Imagine a student who has memorized an entire textbook, but only answers questions when they are phrased exactly like the exercises. Ask the same thing in everyday language and the student hesitates.
That is a vanilla pretrained T5 model: it can be very capable, but it often relies on brittle prompt patterns. To get an answer, you must phrase your request in a specific, rigid structure it has practiced before. FLAN-T5 aims to fix this by teaching the same student how to follow instructions.
FLAN (“Fine-tuned LAnguage Net”) refers to a family of instruction-tuning recipes: take a pretrained model (here, T5) and fine-tune it on a large mixture of tasks rewritten as natural language instructions. The core idea is simple:
- Pretraining teaches “language patterns.” so that the model can understand and generate text.
- Instruction tuning teaches “when the user says X, do task Y,” so that a new instruction can generalize without task-specific prompt engineering.
For practitioners, FLAN-T5 often hits a pragmatic sweet spot:
- Prompt robustness: lower sensitivity to exact wording than base T5.
- Strong zero-shot and few-shot baselines: competitive accuracy per parameter.
- A good backbone for adaptation: works well with PEFT (for example, LoRA) and can be paired with retrieval (RAG).
At a glance (what changes with FLAN-T5?)
- Architecture: unchanged (still T5 encoder–decoder).
- Training recipe: adds multi-task instruction fine-tuning on an instruction mixture.
- Observed behavior: better generalization from natural-language instructions to task behavior, and reduced prompt sensitivity.
This article keeps intuition first, then moves to technical detail: what instruction tuning optimizes, how the task mixture is assembled, why it often improves zero-shot performance, and the failure modes to watch for.
The T5 Backbone: A Quick Recap
The Underlying T5 Encoder–Decoder
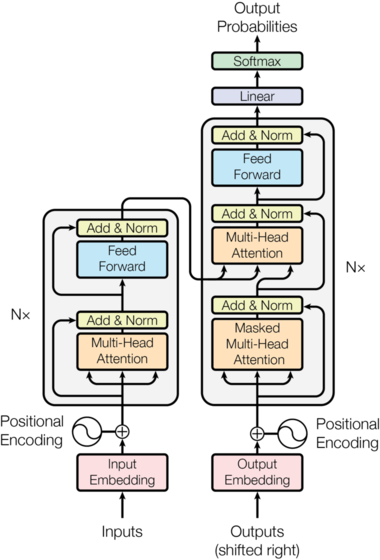
T5 introduced a unified text-to-text paradigm: every task (classification, translation, summarization, question answering) is expressed as text-in → text-out. Architecturally, T5 is a Transformer encoder–decoder with relative position bias (instead of absolute sinusoidal embeddings) and span-corruption pretraining, where spans of tokens are replaced by sentinel tokens and the model learns to reconstruct them.
Two details matter for understanding why FLAN-T5 is “the same architecture, different behavior”:
- Pretraining objective: T5 is pretrained with span corruption, which teaches general denoising and generation ability, but does not explicitly teach instruction following.
- Encoder–decoder conditioning: because the entire instruction and context can be encoded bidirectionally, the decoder can condition on a global view of “what is being asked,” which tends to make instruction prompts behave like a stable interface.
Key structural features:
- Tokenization: SentencePiece subword vocabulary (approx. 32k) enabling efficient multilingual and domain adaptation.
- Encoder: Multi-head self-attention + feed-forward blocks, augmented with relative position bias that helps longer context modeling without fixed positional encoding.
- Decoder: Masked self-attention (causal) plus encoder-decoder cross-attention linking representations of the input to generative outputs.
- Scaling: Sizes range from small (≈60M parameters) to XXL (≈11B parameters).
What FLAN Adds: A Different Fine-Tuning Regime
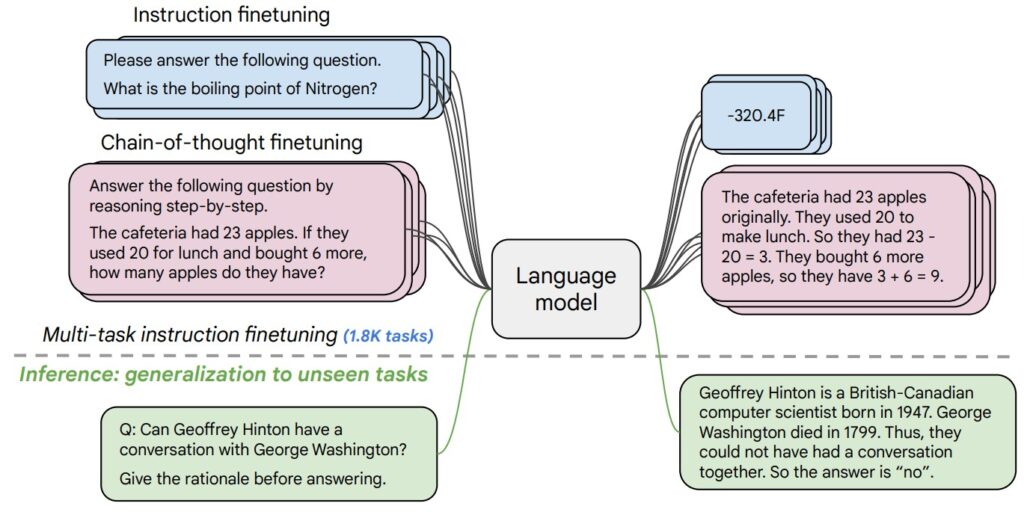

FLAN does not alter the core T5 architecture. The novelty is how the pretrained checkpoint is fine-tuned: a large mixture of tasks is converted into natural-language instruction templates, and the model is trained to produce the appropriate targets.

Critically, the “Instruction” lane in the figure corresponds to many paraphrases of the same intent. Whether the prompt says “Translate to German” or “How do I say this in German?”, the model learns that both should activate the same behavior.
The result is a set of weights that better internalize the pattern “instruction → task behavior,” which tends to improve generalization to new but semantically similar instructions.
One subtle point: instruction tuning is not only about “more data.” It changes the distribution of prompts the model is optimized on. The model sees many tasks where the task identity is communicated through natural language, so it learns a reusable interface rather than a single dataset-specific format.
The Art of the Mixture: Instruction-Tuning Data
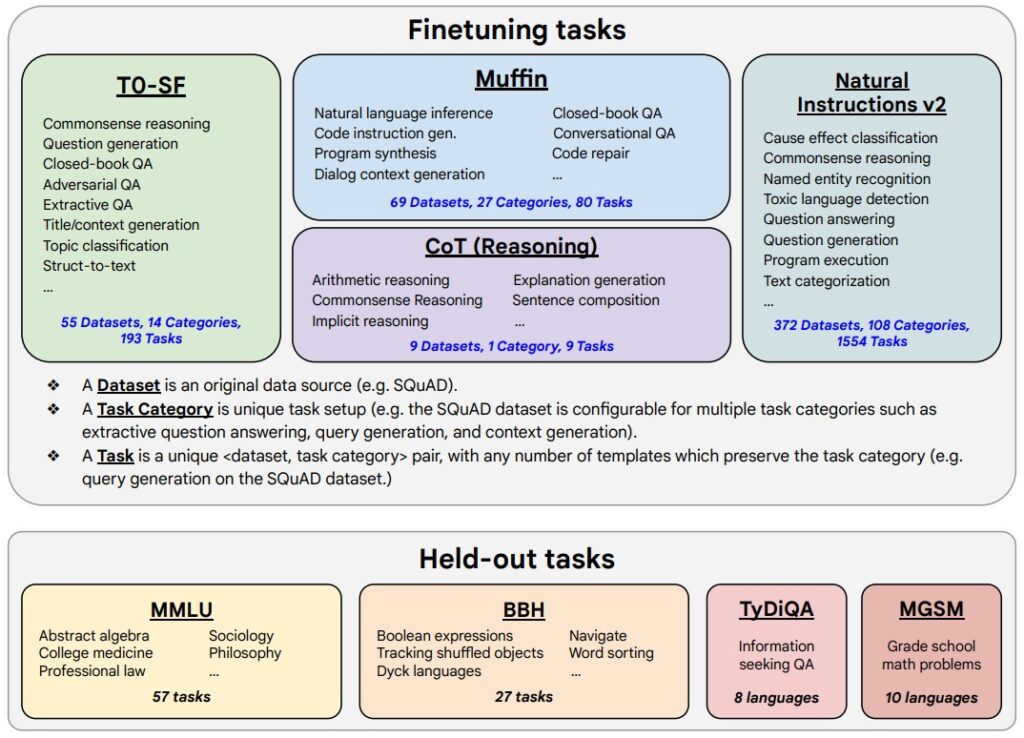
Data Sources and Heterogeneity
The FLAN mixture aggregates a wide coverage of tasks. You can think of it as a curriculum: many subjects, each restated in multiple ways.
- Natural Language Inference: Entailment, contradiction, neutral (e.g., SNLI, MNLI).
- Question Answering: Extractive, multi-hop, open, closed-book (e.g., SQuAD, Natural Questions).
- Summarization: Short form, extreme summarization, headline generation (e.g., XSum, CNN/DailyMail).
- Translation: Bi-directional across several language pairs.
- Sentiment and Classification: Topic, emotion, stance detection.
- Reasoning: Coreference resolution, commonsense QA (e.g., Winograd, COPA).
- Mathematical and Symbolic Reasoning: Arithmetic word problems, simple algebraic manipulations.
- Dialogue: Instruction following and reformulations in conversational contexts.
Each original dataset is reformulated into sets of natural-language instructions with multiple variants to reduce template overfitting. Tasks are interleaved so the model does not over-specialize in any single domain.
From a generalization perspective, two axes matter:
- Task diversity (different skills): classification, QA, translation, summarization, reasoning.
- Surface-form diversity (different prompts): paraphrases, formatting variants, separators, answer constraints.
Task diversity pushes the model to learn reusable features. Surface-form diversity pushes it to become invariant to prompt wording.
Formatting Conventions
The canonical pattern for a single instruction-tuning example is:
- Instruction: A natural-language directive
- Optional context: a passage, dialogue history, or table
- Input: the data to be processed
- Output: the desired answer/completion
Multiple paraphrases are key: “Translate this sentence into French:”, “Convert the following English sentence to French:”, “French translation:”. This encourages invariance to surface form and improves robustness.
Mixture Assembly and Balancing
Constructing the mixture involves sampling and weighting tasks so that a few large datasets do not dominate training. A common strategy is to cap high-resource tasks and upsample smaller ones. This soft balancing reduces dominance by a handful of corpora and helps retain broad cross-task behavior.
Chain-of-Thought Augmentation
A notable ingredient in the FLAN family is the inclusion of examples with intermediate reasoning text (often discussed as “chain-of-thought: CoT”). Some reasoning tasks are formatted so that the target includes intermediate steps before the final answer.
- Standard Path: Instruction → Final Answer.
- CoT Path: Instruction → Reasoning Steps (Step 1 → Step 2 → Step 3) → Final Answer.
The CoT path is triggered by meta-instructions like “Explain your reasoning,” encouraging the model to produce intermediate steps before the final answer.
However, it is useful to separate capability (solving the problem) from explanation quality (producing a faithful rationale). CoT text is not guaranteed to be a faithful trace of the internal computation; treat it as a helpful interface, not a proof.

What Instruction Tuning Changes at Inference Time
Zero-Shot vs. Few-Shot Prompts
Before instruction tuning, many seq2seq models exhibited a sharp performance cliff between few-shot prompting (explicit exemplars) and zero-shot prompting (pure task description). FLAN-style training narrows this gap because the model is optimized on prompts where the task identity is communicated in natural language, not only through a dataset-specific template.
During fine-tuning, the model sees both:
- Zero-shot: instruction + input, no exemplars.
- Few-shot: instruction + several input–output exemplars + a new query.
Through exposure to diverse concatenations of exemplars beneath a unifying instruction, the model learns that earlier lines can serve as conditioning context rather than competing generation targets.
Prompt Robustness
Because multiple paraphrases are used for each underlying task, FLAN-T5 is pushed toward an internal representation of intent. Minor wording changes (“Summarize the passage” vs. “Provide a concise summary of the following text”) are less likely to change behavior.
This is also why instruction tuning is often evaluated with prompt paraphrase sets: you measure not only peak accuracy, but also the variance across paraphrases.
Handling Structured Outputs
Instruction tuning includes patterns where outputs are constrained (e.g., answer choices A/B/C/D, true/false, JSON-like fragments). While FLAN-T5 is not a strict semantic parser, exposure to constraint-style prompts improves its ability to adhere to required output schemas when you state them explicitly (for example: “Respond with only ‘entailment’, ‘contradiction’, or ‘neutral’.”).
A useful mental model is that instruction tuning improves format obedience under clear constraints, but it does not provide the strong guarantees you get from constrained decoding or a parser with a formal grammar.
Reasoning and Rationale Generation
When prompted with meta-phrases like “Explain your answer” or “Show your reasoning step by step,” FLAN-T5 can produce intermediate reasoning chains for tasks with arithmetic or logical dependencies. This is partially emergent from mixture tasks that include rationale exemplars, demonstrating early forms of “chain-of-thought” style capability, though less pronounced than in later specialized models.
It is also worth noting a common evaluation pitfall: “better-looking rationales” can be easier to measure qualitatively than genuine improvements in correctness. For applied work, prioritize task metrics (accuracy, EM, ROUGE) and treat rationales as an optional interface feature.
Transfer to Novel Tasks
Novel tasks that share structural similarity (for example, a new sentiment dataset or NLI formulation) can often be addressed by writing a fresh instruction without any gradient updates. This is genuine instruction-following generalization.
The limits show up when tasks require domain knowledge or reasoning styles absent in the mixture, or when the output format is substantially more rigid than what the model saw during fine-tuning.
We now ground these mechanics in a compact mathematical view.
A Compact Mathematical View
Core Sequence-to-Sequence Objective
At its heart, FLAN-T5 is still a standard sequence-to-sequence model. It reads an input $x$ and generates an output $y$, token by token. In simple terms: for every correct word in the target answer, did the model assign it a high probability?
The loss function is the negative log-likelihood.
This is the usual token-level cross-entropy for sequence-to-sequence models:
$$
\mathcal{L}_{\text{seq2seq}}(\theta) = – \sum_{t=1}^{T_y} \log p_\theta(y_t \mid y_{<t}, x)
$$
- $x$: The input sequence (which now includes the instruction text).
- $y_t$: The current word the model is trying to predict.
- $y_{<t}$: All the words it has generated so far.
- $\theta$: The model’s weights that we are trying to optimize.
- $T_y$: The total number of words in the target output.
Instruction tuning changes the content of $x$ (the examples you train on), but it does not change this fundamental mathematical goal.
The encoder produces contextual states $H = \text{Encoder}_\theta(x)$. The decoder attends over $H$ and previously generated tokens. Relative position bias enters the attention score computation as an additive term.
This is often written as:
$$
A_{ij} = \frac{Q_i K_j^\top}{\sqrt{d}} + b_{\text{rel}}(i,j).
$$
This bias allows the model to learn relationships based on distance (e.g., “pay attention to the word immediately preceding this one”), which is crucial for parsing structured instructions.
Multi-Task Mixture Loss
The “magic” of FLAN isn’t the model architecture; it’s the curated diet of tasks it consumes. We don’t just minimize loss on one task; we minimize the weighted average loss across hundreds of different tasks (Translation, Logic, Coding, etc.).
Suppose we have a set of instruction-tuned tasks $\{\mathcal{T}_k\}_{k=1}^K$. The global objective is:
$$
\mathcal{L}(\theta) = \sum_{k=1}^K \underbrace{w_k}_{\text{Importance}} \cdot \underbrace{\mathbb{E}_{(x,y) \sim \mathcal{T}_k} \left[ -\log p_\theta(y \mid x) \right]}_{\text{Average Loss on Task } k}
$$
- $\mathbb{E}$ (Expectation): The average over all examples in this task.
- $w_k$ (Task Weight): This is our curriculum lever. We might cap $w_k$ for huge datasets (like common web crawls) so they don’t drown out smaller, high-quality instruction tasks (like logic puzzles). This ensures the “student” becomes a generalist, not determining its behavior solely based on the most frequent task.
Few-Shot Prompting: Concatenation
When we do “few-shot” prompting (giving examples in the prompt), we aren’t changing the model’s weights. We are just creating a very long input string $\tilde{x}$. We essentially “stuff” the examples into the input context.
If we have examples $E = [(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)})]$, the input becomes:
$$
\tilde{x} = \text{Instruction} \oplus \underbrace{x^{(1)} \oplus y^{(1)}}_{\text{Example 1}} \oplus \underbrace{x^{(2)} \oplus y^{(2)}}_{\text{Example 2}} \oplus \text{New Query}
$$
The model, trained on mixes of zero-shot and few-shot data, learns that these early patterns are context, not the final answer to be predicted.
Scaling Considerations (Why Size and Task Diversity Both Matter)
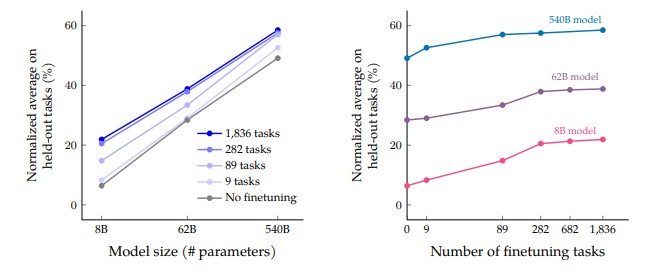
Think of the model as a student and the fine-tuning tasks as the set of subjects. If you only teach a student mathematics, that student might struggle with history.
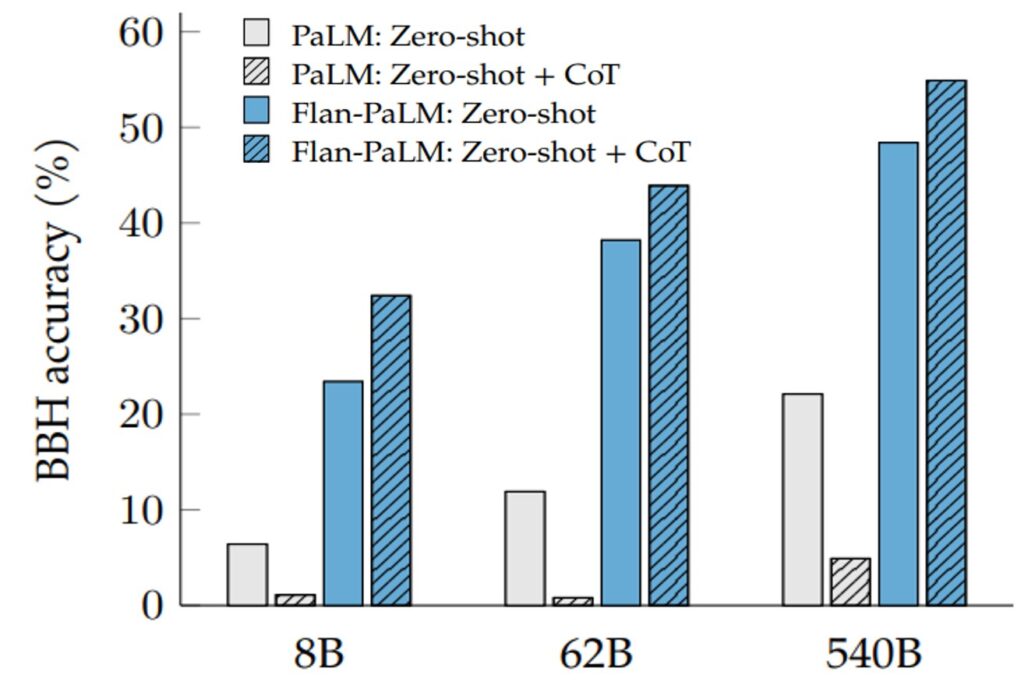
The graph illustrates a common pattern in instruction tuning: held-out generalization improves when (1) the model has enough capacity to represent diverse behaviors, and (2) the curriculum has enough task diversity to incentivize reusable internal features rather than template memorization.
In other words, model size helps, but task diversity is the lever that teaches the model what kinds of behaviors to generalize.
Getting Hands-On: Code and Applications
Representative Application Domains
- Rapid Prototyping: Quickly build classifiers for sentiment, topic, or intent without fine-tuning.
- Multi-lingual Pivoting: Zero-shot translation or paraphrase generation across language pairs present in the mixture.
- Summarization: Condense long-form content into headlines or bullet points.
- Lightweight Reasoning: Solve arithmetic word problems and commonsense QA, with optional stepwise explanations.
- Data Transformation: Transform unstructured text into labeled key-value pairs with an explicit instruction.
- Code-related NLP: Generate explanatory comments or docstrings (though larger, specialized code models will outperform on complex tasks).
Hugging Face Inference Example
Below is a complete inference snippet. (Assumes transformers and torch are installed: pip install transformers torch sentencepiece).
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_name = "google/flan-t5-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
instruction = "Classify the sentiment of the following review as positive or negative."
text = "The product quality exceeded every expectation I had."
prompt = f"{instruction}\nReview: {text}\nSentiment:"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(
**inputs,
max_new_tokens=8,
do_sample=False
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)) # Expected: 'positive'Few-Shot Augmentation
examples = [
("The battery died after one day.", "negative"),
("Fantastic sound quality and build.", "positive")
]
query = "Packaging felt cheap but the device works well." # Ambiguous case
instruction = "Determine if each review is positive or negative."
shot_block = "".join([
f"Review: {ex}\nSentiment: {label}\n" for ex, label in examples
])
prompt = f"{instruction}\n{shot_block}Review: {query}\nSentiment:"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=8, do_sample=False)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)) # Expected: 'positive'Asking for an Explanation (Optional)
instruction = "Answer the math question. Then provide a brief explanation."
question = "If a train travels 60 km in 1.5 hours, what is its average speed in km per hour?"
prompt = f"{instruction}\nQuestion: {question}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# Expected: '40 km per hour. Explanation: Average speed is total distance divided by total time...'Constraining Output Choices
Explicitly stating allowed tokens can reduce drift:
instruction = "Return only 'entailment', 'contradiction', or 'neutral' for the relationship between the premise and hypothesis."
premise = "The cat sat on the mat."
hypothesis = "The average speed of a train is 60 km per hour."
prompt = f"{instruction}\nPremise: {premise}\nHypothesis: {hypothesis}\nLabel:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs.to(device), max_new_tokens=4, do_sample=False)
label = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(label) # Expected: 'neutral'Accelerating with Batch Processing
For multiple prompts, batch encode to leverage parallel GPU execution:
prompts = [
"Summarize: Advances in transformer efficiency focus on sparse attention and quantization techniques.",
"Summarize: Instruction tuning aligns models with user intent across diverse tasks.",
]
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
outputs = model.generate(**inputs.to(device), max_new_tokens=40)
summaries = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs]
for s in summaries:
print("-", s)
'''Expected summaries:
- Advances in transformer efficiency include sparse attention and quantization.
- Instruction tuning helps models follow user intent across tasks.'''Performance and Competitive Landscape
Qualitative Improvements
Key areas where FLAN-T5 distinguishes itself from the base T5 model:
- Instruction Sensitivity: Lower variance in outputs when given paraphrased instructions.
- Zero-Shot Accuracy: Elevated baseline on tasks that are structurally similar to the training mixture but not explicitly seen.
- Few-Shot Efficiency: Achieves strong performance with just a few examples, whereas vanilla T5 requires more.
Comparison to Large Autoregressive Models (GPT-3 Era)
While large decoder-only models (like GPT-3) achieve strong few-shot performance via in-context learning, FLAN-T5 (especially larger variants) often narrows the zero-shot gap with substantially fewer parameters. Furthermore, decoder-only models can be sensitive to the order of examples in a prompt; FLAN-T5’s encoder-decoder structure allows for a more robust conditioning on long instructions and context passages.
Model Selection and Sizing Guidance
| Size | Approx VRAM (fp16) | Recommended Use | Latency |
|---|---|---|---|
| Small | ~1 GB | Edge classification, lightweight prototypes | Very Low |
| Base | ~2 GB | General light NLP workloads | Low |
| Large | ~4 GB | Balanced multi-task, summarization | Medium |
| XL | ~10 GB | Complex reasoning, multi-hop QA | High |
| XXL | ~24 GB | Research-scale, maximal robustness | Very High |
Operational Deployment Considerations
- Batching: Group requests with similar max generation length to minimize idle decoder steps.
- Quantization: Employ 8-bit (LLM.int8) for minimal accuracy loss; 4-bit (QLoRA) for aggressive compression with small validation to verify drift.
- Prompt Normalization: Standardize instruction prefixes (e.g., “Task:” “Instruction:”) to reduce variance; maintain a prompt registry.
Limitations and Ethical Guardrails
- Bias and Representation:
Instruction tuning does not remove inherent biases from the underlying pretraining corpora. If the datasets used to create instructions reflect demographic skews or cultural stereotypes, the model outputs can propagate and even amplify such biases. - Hallucination:
The model may confidently produce incorrect factual assertions. Prompts that encourage the model to admit uncertainty (“If you do not know, say so”) can partially reduce harmful hallucination, but retrieval augmentation is the recommended solution for critical factual tasks. In practice, a useful split is:- Instruction following: “Does the model do the right kind of task?”
- Factuality: “Is the content correct with respect to the world or a source document?”
- Over-Reliance on Surface Form:
Despite robustness gains, drastically unconventional phrasing or multi-language hybrid instructions (code-switching) can still degrade performance. Always evaluate custom paraphrases before deployment. - Privacy and Data Leakage:
Fine-tuning on proprietary instructions might inadvertently cause the model to memorize sensitive snippets. Strategies include using differential privacy during fine-tuning, implementing redaction pipelines, or restricting exposure to personally identifying information.
Troubleshooting and Advanced Techniques
- Handling Inputs That Exceed Context Length:
For very long documents that surpass the encoder’s token limit, naive truncation can discard crucial information. Strategies include:- Hierarchical Summarization: Summarize chunks of the document, then summarize the summaries.
- Sliding Window Extraction: Apply the instruction to overlapping segments and aggregate the answers via voting or confidence heuristics.
- Mitigating Domain Shift:
If your task domain diverges significantly from the training mixture (e.g., dense chemical nomenclature), model outputs may degrade. The solution is a short adaptation phase with a few hundred domain-specific instruction-output pairs, ideally using LoRA or another PEFT method.
- Dealing with Ambiguous Instructions:
If the model produces inconsistent outputs, refine the instruction to be more specific about the desired format, length, and constraints. For example, replace “Summarize this” with “Produce a 2-sentence summary focusing only on the causal relationships.” Explicit constraints reduce the entropy of plausible generations. - Robustness to Adversarial Prompts:
Edge cases like instructions with conflicting directives (“Answer the question but ignore the question and output ‘cat’.”) can yield unpredictable outputs. For production systems, consider pre-validating prompts with heuristic filters that reject self-contradictory or malicious patterns. - Constraining Generation:
Sometimes a binary classification instruction yields an explanatory paragraph. A simple fix is to add a postfix like “Respond with only ‘yes’ or ‘no’.” If drift persists, you can apply constrained decoding to filter the logits at each step, allowing only the tokens from your desired output set. - Decoding Strategy Selection:
- For deterministic labels: Use greedy decoding.
- For creative tasks like paraphrasing: Use nucleus sampling (top-p) with $p \approx 0.9$.
- For reasoning tasks: Beam search with a small beam size (3–5) can improve the clarity of multi-step answers. Monitor for repetitive loops and adjust the repetition penalty if necessary.
- Temperature and Calibration:
If outputs are overconfident but incorrect, try increasing the temperature slightly (e.g., to 0.8–1.2). You can also combine this with a self-check prompt (“Is the above answer consistent with the provided passage? Answer yes or no.”).
Final Thoughts
FLAN-T5 is an instructive milestone: it shows that a strong pretrained model can become substantially more usable through data-centric alignment, without changing the architecture. Instruction tuning turns “prompting” from a brittle craft into something closer to a stable interface: natural-language instructions map more reliably to task behavior.
In practice, FLAN-T5 is a strong choice when you want solid zero-shot baselines, predictable behavior across paraphrases, and an encoder–decoder model that adapts well with PEFT. It is less ideal when you need strict schema guarantees, high-fidelity rationales, or up-to-date factuality without retrieval.
If you treat instruction tuning as curriculum design (diversity, balancing, and careful formatting), the resulting model is often less about memorizing templates and more about learning a reusable skill: “read an instruction and do the task.”

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!