
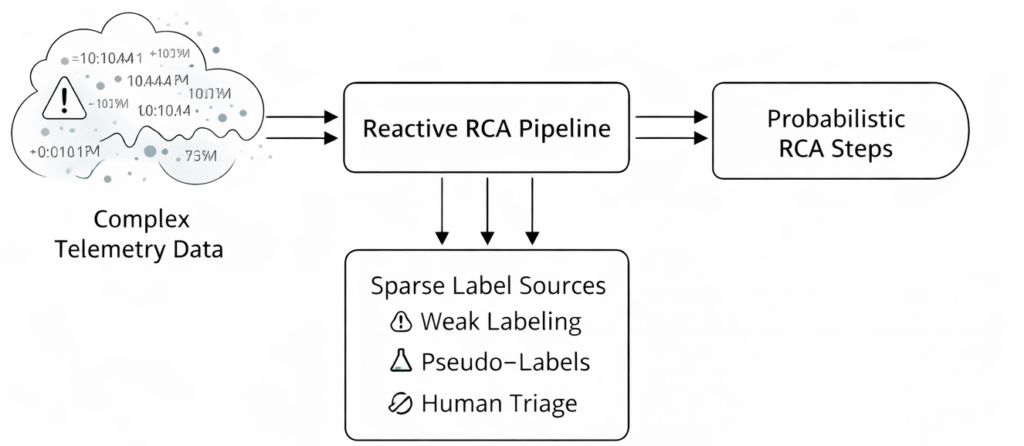
SmartCam RCA: Shrinking Mean Time to Repair with Telemetry
1. Problem framing (what “reactive RCA” means) Imagine you are a doctor in a busy emergency room. A patient (the […]
SmartCam RCA: Shrinking Mean Time to Repair with Telemetry Read More »
1. Problem framing (what “reactive RCA” means) Imagine you are a doctor in a busy emergency room. A patient (the […]
SmartCam RCA: Shrinking Mean Time to Repair with Telemetry Read More »
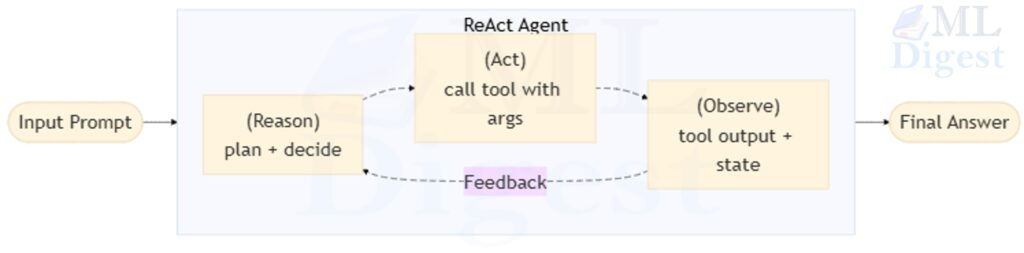
Imagine you are in a kitchen trying to cook a new, complex dish. You do not just grab random ingredients
ReAct (Reasoning + Acting): A Practical Framework for Building Agentic AI Read More »
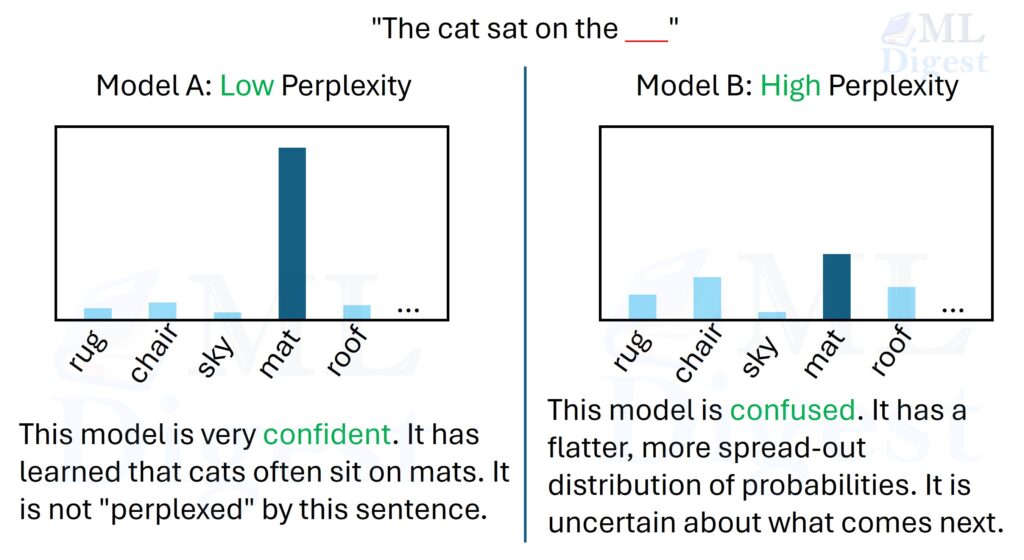
Perplexity answers one narrow question: When the true next token is revealed, how confused/uncertain is the model? It is a
Perplexity (PPL): what it measures, how to compute it, and when it misleads Read More »
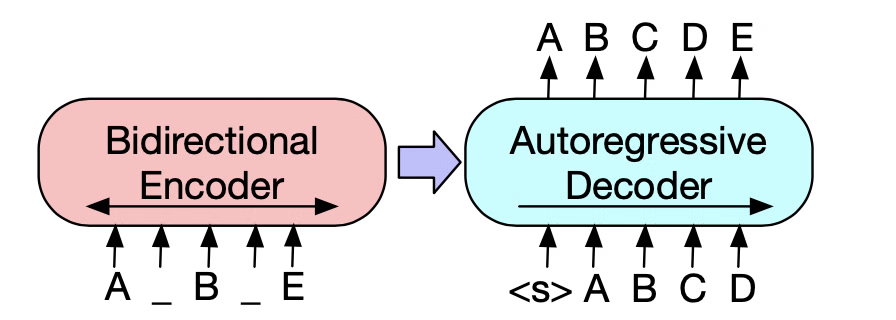
BART is a sequence-to-sequence (encoder–decoder) Transformer pretrained as a denoising autoencoder: it learns to reconstruct clean text $x$ from a
BART (Bidirectional and Auto-Regressive Transformers) Read More »
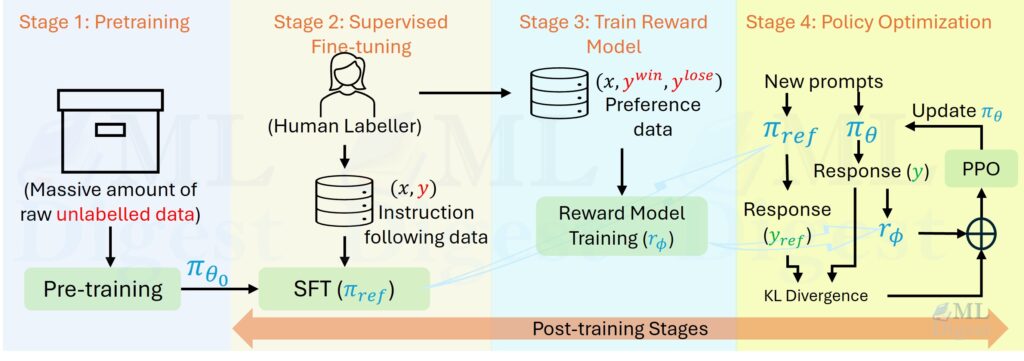
RLHF is a post-training recipe for turning a broadly capable language model into a more useful assistant. In practice, it
Reinforcement Learning with Human Feedback (RLHF) Read More »
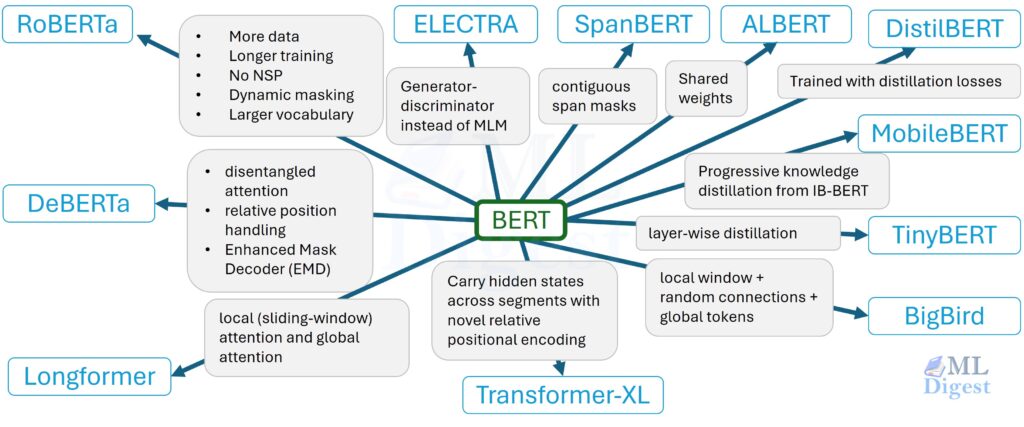
Think of BERT as a strong, general-purpose “reader” that turns text into contextual vectors. The moment you move from a
BERT Variants: A Practical, Technical Guide Read More »

Chatbots produce text. Agents produce outcomes. The conceptual shift is simple: instead of stopping at an answer, an AI agent
AI Agents and Agentic Systems: From Chat to Action Read More »
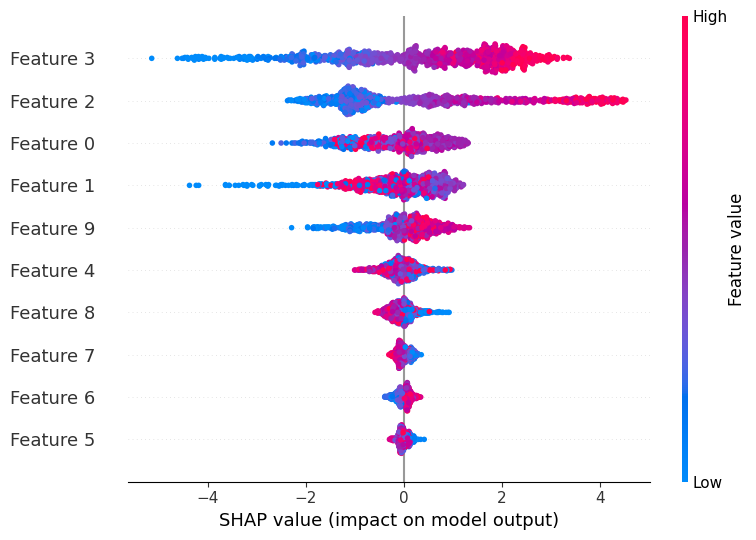
Imagine you have trained a complex gradient-boosted tree to predict house prices. It achieves state-of-the-art accuracy, but when it predicts
SHAP (Shapley Additive Explanations): From Intuition to Implementation Read More »
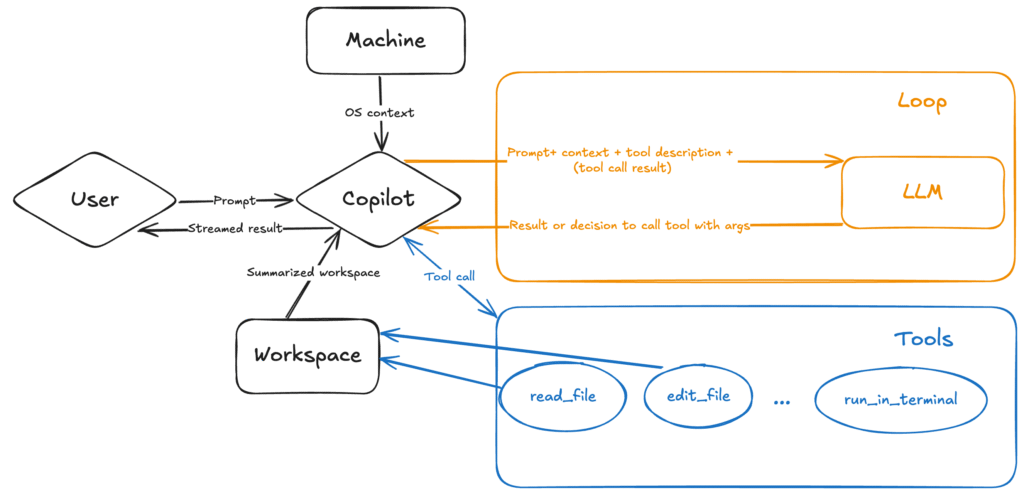
GitHub Copilot is evolving from in-editor code completion toward a software engineering assistant capable of independent action. In Agent Mode,
How GitHub Copilot Works in Agent Mode Read More »
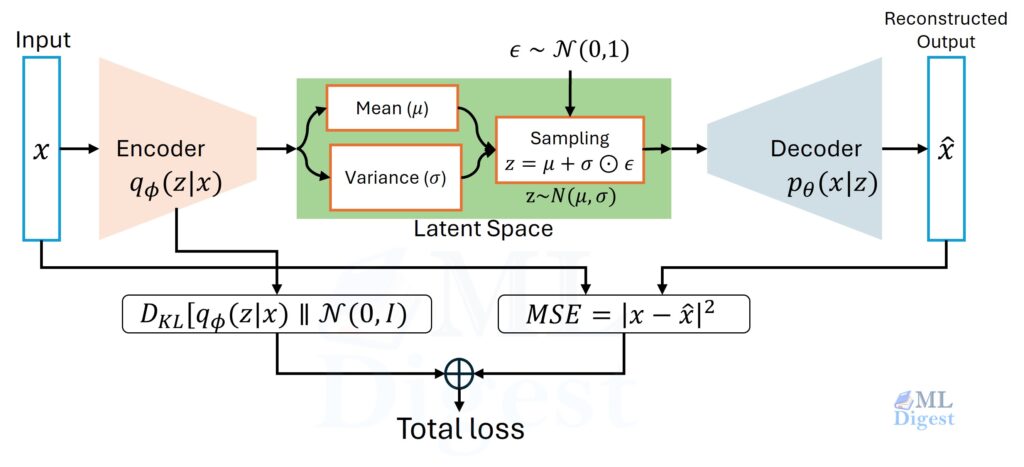
Imagine you are trying to teach a computer to paint. A classic autoencoder is a skilled copier: it learns an
Variational Autoencoders (VAEs): Intuition, Math, and Practical Implementation Read More »
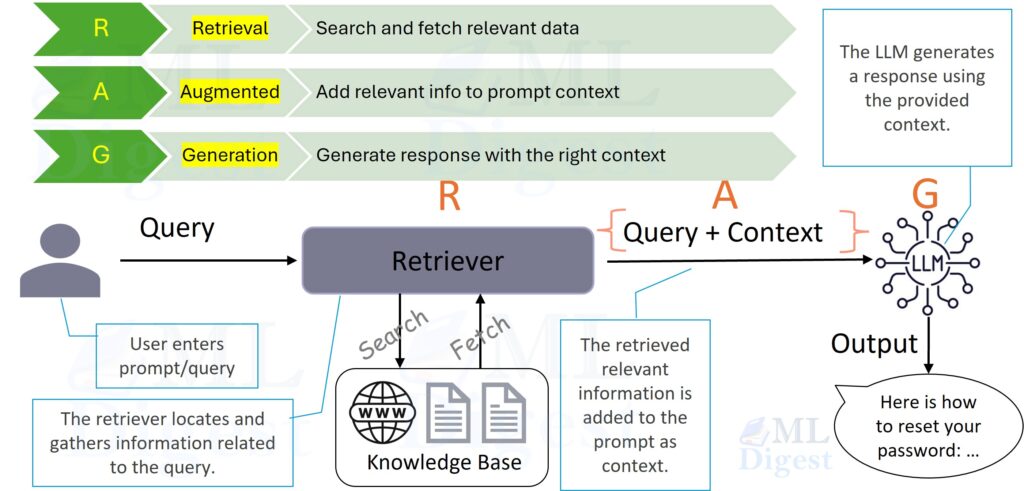
Retrieval-Augmented Generation (RAG) is a technique that acts as an open-book exam for Large Language Models (LLMs). It allows a
Retrieval-Augmented Generation (RAG): A Practical Guide Read More »
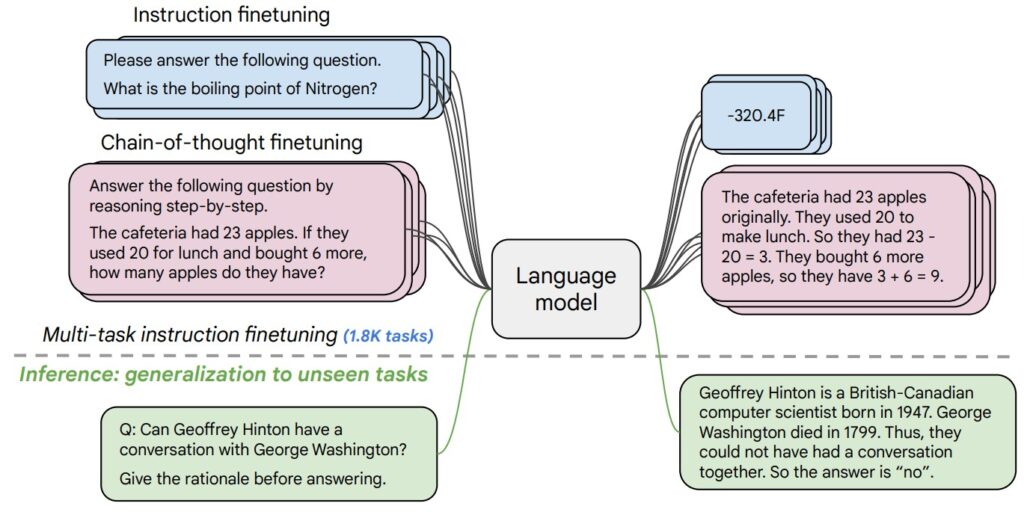
Imagine a student who has memorized an entire textbook, but only answers questions when they are phrased exactly like the
FLAN-T5: Instruction Tuning for a Stronger “Do What I Mean” Model Read More »