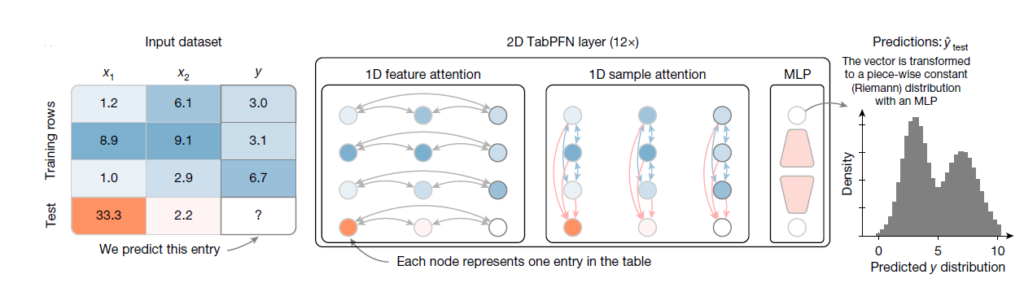
Here are the 20 influential AI papers in 2024:
Mixtral of Experts (Jan 2024) [paper]
- This paper describes Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) model.
- It uses 8 expert networks per layer but only activates 2 experts per token.
- Mixtral 8x7B outperformed Llama 2 70B and GPT-3.5 on a variety of benchmarks.
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model (Jan 2024) [paper]
- Introduces the use of state-space models (SSMs) for computer vision tasks, offering a more efficient alternative to transformer-based architectures.
- Achieves competitive performance with linear complexity, making it suitable for real-time applications like robotics and AR/VR systems.
Genie: Generative Interactive Environments (Feb 2024)[paper]
- This paper introduces a generative model capable of creating interactive virtual environments.
- Developed by Google DeepMind, Genie was trained on over 200,000 hours of gameplay videos.
- Genie can generate diverse environments that users can explore interactively.
DoRA: Weight-Decomposed Low-Rank Adaptation (February 2024)[paper]
- This paper extends LoRA, a popular method for parameter-efficient LLM finetuning.
- DoRA decomposes a pretrained weight matrix into a magnitude vector and a directional matrix.
- DoRA makes subtle directional adjustments without necessarily increasing the magnitude.
Simple and Scalable Strategies to Continually Pre-train Large Language Models (March 2024)[paper]
- This 24-page paper reports on numerous experiments on continued pretraining of LLMs.
- The paper suggests that re-warming and re-decaying the learning rate will improve LLM performance.
- Adding a small portion of the original pretraining data to the new dataset will also improve LLM performance.
Gemma: Open Models Based on Gemini Research and Technology (Mar 2024)[paper]
- This paper presents two of Google’s newest models, which are 2 billion and 7 billion parameters, respectively.
- The models outperform similarly sized models in almost 70% of the investigated language tasks.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study (April 2024)[paper]
- This paper compares Direct Preference Optimisation (DPO) and Proximal Policy Optimisation (PPO).
- The authors concluded that PPO tends to outperform DPO.
- DPO is inferior when used with out-of-distribution data.
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction (Apr 2024)[paper]
- This paper, which won an award at the 2024 NeurIPS conference, presents a new approach to image generation called Visual AutoRegressive (VAR) modeling.
- VAR modeling predicts images in stages, ranging from coarse to fine resolutions, resulting in more efficient training and enhanced performance.
Vision Transformers Need Registers (Apr 2024)[paper]
- This paper won an Outstanding Paper Award at the International Conference of Learning Representations (ICLR 2024).
- The authors added “register tokens” to the input of vision transformers to improve the model’s performance.
- The register tokens address the issue of the model generating high-value tokens for less important areas of an image, such as the background.
KAN: Kolmogorov-Arnold Networks (Apr 2024) [paper]
- Combines kernel methods with deep learning principles to create a novel architecture for data representation and processing.
- Offers scalability and robustness, particularly in tasks requiring high interpretability or dynamic adaptability, such as time series analysis and scientific research.
Why Larger Language Models Do In-context Learning Differently? (May 2024)[paper]
- This highly cited study found that small language models (SLMs) are more robust to noise than larger language models (LLMs).
- SLMs are “less easily distracted” because they focus on a narrower range of hidden features.
Accurate Structure Prediction of Biomolecular Interactions with AlphaFold 3 (May 2024)[paper]
- This paper introduces the new AlphaFold 3 (AF3) model.
- This model can predict the joint structures of various biomolecular complexes.
- AF3 outperforms previous specialized tools in predicting protein-ligand and protein-nucleic acid interactions.
LoRA Learns Less and Forgets Less (May 2024)[paper]
- This empirical study compares LoRA with full finetuning for LLMs.
- LoRA learns less than full finetuning.
- LoRA consistently forgets less than full finetuning.
The Llama 3 Herd of Models (July 2024)[paper]
- This paper introduced Meta’s new 405B-parameter multilingual language model.
- The model integrates multimodal capabilities, enabling it to perform competitively in use cases such as speech, image, and video recognition.
- Llama 3 also includes Llama Guard 3 for secure input and output.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (August 2024)[paper]
- This paper introduces the phi-3 series, which includes phi-3-mini, phi-3-small, and phi-3-medium.
- The phi-3-mini is a 3.8 billion parameter language model trained on 3.3 trillion tokens.
- Despite its compact size, phi-3-mini can be deployed on devices like smartphones.
Qwen2 Technical Report (September 2024)[paper]
- This paper introduces the Qwen2 series, including models from 0.5 to 72 billion parameters.
- It outperforms its predecessor Qwen1.5 and many open-weight models.
- Qwen2 supports 30 languages.
Movie Gen: A Cast of Media Foundation Models (October 2024)[paper]
- This paper introduces foundation models for generating high-quality videos with audio.
- The models excel in text-to-video synthesis, video personalisation, video editing, and text-to-audio generation.
- The largest model can generate 16-second videos at 16 frames-per-second.
Byte Latent Transformer: Patches Scale Better Than Tokens (December 2024)[paper]
- This paper introduces the Byte Latent Transformer (BLT), which achieves tokenization-based LLM performance with improved inference efficiency.
- BLT encodes data into dynamically sized patches, allocating more computation where complexity increases.
- BLT models are trained on raw bytes instead of fixed vocabularies.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory-Efficient, and Long Context Fine-Tuning and Inference (December 2024)[paper]
- This paper introduces ModernBERT, which improves the BERT architecture.
- Trained on 2 trillion tokens, ModernBERT achieves state-of-the-art results across a wide range of evaluations.
- ModernBERT offers superior efficiency for inference on common GPUs.
DeepSeek-V3 Technical Report (December 2024)[paper]
- This paper introduces DeepSeek-V3, a 671B parameter Mixture-of-Experts (MoE) model.
- DeepSeek-V3 utilizes Multi-head Latent Attention (MLA) and DeepSeekMoE architectures.
- DeepSeek-V3 outperforms other open-source models and rivals leading closed-source models.
Reference

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!