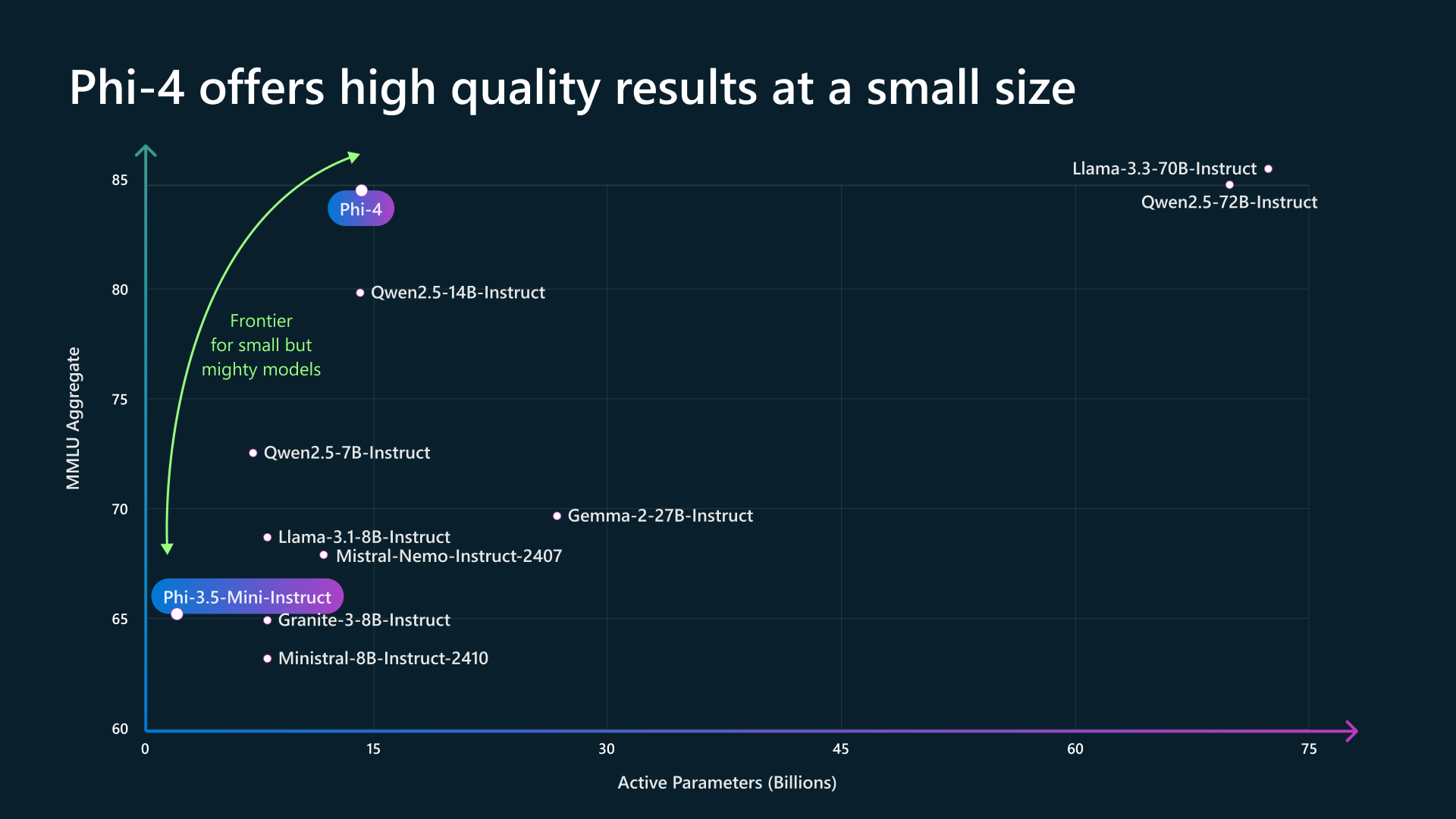
Microsoft has released Phi-4, designed to excel in mathematical reasoning and complex problem-solving. Phi-4, with only 14 billion parameters, demonstrates the increasing potential of SLMs in areas typically dominated by larger models.
Key Features
- Focus on Complex Reasoning: Phi-4 is specifically designed to excel in complex reasoning tasks, with a particular emphasis on mathematical problem-solving. This focus is evident in its impressive performance on challenging math competitions like the AMC 10/12, where it surpasses even larger models.
- Small Size and Efficiency: Despite its high performance, Phi-4 is a relatively small model (14 billion parameters), making it more efficient and accessible compared to larger language models.
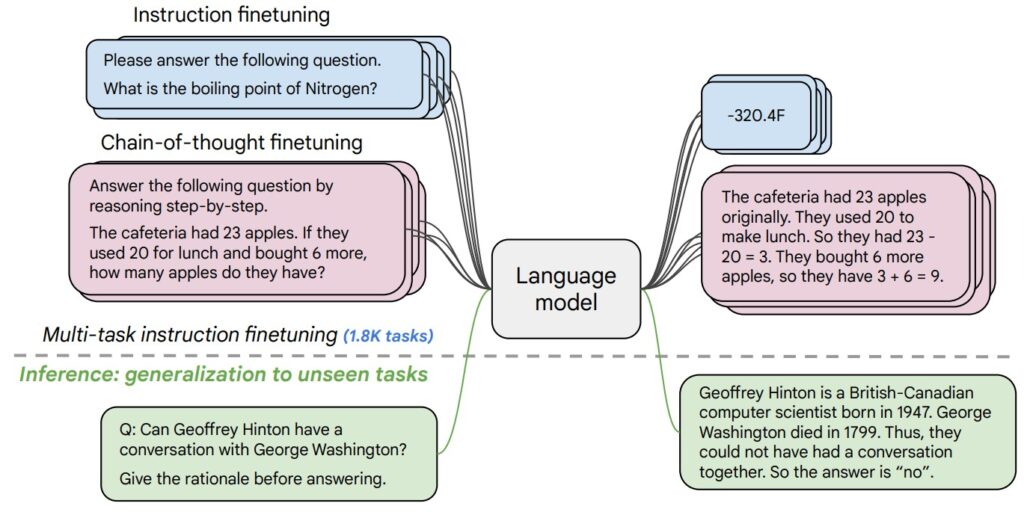
- Synthetic Data-Driven Training: Phi-4’s training heavily utilizes synthetic datasets crafted with methods like multi-agent prompting, instruction reversal, and self-revision workflows, providing structured, diverse, and reasoning-intensive content.
- Post-Training Enhancements: Phi-4 incorporates post-training techniques like Direct Preference Optimization (DPO) powered by pivotal token search. DPO refines critical tokens in the model’s output that significantly influence reasoning outcomes, leading to improved accuracy in tasks like STEM question answering.
- Strong Benchmark Performance: Phi-4 outperforms comparable and even larger models on various benchmarks, including math competitions and academic datasets.
- Responsible AI Principles: Microsoft emphasizes the importance of responsible AI development. Phi-4 incorporates various safety measures and content filtering capabilities to mitigate potential risks associated with language models.
These include Azure AI Content Safety features like prompt shields, protected material detection, and groundedness detection. Rigorous decontamination processes and the use of freshly collected benchmarks are also implemented to ensure fair and reliable performance.
Architectural Efficiency and Usage
Phi-4 employs a decoder-only transformer architecture with an initial context length of 4k, expanded to 16k during midtraining adjustments. The model was trained on 10 trillion tokens, using linear warm-up and decay learning schedules.
Phi-4 uses the tiktoken tokenizer, known for its improved multilingual support compared to previous tokenizers. This enables the model to better handle text in multiple languages, broadening its potential applications.
Given the nature of its training data, Phi-4 is best suited for prompts in the chat format. For instance:
<|im_start|>system<|im_sep|> You are a medieval knight and must provide explanations to modern people.<|im_end|>
<|im_start|>user<|im_sep|> How should I explain the Internet?<|im_end|>
<|im_start|>assistant<|im_sep|>Training Methodology: A Focus on Synthetic Data
Phi-4’s success stems from its unique training approach, heavily reliant on synthetic data. Unlike its predecessors that primarily utilized organic data from web content and code, Phi-4 leverages synthetic datasets created using techniques like multi-agent prompting, instruction reversal, and self-revision workflows.
These datasets provide structured, diverse, and reasoning-intensive content, specifically designed to bolster the model’s complex problem-solving abilities. Synthetic data comprises 40% of Phi-4’s training mix, supplemented by meticulously filtered organic data such as licensed books, academic papers, and high-quality programming repositories.
Post-Training Innovations: Direct Preference Optimization
Phi-4 incorporates several post-training advancements, including Direct Preference Optimization (DPO) powered by pivotal token search. This technique identifies and refines critical tokens in the model’s output that significantly impact reasoning outcomes.
By optimising these “pivotal tokens”, Phi-4 achieves higher accuracy in reasoning-heavy tasks like STEM question answering. Furthermore, the model includes robust safeguards against overfitting and data contamination, ensuring that performance improvements reflect genuine generalisation.
Benchmark Performance: Outperforming Larger Models
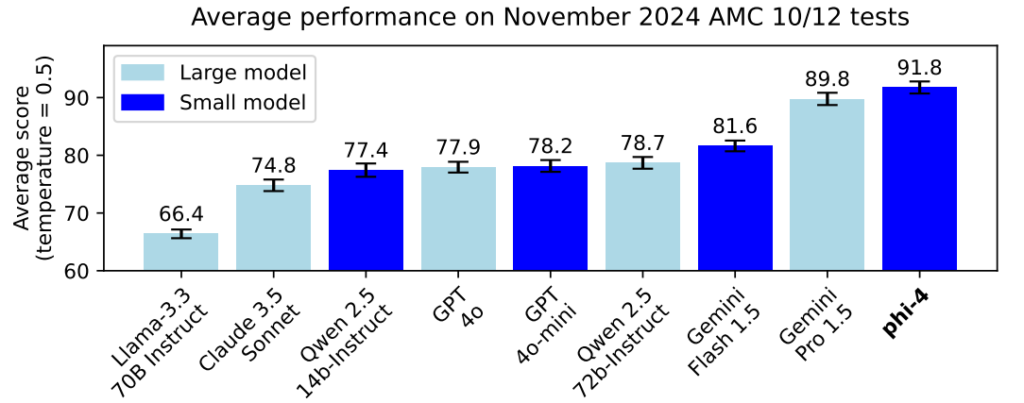
Phi-4 showcases exceptional performance across various benchmarks, even surpassing much larger models. On the November 2024 AMC 10/12 math tests, Phi-4 achieved an average score of 91.8, outperforming competitors like Gemini Pro 1.5 and Qwen 2.5 (72B-Instruct). Additionally, Phi-4 excels on benchmarks such as MATH (80.4), GPQA (56.1 for graduate-level STEM Q&A), and HumanEval (82.6 for coding tasks), highlighting its versatile capabilities.
The model’s balanced data mixture, optimised training curriculum, and effective post-training have allowed it to achieve top-tier performance with significantly lower computational costs, bridging the gap between small and large language models.
Responsible AI Considerations
Potential limitations and ethical considerations associated with Phi-4 include:
- Quality of Service: The model is primarily trained on English text and might not perform as well with other languages.
- Representation of Harms & Perpetuation of Stereotypes: The model could potentially over- or under-represent certain groups of people or reinforce negative stereotypes.
- Inappropriate or Offensive Content: The model may generate inappropriate or offensive content and may require additional mitigations for sensitive contexts.
- Information Reliability: The model could generate inaccurate or outdated information.
Overall, Phi-4 is a promising step forward in the development of SLMs. Its ability to perform complex reasoning tasks opens up exciting new possibilities for AI applications.
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!