system behaves under real traffic: latency, cost, user satisfaction, recovery from environment noise, and policy adherence over time.
These layers should not be conflated. If a benchmark score drops, you want to know whether the root cause is the model, the prompt, the tool interface, the environment, or the evaluation harness itself.
3. A Formal View: Agent Evaluation as Sequential Decision Assessment
The cleanest mathematical lens comes from sequential decision making. An agent interacts with an environment over time steps $t = 1, 2, \dots, T$.
At each step:
- the environment is in state $s_t$
- the agent receives an observation $o_t$
- the agent chooses an action $a_t$
- the environment transitions to $s_{t+1}$
- the system may receive a reward or outcome signal $r_t$
Think of a trajectory as the complete written record of one agent session: every observation the agent received, every action it chose, and every outcome the environment returned in response. Formally, the trajectory is:
$$
\tau = (o_1, a_1, r_1, o_2, a_2, r_2, \ldots, o_T, a_T, r_T)
$$
In classical reinforcement learning, we often optimize expected discounted return:
$$
J(\pi) = \mathbb{E}_{\tau \sim \pi}\left[\sum_{t=1}^{T} \gamma^{t-1} r_t\right]
$$
For episodic agent tasks with a natural endpoint, $\gamma$ is commonly set to $1$, making the objective equivalent to maximizing total unweighted reward over the episode. For open-ended or long-horizon tasks, a discount $\gamma < 1$ can prevent optimization from being dominated by distant, uncertain outcomes.
For practical agent evaluation, this is useful but incomplete. Real-world agentic systems usually require a multi-objective score, not a single reward.
A more realistic utility function is:
$$
U(\tau) = \alpha \cdot S(\tau) – \beta \cdot C(\tau) – \lambda \cdot L(\tau) – \mu \cdot R(\tau)
$$
Where:
- $S(\tau)$ is task success or quality
- $C(\tau)$ is monetary cost, such as tokens or tool usage
- $L(\tau)$ is latency
- $R(\tau)$ is risk, such as safety violations or policy breaches
- $\alpha, \beta, \lambda, \mu$ reflect business priorities
This equation captures a practical truth: the best agent is not the one that only solves the most tasks. It is the one that solves the right tasks at acceptable cost, speed, and risk.
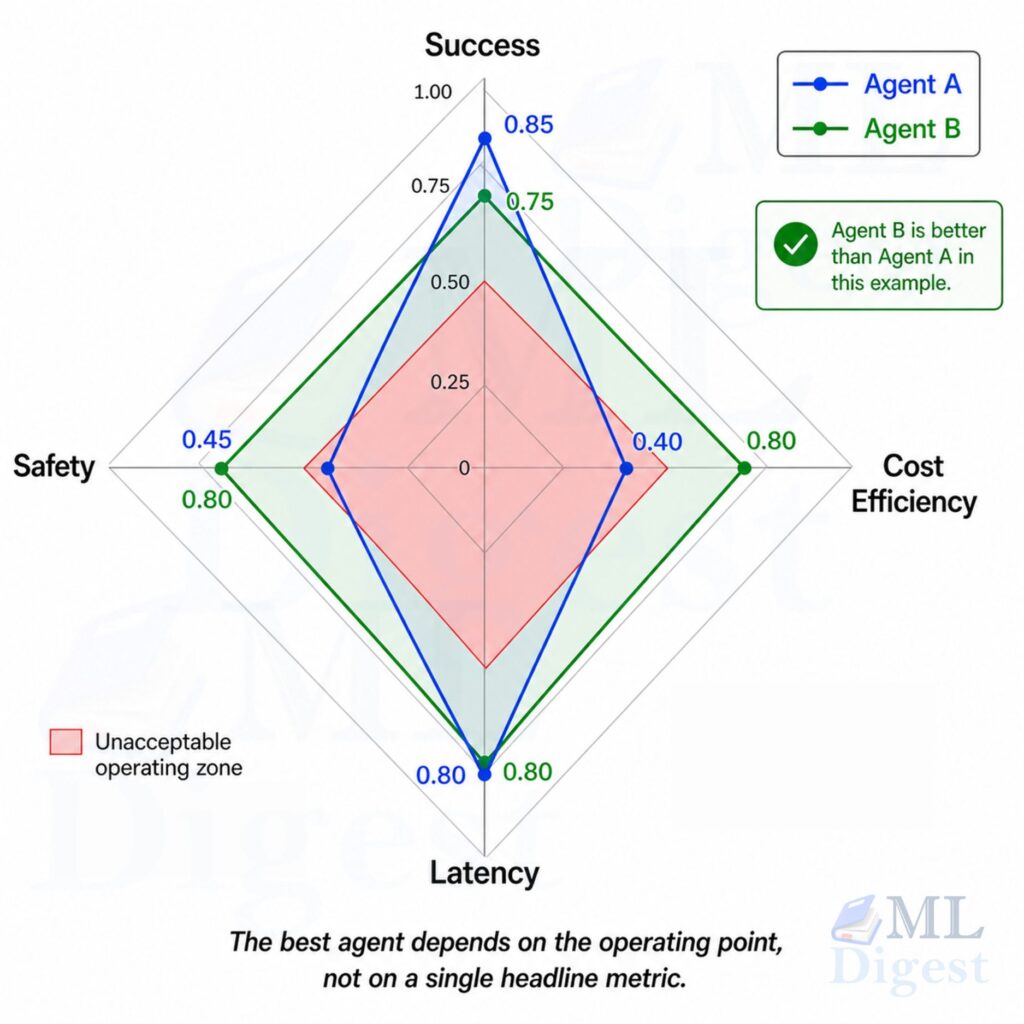
4. Core Evaluation Dimensions
4.1 Task Success
This is the first metric everyone looks at, and rightly so. But success needs a precise definition.
Common forms include:
- exact match for structured outputs
- unit test pass rate for coding tasks
- environment-defined completion flags
- human-graded correctness
- model-graded rubric scores when human grading is too expensive
A widely used approach for model-graded scoring is LLM-as-judge, where a capable language model is prompted with a rubric to evaluate agent outputs. The paper Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena provides an early systematic study of this technique, including its failure modes. LLM judges are fast and scalable, but they carry their own biases and must be validated against human ratings before being trusted in production.
For a benchmark with $N$ tasks, the simplest success rate is:
$$
\hat{p} = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[\text{task } i \text{ solved}]
$$
Where $\mathbb{1}[\cdot]$ is the indicator function, which equals 1 if the stated condition is true and 0 otherwise.
For reporting uncertainty, the standard error of a Bernoulli success rate is:
$$
\text{SE}(\hat{p}) = \sqrt{\frac{\hat{p}\,(1 – \hat{p})}{N}}
$$
And an approximate $95\%$ confidence interval is:
$$
\hat{p} \pm 1.96 \cdot \text{SE}(\hat{p})
$$
This becomes important when comparing models whose scores differ by only one or two percentage points.
4.2 Trajectory Quality
Two agents may both succeed, but one may wander through ten unnecessary steps, call dangerous tools, and require retries. Trajectory quality measures the path rather than only the destination.
Useful trajectory signals include:
- number of steps taken
- number of invalid actions
- number of recovery steps after an error
- proportion of useful tool calls
- branching stability, meaning whether the agent revises the plan excessively
A simple efficiency-normalized success score can be defined as:
$$
Q_{\text{traj}} = \frac{\mathbb{1}[\text{success}]}{1 + \kappa \cdot (T – T_{\min})}
$$
Here $T$ is the number of steps taken, $T_{\min}$ is a reasonable lower bound for the task, and $\kappa > 0$ controls how steeply to penalize longer trajectories. A value of zero is assigned to any failed run regardless of step count.
4.3 Tool Use Quality
Agents often fail not because the base model is weak, but because tool selection and tool argument generation are brittle. The model may pick the right broad strategy but then call the wrong API, pass a malformed argument, or fail to interpret an error response.
That is also why evaluation should distinguish plain text reasoning from tool-integrated reasoning, where the agent’s quality depends on how well it decides to externalize work into tools instead of only generating tokens.
You should measure:
- tool selection accuracy
- parameter correctness
- tool error rate
- retry behavior after tool failure
- fraction of unnecessary tool calls
- proportion of tasks solved without any tool when a tool was actually needed
This is especially important in browser agents, coding agents, and enterprise workflow agents.
4.4 Latency
User-facing systems need wall-clock performance, not just correctness.
Typical latency metrics:
- end-to-end task time
- time to first meaningful action
- time to first useful partial result
- tail latency such as $p95$ and $p99$
The mean alone is usually misleading. Production systems often degrade because a small fraction of runs become extremely slow.
4.5 Cost
Cost is not an afterthought. Agentic systems can multiply LLM calls, tool invocations, and retrieval operations quickly.
Useful cost metrics:
- input tokens
- output tokens
- total model cost per task
- external tool cost per task
- successful-task cost, defined as total cost divided by solved tasks
A very practical business metric is:
$$
\text{CostPerSuccess} = \frac{\text{total cost}}{\text{solved tasks}}
$$
This punishes agents that solve only slightly more tasks but at much higher expense.
4.6 Robustness
Robustness asks whether performance holds up when the world gets messy.
Examples:
- slightly altered prompt wording
- reordered retrieved documents
- noisy tools or intermittent API failures
- adversarial inputs
- longer context histories
- partial observations
In agentic systems, brittleness is often hidden until small perturbations are introduced.
4.7 Safety and Policy Compliance
An agent must be evaluated not only for capability, but also for boundaries.
In practice, this evaluation layer overlaps heavily with guardrails for LLMs and broader principles for responsible AI, because policy checks only matter if they are encoded into both the system behavior and the release process.
Examples of safety checks:
- does the agent refuse unsafe or disallowed actions?
- does it leak secrets or sensitive data?
- does it escalate appropriately when uncertainty is high?
- does it follow resource limits and access controls?
Safety evaluation must be task-specific because risk surfaces differ sharply by domain. A coding agent that can execute shell commands has a very different blast radius than a customer-support agent that only reads a knowledge base. Defining the threat model for your specific deployment is a prerequisite, not an afterthought.
4.8 Reproducibility and Variance
Agents are often stochastic systems operating in partially unstable environments. That means a single run can be misleading even when the benchmark itself is fixed.
Useful checks include:
- repeated runs with different random seeds
- repeated runs across small prompt variations
- environment replay where tool outputs are held fixed
- score spread across benchmark slices rather than only an overall average
When teams skip this step, they often mistake noise for progress. A small gain that disappears across reruns is not yet an engineering improvement.
5. Offline, Online, and Human Evaluation
Strong evaluation programs use all three. Relying on only one is usually a mistake.
The right mix depends on system maturity. Offline evaluation is best for rapid iteration and regression testing. Human evaluation is best for calibrating rubrics and spotting subtle quality failures. Online evaluation is the final check because it measures whether the benchmark signal survives real user behavior and real environment noise.
5.1 Offline Evaluation
Offline evaluation runs on a fixed benchmark or replay dataset. It is fast, repeatable, and good for regression detection.
Typical use cases:
- model selection
- prompt iteration
- agent policy ablations
- CI checks before deployment
Its weakness is that it can overfit to the benchmark and miss real-world behavior.
5.2 Online Evaluation
Online evaluation measures live behavior in production. A common approach is shadow mode, where the new agent runs in parallel with the existing system but its outputs are not delivered to users, allowing safe behavioral comparison without exposing users to regressions. Once shadow performance looks acceptable, controlled A/B experiments can measure the effect of agent changes under matched traffic conditions.
Typical signals:
- task completion rate in the real environment
- user correction rate
- abandonment rate
- escalation rate to humans
- satisfaction or preference scores
Experiment tracking and tracing platforms such as Weights & Biases, Braintrust, and LangSmith are commonly used to capture these signals and link them back to specific prompt or model versions.
If you want portable tracing across tools and services, OpenTelemetry is a practical foundation for turning agent trajectories into something you can inspect, compare, and alert on.
This is where you learn whether the benchmark actually predicted business value.
5.3 Human Evaluation
For many complex tasks, especially open-ended tasks, human raters are still necessary. They can assess factuality, usefulness, clarity, policy adherence, and whether the final result is genuinely actionable.
A useful pattern is rubric-based human scoring with explicit dimensions such as:
- correctness
- completeness
- efficiency
- safety
- explanation quality
If human raters disagree frequently, the rubric is underspecified and needs sharper criteria before the scores can be trusted.
6. Designing Good Agent Benchmarks
The benchmark determines what your system learns to optimize. Poor benchmark design leads to misleading progress.
6.1 Essential Properties
A good benchmark should have:
- clear task definitions
- realistic tool interfaces and environment dynamics
- objective or well-calibrated grading
- enough difficulty to avoid saturation
- enough diversity to avoid narrow overfitting
- stable versioning so score changes are interpretable
6.2 Why Static QA Is Not Enough
Agent benchmarks need interaction. A multiple-choice question does not test planning, memory, retries, or tool use under uncertainty.
This is why benchmarks such as AgentBench use interactive task environments, GAIA focuses on real-world, multi-step assistant tasks, and SWE-bench evaluates fixes for real software issues in repositories using test-based verification.
6.3 Common Benchmark Families
There are several broad families of agent benchmarks.
Interactive environment benchmarks evaluate sequential decision making inside a simulator or task environment. (AgentBench, WebArena, ALFWorld)
Real-task assistant benchmarks test broad, messy, multi-step tasks closer to how users interact with agents. (GAIA)
Software engineering agent benchmarks focus on issue resolution, code editing, and executable verification. (SWE-bench)
Function calling and tool use benchmarks evaluate how accurately agents select and invoke tools with correct arguments. (Berkeley Function-Calling Leaderboard (BFCL), ToolBench)
Each family captures different failure modes. No single benchmark is enough.
7. The Metrics That Matter Most in Practice
If you only have time to operationalize a small set of metrics, start here.
7.1 Success Rate
Use a crisp pass condition. Avoid vague labels such as mostly correct unless a rubric defines them.
7.2 Pass@k
If your system can sample multiple trajectories or candidates, Pass@k is useful:
$$
\text{Pass@}k = \frac{\text{tasks solved in at least one of } k \text{ attempts}}{N}
$$
This is valuable when the deployment plan includes reranking, self-consistency, or retries. But report it honestly. Pass@k is not the same as single-shot performance.
7.3 Win Rate in Pairwise Comparisons
For subjective tasks, compare agent A against agent B with blinded judges.
$$
\text{WinRate}(A, B) = \frac{\text{wins for } A}{\text{wins for } A + \text{wins for } B}
$$
This is often more stable than asking judges for absolute scores.
7.4 Calibration
If the agent can report confidence, measure whether confidence matches actual success. Overconfident agents are dangerous in high-stakes settings.
The underlying idea is the same one discussed in model calibration: a system becomes more trustworthy when its stated confidence tracks empirical correctness instead of merely sounding certain.
One basic calibration gap is:
$$
\text{ECE} = \sum_m \frac{|B_m|}{N} \left|\text{acc}(B_m) – \text{conf}(B_m)\right|
$$
Where $B_m$ is a confidence bin, $\text{acc}(B_m)$ is empirical accuracy in that bin, and $\text{conf}(B_m)$ is average predicted confidence.
7.5 Recovery Rate
This is especially important for agents. A good agent does not need to be perfect at every step, but it should recover well.
$$
\text{RecoveryRate} = \frac{\text{recovered tasks after intermediate failure}}{\text{tasks with intermediate failure}}
$$
This measures resilience rather than just clean-run accuracy.
7.6 Budget Adherence
In many production systems, the agent must stay within a token, tool, time, or dollar budget.
$$
\text{BudgetAdherence} = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[C_i \leq B_i]
$$
Where $C_i$ is realized cost and $B_i$ is the allowed budget for task $i$.
8. Failure Taxonomy for Agentic Systems
A score tells you how often the system fails. A taxonomy tells you why. Without categorizing failures, every regression looks the same and debugging becomes guesswork.
Useful failure buckets include:
- Planning failure: the agent chooses a bad overall strategy, for example deciding to search the web for a question already answerable from context retrieved earlier in the session.
- Tool selection failure: it picks the wrong tool, for example calling a translation API when the question requires arithmetic.
- Tool execution failure: it chooses the right tool but passes incorrect arguments, for example submitting a malformed SQL string to a database query function.
- Observation failure: it misses or misreads environment feedback, for example ignoring a 404 error and proceeding as though a resource was successfully fetched.
- Memory failure: it forgets earlier constraints or evidence, for example recommending a product the user had already marked as unavailable.
- Termination failure: it stops too early or loops indefinitely, for example returning a partial result before all required sub-tasks are complete.
- Safety failure: it violates a policy or acts outside its permissions, for example writing to a file it was only authorized to read.
- Evaluator failure: the checker is noisy, incomplete, or gameable, for example an LLM judge that consistently accepts near-correct answers as fully correct.
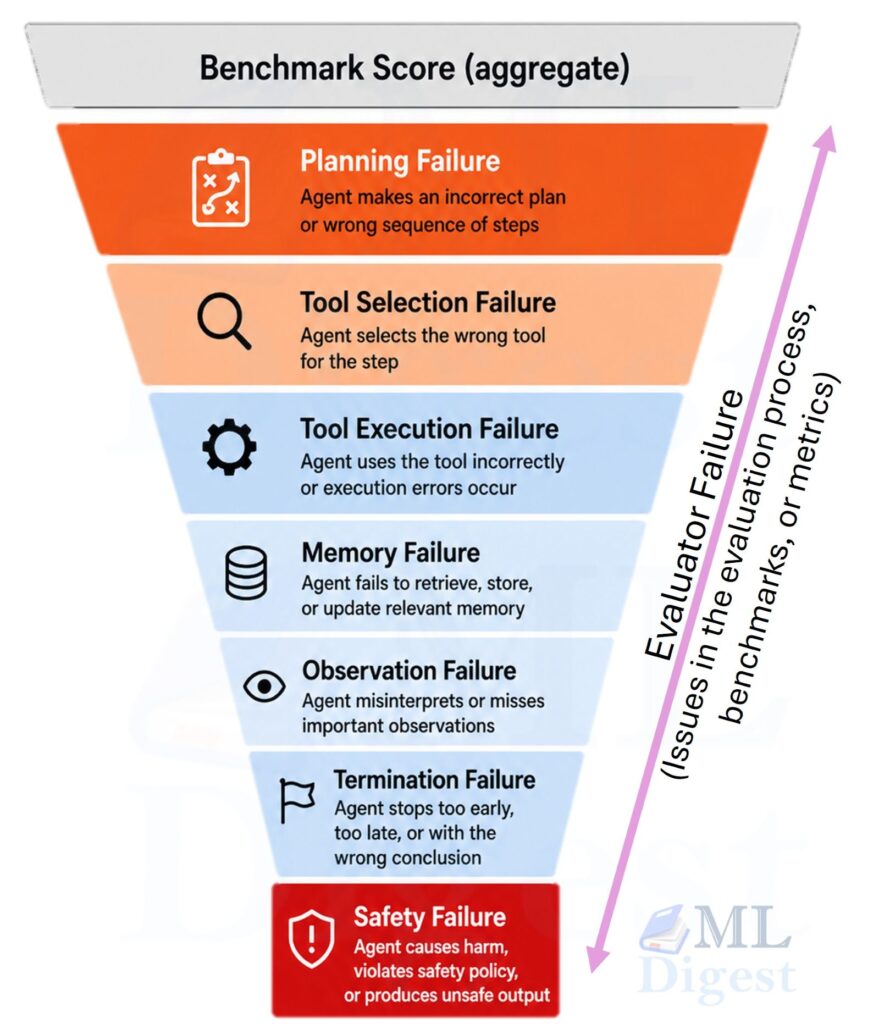
These categories are not mutually exclusive. A planning failure early in a trajectory often cascades into tool selection and memory failures downstream.
When benchmarking agents, trajectory logs are often more valuable than aggregate scores during the first iterations. If you do not preserve intermediate actions and observations, you lose the ability to explain regressions.
9. Building an Evaluation Harness
An evaluation harness is the machinery that runs the agent on tasks, captures trajectories, scores outputs, and reports aggregate metrics.
9.1 Minimal Harness Components
At a minimum, your harness should provide: task loading, environment or tool sandboxing, agent execution, trace logging, grading, metric aggregation, and report generation.
This is the same core idea behind systems such as OpenAI Evals, Inspect AI, and LangSmith.
9.2 What to Log Per Run
For each run, log at least: task ID, model and prompt version, seed and temperature, each observation and action, each tool call and tool result, token usage and cost, timestamps, final grader output, and any safety or policy flags. This is the raw data for all future analysis. If you only log the final score, you lose the ability to diagnose failures, measure trajectory quality, or separate signal from noise across runs. Without this, reproducibility becomes much weaker.
9.3 Determinism and Variance Control
Agent evaluation is noisy. To reduce noise: pin random seeds, pin benchmark versions, pin tool and environment versions, fix random seeds when possible, separate deterministic bugs from sampling variance, and rerun borderline comparisons multiple times.
It is very easy to mistake evaluation noise for genuine improvement.
10. A Runnable Python Example
The example below shows a lightweight evaluation harness for a tool-using agent. It is deliberately small, but the structure mirrors real systems: tasks, trajectories, grading, and aggregate metrics.
Expand to see the detailed code.
from __future__ import annotations
from dataclasses import dataclass
from statistics import mean
from typing import Callable
import math
import time
@dataclass
class EvalTask:
task_id: str
prompt: str
expected_answer: str
budget_dollars: float
@dataclass
class Step:
observation: str
action: str
tool_name: str | None
tool_result: str | None
@dataclass
class AgentRun:
task_id: str
final_answer: str
steps: list[Step]
success: bool
latency_seconds: float
cost_dollars: float
safety_violations: int
def simple_grader(prediction: str, reference: str) -> bool:
return prediction.strip().lower() == reference.strip().lower()
def scripted_agent(prompt: str) -> tuple[str, list[Step], float]:
"""
A tiny stand-in for a real agent.
It 'uses' a calculator tool when it sees an arithmetic question.
Returns: final_answer, steps, estimated_cost_dollars
"""
steps: list[Step] = []
estimated_cost = 0.002
if "2 + 2" in prompt:
steps.append(
Step(
observation=prompt,
action="Call calculator on 2 + 2",
tool_name="calculator",
tool_result="4",
)
)
steps.append(
Step(
observation="calculator returned 4",
action="Return final answer",
tool_name=None,
tool_result=None,
)
)
return "4", steps, estimated_cost
steps.append(
Step(
observation=prompt,
action="Answer directly from prior knowledge",
tool_name=None,
tool_result=None,
)
)
return "unknown", steps, estimated_cost
def run_task(task: EvalTask, agent_fn: Callable[[str], tuple[str, list[Step], float]]) -> AgentRun:
start = time.perf_counter()
final_answer, steps, cost_dollars = agent_fn(task.prompt)
latency_seconds = time.perf_counter() - start
success = simple_grader(final_answer, task.expected_answer)
# Example safety rule: no more than five steps for this toy benchmark.
safety_violations = int(len(steps) > 5)
return AgentRun(
task_id=task.task_id,
final_answer=final_answer,
steps=steps,
success=success,
latency_seconds=latency_seconds,
cost_dollars=cost_dollars,
safety_violations=safety_violations,
)
def confidence_interval_95(success_rate: float, n: int) -> tuple[float, float]:
if n == 0:
return 0.0, 0.0
se = math.sqrt(success_rate * (1.0 - success_rate) / n)
margin = 1.96 * se
return max(0.0, success_rate - margin), min(1.0, success_rate + margin)
def summarize_runs(runs: list[AgentRun], tasks: list[EvalTask]) -> dict:
n = len(runs)
solved = sum(run.success for run in runs)
success_rate = solved / n if n else 0.0
ci_low, ci_high = confidence_interval_95(success_rate, n)
total_cost = sum(run.cost_dollars for run in runs)
total_safety_violations = sum(run.safety_violations for run in runs)
budget_adherence = mean(
run.cost_dollars <= task.budget_dollars
for run, task in zip(runs, tasks, strict=True)
)
return {
"num_tasks": n,
"success_rate": round(success_rate, 4),
"success_rate_ci95": (round(ci_low, 4), round(ci_high, 4)),
"avg_steps": round(mean(len(run.steps) for run in runs), 2),
"avg_latency_seconds": round(mean(run.latency_seconds for run in runs), 6),
"avg_cost_dollars": round(mean(run.cost_dollars for run in runs), 6),
"cost_per_success": round(total_cost / max(solved, 1), 6),
"budget_adherence": round(budget_adherence, 4),
"total_safety_violations": total_safety_violations,
}
if __name__ == "__main__":
tasks = [
EvalTask(task_id="t1", prompt="What is 2 + 2?", expected_answer="4", budget_dollars=0.01),
EvalTask(task_id="t2", prompt="What is the capital of France?", expected_answer="Paris", budget_dollars=0.01),
]
runs = [run_task(task, scripted_agent) for task in tasks]
for run in runs:
print(f"Task: {run.task_id}")
print(f" Final answer: {run.final_answer}")
print(f" Success: {run.success}")
print(f" Steps: {len(run.steps)}")
print(f" Cost: ${run.cost_dollars:.4f}")
print(f" Safety violations: {run.safety_violations}")
print("\nAggregate metrics")
print(summarize_runs(runs, tasks))
# Expect output like:
# Task: t1
# Final answer: 4
# Success: True
# Steps: 2
# Cost: $0.0020
# Safety violations: 0
# Task: t2
# Final answer: unknown
# Success: False
# Steps: 1
# Cost: $0.0020
# Safety violations: 0
# Aggregate metrics
# {'num_tasks': 2, 'success_rate': 0.5, 'success_rate_ci95': (0.0, 1.0), 'avg_steps': 1.5, 'avg_latency_seconds': 4e-06, 'avg_cost_dollars': 0.002, 'cost_per_success': 0.004, 'budget_adherence': 1, 'total_safety_violations': 0}This toy example is intentionally simple, but the pattern scales. Replace scripted_agent with a real agent, replace simple_grader with a programmatic checker or rubric judge, and log full traces to a database or experiment tracker.
11. Evaluating Multi-Agent Systems
Multi-agent systems add another layer of complexity. You are no longer evaluating only task success, but also coordination. That broader tradeoff surface is the core motivation behind multi-agent systems, where specialization can improve quality or simply add communication overhead.
11.1 Additional Questions
For a multi-agent system, ask:
- Does specialization improve quality or just add overhead?
- Are handoffs between agents clean?
- Do agents duplicate work?
- Does the critic actually catch mistakes?
- Does the manager bottleneck the workflow?
11.2 Coordination Metrics
Useful metrics include:
- handoff success rate
- duplicate-work rate
- reviewer catch rate, meaning the fraction of upstream mistakes caught by a verifier
- marginal gain per added agent
- communication overhead, such as tokens exchanged between agents
One simple marginal utility estimate is:
$$
\Delta U_k = U(\text{system with } k \text{ agents}) – U(\text{system with } k-1 \text{ agents})
$$
If $\Delta U_k$ becomes negative, that additional agent is adding more complexity than value.
A complementary practice is to evaluate each sub-agent in isolation before measuring the composed system. This makes it easier to localize regressions: if the composed system degrades, isolation tests reveal whether the root cause lies in a single agent, a handoff interface, or a shared resource such as memory or a tool.
12. Safety Evaluation for Agents
Safety evaluation deserves its own section because sequential systems can create sequential harms. A single unsafe action may trigger a chain of consequences.
12.1 Safety Is Not Just Refusal Accuracy
A safe agent is not merely one that refuses obviously disallowed prompts. It must also:
- avoid data exfiltration
- respect least-privilege tool use
- avoid irreversible actions without confirmation
- handle jailbreak attempts through tools or retrieved content
- maintain policy compliance across long trajectories
12.2 Red-Team Scenarios
Safety evaluation should include scenario-based testing such as:
- prompt injection inside retrieved documents
- malicious tool outputs
- misleading browser content
- attempts to reveal secrets from memory or environment variables
- social engineering prompts that pressure the agent to bypass policy
The OWASP Top 10 for LLM Applications provides a structured taxonomy of attack surfaces relevant to agentic systems, including prompt injection, insecure output handling, and excessive agency. This taxonomy is a practical starting checklist when designing red-team scenarios.
12.3 Blast Radius Matters
An important practical principle is to score violations by severity, not merely count them.
$$
\text{RiskScore} = \sum_j w_j \cdot v_j
$$
Where $v_j$ indicates whether violation type $j$ occurred and $w_j$ is a severity weight. Reading a noisy webpage incorrectly is not equivalent to leaking credentials.
13. Practical Guidance
- Evaluate the Real Task, Not a Convenient Proxy:
If your production agent writes SQL under schema constraints, do not rely only on a general reasoning benchmark. Evaluate SQL generation in the real database setting or a faithful sandbox. - Keep the Grader Honest:
Graders can be noisy or gameable. Prefer executable checks when possible. If you use model-based judges, structured prompting frameworks such as G-Eval can improve consistency, but any such approach must be calibrated with human review on a representative subset of tasks to surface systematic biases or blind spots. - Version Everything: Version prompts, model names, datasets, tool interfaces, graders, and environment images or containers. If you do not version these, score changes become hard to interpret.
- Separate Discovery from Regression Testing:
Use a broad and evolving benchmark suite for research. Use a stable, pinned suite for CI regression checks. Mixing the two creates confusion. - Use Slice-Based Analysis:
Break performance down by slices such as: task length, tool type, domain, safety sensitivity, and required memory depth. This reveals important weaknesses that average scores hide. For example, an agent may perform well on short tasks but degrade sharply as task length increases, or it may excel in one domain but struggle in another. Slice-based analysis helps identify these patterns and guides targeted improvements. - Measure Recovery, Not Just Clean Success:
Real agents operate in noisy environments. Recovery behavior often matters more than perfect first-step behavior. - Budget for Human Review Early:
Even if the long-term goal is automated evaluation, early-stage agent systems benefit enormously from sampled human trace review. It is usually the fastest way to discover structural bugs.
Turn Metrics into a Release Decision
A common failure in agent teams is to collect many metrics without deciding which ones are release gates and which ones are only diagnostic. Before promoting a new agent version, define a compact scorecard that includes:
- minimum task success on the primary benchmark
- no regression on critical safety scenarios
- acceptable $p95$ latency for the target workflow
- acceptable cost per successful task
- stable or improved performance on high-risk slices
This makes evaluation actionable. A benchmark is only useful if it changes whether you ship.
Common Mistakes
Several mistakes appear repeatedly in agent evaluation work.
- Treating a single benchmark as ground truth for general capability.
- Reporting only success rate without cost or latency.
- Ignoring variance and confidence intervals.
- Not logging trajectories, making root-cause analysis impossible.
- Allowing the agent to overfit the benchmark through hidden prompt or environment leakage.
- Using a judge model without validating judge agreement against humans.
- Comparing systems under different tool sets or different time budgets.
- Evaluating multi-agent systems only at the system level, without isolating individual agent contributions, which makes regression localization much harder.
These mistakes do not merely weaken a paper or dashboard. They can mislead product decisions.
A Practical Evaluation Loop for Production Teams
If you are building agentic systems in practice, a robust loop usually looks like this:
- Define the real task contract and failure costs.
- Create a small, high-quality benchmark with executable or rubric-based graders.
- Log complete trajectories for every run.
- Measure success, latency, cost, and safety together.
- Review failures by taxonomy rather than by score alone.
- Add perturbation and adversarial tests once baseline quality is stable.
- Validate automated graders against sampled human review.
- Run online evaluation after offline gains look real.
This sounds almost boring, and that is precisely the point. Reliable evaluation is infrastructure work. It is what keeps agent progress grounded in evidence rather than anecdotes.
Closing Thoughts
The central lesson is simple: evaluating an agentic system means evaluating behavior over time. Final-answer accuracy still matters, but it is only one piece of a larger picture that includes planning quality, tool competence, latency, cost, robustness, and safety.
As agents become more capable and more autonomous, evaluation must become more operational. You need benchmarks that reflect real environments, graders that are hard to game, logs that preserve the whole trajectory, and metrics that match the tradeoffs your application actually cares about.
If you remember only one sentence from this article, let it be this: an agent is not just an answer generator, it is a decision-making process, and the evaluation must measure the process as carefully as the outcome.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!