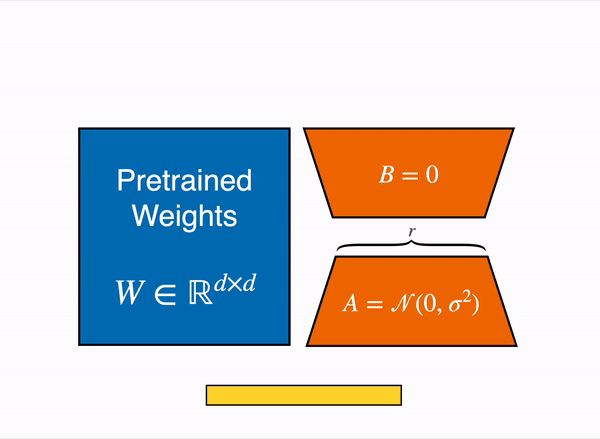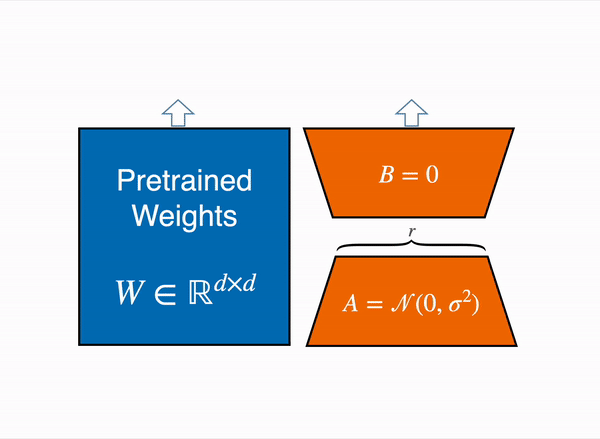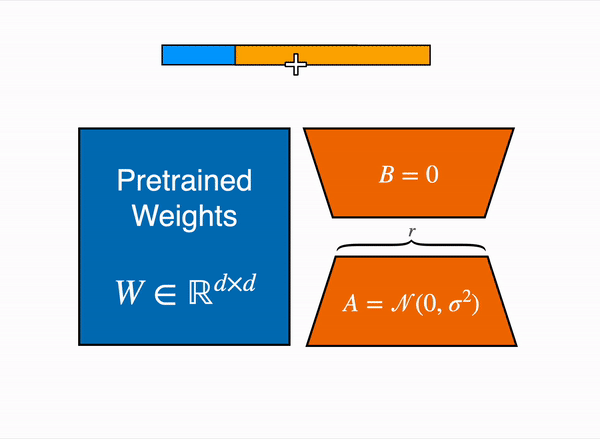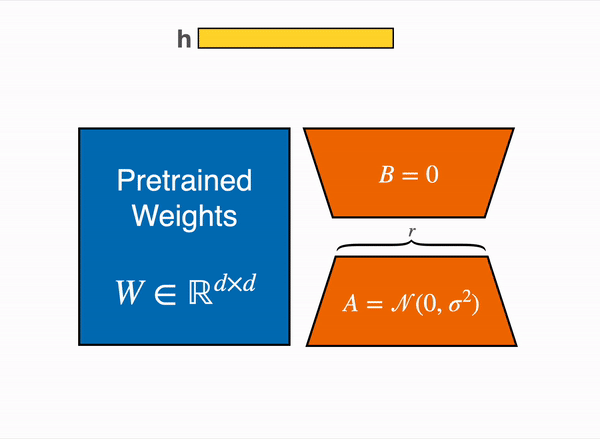
Dissecting the Vision Transformer (ViT): Architecture and Key Concepts
Vision Transformers (ViT) have emerged as a groundbreaking architecture that has revolutionized how computers perceive and understand visual data. Introduced […]
Dissecting the Vision Transformer (ViT): Architecture and Key Concepts Read More »