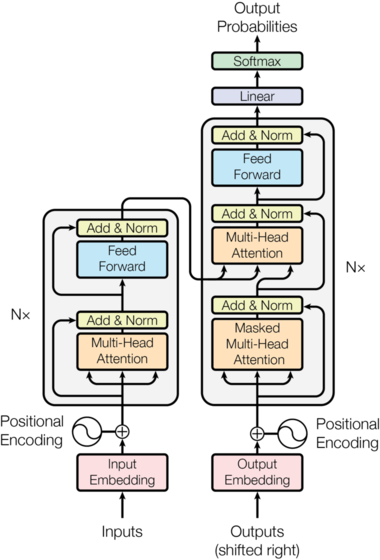
BART is a sequence-to-sequence (encoder–decoder) Transformer pretrained as a denoising autoencoder: it learns to reconstruct clean text $x$ from a corrupted version $\tilde{x}$.
Even though it was introduced in 2019, BART remains a practical production model for supervised, high-throughput conditional generation. Compared with large decoder-only LLMs, it is usually fine-tuned on a task dataset and then deployed with a much smaller runtime footprint.
This note focuses on the technical write-up:
- When BART is the right tool (and when it is not)
- The encoder–decoder architecture and the role of cross-attention
- The denoising pretraining objective and corruption functions
- What changes from pretraining to fine-tuning
- Common pitfalls and how to diagnose them
Subscribe to our newsletter!
1) When BART is the right tool
1.1 What problem it solved
Before encoder–decoder pretraining became mainstream, popular pretraining families had a clean trade-off:
- BERT-style models (masked language modeling) are great for understanding but not naturally generative.
- GPT-style models (left-to-right language modeling) are naturally generative but less directly optimized for bidirectional context during encoding.
BART combines the strengths by using:
- A bidirectional encoder (like BERT) reads the (corrupted) input with full context.
- An autoregressive decoder (like GPT) generates the output token-by-token.
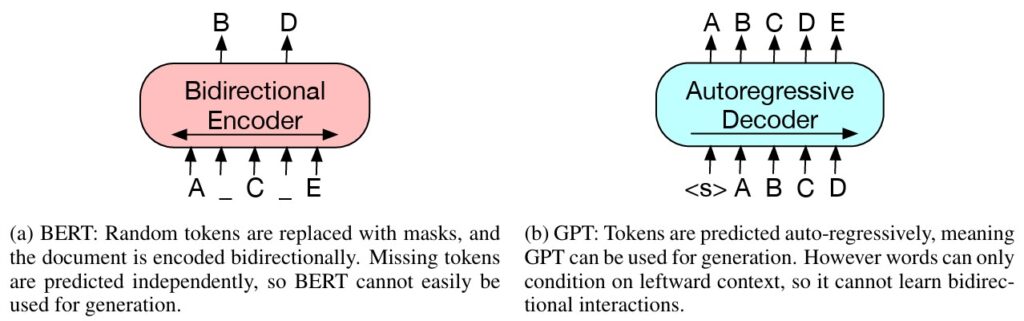
This design targets conditional generation: you have an input sequence (source document) and you want a related output sequence (summary/translation/rewrite). In probabilistic terms, you model $p(\text{output}\mid\text{input})$.
1.2 Good fits
BART is a strong default when you need:
- Conditional generation: summarize, rewrite, simplify, paraphrase, translate.
- An input document and a target output with a different length.
- A pretrained backbone for seq2seq tasks without task-specific pretraining assumptions.
Prefer encoder-only models (BERT/RoBERTa) when the output is a label, embedding, or ranking score (classification / retrieval). Prefer decoder-only LMs if you want open-ended continuation without an explicit conditioning input, or you’re doing instruction-following style prompting.
1.3 Non-obvious drawbacks
- Slower inference than encoder-only: generation is autoregressive (token-by-token).
- Context length constraints: many classic BART checkpoints use
max_position_embeddings=1024(tokens, not words). Confirm for your checkpoint viamodel.config.max_position_embeddings. - Factuality is not guaranteed: summarizers can hallucinate. ROUGE measures overlap, not truth.
A practical mindset shift: BART is best when you can afford to define the task narrowly (inputs and outputs are well-specified) and you value repeatable behavior. If the task is open-ended, requires tool use, or needs multi-step reasoning, a modern instruction-tuned LLM is typically a better fit.
1.4 Relationship to similar models (quick mental map)
- BART vs T5: both are encoder–decoder, trained with corruption → reconstruction. T5 frames everything as explicit text-to-text with sentinel tokens; BART uses a broader set of corruptions (deletion, infilling, permutation, etc.).
- BART vs RoBERTa: RoBERTa is encoder-only and excels at understanding tasks; BART adds a decoder and is trained to generate.
1.5 Essential Variants (mBART & LED)
Understanding two key derivatives is crucial for real-world use:
- mBART (Multilingual BART): Pretrained on many languages (e.g., mBART-50). It is a standard backbone for translation. Crucial detail: You must manage language-specific start/end tokens (e.g.,
en_XX,de_DE) during tokenization, which is a frequent source of bugs. - LED (Longformer-Encoder-Decoder): Standard BART struggles with long docs ($O(N^2)$ attention). LED substitutes the encoder’s full attention with sparse “Longformer” attention, allowing input windows of 16k tokens. Use LED if your documents are 20+ pages.
1.6 Decision Guide: BART vs. Modern LLMs
Today, why choose a 2019 model when modern LLMs exist?
| Feature | BART (Fine-tuned) | Modern LLMs |
|---|---|---|
| Paradigm | Supervised Finetuning (SFT) | Zero-shot / Few-shot Prompting |
| Data Requirement | High (Needs 500+ formatted examples) | Low (Needs just instructions) |
| Inference Cost | Very Low (Runs on CPU or cheap GPU) | High (Requires large VRAM or API) |
| Latency | Milliseconds (low parameter count) | Seconds |
| Control | High (Learns strict output format) | Moderate (Can be chatty/disobedient) |
Verdict: Use BART for high-volume production pipelines where you can curate training pairs and you want stable formatting and latency. Use LLMs for rapid prototyping, tasks with weak supervision, or workflows that benefit from interactive reasoning.
2) High-level architecture
2.1 Encoder–decoder Transformer
BART uses a standard Transformer encoder–decoder layout:
- Encoder consumes the corrupted input $\tilde{x}$ and produces contextual hidden states.
- Decoder attends to those encoder states and generates the original clean text $x$.
Key components:
- Multi-head self-attention in encoder and decoder
- Cross-attention in decoder (decoder attends to encoder outputs)
- Feed-forward blocks, residual connections, layer normalization
Conceptually:
- Corrupt clean text $x$ to get $\tilde{x}$ (pretraining only).
- Encode $\tilde{x}$ (or your task input at fine-tuning time).
- Decode and predict the target text ($x$) autoregressively.
2.2 “Bidirectional encoder + autoregressive decoder”
- Bidirectional encoder: each input position can attend to tokens on both left and right of the input sequence.
- Autoregressive decoder: token $y_t$ is predicted using previously generated tokens $y_{<t}$.
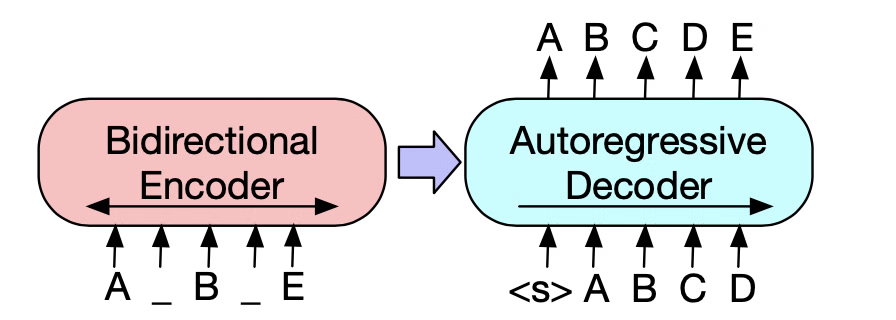
This matches typical fine-tuning: given an input (document), generate an output (summary). The encoder gives the decoder a rich, global representation of the source; the decoder turns that representation into a sequence one token at a time.
3) Pretraining objective (denoising)
3.1 Notation
- Clean text sequence: $x = (x_1, x_2, \dots, x_T)$
- Corruption/noising function: $C(\cdot)$
- Corrupted input: $\tilde{x} = C(x)$
- Model conditional distribution: $p_\theta(x \mid \tilde{x})$
3.2 Denoising autoencoding objective
BART is trained to maximize the likelihood of reconstructing $x$ given $\tilde{x}$:
$$
\max_\theta \; \mathbb{E}_{x \sim \mathcal{D}}\; \mathbb{E}_{\tilde{x} \sim C(x)} \left[\log p_\theta(x \mid \tilde{x})\right]
$$
With an autoregressive decoder, this expands as:
$$
\log p_\theta(x \mid \tilde{x}) = \sum_{t=1}^{T} \log p_\theta(x_t \mid x_{<t}, \tilde{x})
$$
Training uses token-level cross-entropy loss:
$$
\mathcal{L}(\theta) = – \sum_{t=1}^{T} \log p_\theta(x_t \mid x_{<t}, \tilde{x})
$$
3.3 Corruption / noising functions
The core idea is to make reconstruction harder than “predict a masked token in place”. By corrupting spans and even global structure (sentence order), BART forces the model to rely on semantics and discourse cues rather than local n-gram patterns.
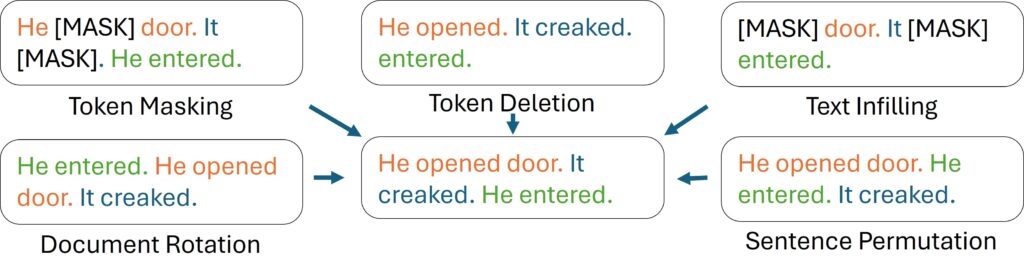
The image above illustrates different corruption strategies. Below is a concrete walkthrough using another example sentence “The quick brown fox jumps over the dog” ($x$):
- Text infilling (span masking): Sample a span length (for example, from a Poisson distribution) and replace the entire span with a single mask token.
- $\tilde{x}$: “The quick [MASK] jumps over the dog” (replaces “brown fox”)
- Goal: The model must infer both content and span length.
- Token deletion: Delete tokens entirely.
- $\tilde{x}$: “The brown fox over the dog”
- Goal: Model must decide which positions are missing inputs.
- Sentence permutation: Shuffle sentences in a document.
- $\tilde{x}$: “Over the dog. The quick brown fox jumps.” (assuming two sentences)
- Goal: Learn logical flow and discourse structure.
- Token masking: BERT-style masking.
- $\tilde{x}$: “The quick [MASK] fox jumps [MASK] the dog”
- Document rotation: Pick a random token and rotate the document so it starts with that token.
- $\tilde{x}$: “jumps over the dog. The quick brown fox” (tokens of the document retain order, but start point changes)
Intuition:
- Deletions and span infilling force the encoder to build robust representations.
- Sentence permutation / rotation encourage discourse-level and longer-range reasoning.
BART’s pretraining is not “fill in masked tokens in place”; it is “generate the full original sequence conditioned on a corrupted sequence”. This matters because most downstream seq2seq tasks also look like “generate an output conditioned on an input”, so the pretraining-to-fine-tuning transition is conceptually aligned.
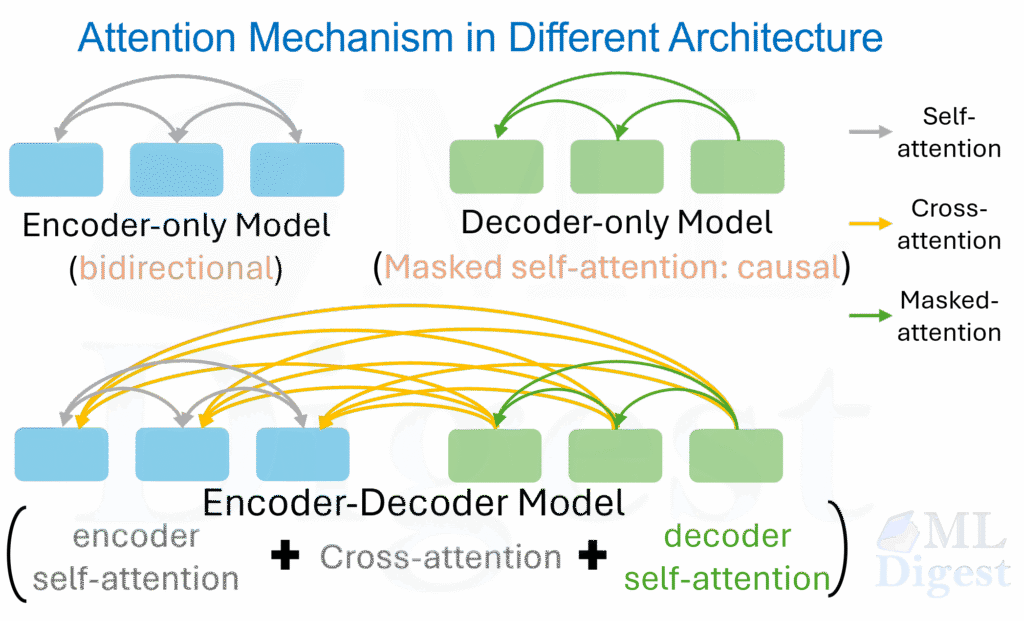
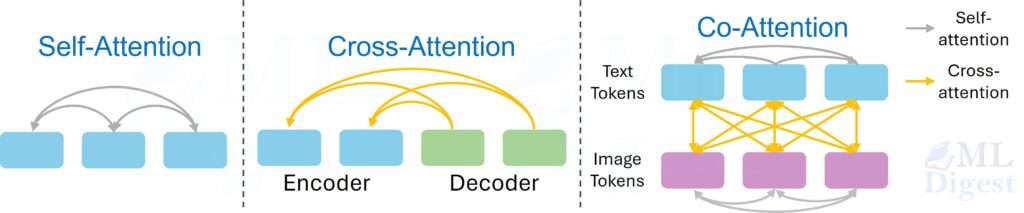
4) Cross-attention (the bridge between reading and writing)
Self-attention explains how tokens interact within the source (encoder) or within the generated prefix (decoder). Cross-attention is the mechanism that lets the decoder consult the source representation at every generation step.
For every token generated by the decoder:
- Decoder Self-Attention: Look at what I have generated so far ($x_{<t}$).
- Cross-Attention: Look at the entire input sequence ($Enc_{out}$).
- Queries ($Q$): Come from the Decoder (current state).
- Keys ($K$) & Values ($V$): Come from the Encoder (input document).
For a sequence of hidden states $H \in \mathbb{R}^{n \times d}$:
- Queries: $Q = HW_Q$
- Keys: $K = HW_K$
- Values: $V = HW_V$
Scaled dot-product attention:
$$
\mathrm{Attn}(Q,K,V) = \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}} + M\right)V
$$
where $M$ is a mask:
- Encoder self-attention: typically no causal mask.
- Decoder self-attention: a causal (triangular) mask so position $t$ cannot see future tokens.
- Decoder cross-attention: queries from decoder, keys/values from encoder outputs.
Multi-head attention runs this in parallel across heads and concatenates.
Mathematically, the decoder asks: “Given my current generation state (queries), which source positions (keys) are relevant, and what information should I extract (values)?”
This mechanism often behaves like soft alignment: when the decoder is about to generate a specific phrase, the cross-attention distribution typically peaks on the source spans that support that phrase.
5) Fine-tuning: what changes vs pretraining
In most applications you fine-tune BART as a conditional generator. The input is no longer “corrupted text”; it is your task source sequence $s$. The target $t$ is what you want the model to generate.
Given an input $s$ and target $t$:
$$
\mathcal{L}(\theta) = -\sum_{i=1}^{|t|} \log p_\theta(t_i \mid t_{<i}, s)
$$
Examples:
- Summarization: $s = \text{document}$, $t = \text{summary}$
- Translation: $s = \text{source language}$, $t = \text{target language}$
- Classification: $s = \text{input text}$, $t = \text{class label token}$
Practical implication: you usually train with teacher forcing (the decoder receives the gold prefix $t_{<i}$), but at inference time you must run decoding (beam search or sampling). This train–test mismatch is one reason decoding choices can have a surprisingly large effect on perceived quality.
6) Practical implementation (Hugging Face Transformers)
Below is a realistic workflow for fine-tuning and inference. It assumes you already have paired data: input_text → target_text.
Tokenization (important details)
BART uses a subword tokenizer (BPE-like). In a seq2seq setup:
- Inputs go to the encoder.
- Labels are the target tokens; padding tokens in labels should be masked out with
-100(so loss ignores them).
Two practical gotchas:
- Use
DataCollatorForSeq2Seq(or mask label pads yourself) so the loss does not train on padding. - Prefer
max_new_tokensat inference; it avoids surprising behavior when input lengths vary.
Key fields when preparing batches: input_ids, attention_mask, labels
Minimal fine-tuning script (Trainer)
This is a compact starting point for fine-tuning. Adjust hyperparameters based on GPU memory, sequence lengths, and dataset size.
import rouge_score
import evaluate
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForSeq2SeqLM,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer,
)
checkpoint = "facebook/bart-base"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, use_fast=True)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
max_source_length = 768
max_target_length = 128
def preprocess(batch):
model_inputs = tokenizer(
batch["dialogue"],
max_length=max_source_length,
truncation=True,
)
labels = tokenizer(
text_target=batch["summary"],
max_length=max_target_length,
truncation=True,
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# Replace with your dataset loading
dataset = load_dataset("knkarthick/samsum")
dataset = dataset.map(preprocess, batched=True, remove_columns=dataset["train"].column_names)
rouge = evaluate.load("rouge")
def compute_metrics(eval_pred):
preds, labels = eval_pred
# When predict_with_generate=True, preds are generated token ids (already).
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = [[(l if l != -100 else tokenizer.pad_token_id) for l in label] for label in labels]
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
return rouge.compute(predictions=decoded_preds, references=decoded_labels)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
args = TrainingArguments(
output_dir="./bart-finetuned",
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=3,
warmup_ratio=0.06,
weight_decay=0.01,
logging_steps=50,
eval_strategy="no",
eval_steps=500,
save_steps=500,
save_total_limit=2,
fp16=True,
report_to="none",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset["train"], # replace
eval_dataset=dataset["validation"], # replace
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()Notes:
predict_with_generate=Trueensures evaluation usesmodel.generate().fp16=True(orbf16=Trueon newer GPUs) improves throughput.gradient_accumulation_stepslets you simulate bigger batches.
Optional stabilizers to consider when training is finicky:
max_grad_norm=1.0(gradient clipping)gradient_checkpointing=True(lower memory, slower)
Version note: tokenizer.as_target_tokenizer() is deprecated in newer transformers; text_target=... is the forward-compatible way.
Inference with generate()
Generation quality depends heavily on decoding settings, and “best” settings are task-dependent.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
checkpoint = "./bart-finetuned/checkpoint-921" # or your fine-tuned path
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
text = "Bob: I want to visit paris. I want to take a photo in front of eiffel tower."
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=768)
summary_ids = model.generate(
**inputs,
max_new_tokens=128,
num_beams=4,
length_penalty=1.0,
no_repeat_ngram_size=3,
)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))
# Expected output: "Bob wants to visit Paris and take a photo in front of the Eiffel Tower."Practical knobs:
num_beams: higher improves quality but slower.no_repeat_ngram_size: helpful for summarization to reduce repetition.early_stopping=True: sometimes helps beam search behave more predictably.max_new_tokens: safer thanmax_lengthwhen inputs vary.
Rule of thumb: if you see repetition, adjust decoding constraints first; if you see systematic factual errors, change data/task framing (decoding tweaks rarely “fix” hallucination).
Decoding cookbook
- Summarization (safe default):
num_beams=4,no_repeat_ngram_size=3,length_penalty≈1.0. - Shorter summaries: lower
max_new_tokens, or uselength_penalty<1.0. - Longer summaries: increase
max_new_tokens, or uselength_penalty>1.0. - More diversity (rewriting): set
do_sample=True, picktop_p+temperature(expect variance).
7) Fine-tuning best practices (what usually matters)
7.1 Data prep
- Clean alignment: ensure
input_textandtarget_textcorrespond exactly. - Remove leakage: if targets appear verbatim in inputs (e.g., summaries embedded in article), metrics become misleading.
- Deduplicate: large duplication can cause overfitting and inflated automatic scores.
- Normalize whitespace and remove broken Unicode where possible.
7.2 Sequence length strategy
BART has a fixed maximum context length depending on checkpoint/config.
For long documents:
- Truncation: simplest; keep the first $N$ tokens (works okay for news, less for scientific papers).
- Heuristic chunking: split into sections/paragraphs, summarize each, then summarize summaries.
- Retrieval + summarize: select salient sentences/paragraphs, then summarize the selection.
Practical tip: prefer measuring lengths in tokens (via the tokenizer) rather than words/characters; truncation happens in token space.
7.3 Hyperparameters (rule-of-thumb)
- Learning rate: often $1\text{e-}5$ to $5\text{e-}5$.
- Batch size: aim for larger effective batches via gradient accumulation.
- Warmup: 3–10% of steps is common.
- Label smoothing: can help a bit for generation stability (optional).
Also consider:
- Gradient clipping:
max_grad_norm=1.0is a common stabilizer. - Dropout: keep default unless overfitting is obvious.
7.4 Decoding best practices
Start with:
- Summarization: beam search (
num_beams=4or6), addno_repeat_ngram_size. - Creative rewriting: sampling (
do_sample=True,top_p=0.9,temperature=0.7), but expect more variance.
Avoid:
- Very high beam sizes without constraints (can increase repetition and reduce diversity).
7.5 Stability and speed
- Use mixed precision (
fp16/bf16) when possible. - Use gradient checkpointing if memory is tight (slower but fits longer sequences).
- Monitor GPU OOM: reduce
max_source_length, batch size, or enable accumulation.
8) Common pitfalls and troubleshooting
Troubleshooting generative models often feels like debugging a black box. In practice, most failures come from one of three mismatches: (1) the dataset does not match the stated task, (2) the training regime is unstable or underpowered, or (3) decoding settings amplify degenerate behaviors. The table below organizes common symptoms by the most likely root causes.
| Symptom | Likely Diagnosis | Prescribed Fixes |
|---|---|---|
| “Loss becomes NaN” (Training explodes) | – Learning Rate: Too high for the batch size. – Precision: fp16 instability (common in older GPUs).– Data: “Bad batches” containing empty strings or NaN inputs. | – Decrease LR: Try step-down (e.g., 5e-5 → 2e-5).– Clip Gradients: Set max_grad_norm=1.0 in TrainingArguments.– Sanitize Data: Filter out empty text rows before tokenization. |
| Outputs are repetitive (e.g., “the the the…”) | – Decoding: Beam search without penalties is prone to loops. – Data: Training targets contain repetitive phrases. | – Block N-grams: Set no_repeat_ngram_size=3 in generate().– Penalize: Add repetition_penalty=1.2 (values > 1.0 penalize repetition).– Sampling: Switch to do_sample=True if exact wording matters less than flow. |
| Outputs are too short (Summary cuts off) | – Penalty: The model is finding that stopping early minimizes loss. – EOS Token: The model predicts the “End of Sentence” token too aggressively. | – Boost Length: Set length_penalty=2.0 (encourages longer sequences).– Force Min: Set min_new_tokens=50 to prevent premature stopping. |
| “Model ignores the input” (Hallucination / Generic text) | – Signal Loss: The key information was truncated (it was past the 1024th token). – Dataset Noise: Targets don’t actually depend on inputs (weak supervision). | – Check Truncation: Ensure salient info is in the first 1024 tokens. – Inspect Data: Manually accept/reject 20 random training examples. – Train Longer: Underfitting models tend to output generic language model priors. |
| Truncation hurts quality (Missing end of doc) | – Architecture: Standard self-attention is $O(N^2)$, limiting context. | – Chunking: Split long docs into 1024-token chunks and summarize separately. – Switch Model: Use LED (Longformer-Encoder-Decoder) for 16k context windows without changing the paradigm. |
Conclusion
BART is best understood as “pretrained conditional generation”: a bidirectional encoder reads an input sequence and an autoregressive decoder writes an output sequence while repeatedly consulting the input through cross-attention. The denoising objective makes pretraining look structurally similar to downstream seq2seq tasks, which is why BART fine-tunes reliably for summarization, translation, and rewriting.
If you treat it as a production component (curate pairs, respect context limits, and debug decoding separately from training), BART remains a strong choice for fast, cost-efficient, high-volume text generation.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!