
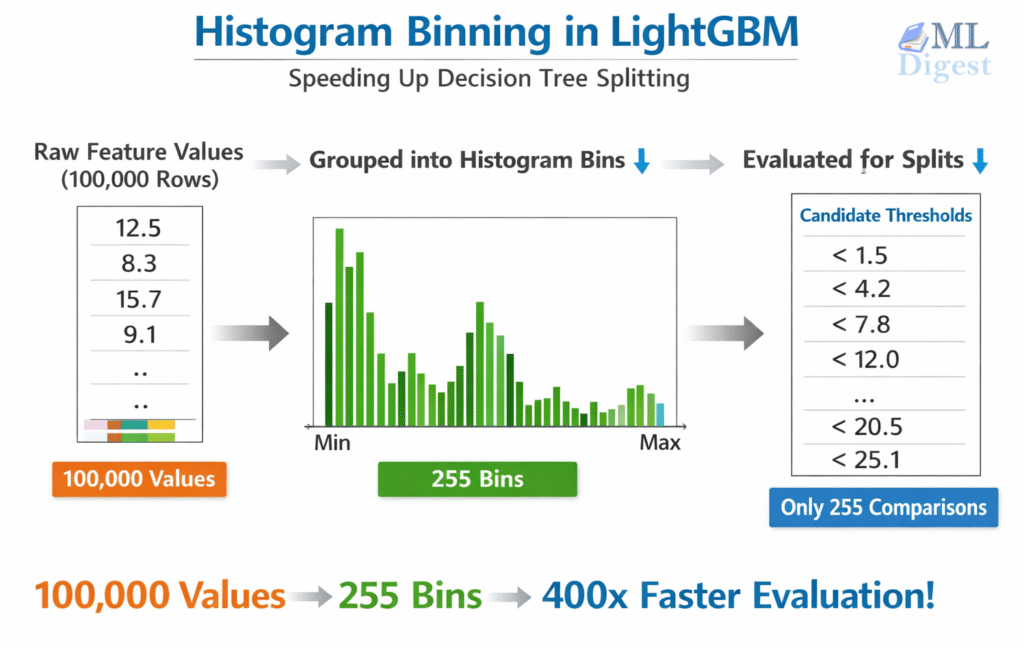
The Illustrated LightGBM: A Beginner-Friendly Guide
In tabular machine learning, the winning recipe is often not a flashy architecture but strong features plus a fast, reliable […]
The Illustrated LightGBM: A Beginner-Friendly Guide Read More »
In tabular machine learning, the winning recipe is often not a flashy architecture but strong features plus a fast, reliable […]
The Illustrated LightGBM: A Beginner-Friendly Guide Read More »
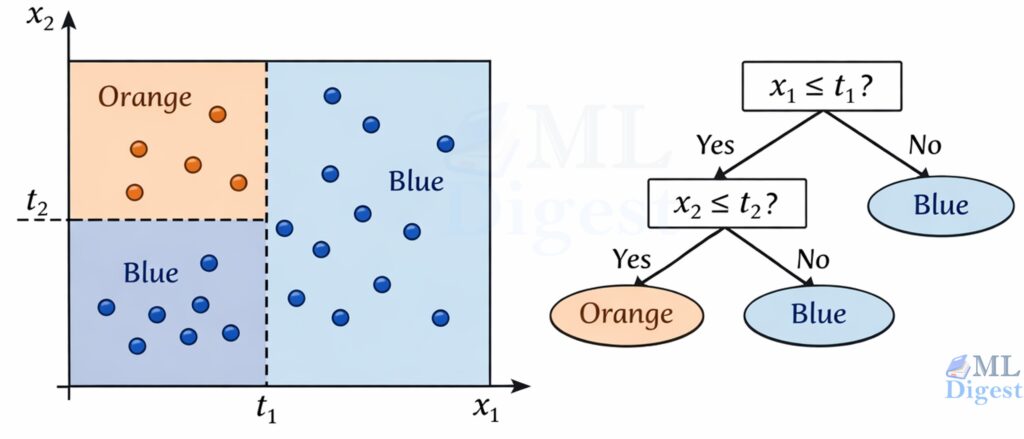
Decision trees are one of the simplest ways to turn data into a sequence of human-readable rules. You can think
How Decision Trees Work: A Practical Machine Learning Guide Read More »
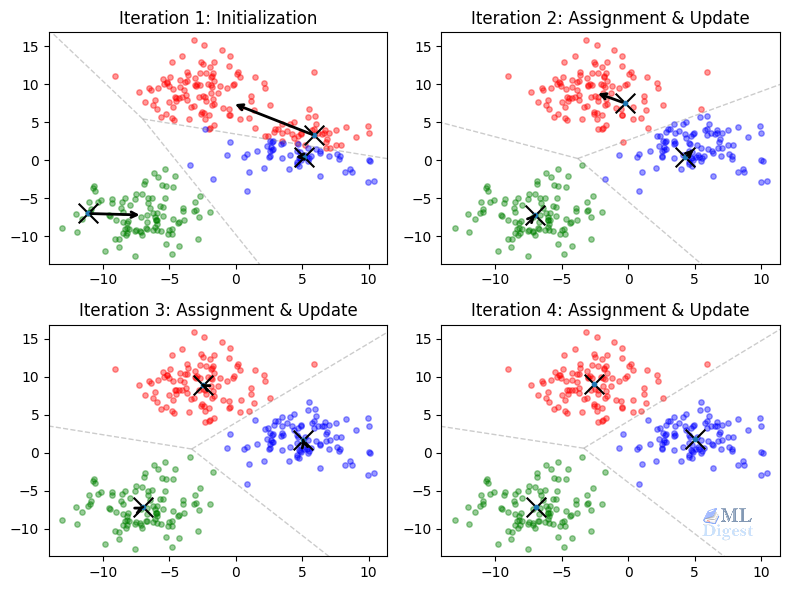
Imagine that you need to open $K$ new coffee shops in a city. You want each person to walk to
Understanding K-Means Clustering: Intuition, Math, and Practical Implementation Read More »
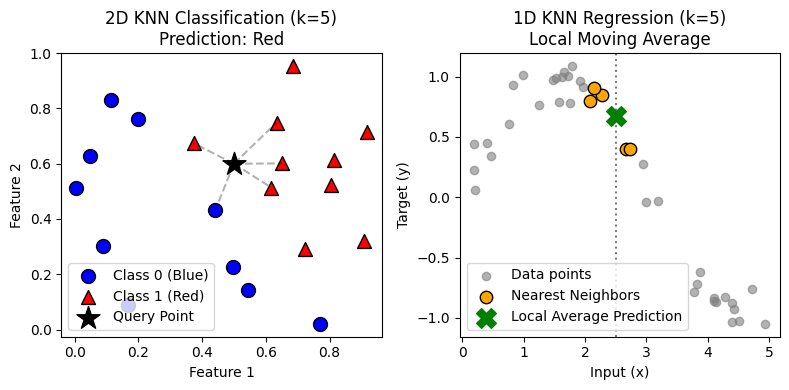
There is an old proverb that perfectly captures the intuition behind one of the most fundamental algorithms in machine learning:
k-Nearest Neighbors (KNN): From Geometry to Algorithms Read More »
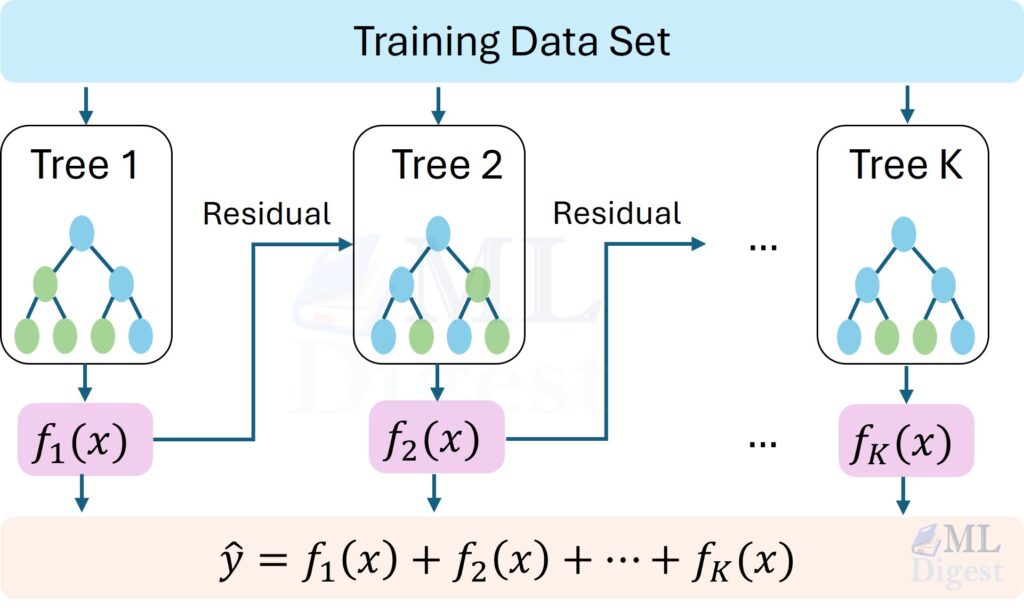
Before LightGBM entered the scene, another algorithm reigned supreme in the world of machine learning competitions and industrial applications: XGBoost.
XGBoost: Extreme Gradient Boosting — A Complete Deep Dive Read More »

Logistic Regression is one of the simplest and most widely used building blocks in machine learning. In this article, we
Logistic Regression in PyTorch: From Intuition to Implementation Read More »
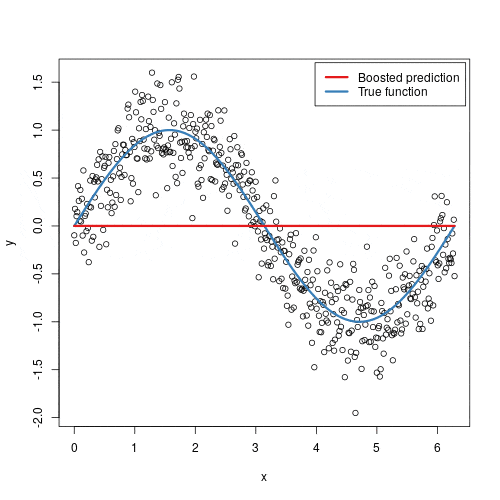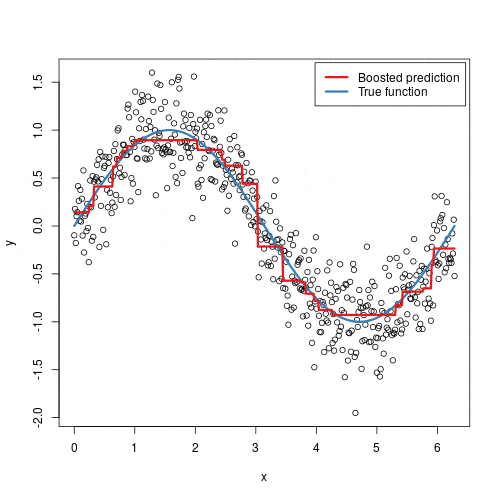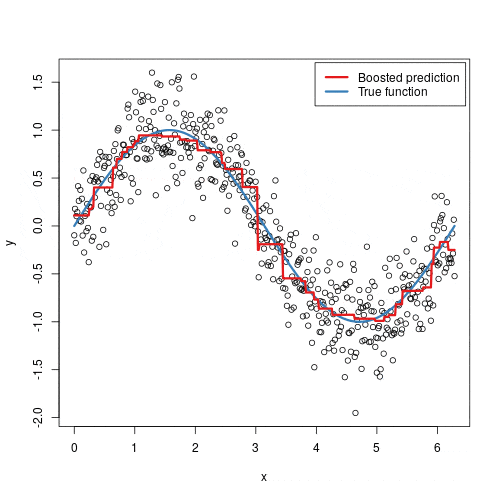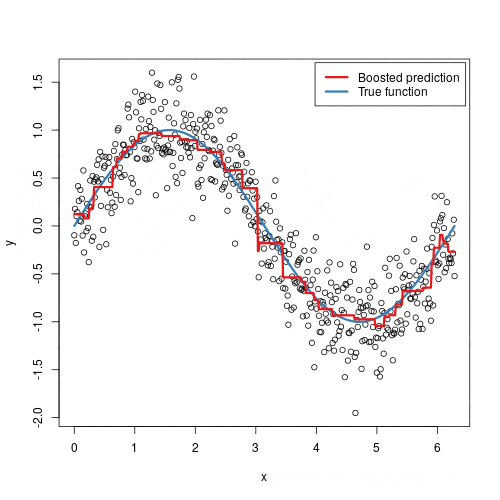
Gradient Boosting is more than just another algorithm; it is a fundamental concept that combines several key ideas in machine learning: the wisdom of ensembles, the precision of gradient descent, and the power of iterative improvement. By building a model that learns from its mistakes in a structured, mathematically-grounded way, it has rightfully earned its place as one of the most effective and versatile tools in a data scientist’s toolkit.
Gradient Boosting: Building Powerful Models by Correcting Mistakes Read More »

FastText is a testament to the power of simple ideas. By treating words as compositions of their parts, it elegantly solves the out-of-vocabulary problem and provides a robust way to represent language. Its speed and efficiency, for both embedding generation and classification, make it a go-to tool for NLP practitioners.
What is FastText? Quick, Efficient Word Embeddings and Text Models Read More »

Target encoding, also known as mean encoding or impact encoding, is a powerful feature engineering technique used to transform high-cardinality
Target Encoding: A Comprehensive Guide Read More »

Extremely Randomized Trees (Extra-Trees) is a machine learning ensemble method that builds upon Random Forests construction process. Unlike Random Forests,
Understanding Extra-Trees: A Faster Alternative to Random Forests Read More »

Random forest is a powerful ensemble learning algorithm used for both classification and regression tasks. It operates by constructing multiple
The Complete Guide to Random Forest: Building, Tuning, and Interpreting Results Read More »
In today’s data-rich and digitally connected world, users expect personalized experiences. Recommendation systems are crucial for providing users with tailored
What are Recommendation Systems and How Do They Work? Read More »