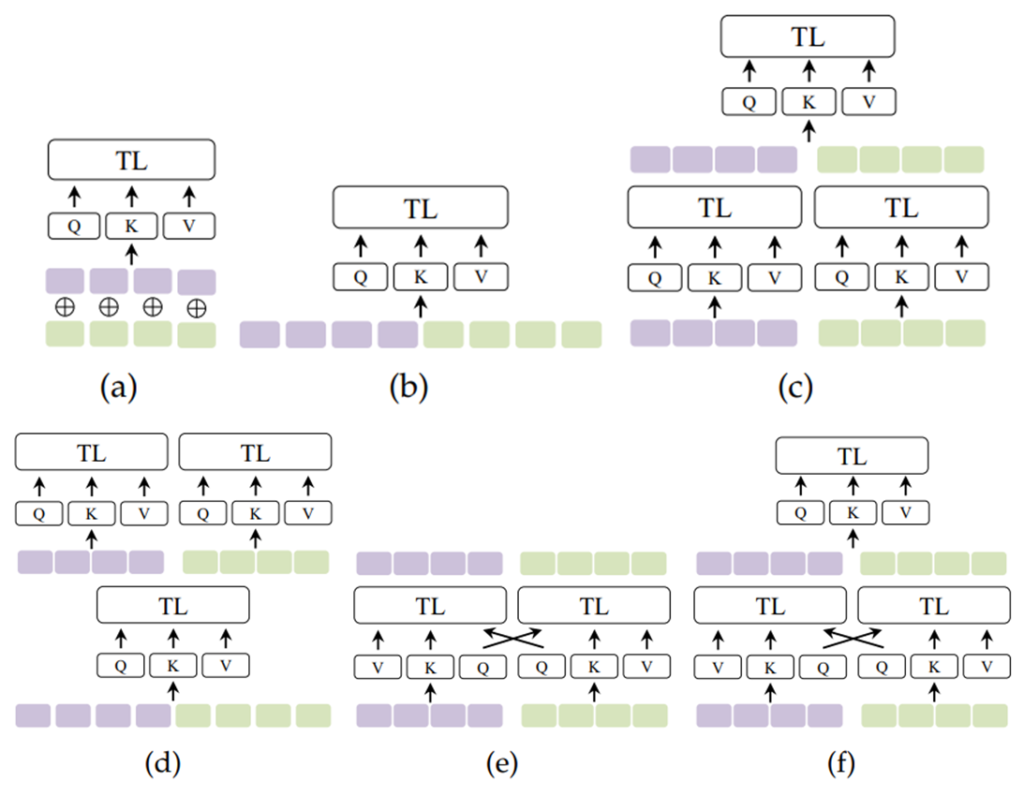
A Guide to Positional Embeddings: Absolute (APE) vs. Relative (RPE)
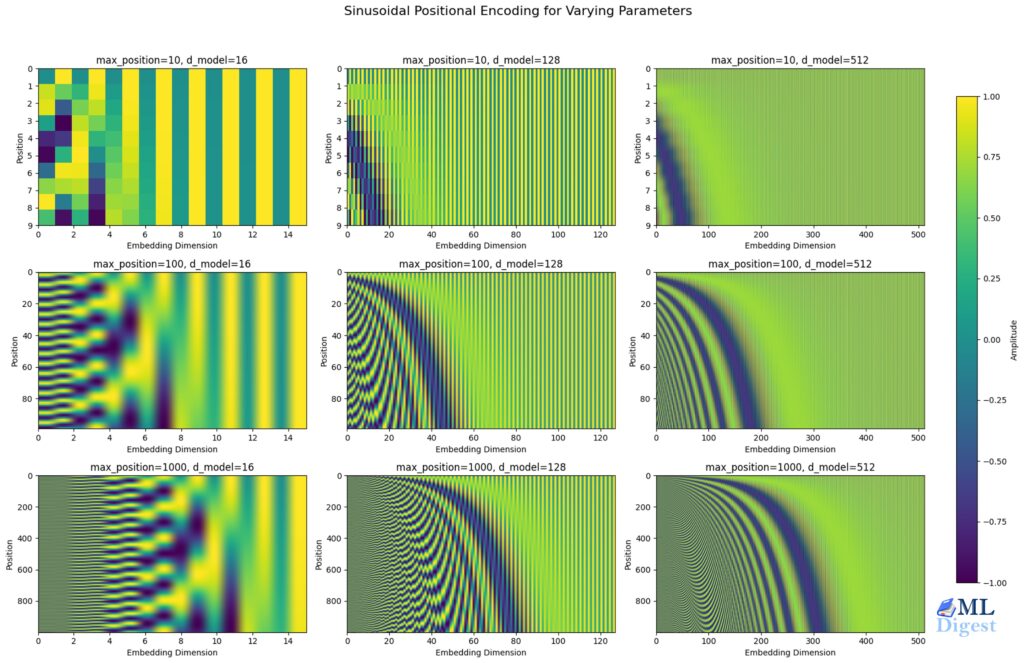
Think of a bookshelf versus a long hallway: absolute positional embeddings (APE) assign each token a fixed “slot” on the shelf, while relative positional embeddings (RPE) care only about the distance between tokens — like how far two people stand in a hallway. This article first builds intuition with simple analogies and visual descriptions, then dives into the math: deriving sinusoidal APE, showing how sin–cos interactions yield purely relative terms, and explaining how RPE is injected into attention (including T5-style relative bias). Practical PyTorch examples are provided so the reader can implement APE and RPE, understand their trade‑offs (simplicity and extrapolation vs. relational power), and choose the right approach for real-world sequence tasks.
A Guide to Positional Embeddings: Absolute (APE) vs. Relative (RPE) Read More »