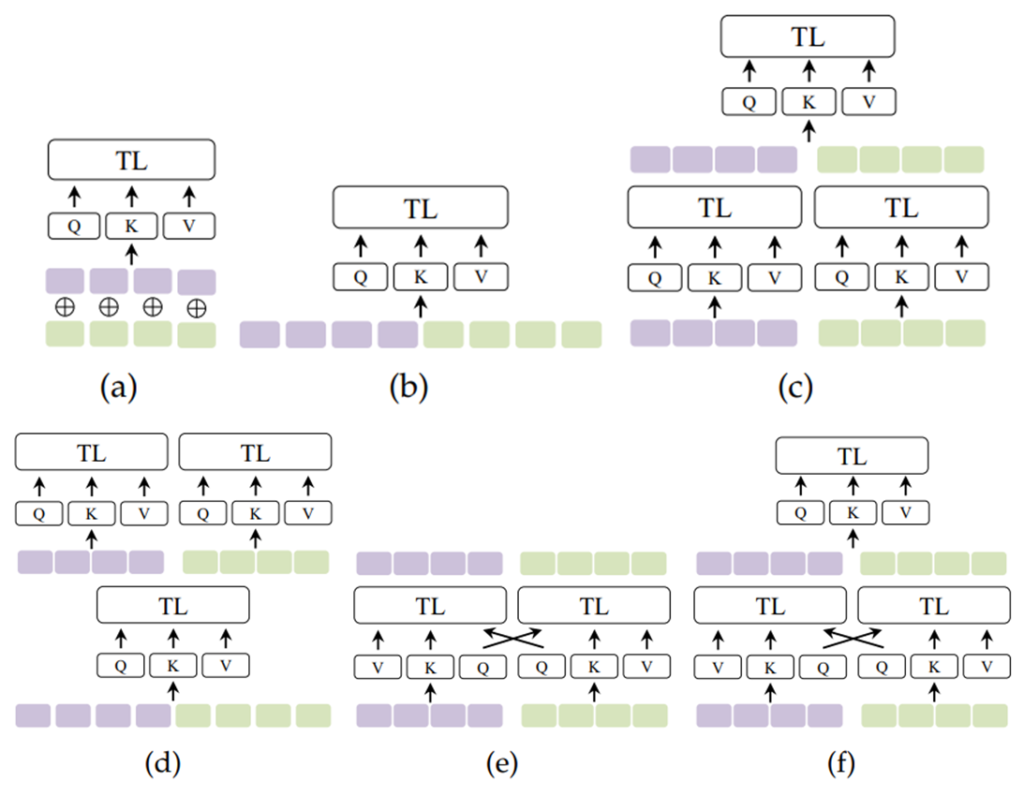
Initially proposed in the seminal paper “Attention is All You Need” by Vaswani et al. in 2017, Transformers have proven to be a game-changer in how we approach tasks in NLP, computer vision, and various other domains. This architecture departs from traditional RNNs and CNNs by leveraging a mechanism called self-attention, enabling it to process sequential data more efficiently and effectively.
This article aims to provide a comprehensive overview of Transformers, their architecture, advantages, and challenges.
Background: Sequence Modeling and Early Architectures
Understanding Transformers requires a grasp of the historical context of sequence modeling in deep learning, primarily focusing on Recurrent Neural Networks (RNNs) and their extensions.
RNNs were among the pioneering architectures designed to process sequential data. They operate by maintaining a hidden state that is updated with each input token. However, RNNs struggle with long-range dependencies due to issues like vanishing and exploding gradients. This shortcoming was addressed by Long Short-Term Memory (LSTM) networks, which introduced memory cells that can retain information over longer sequences.
Limitations of Early Architectures
- Parallelization: Sequence processing is inherently sequential, which prevents effective parallelization during training and slows down performance.
- Vanishing/Exploding Gradients: Training deep RNNs can be challenging due to the vanishing or exploding gradient problem, which hinders the model’s ability to learn long-range dependencies.
- Difficulty Capturing Long-Range Dependencies: While LSTMs improved long-term dependency handling, they still struggled with gathering contextual information from distant tokens.
- Resource Intensiveness: Both RNNs and LSTMs can be computationally expensive, necessitating extensive resource availability for training.
These limitations set the stage for the development of the Transformer architecture.
What is a transformer?
Transformer is a powerful neural network architecture that has revolutionized how machines understand and process human language. Transformers rely on self-attention mechanisms to weigh the significance of different words in a sentence relative to each other. This allows them to capture complex relationships and dependencies in the data, making them highly effective for tasks like machine translation, text summarization, and sentiment analysis.
The versatility of Transformers extends beyond textual data; they have also been adapted for image analysis, audio, and video processing. Their ability to model long-range dependencies and capture contextual information has made them a important milestone in deep learning research.
The Transformer Architecture
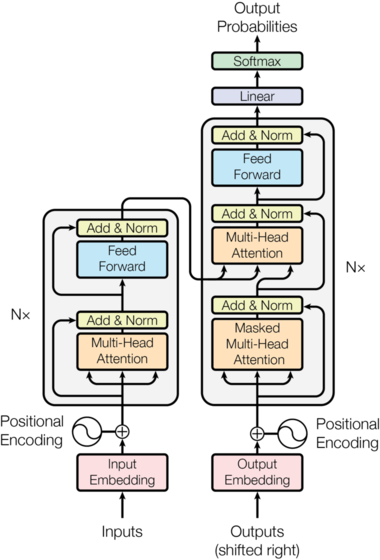
The core components of the transformer are outlined below:
- Encoders and Decoders:
- Encoder: Processes the input sequence and generates a set of continuous representations.
- Decoder: Takes the encoder’s output to generate the target sequence, one element at a time.
- Self-Attention Mechanism:
- This is the crux of the Transformer architecture. It allows the model to weigh the significance of different words in a sentence relative to each other. The self-attention mechanism provides a method to compute a representation of the input sequence by learning the relationships between different words (tokens).
- Multi-Head Self-Attention Mechanism:
- This mechanism allows the model to jointly attend to information from different representation subspaces.
- Instead of performing a single attention function, multiple attention heads are computed in parallel and then concatenated, enabling the model to capture diverse features from the input sequence.
- Positional Encoding:
- Since transformers do not inherently understand the order of the input tokens, positional encodings are added to the input embeddings to incorporate information about the relative or absolute positions of the tokens.
- Feedforward neural networks:
- Following self-attention, feedforward networks apply non-linear transformations to the token representations, allowing the model to learn complex data patterns.
- Stacked layers:
- Transformers employ a layered architecture, where the output of one layer feeds into the next. This stacking of layers enables the model to extract features at different levels of abstraction, capturing hierarchical relationships within the data.
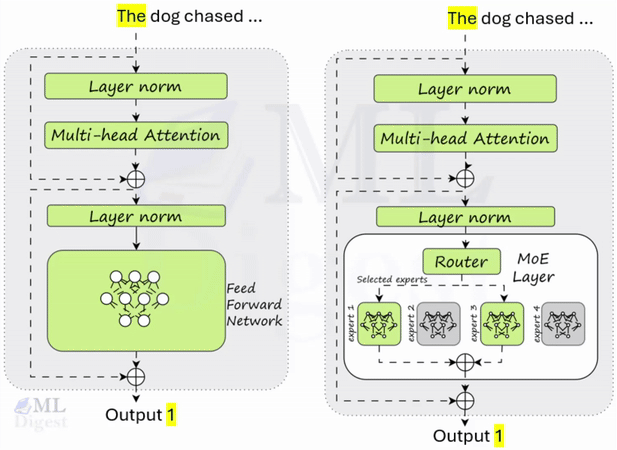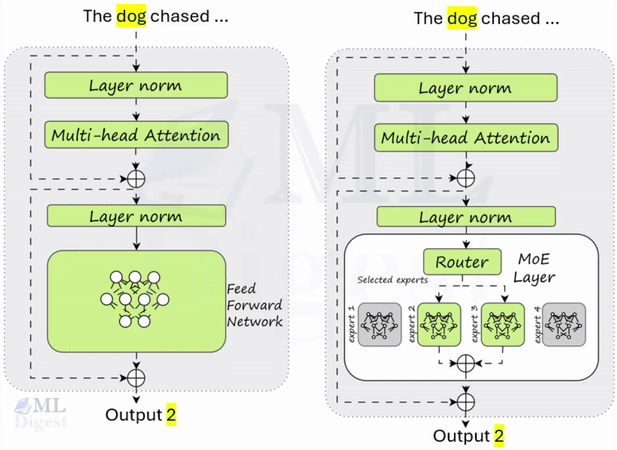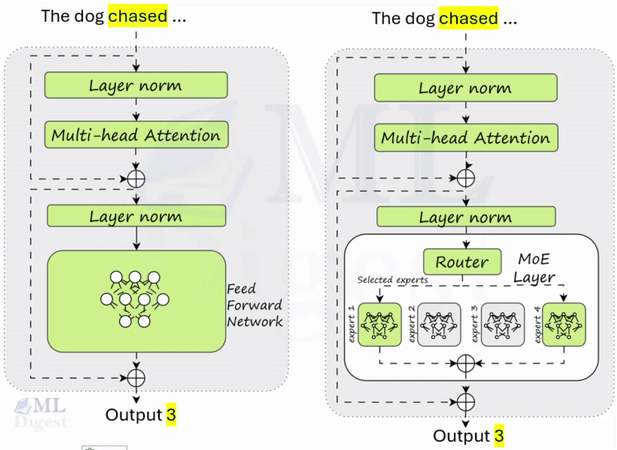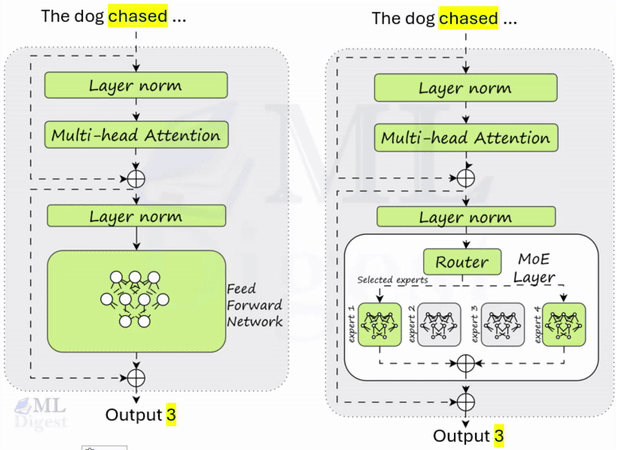
- Layer Normalization and Residual Connections:
- Each sub-layer (like self-attention and feed-forward networks) has a residual connection around it followed by layer normalization.
- Layer normalization is employed to stabilize training, while residual connections help mitigate the vanishing gradient problem by allowing gradients to flow more easily through the network during backpropagation.
In-Depth Mechanism of Transformers
We will focus on the key components of the Transformer architecture that make it a powerful tool for sequence modeling:
1. Self-Attention Mechanism
The self-attention mechanism is the heart of the transformer model. Its primary function is to enable the model to focus on specific parts of the input sequence when making predictions about another part.
Self-attention works through the following steps:
- Input Representation: Each input token is first converted into an embedding vector. Subword segmentation techniques, like Byte Pair Encoding (BPE), are often used to handle out-of-vocabulary words and reduce vocabulary size.
- Transformations: For each input token, three vectors are computed:
- Query (Q): A vector derived from the current word to ask for information.
- Key (K): A vector for each word in the input sequence indicating the attributes that the word can provide as information.
- Value (V): A vector that carries the actual information of the token. These transformations are done through learned linear projections. \[
Q = XW_Q, \quad K = XW_K, \quad V = XW_V
\]
Where \(X\) is the input embedding, and \(W_Q, W_K, W_V\) are learned weights.
- Attention Scores Calculation: The attention score is determined by taking the dot product of the query vector with all key vectors, scaled down by the square root of the dimension of the keys to stabilize gradients for large dimensions. \[
\text{Attention Score} = \frac{QK^T}{\sqrt{d_k}}
\] - Softmax Normalization: These attention scores are passed through a softmax function to yield a distribution (weights), ensuring they sum to 1. This distribution indicates the importance of each token concerning the current one. \[
\alpha = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)
\] - Context Vector Calculation: The output of the self-attention layer is computed by multiplying the softmaxed attention scores with the value vectors. \[
\text{Output} = \alpha V
\]
This step computes a weighted sum of the values where the weights are essentially “how much focus” the model should put on different parts of the sequence for generating the current token’s representation.
2. Multi-Head Attention
To capture diverse aspects of relationships among words, transformers utilize multiple attention heads:
- Instead of calculating a single set of attention scores, multiple sets (heads) are created by projecting the inputs into different subspaces.
- Each attention head computes its output independently.
- The outputs from all attention heads are then concatenated and linearly transformed back to the original embedding size. \[
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h) W^O
\]
Where each \(\text{head}_i\) is computed as:
\[
\text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i)
\]
This multi-head setup allows the model to attend to information from different representation subspaces, enriching its understanding of the context.
3. Positional Encoding
Transformers do not inherently capture the sequential order of input tokens like RNNs. To address this, positional encodings are added to input embeddings. These encodings are sine and cosine functions of different frequencies (Transformer paper by Vaswani et al.), allowing the model to discern order:
\[
\text{PE}_{\text{(pos,2i)}} = \sin\left(\frac{\text{pos}}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
\]
\[
\text{PE}_{\text{(pos,2i+1)}} = \cos\left(\frac{\text{pos}}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
\]
Where \( \text{pos} \) represents the position of the word in the sequence, \(i\) is the dimension index (ranging from 0 to \(d_{\text{model}}/2)\) and \( d_{\text{model}} \) is the dimension of the input embeddings.
Advantages of Transformers
- Parallelization: Unlike RNN architectures, which must process tokens sequentially, Transformers allow for complete parallelization. This feature leads to significant speed-up during training and inference.
- Scalability: The design of Transformers scales effectively with larger datasets and higher model capacity. The advent of larger pre-trained models like GPT-3, with billions of parameters, showcases this scalability.
- Contextual Understanding & Long-Range Dependency Handling: The self-attention mechanism in Transformers allows them to consider relationships between all tokens in a sequence simultaneously, facilitating richer contextual embeddings. This also allows Transformers to capture long-range dependencies effectively.
- Versatility: Transformers can be easily adapted for various tasks by changing the input format, making them suitable for a range of applications in NLP, vision, and beyond.
- State-of-the-Art Performance: Transformers have achieved state-of-the-art results in numerous benchmark tasks in NLP, often outperforming traditional models.
Advanced Transformer Variants
The Transformer architecture has spurred numerous advanced variants tailored for specific tasks:
- BERT (Bidirectional Encoder Representations from Transformers): Introduced bidirectional context into the attention mechanism, allowing the model to consider both left and right contexts during training. This innovation led to improved performance in various NLP tasks.
- BART (Bidirectional and Auto-Regressive Transformers): Combines the strengths of bidirectional and auto-regressive models, excelling in tasks like text generation and summarization.
- GPT (Generative Pre-trained Transformer): Emphasizes unidirectional language modeling, excelling in generating coherent text and conversation. GPT-3 has set benchmarks in text generation tasks.
- T5 (Text-to-Text Transfer Transformer): Reframes all NLP tasks as converting input text into output text, providing a unified framework for various applications.
- Vision Transformers (ViTs): Applying Transformer principles to images, ViTs have shown that Transformers can outperform traditional CNNs in several vision tasks when trained on sufficient data. (How to compute the # tokens in ViT?)
- XLNet: A generalized autoregressive pretraining method that combines the strengths of autoregressive and autoencoding models, achieving state-of-the-art results in several NLP benchmarks.
Challenges and Limitations
Despite their remarkable capabilities, Transformers face challenges and limitations:
- Compute Resources: Training large Transformer models requires extensive computing resources and memory, making it challenging for smaller institutions or researchers to replicate state-of-the-art results.
- Lack of Interpretability: The inner workings of Transformer models can be opaque, complicating efforts to understand their decisions and behaviors.
- Data-Dependency: Transformers typically require substantial amounts of data for effective training, and securing such datasets can be problematic.
- Bias and Fairness: Transformers can learn and perpetuate biases from training datasets, raising ethical concerns about their deployment in real-world applications.
Conclusion
Transformers have revolutionized the field of deep learning, providing powerful solutions and breaking records across numerous domains. Their architecture, built around self-attention, has reshaped how we build models for complex tasks, from natural language processing to computer vision.
As research evolves and the applications of Transformers continue to expand, their potential will only grow. The challenges they face, though notable, are not insurmountable and highlight the importance of continued exploration and innovation in this exciting field.
References
- Vaswani et al. (2017). Attention Is All You Need. NeurIPS
- Annotated Transformer
- Illustrated-transformer

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!