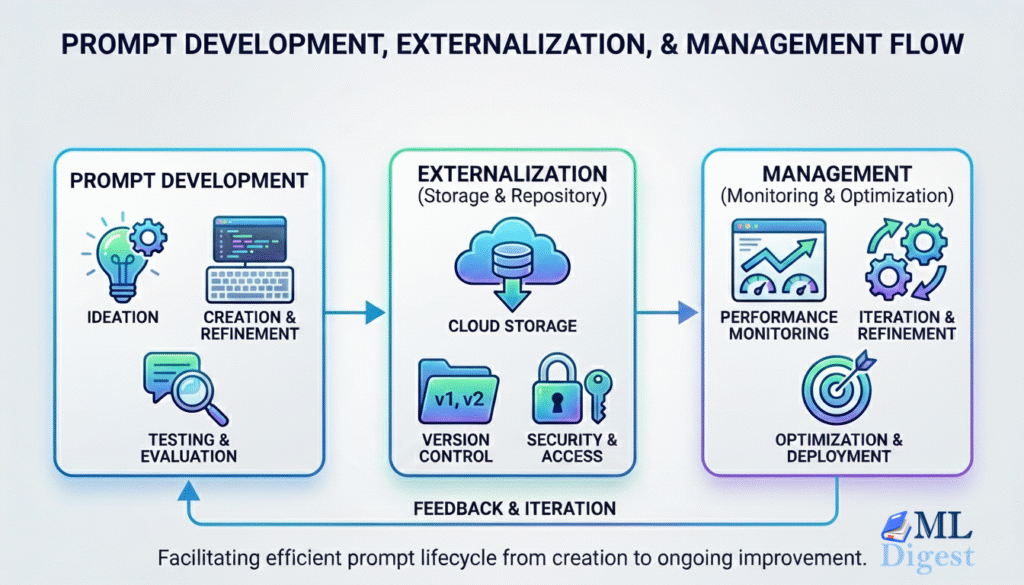
Evaluating the effectiveness of a prompt is crucial to harnessing the full potential of Large Language Models (LLMs). An effective prompt guides the model to generate accurate, relevant, and contextually appropriate responses. Assessing prompt effectiveness involves a combination of qualitative and quantitative methods, incorporating both human judgment and automated metrics. This is a crucial step in prompt lifecycle.
Defining Prompt Effectiveness
- Clarity: The prompt should be unambiguous and easily understood by the model.
- Specificity: It should provide enough detail to guide the model toward the desired response.
- Relevance: The prompt must be pertinent to the intended topic or task.
- Conciseness: While being specific, the prompt should avoid unnecessary verbosity.
- Alignment with Goals: It should steer the model to produce outputs that meet the intended objectives, whether informational, creative, or functional.
Evaluation Criteria
(a) Relevance
- Definition: The degree to which the response addresses the prompt’s intent
- Assessment: Determine if the output stays on topic and fulfills the request made in the prompt.
(b) Accuracy
- Definition: Correctness of the information provided in the response.
- Assessment: Verify factual statements and ensure that the response does not contain errors or misconceptions.
(c) Completeness
- Definition: The extent to which the response covers all aspects of the prompt.
- Assessment: Check if the answer fully addresses all components or questions posed in the prompt.
(d) Clarity and Coherence
- Definition: How clearly and logically the response is articulated.
- Assessment: Evaluate the readability, logical flow, and organization of the content.
(e) Creativity and Originality
- Definition: The model’s ability to generate novel and inventive responses.
- Assessment: Assess the uniqueness and imaginative quality of the output, especially for creative tasks.
(f) Compliance with Constraints
- Definition: Adherence to specified guidelines, such as format, length, or style.
- Assessment: Ensure that the response meets any predefined structural or stylistic requirements.
(g) Safety and Appropriateness
- Definition: The absence of harmful, biased, or inappropriate content.
- Assessment: Review responses for compliance with ethical standards and safety guidelines.
Evaluation Methods
(a) Human Evaluation
i. Qualitative Analysis
- Description: Subjective assessment by human reviewers based on predefined criteria.
- Advantages: Offers nuanced insights into relevance, creativity, and appropriateness.
- Implementation: Single or multiple reviewers with clear evaluation rubrics.
ii. Rating Systems
- Description: Assigning numerical scores or categorical labels (e.g., Excellent, Good, Fair, Poor) to responses based on predefined criteria.
- Advantages: Facilitates comparative analysis and statistical evaluation.
- Implementation: Develop a scoring rubric and train reviewers for consistency.
iii. Comparative Assessments
- Description: Presenting multiple responses generated by different prompts for side-by-side comparison.
- Advantages: Enables direct comparison to identify effective prompts.
- Implementation: Use paired comparisons or ranking systems. Ensure that responses are anonymized to avoid reviewer bias.
(b) Automated Metrics
i. Content Overlap Metrics
- Examples: BLEU, ROUGE, METEOR.
- Description: Measure the similarity between the generated response and reference answers.
- Advantages: Objective and scalable for large datasets.
- Limitations: May not fully capture relevance or creativity.
ii. Perplexity
- Description: Measures how well a probability model predicts a sample.
- Advantages: Lower perplexity indicates higher confidence and fluency.
- Limitations: Does not directly assess relevance or factual accuracy.
iii. Semantic Similarity
- Examples: BERTScore, Universal Sentence Encoder (USE).
- Description: Evaluates the semantic similarity between generated responses and reference texts.
- Advantages: Better captures meaning and relevance.
- Limitations: Still relies on having reference texts and may not account for all valid variations in responses.
(c) A/B Testing
- Description: Comparing different prompts by deploying them to user segments and measuring performance based on user interactions or predefined metrics.
- Advantages: Provides real-world effectiveness data and accounts for user preferences.
- Implementation: Define success metrics (e.g., user satisfaction, engagement rates) and randomly assign prompts to user groups.
(d) User Feedback and Interaction Analysis
i. Surveys and Questionnaires
- Description: Collecting direct feedback from users regarding the usefulness and satisfaction of responses.
- Advantages: Provides insights into user perceptions and experiences.
- Implementation: Design targeted questions and ensure anonymity for honest feedback.
ii. Behavioral Metrics
- Description: Analyzing user interactions with responses to infer quality and relevance.
- Advantages: Reflects actual user behavior and preferences.
- Limitations: Indirect measures that may require careful interpretation.
- Implementation: Monitor click-through rates, time spent on response, and follow-up actions.
(e) Robustness and Consistency Testing
- Description: Assessing how consistently a prompt elicits desired responses across different contexts and variations.
- Advantages: Ensures reliability and predictability of the model’s behavior.
- Implementation: Vary input contexts systematically and test against adversarial or edge-case inputs.
Best Practices for Evaluating Prompt Effectiveness
(a) Establish Clear Objectives
- Action: Define what you aim to achieve with the prompt—be it information retrieval, creative generation, or task automation.
- Benefit: Guides the selection of appropriate evaluation criteria and methods.
(b) Develop Comprehensive Evaluation Rubrics
- Action: Create detailed rubrics that outline the criteria and standards for assessing responses.
- Benefit: Ensures consistency and objectivity in evaluations, especially when involving multiple reviewers.
(c) Incorporate Multiple Evaluation Methods
- Action: Use a combination of human evaluation, automated metrics, and user feedback.
- Benefit: Provides a holistic assessment, balancing objective measures with subjective insights.
(d) Iterate and Refine Prompts
- Action: Use evaluation results to iteratively modify and improve prompts.
- Benefit: Enhances prompt effectiveness through continuous optimization based on feedback and performance data.
(e) Ensure Representative Sampling
- Action: Evaluate prompts across diverse scenarios, topics, and user demographics.
- Benefit: Validates that prompts perform well under various conditions and for different user groups.
(f) Maintain Transparency and Documentation
- Action: Document evaluation processes, criteria, and outcomes comprehensively.
- Benefit: Facilitates reproducibility, accountability, and informed decision-making for future prompt refinements.
Common Challenges in Evaluating Prompt Effectiveness
(a) Subjectivity in Human Evaluation
- Issue: Human judgments can be influenced by personal biases and interpretations.
- Mitigation:
- Use multiple reviewers and aggregate their assessments.
- Provide clear and detailed evaluation guidelines to minimize individual discrepancies.
(b) Scalability of Evaluation Processes
- Issue: Manual evaluations, especially human assessments, can be time-consuming and resource-intensive.
- Mitigation:
- Combine automated metrics with targeted human evaluations for larger datasets.
- Implement sampling strategies to evaluate representative subsets.
(c) Defining Appropriate Reference Responses
- Issue: Particularly in creative or open-ended tasks, establishing reference answers is challenging.
- Mitigation:
- Allow for multiple valid responses and use semantic similarity metrics.
- Employ expert consensus or use diverse reference sets to capture variability.
(d) Balancing Specificity and Flexibility in Prompts
- Issue: Highly specific prompts may limit creativity, while vague prompts may lead to irrelevant responses.
- Mitigation:
- Experiment with varying levels of specificity and assess their impact on response quality.
- Align prompt specificity with the desired balance between creativity and accuracy.
(e) Measuring Subjective Qualities
- Issue: Attributes like creativity, engagement, or empathy are inherently subjective and difficult to quantify.
- Mitigation:
- Develop qualitative descriptors and training for evaluators to assess these qualities more consistently.
- Use proxy metrics that can indirectly capture these subjective attributes.
Tools and Frameworks for Prompt Evaluation
(a) Human-Centric Tools
- Platforms: Amazon Mechanical Turk, Prolific, or in-house annotation tools.
- Features: Enable scalable collection of human judgments, support for custom evaluation interfaces, and integration with evaluation workflows.
(b) Automated Evaluation Tools
- Libraries: Hugging Face’s
evaluatelibrary, ROUGE, BLEU, BERTScore. - Features: Facilitate the calculation of various automated metrics, integration with model outputs, and support for batch processing.
(c) A/B Testing Platforms
- Platforms: Optimizely, Google Optimize, custom-built A/B testing frameworks.
- Features: Allow for deploying different prompt variations to user segments, tracking performance metrics, and analyzing comparative results.
(d) Visualization and Analysis Tools
- Platforms: Tableau, Grafana, Python’s Matplotlib and Seaborn libraries.
- Features: Help visualize evaluation metrics, identify trends, and communicate findings effectively to stakeholders.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!