ModernBERT emerges as a groundbreaking successor to the iconic BERT model, marking a significant leap forward in the domain of encoder-only models for NLP. Since BERT’s inception in 2018, encoder-only models are used in countless NLP pipelines due to their compact size and robust performance in tasks like retrieval and classification. However, the NLP landscape has evolved, demanding models capable of handling longer sequences, exhibiting higher efficiency, and adapting to modern applications like Retrieval Augmented Generation (RAG) and tasks involving code.
Why ModernBERT?
ModernBERT was created to address the shortcomings of older NLP models and meet the changing demands of natural language processing.
Problems with earlier models like BERT:
- Restricted Input Size: BERT and similar models could only handle text chunks of a maximum of 512 tokens, which limited their effectiveness in in long-context tasks like document retrieval and summarization.
- Suboptimal Model Design: The way these models were structured, with absolute positional embeddings and bias terms, resulted in less than ideal performance and slower processing speeds.
- Limited Training Information: These models were trained on smaller, older datasets that often lacked representation from important areas like computer code and up-to-date information.
New demands in NLP:
- Applications involving lengthy texts: Tasks like RAG, which combines information retrieval with text generation, require models capable of processing and using information from very long pieces of text.
- Tasks using combined data types: Current applications often work with both text and code, requiring models that can handle both types of data effectively.
- The need for speed: Real-world applications require models that can make predictions quickly and use memory efficiently so they can be used on a variety of hardware.
ModernBERT directly addresses these issues through architectural innovations, data scaling, and efficiency enhancements.
Key Innovations in ModernBERT
- Modernized Transformer Architecture: ModernBERT integrates modern transformer architecture features:
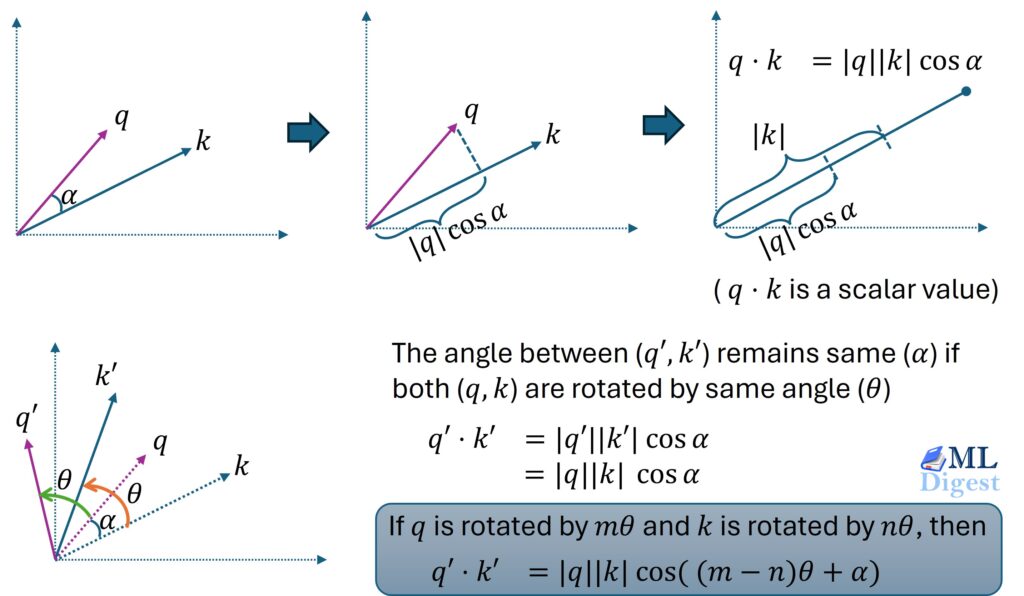
- Rotary Positional Embeddings (RoPE): ModernBERT replaces traditional positional encoding with RoPE, which enhances the model’s understanding of word positioning and allows for longer sequence lengths.
- GeGLU Layers: ModernBERT utilizes GeGLU layers, refining BERT’s GeLU activation function for enhanced performance.
- Streamlined Architecture: The removal of unnecessary bias terms allows for a more effective use of the parameter budget.
- Additional Normalization Layer: An extra normalization layer after embeddings contributes to training stabilization.
- FlexBERT: A modular approach to encoder building blocks, further enhancing architectural flexibility and adaptability.
- Extended Context Handling (8192-Token Sequence Length): A substantial increase from BERT’s 512 tokens, enabling the model to handle much longer documents or datasets. This is a significant advantage for applications like full-document retrieval and large-scale code analysis.
- Modern Data Scales & Sources:
- Massive Dataset: Trained on 2 trillion tokens from a diverse range of sources, including web documents, code, and scientific articles. This diverse data exposure allows ModernBERT to excel in tasks that require specialized knowledge, such as code retrieval and technical document comprehension.
- Updated Tokenizer: Utilizes a modern Byte-Pair Encoding (BPE) tokenizer, optimized for handling both natural language and programming tasks.
- Enhanced Efficiency:
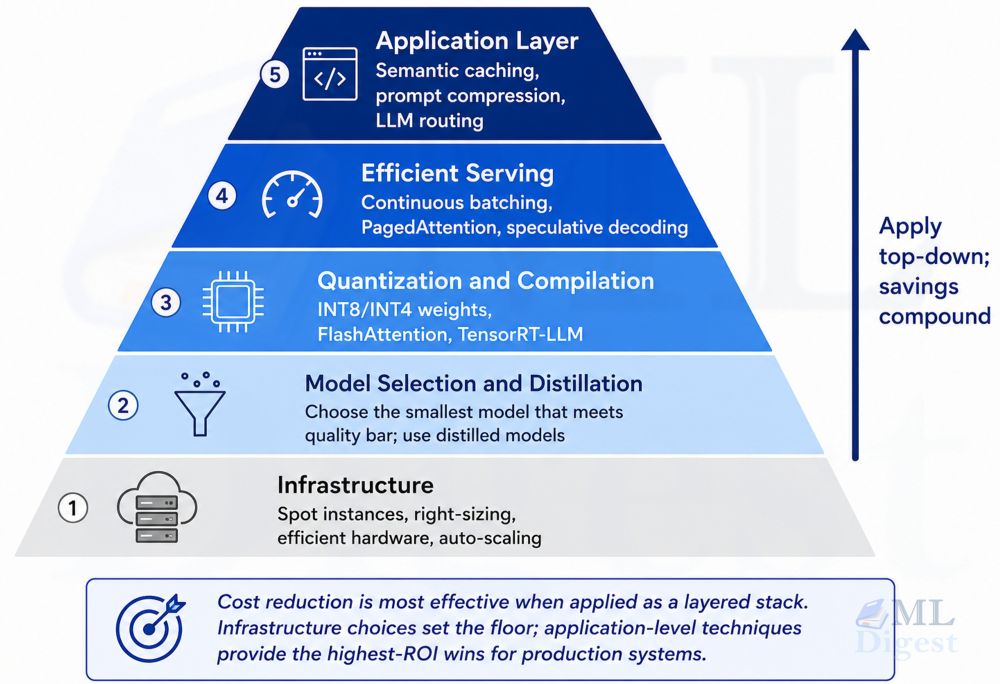
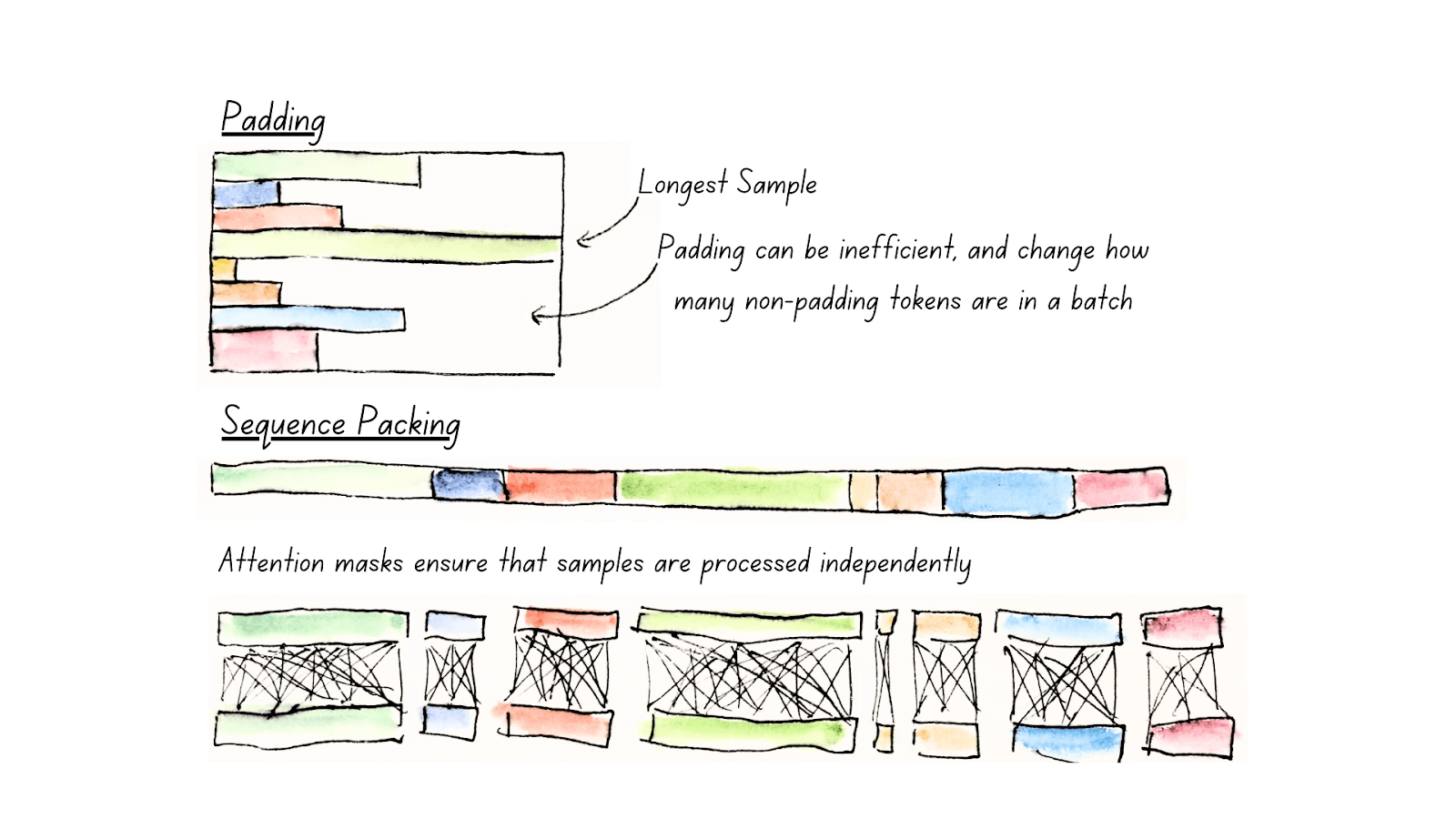
- Flash Attention and Unpadding: ModernBERT employs Flash Attention 2 and unpadding techniques to accelerate training and inference. Flash Attention 2, a highly efficient attention mechanism, minimizes the computational cost of processing long sequences. Unpadding removes unnecessary padding tokens during computation, optimizing memory usage and accelerating operations.
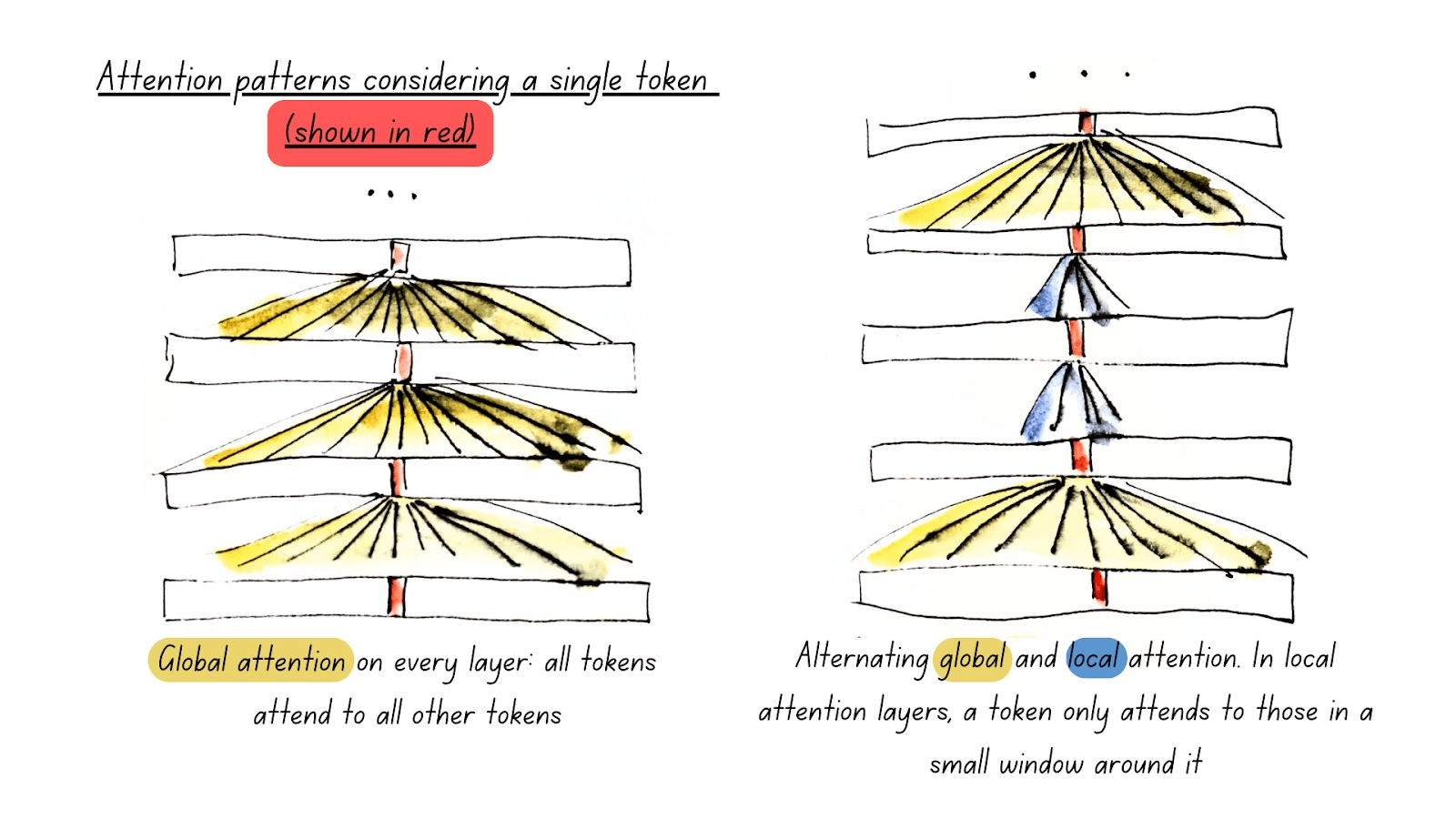
- Alternating Attention: ModernBERT utilizes a strategy of alternating global and local attention, similar to how a person reads. Every third layer employs full global attention, while the remaining layers focus on a local sliding window of 128 tokens. This approach effectively balances performance and efficiency.
- Hardware-Aware Model Design: ModernBERT is designed with hardware efficiency in mind, ensuring optimal execution across various GPUs.
Training ModernBERT
ModernBERT’s training process is designed to maximize its understanding of both natural language and code. The training involves three phases:
- Initial Training: The model is trained on a sequence length of 1024 tokens, progressively increasing the batch size to enhance efficiency.
- Context Length Extension: The sequence length is extended to 8192 tokens, further exposing the model to longer contexts and improving its ability to handle long documents.
- Fine-Tuning: The model can be fine-tuned for specific downstream tasks using standard BERT fine-tuning methods.
ModernBERT comes in base and large sizes. The base model has 22 layers and 149 million parameters, while the large model has 28 layers and 395 million parameters. The base model has a hidden size of 768 and a GLU expansion of 2,304. The large model has a hidden size of 1,024 and a GLU expansion of 5,248.
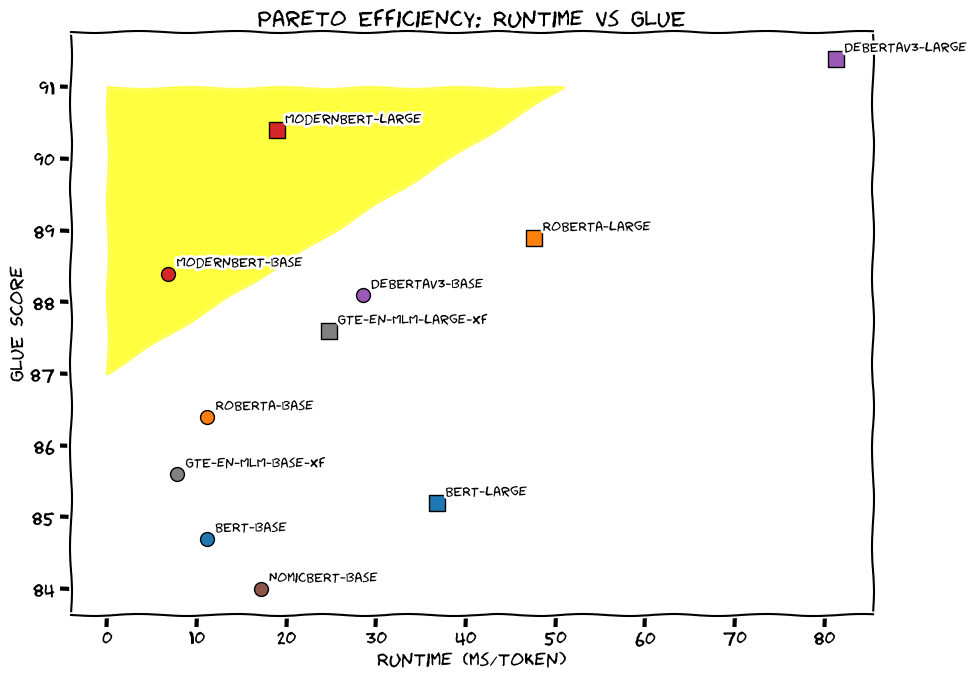
ModernBERT Performance & Efficiency
ModernBERT consistently outperforms its predecessors in a wide range of NLP tasks, including:
- Natural Language Understanding (NLU):
- GLUE Benchmark: ModernBERT-base surpasses all existing base models on the GLUE benchmark, including DeBERTaV3-base. ModernBERT-large is the second-best large encoder on GLUE, closely matching DeBERTaV3-large.
- Retrieval:
- Short-Context Retrieval (BEIR Benchmark): ModernBERT outperforms other encoders, including GTE-en-MLM and NomicBERT, in both the DPR (Dense Passage Retrieval) and ColBERT (Contextualized Late Interaction over BERT) settings.
- Long-Context Retrieval (MLDR Benchmark): ModernBERT achieves top performance on the MLDR benchmark, showcasing its effectiveness in handling long documents. ModernBERT-large demonstrates particularly strong performance in the ColBERT setting, significantly surpassing other long-context models.
- Code Retrieval:
- CodeSearchNet and StackQA Benchmarks: ModernBERT excels in code retrieval due to its training on code data, outperforming other models on benchmarks like CodeSearchNet and StackQA. This capability opens new possibilities for AI-powered coding tools and code search engines.
ModernBERT’s efficiency is also noteworthy, demonstrating significant improvements over previous models:
- Speed: ModernBERT processes both short and long context inputs faster than other recent encoders. It is particularly efficient in handling long sequences, processing 8192 tokens considerably faster than previous models.
- Memory Efficiency: ModernBERT exhibits superior memory efficiency, allowing it to utilize larger batch sizes compared to other models. This advantage enables more efficient training and inference, especially on resource-constrained hardware.
Practical Applications of ModernBERT
- Retrieval Augmented Generation (RAG): ModernBERT’s long context handling and efficient processing make it ideal for RAG pipelines, enabling the retrieval and processing of relevant data from large knowledge bases.
- Semantic Search: ModernBERT can be utilized to develop semantic search engines that deliver more accurate and relevant search results by understanding the meaning and context of search queries and documents.
- Code Retrieval: ModernBERT’s superior performance in code retrieval tasks makes it suitable for developing AI-powered IDEs and large-scale code indexing solutions.
- Classification: ModernBERT can be fine-tuned for a variety of classification tasks, including sentiment analysis, topic classification, and spam detection.
- Question Answering: ModernBERT can be implemented in question answering systems to deliver accurate and comprehensive answers.
Limitations and Future Directions
- Language Focus: Currently, ModernBERT is primarily focused on the English language, restricting its applicability to other languages.
- Potential for Data Bias: ModernBERT’s reliance on web data for training may introduce biases inherent in such data.
- Limited Generative Capacity: ModernBERT is primarily trained using the MLM objective, which limits its generative capabilities. While it can suggest tokens to replace masked tokens, it is not designed for generating extensive, coherent text sequences.
- Scaling Exploration: ModernBERT focuses on architecture and data optimization but does not extensively investigate the effects of scaling model parameters.
- Long-Context Adaptation: Although ModernBERT excels in long-context tasks, some benchmarks indicate that its performance might require further fine-tuning for optimal results in domain-specific scenarios.
ModernBERT incorporates several key improvements:
- Extended Context Length: It can process sequences up to 8,192 tokens long, significantly exceeding BERT’s 512 token limit. This allows it to handle much larger documents and datasets.
- Improved Architecture: ModernBERT utilizes Rotary Positional Embeddings (RoPE), GeGLU layers, and a streamlined architecture for enhanced performance and efficiency.
- Flash Attention and Unpadding: These techniques contribute to faster training and inference, especially for long sequences, by optimizing memory usage and reducing computational overhead.
- Alternating Attention: ModernBERT strategically alternates between global and local attention, allowing it to efficiently balance contextual awareness with computational speed.
- Hardware-Aware Model Design: The model is designed for efficient execution on various GPUs commonly used in inference.
- Training on a Massive Dataset: Trained on a 2 trillion token dataset including diverse sources like web documents, scientific papers, and code, enabling it to excel in tasks requiring specialized knowledge.
- State-of-the-art performance: ModernBERT achieves top results across various benchmarks for retrieval, natural language understanding, and code retrieval tasks.
- Efficiency: It is significantly faster and more memory-efficient than many comparable models, making it practical for real-world deployments.
- Long context handling: The extended context length enables applications requiring understanding of longer documents, such as document retrieval and summarization.
- Versatility: ModernBERT excels in various NLP tasks, including classification, retrieval, and code understanding.
ModernBERT employs several techniques for efficient long sequence handling:
- Extended context length: Supports sequences up to 8,192 tokens.
- Rotary Positional Embeddings (RoPE): Enhances positional understanding for long sequences.
- Flash Attention: Improves memory efficiency and speed, particularly for long sequences.
- Unpadding: Removes unnecessary padding tokens, optimizing memory usage and computation.
- Alternating Attention: Balances the need for global contextual awareness with the efficiency of local attention.
Implementing ModernBERT
ModernBERT is readily available through popular NLP libraries like Hugging Face Transformers.
For tasks like masked word prediction, you can use the fill-mask pipeline:
import torch
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
from pprint import pprint
# Specify the desired ModernBERT model
model_id = "answerdotai/ModernBERT-base"
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
pipe = pipeline(
"fill-mask",
model=model_id,
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)ModernBERT can be fine-tuned for specific downstream tasks, such as text classification.
Clsosing Remarks
ModernBERT signifies a substantial advancement in encoder-only model development. It sets a new standard for performance and efficiency, making it a powerful tool for various NLP tasks. Its architectural innovations, large-scale training, and focus on real-world performance position it as a valuable asset for researchers and practitioners alike.
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!