The exponential growth of data in diverse formats—text, images, video, audio, and more—has necessitated the development of AI models capable of seamlessly processing and understanding multiple data modalities simultaneously. By integrating various data types, Multi-modal Transformers enable richer and more contextually aware AI systems, unlocking a plethora of applications across numerous domains.
Background: The Evolution of Transformer Architectures
The Transformer Revolution
The Transformer architecture revolutionized NLP with its novel use of self-attention mechanisms. Transformers process input data in parallel, enabling efficient training on large datasets. This shift enabled models to handle long-range dependencies and scale efficiently with data and computational resources.
From Single to Multiple Modalities
Originally designed for text-based tasks, transformers have been adapted to various other domains, including computer vision and audio. The adaptability of the transformer architecture facilitates its extension to multi-modal scenarios, where different types of data are processed in a unified framework.
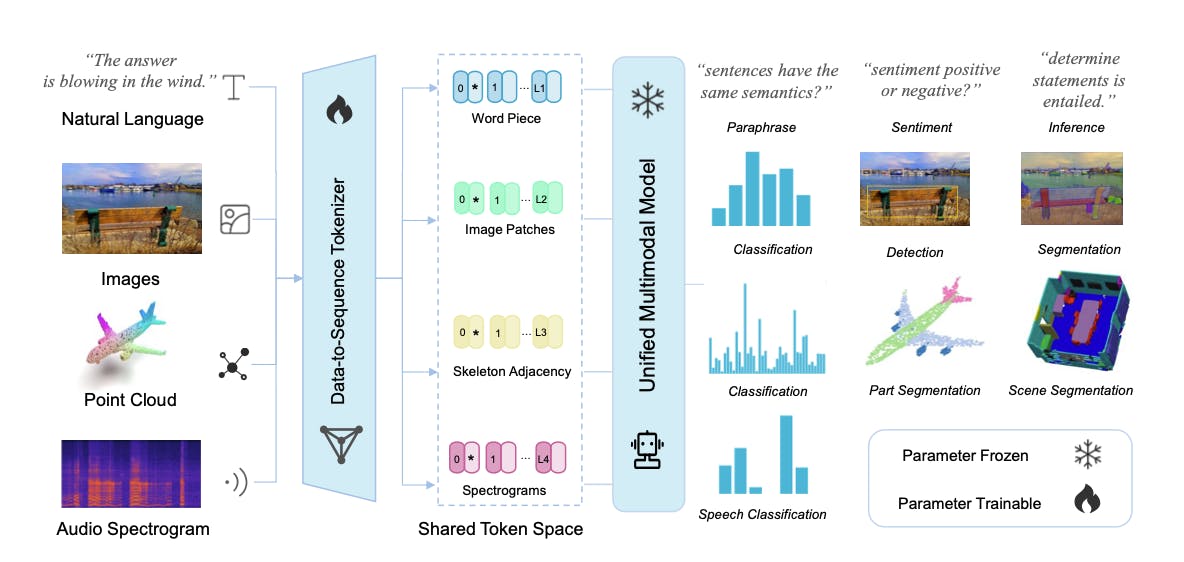
Meta-Transformer: A Unified Framework for Multimodal Learning
Foundations of Multi-modal Transformers
Key Components
Multi-modal Transformers build upon the core principles of standard Transformer architectures but incorporate additional mechanisms to handle diverse data types. The primary components include:
- Input Representation: Each modality is represented in a form suitable for processing by the transformer. For example, images might be divided into patches and linearly embedded, while text is tokenized and embedded similarly to traditional NLP models.
- Modality-specific Encoders: Separate encoders process each modality (e.g., text, images, video), extracting features unique to the data type. These encoders are often transformer-based.
- Fusion Layers: These layers integrate the representations from different modalities.
- Cross-modal Attention Mechanisms: To capture interdependencies between modalities, cross-modal attention layers allow one modality to attend to features from another, facilitating enriched representations.
- Unified or Task-specific Decoders: After fusion, a decoder processes the integrated information to perform the desired task, whether it’s classification, generation, or retrieval.

Cross modal Attention for Two Sequences from Distinct Modalities
Fusion Strategies
Effective integration of multiple modalities is crucial for the success of Multi-modal Transformers. The three primary fusion strategies include:
- Early Fusion: Combines raw data from different modalities before any significant processing. This approach can be simple but may struggle with aligning disparate data types effectively.
- Mid-level Fusion: Integrates features extracted from each modality at intermediate processing stages. This method balances complexity and alignment efficiency, allowing for richer interactions between modalities.
- Late Fusion: Merges high-level representations obtained after individual processing. While straightforward and scalable, it may miss finer inter-modal interactions.
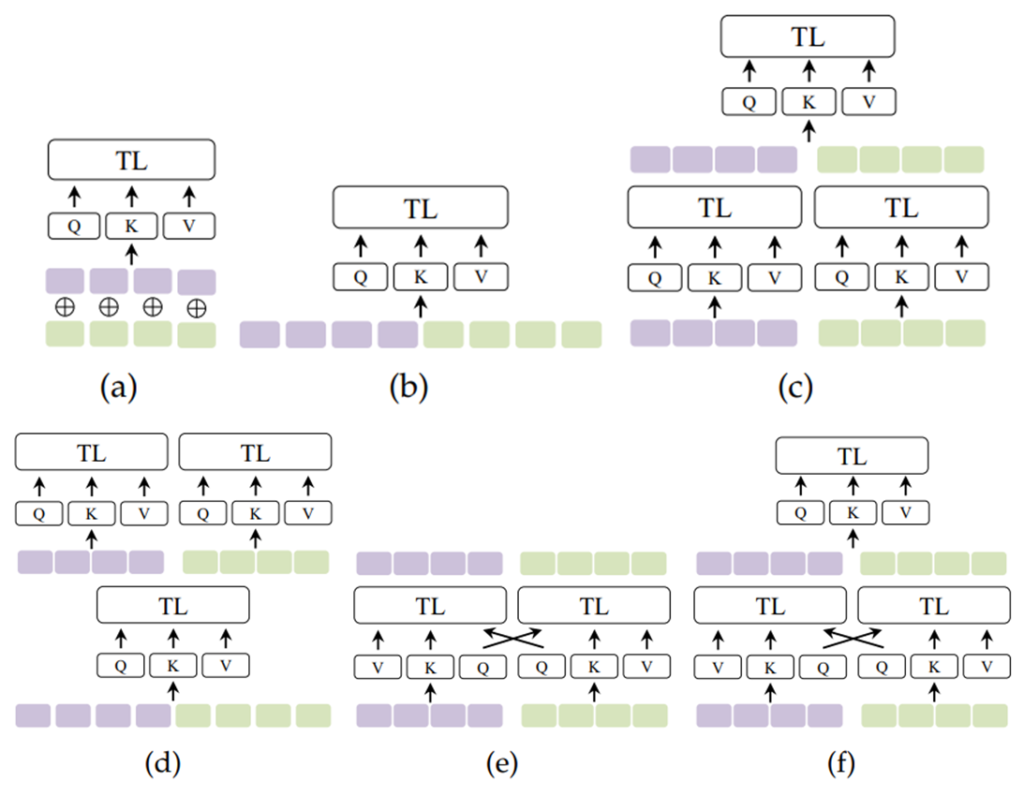
Hybrid fusion strategies, which combine elements from multiple approaches, are also commonly employed to leverage the strengths of each method.
Training Paradigms
Multi-modal Transformers can be trained using various paradigms, including:
- Supervised Learning: Requires labeled multi-modal datasets where corresponding data across modalities are annotated for specific tasks.
- Self-supervised Learning: Utilizes inherent structures or relationships within the data, such as predicting one modality from another, reducing the reliance on labeled data.
- Contrastive Learning: Encourages the model to align representations of corresponding multi-modal data while distancing non-corresponding pairs, enhancing cross-modal alignment without explicit labels.
Prominent Multi-modal Transformer Models
CLIP (Contrastive Language–Image Pre-training)
Developed by: OpenAI, 2021
Overview: CLIP revolutionized the field by demonstrating that large-scale pre-training on image-text pairs enables powerful zero-shot image classification and retrieval capabilities. By aligning image and text embeddings in a shared space using contrastive learning, CLIP can understand and relate visual and textual information without task-specific fine-tuning.
Key Features:
- Utilizes a Vision Transformer (ViT) for image encoding and a Transformer-based text encoder.
- Trained on 400 million image-text pairs sourced from the internet.
- Capable of performing zero-shot classification by matching images with textual descriptions.
Applications:
- Image classification without labeled training data.
- Text-based image retrieval.
- Foundation for generative models like DALL-E.
VisualBERT and ViLBERT
Developed by: Various research groups, 2019-2020
Overview: Both VisualBERT and ViLBERT extend BERT, a pure text-based Transformer, to handle vision-language tasks by integrating image features with textual representations.
Key Features:
- VisualBERT: Incorporates image region features extracted from pre-trained object detectors directly into the BERT architecture.
- ViLBERT: Utilizes dual-stream Transformers, processing text and image features separately before performing cross-modal interactions.
Applications:
- Visual Question Answering (VQA).
- Image captioning.
- Visual reasoning tasks.
VideoBERT
Developed by: Google Research, 2019
Overview: VideoBERT extends the BERT architecture to model video data alongside associated text (such as transcripts or captions). It aims to learn joint representations of video and language, facilitating tasks that require understanding both temporal and semantic information.
Key Features:
- Processes video frames and corresponding text in a unified Transformer framework.
- Employs a discrete variational autoencoder to tokenize visual data into “visual words.”
- Leverages self-supervised objectives for pre-training.
Applications:
- Video captioning.
- Video-based question answering.
- Action recognition.
MURAL (Multi-modal Representation Learning)
Developed by: Various research groups, 2021
Overview: MURAL aims to learn universal representations from multiple modalities, including text, images, and audio. It emphasizes the versatility of the Transformer architecture in capturing rich, cross-modal relationships.
Key Features:
- Integrates multiple data types within a single Transformer-based model.
- Utilizes advanced fusion techniques to handle diverse inputs.
- Trained on extensive multi-modal datasets to ensure broad applicability.
Applications:
- Multimedia content analysis.
- Cross-modal generation tasks.
- Unified AI systems for diverse applications.
Florence
Developed by: Microsoft Research, 2022
Overview: Florence is a large-scale multi-modal model designed to unify vision and language understanding. It emphasizes scalability and efficiency, aiming to set new benchmarks in multi-modal tasks.
Key Features:
- Employs a dual-encoder architecture for images and text.
- Trained on a vast dataset comprising billions of image-text pairs.
- Integrates advanced optimization techniques to enhance training efficiency.
Applications:
- Image-text retrieval.
- Zero-shot image classification.
- Cross-modal understanding tasks.
Applications of Multi-modal Transformers
- Enhanced Search and Retrieval
- Cross-modal Search: Users can perform searches using one modality to retrieve information in another. For instance, searching for images using textual descriptions or finding relevant texts based on an input image.
- Content-based Image Retrieval (CBIR): Enables efficient retrieval of images from large databases based on content rather than metadata, leveraging visual and textual embeddings.
- AI-driven Content Creation
- Image and Video Generation: Models like DALL-E, built upon multi-modal Transformers, can generate images from textual descriptions, facilitating creative applications in art, design, and entertainment.
- Automated Video Editing: AI can assist in editing videos by understanding content through multi-modal inputs, streamlining tasks like scene selection and annotation.
- Text-to-Video Synthesis: Generating video content based on textual narratives, enhancing storytelling and media production.
- Healthcare and Medical Diagnostics
- Medical Imaging Analysis: Combining imaging data (e.g., MRI, CT scans) with patient records (textual data) to improve diagnostic accuracy and treatment planning.
- Clinical Decision Support: Integrating diverse data sources to provide comprehensive insights, aiding healthcare professionals in making informed decisions.
- Telemedicine: Enhancing remote diagnosis and patient monitoring by processing multi-modal data, including video consultations and real-time health metrics.
- Autonomous Systems and Robotics
- Self-driving Vehicles: Utilizing multi-modal inputs from cameras, LIDAR, radar, and textual data to navigate and make real-time decisions.
- Robotic Perception and Interaction: Enabling robots to understand and interact with their environment through a combination of visual, auditory, and textual inputs.
- Drones and Aerial Systems: Processing video feeds, sensor data, and navigation instructions for tasks like surveillance, delivery, and environmental monitoring.
- Multimedia Analysis and Understanding
- Video Summarization: Automatically creating concise summaries of long videos by understanding visual and textual content.
- Sentiment Analysis in Multimedia: Analyzing sentiments expressed in videos by combining facial expressions, speech, and contextual information.
- Content Moderation: Detecting inappropriate content by processing multiple modalities, ensuring more accurate and context-aware moderation.
- Education and Personalized Learning
- Interactive Educational Tools: Creating AI tutors that can understand and respond to user inputs across text, speech, and visual interactions, providing a more engaging learning experience.
- Personalized Content Delivery: Tailoring educational materials based on multi-modal assessments of student performance and preferences.
- Environmental Monitoring: Integrating diverse data sources like satellite imagery, sensor data, and textual reports for comprehensive environmental analysis and decision-making.
- Cultural Heritage Preservation: Combining textual descriptions, images, and 3D scans to digitally preserve and interpret cultural artifacts and heritage sites.
- Smart Cities: Utilizing multi-modal data from various urban sensors to enhance city planning, traffic management, and public safety.
Limitations
- Data Alignment and Representation
- Heterogeneity of Data: Different modalities possess distinct structures and characteristics, making it difficult to align and represent them cohesively within a unified framework.
- Synchronization Issues: Temporal synchronization between modalities (e.g., aligning spoken words with corresponding video frames) is non-trivial and essential for coherent representation learning.
- Computational Complexity and Scalability
- Resource Intensiveness: Processing multiple high-dimensional data types demands significant computational resources, including memory and processing power.
- Scalability: As the number of modalities increases, the complexity of model architectures and training algorithms scales exponentially, posing challenges for real-world applications.
- Data Quality and Availability
- Limited Multi-modal Datasets: High-quality, large-scale multi-modal datasets are scarce, often necessitating costly and time-consuming data collection and annotation processes.
- Data Noise and Variability: Inconsistent or noisy data across modalities can degrade model performance and complicate training procedures.
- Bias and Fairness Across Modalities
- Cross-modal Biases: Biases present in one modality (e.g., biased training data in images) can propagate to others, leading to unfair or discriminatory outcomes.
- Representation Fairness: Ensuring that multi-modal models fairly represent and interpret diverse data sources is critical, especially in sensitive applications like healthcare and law enforcement.
- Interpretability and Explainability
- Opaque Decision-making: The complex interplay between modalities can make it challenging to interpret how models arrive at specific decisions
- Transparency Across Modalities: Understanding the contribution of each modality to the final representation and decision is essential for trust and accountability.
Closing Remarks
Multi-modal Transformers represent a significant leap forward in artificial intelligence, enabling the integration and understanding of diverse data types such as text, images, and video within a unified framework. While challenges related to data alignment, computational demands, and fairness persist, ongoing research and innovation continue to push the boundaries of what multi-modal AI can achieve.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!