
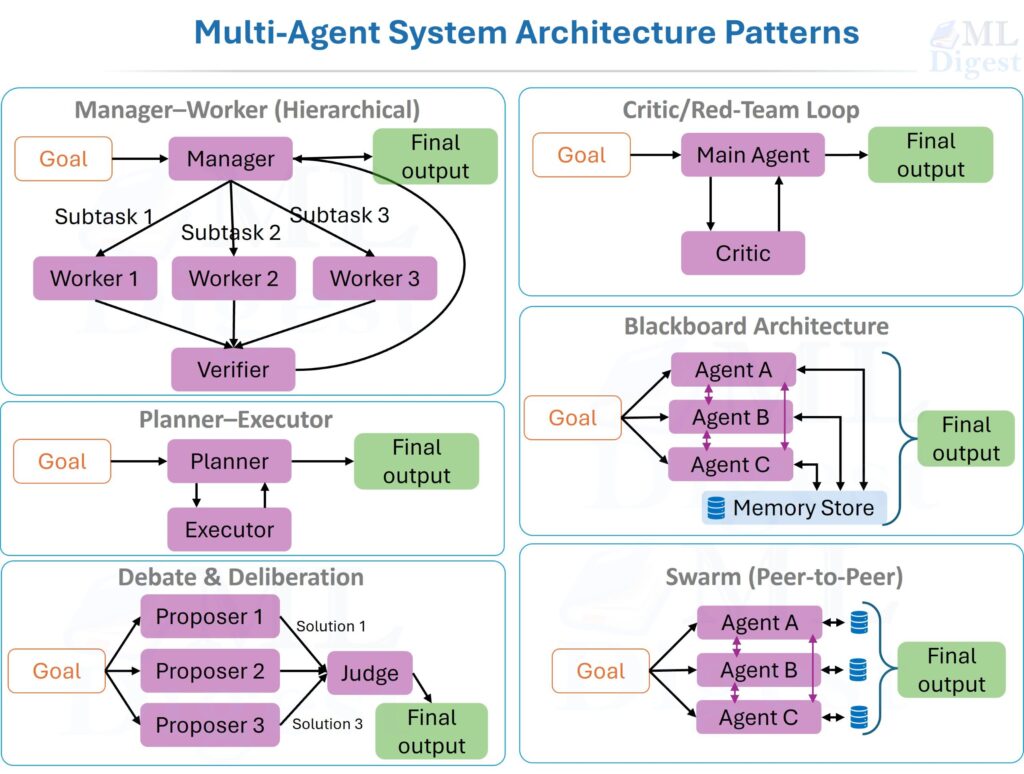
What Are Multi-Agent Systems? A Complete Guide to MAS in AI
Imagine you need to write a detailed technical report on a topic you know nothing about yet. You could ask […]
What Are Multi-Agent Systems? A Complete Guide to MAS in AI Read More »
Imagine you need to write a detailed technical report on a topic you know nothing about yet. You could ask […]
What Are Multi-Agent Systems? A Complete Guide to MAS in AI Read More »
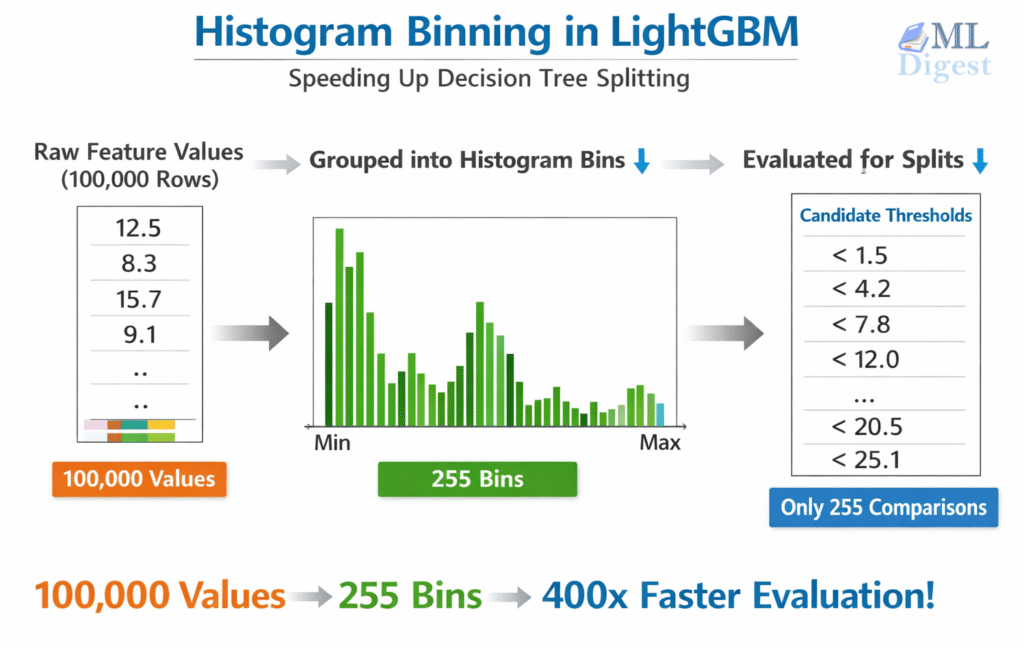
In tabular machine learning, the winning recipe is often not a flashy architecture but strong features plus a fast, reliable
The Illustrated LightGBM: A Beginner-Friendly Guide Read More »

Logistic regression is a probabilistic linear classifier. It starts with a linear score, converts that score into a probability for
Logistic Regression Demystified: A Practical Guide to Binary Classification Read More »
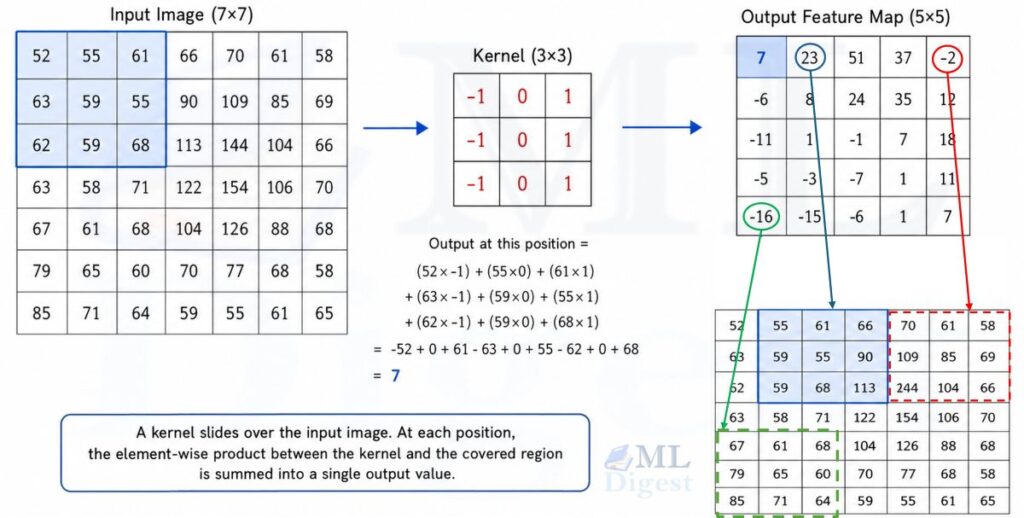
Imagine you are trying to recognize a cat in a photograph. You do not scan the entire image at once.
Convolutional Neural Networks (CNN) Made Easy: An Illustrated Deep Dive Read More »
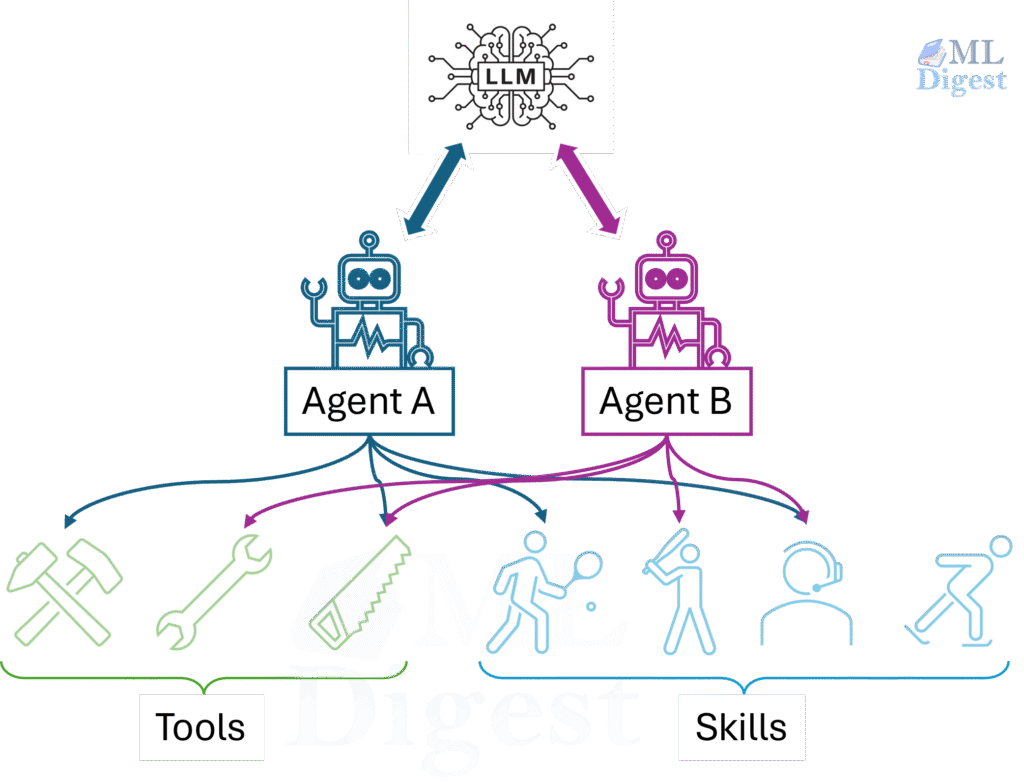
Imagine an AI agent as a highly capable generalist engineer walking into a new team on the first day. It
Agent Skills: A Practical Guide to Extending AI Agents with Reusable Expertise Read More »
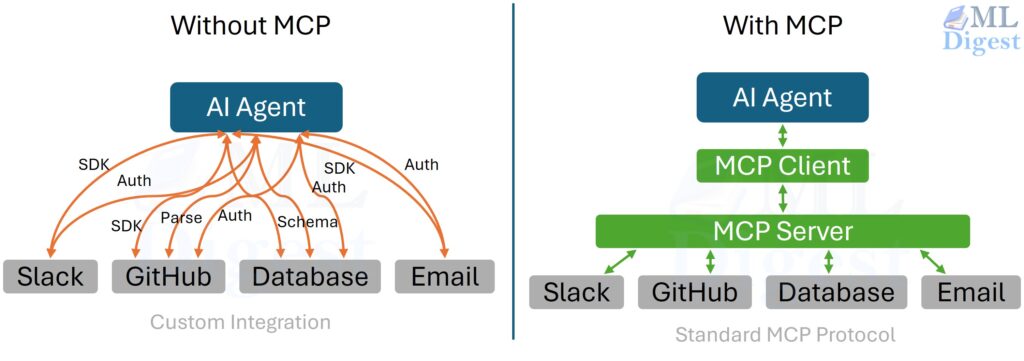
Imagine a desk full of devices with no common port standard. Your monitor needs one cable, your keyboard another, your
The Model Context Protocol (MCP): The USB-C Port for AI Tools and Data Read More »
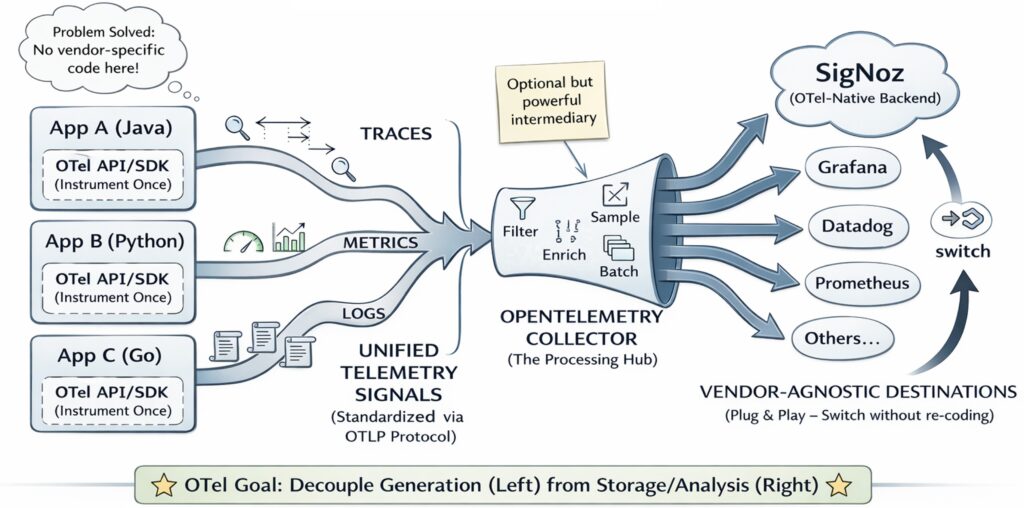
Imagine debugging a modern ML product without observability. It is like managing an airport where planes keep arriving late, bags
OpenTelemetry for ML Systems: Practical Observability That Explains What Happened Read More »
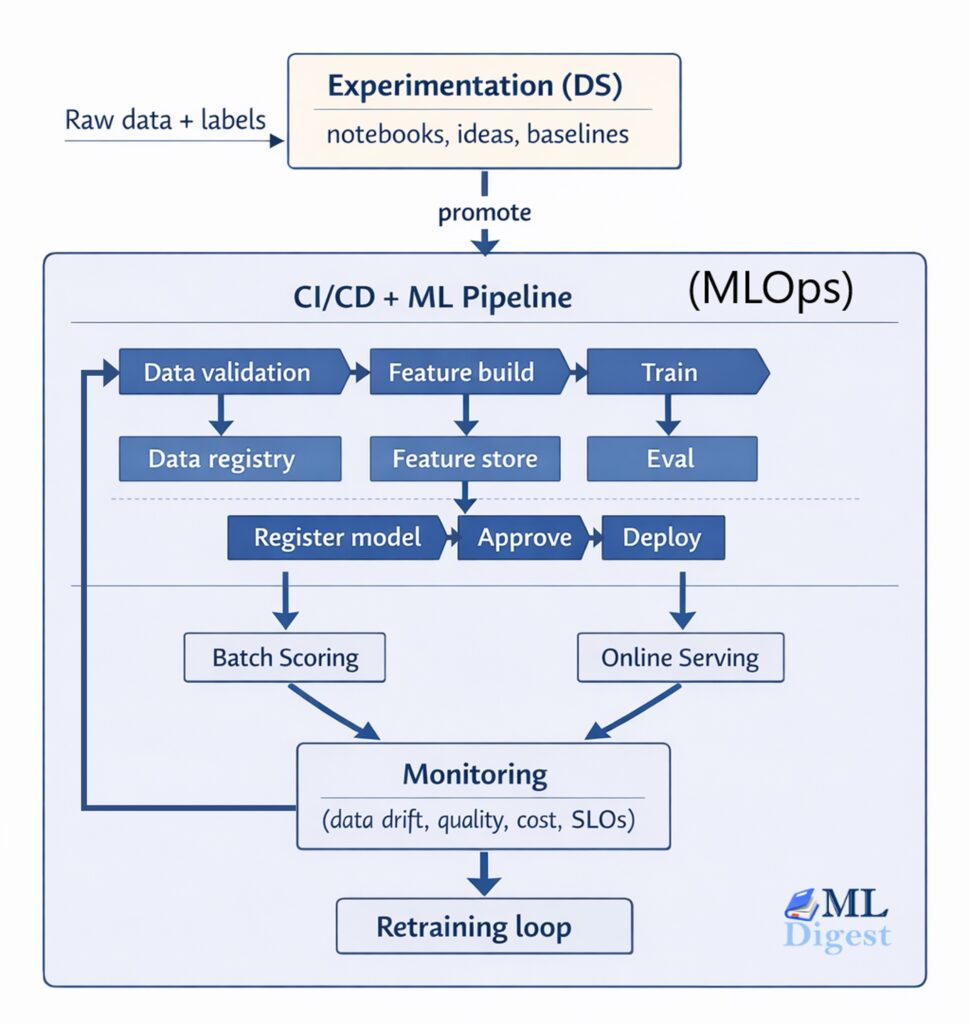
Think of a machine learning model as a high-performance engine prototype sitting on a pristine workbench. It might run beautifully
MLOps (Machine Learning Operations): From a Notebook to a Reliable Production System Read More »
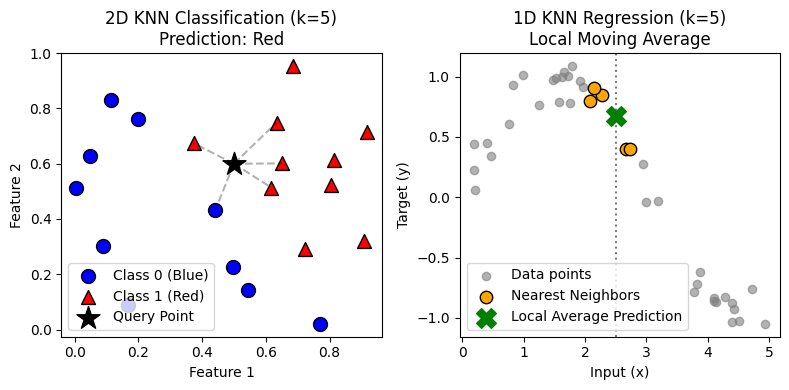
There is an old proverb that perfectly captures the intuition behind one of the most fundamental algorithms in machine learning:
k-Nearest Neighbors (KNN): From Geometry to Algorithms Read More »
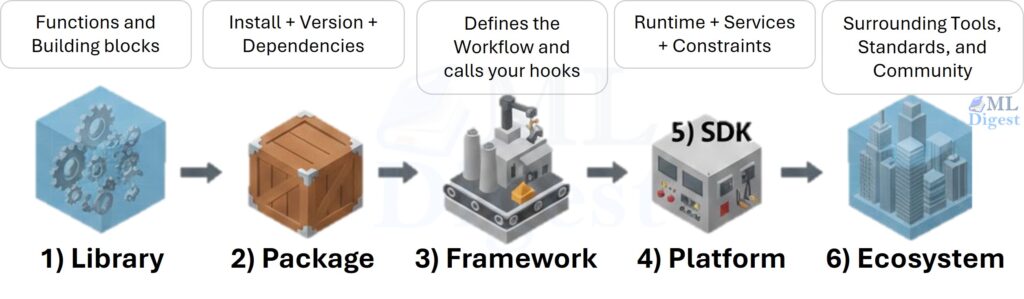
These terms are frequently used interchangeably, but they refer to different layers of software abstraction. Most confusion comes from accidentally
The Difference Between A Library, Framework, SDK, Platform And Ecosystem Read More »
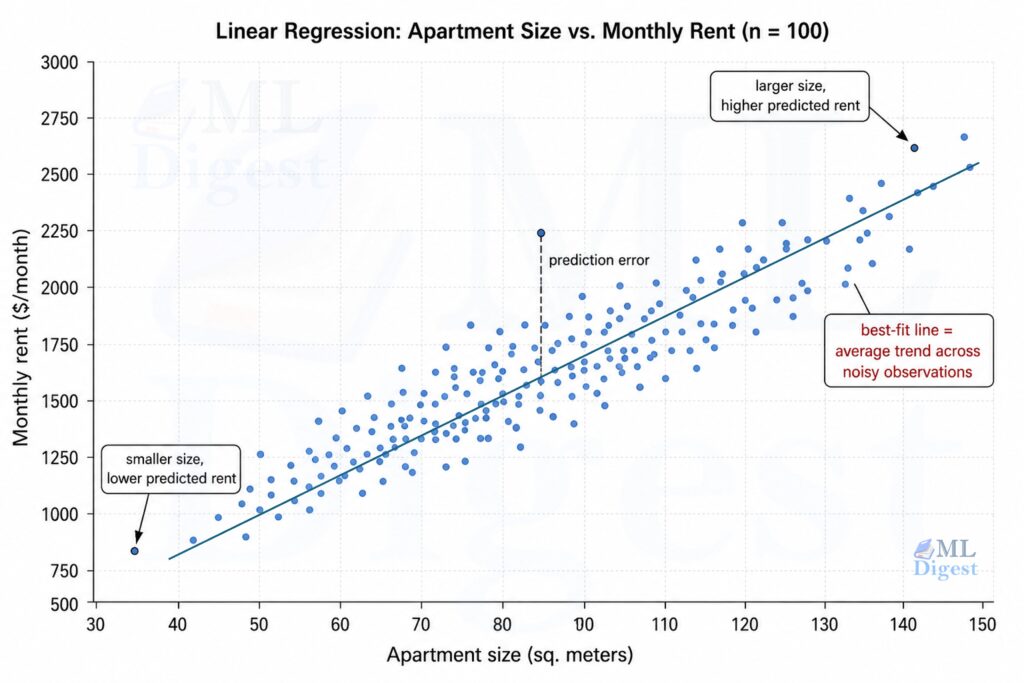
Imagine you are a real estate agent. A client walks in and asks: “How much should I list my house
Linear Regression Made Easy: A Complete Beginner’s Guide Read More »
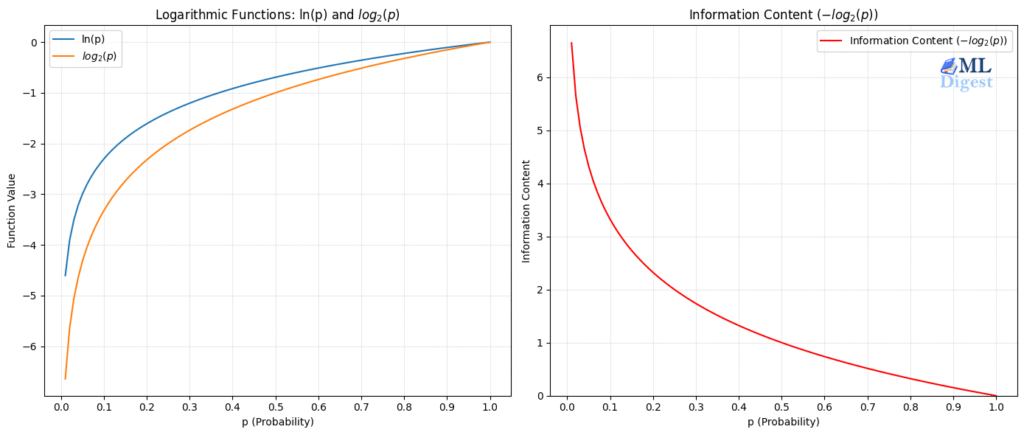
Machine Learning is often described as “data + algorithms”, but mathematics is the glue that makes everything work. At its
The Core Mathematical Foundations of Machine Learning Read More »