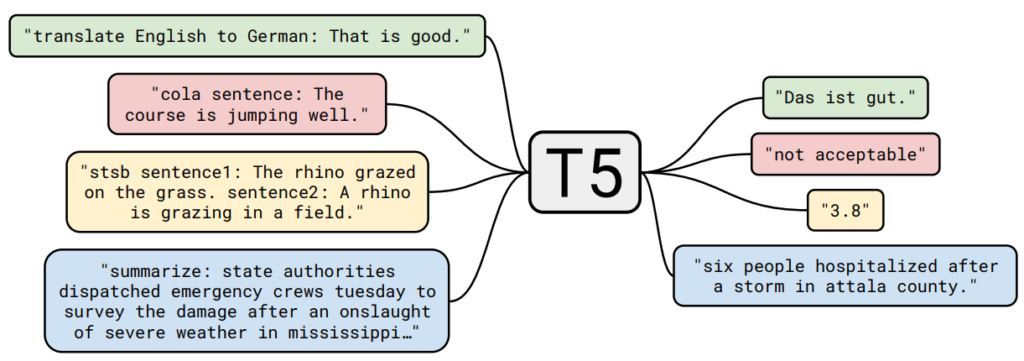
Imagine a study group where every student is allowed to look around the room before answering a question. One student may glance at the subject written on the board, another may check who asked the question, and a third may compare the question with a note from earlier in the discussion. Self-attention works in a similar way. Each token in a sequence looks at the other tokens, decides which ones matter most, and builds a richer representation of itself from that context.
This simple idea is one of the main reasons the Transformer, introduced in Attention Is All You Need, changed modern machine learning. Self-attention lets a model connect distant words directly, compute all token-token interactions within a layer in parallel during training, and build context-sensitive representations that are useful for language modeling, translation, vision, speech, and multimodal systems.
If you are interested in various types of attention mechanisms, then follow this post.
1. Why Self-Attention Matters
Before Transformers, many sequence models relied on recurrent networks such as LSTMs or GRUs. Those models process tokens one step at a time. That sequential structure is useful, but it also creates friction:
- Long-range dependencies are harder to learn because information has to travel through many steps.
- Training is less parallelizable because token $t$ often depends on computations from token $t – 1$.
- Important context can become diluted when sequences are long.
Self-attention changes the pattern. Instead of forcing information through a chain, it allows every token to interact with every other token in one layer. The word “bank” in “the fisherman sat on the bank” can attend to “fisherman” and “sat,” while in “She needed cash, so she went bank” it can attend to “cash.” The token representation becomes context-aware because meaning is built from relationships, not from the token in isolation.

Self-attention gives each token a dynamic view of the sequence. The same token can produce different internal representations depending on which neighboring tokens it attends to. This is a powerful way to capture polysemy, syntax, and long-range dependencies without the constraints of sequential processing.
2. Intuition: What Is Self-Attention Actually Doing?
Let us consider the following example.

When the model processes the token “it,” it should identify that “it” refers to “animal,” not “street.” A self-attention layer gives the model a mechanism to compare “it” with every other token and assign higher weight to the ones that help resolve the meaning.
At a high level, each token goes through three learned projections:
- Query: what this token is looking for
- Key: what this token offers to others
- Value: the information this token can pass along
You can think of the process like a retrieval system inside the sequence itself:
- A token creates a query.
- It compares that query against the keys of all tokens.
- It turns the similarity scores into weights.
- It takes a weighted combination of the value vectors.
The result is a new representation for the token, one that blends information from the whole sequence according to relevance.
This is why self-attention is often described as a “soft lookup” or “soft routing” mechanism. Unlike hard attention, which would commit to a single source position, soft attention constructs a weighted blend across all positions, allowing the model to integrate multiple sources of context simultaneously.
3. From Intuition to Mathematics
The standard self-attention used in Transformers is scaled dot-product attention. Given an input matrix
$$
X \in \mathbb{R}^{n \times d_{model}}
$$
where $n$ is the sequence length and $d_{model}$ is the embedding dimension, we compute:
$$
Q = XW_Q, \quad K = XW_K, \quad V = XW_V
$$
where:
- $W_Q \in \mathbb{R}^{d_{model} \times d_k}$
- $W_K \in \mathbb{R}^{d_{model} \times d_k}$
- $W_V \in \mathbb{R}^{d_{model} \times d_v}$
These are learned projection matrices.
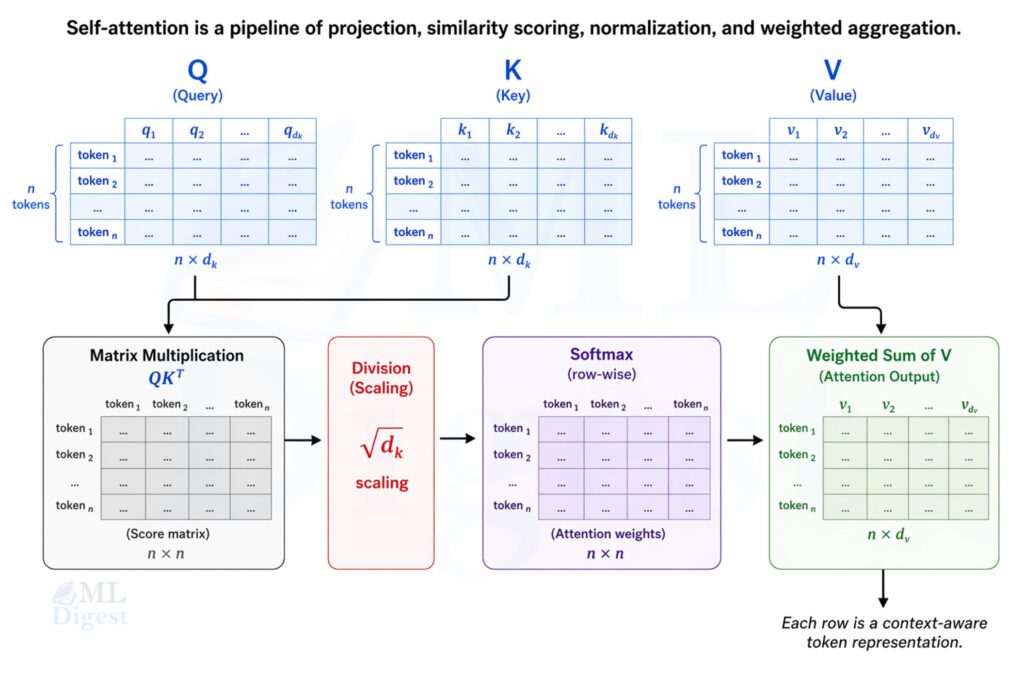
3.1 Attention Scores
Each query vector is compared with all key vectors using a dot product:
$$
S = QK^T
$$
If token $i$ has query $q_i$ and token $j$ has key $k_j$, then the raw attention score is:
$$
s_{ij} = q_i \cdot k_j
$$
Higher values indicate stronger relevance.
3.2 Why Do We Scale by $\sqrt{d_k}$?
The Transformer divides the scores by $\sqrt{d_k}$:
$$
Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V
$$
Why is that useful?
If the key and query dimensions are large, the raw dot products can also become large in magnitude. Passing large scores into softmax can make the output distribution too sharp, which leads to tiny gradients and unstable learning. Dividing by $\sqrt{d_k}$ keeps the variance of the scores under control.
This scaling step is a small modification, but its effect on gradient stability makes it important in practice, especially when training deep Transformer models.
3.3 Softmax Turns Scores into Weights
For each token, softmax converts raw scores into a probability distribution:
$$
\alpha_{ij} = \frac{\exp(s_{ij} / \sqrt{d_k})}{\sum_{m=1}^{n} \exp(s_{im} / \sqrt{d_k})}
$$
The weights for token $i$ sum to 1 across all source positions $j$.
3.4 Weighted Sum of Values
The new representation for token $i$ is:
$$
z_i = \sum_{j=1}^{n} \alpha_{ij} v_j
$$
So the output is a learned blend of value vectors, with the mixing weights determined by query-key similarity.
3.5 Matrix Form
For the entire sequence at once:
$$
Z = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
$$
This matrix form is one reason Transformers are efficient on modern hardware. All token-token interactions in a layer can be computed with large batched matrix multiplications.

Observe that when computing the final representation for token $i$, the model is effectively performing a weighted average of all the value vectors, where the weights are determined by how well the query of token $i$ matches the keys of all tokens. This allows each token to gather information from the entire sequence in a way that is sensitive to context and relevance.
4. Step-by-Step Walkthrough with a Tiny Example
Let us say we have three tokens with projected vectors already computed:
$$
Q = \begin{bmatrix}
1 & 0 \\
1 & 1 \\
0 & 1
\end{bmatrix},
\quad
K = \begin{bmatrix}
1 & 0 \\
1 & 1 \\
0 & 1
\end{bmatrix},
\quad
V = \begin{bmatrix}
1 & 2 \\
0 & 3 \\
4 & 1
\end{bmatrix}
$$
Then:
$$
QK^T = \begin{bmatrix}
1 & 1 & 0 \\
1 & 2 & 1 \\
0 & 1 & 1
\end{bmatrix}
$$
Since $d_k = 2$, the scale factor is $\sqrt{2}$.
For the second token, the raw score row is:$[1, 2, 1]$
After scaling:$[0.707, 1.414, 0.707]$
After softmax, the weights might be approximately:$[0.25, 0.5, 0.25]$
Finally, the output for the second token is:
$$0.25 \cdot [1, 2] + 0.5 \cdot [0, 3] + 0.25 \cdot [4, 1] = [1.25, 2.25]$$
After scaling and softmax, the middle token assigns the highest weight to itself, but it still draws information from the other tokens. This is the essence of soft attention: rather than pointing to a single source position, the model blends information from all positions according to learned relevance.
Note that it is possible for a token to assign more weight to another token than to itself. It depends on the learned projections and the input data. The model can learn to attend more to other tokens if they are more relevant for the current context. This flexibility is part of what makes self-attention so powerful.
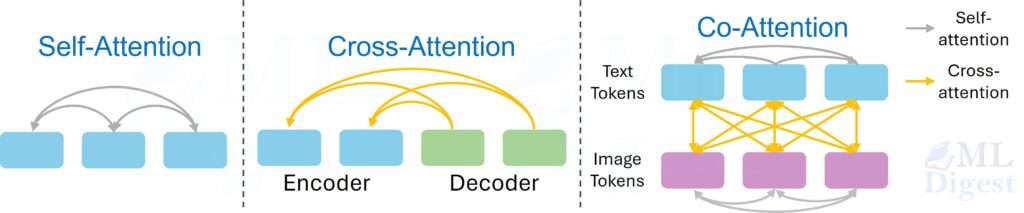
5. Self-Attention vs Cross-Attention
Self-attention means the queries, keys, and values all come from the same sequence.
- In an encoder, each input token attends to other input tokens.
- In a decoder, self-attention is usually masked so a token cannot see future tokens.
Cross-attention is different:
- queries come from one sequence, usually the decoder states
- keys and values come from another sequence, usually the encoder output
This distinction matters because many articles use “attention” as a broad term, but the behavior depends on where $Q$, $K$, and $V$ come from.
In the original Transformer for machine translation, the decoder uses cross-attention to condition each output token on the full encoded source sentence. The same pattern appears in vision-language models, where a language decoder attends over visual features from an image encoder, and in text-conditioned diffusion models, where the denoising network attends over text embeddings.
6. Causal Masking and Padding Masks
In autoregressive language models like GPT, the token at position $t$ must not attend to tokens at positions greater than $t$. Otherwise the model would cheat during training.
This is handled with a causal mask. Conceptually, positions above the diagonal in the score matrix are set to $-\infty$ before softmax:
$$
\begin{bmatrix}
0 & -\infty & -\infty \\
0 & 0 & -\infty \\
0 & 0 & 0
\end{bmatrix}
$$
After softmax, those masked entries become zero probability.
Padding masks solve a different problem. They prevent the model from attending to artificial pad tokens that were added only for batching. The padding mask is typically a binary matrix that indicates which positions are padding and which are real tokens. The masked positions are again set to $-\infty$ before softmax, ensuring they do not contribute to the output.
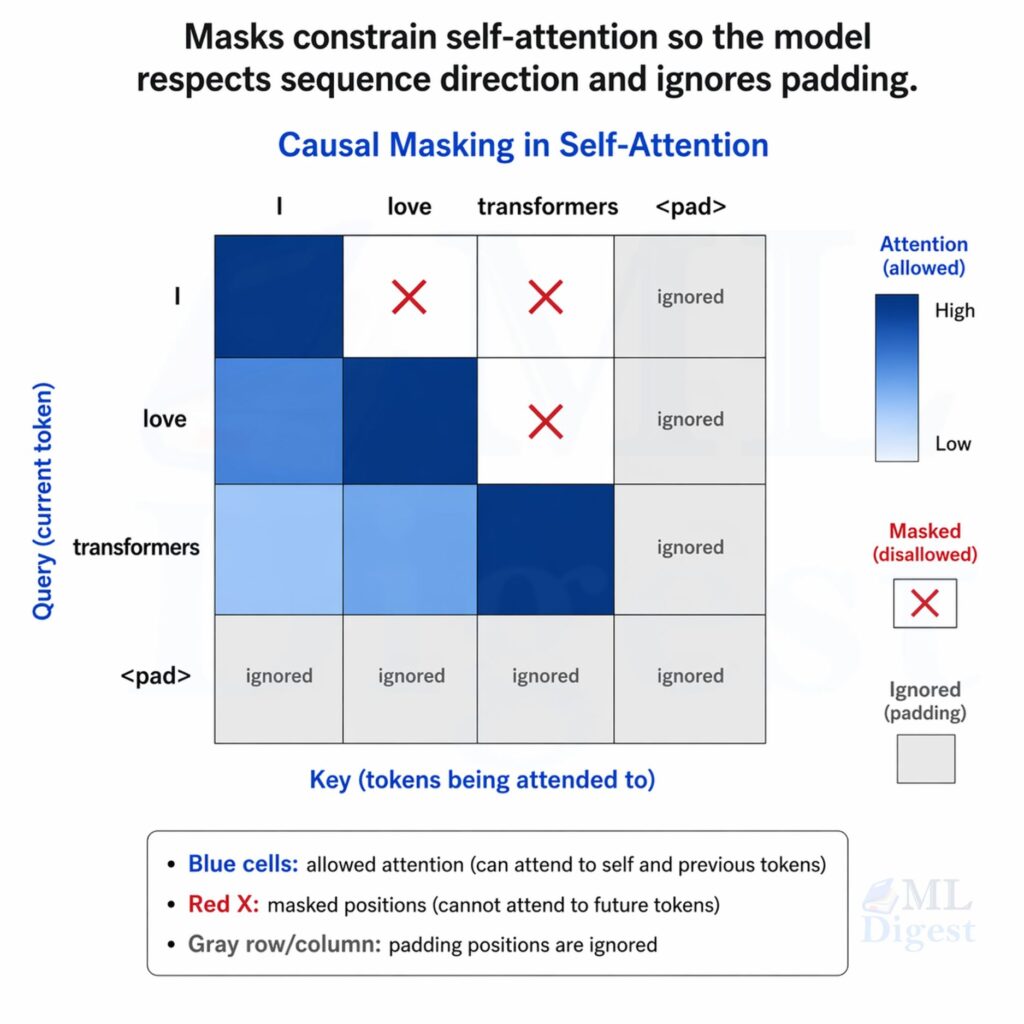
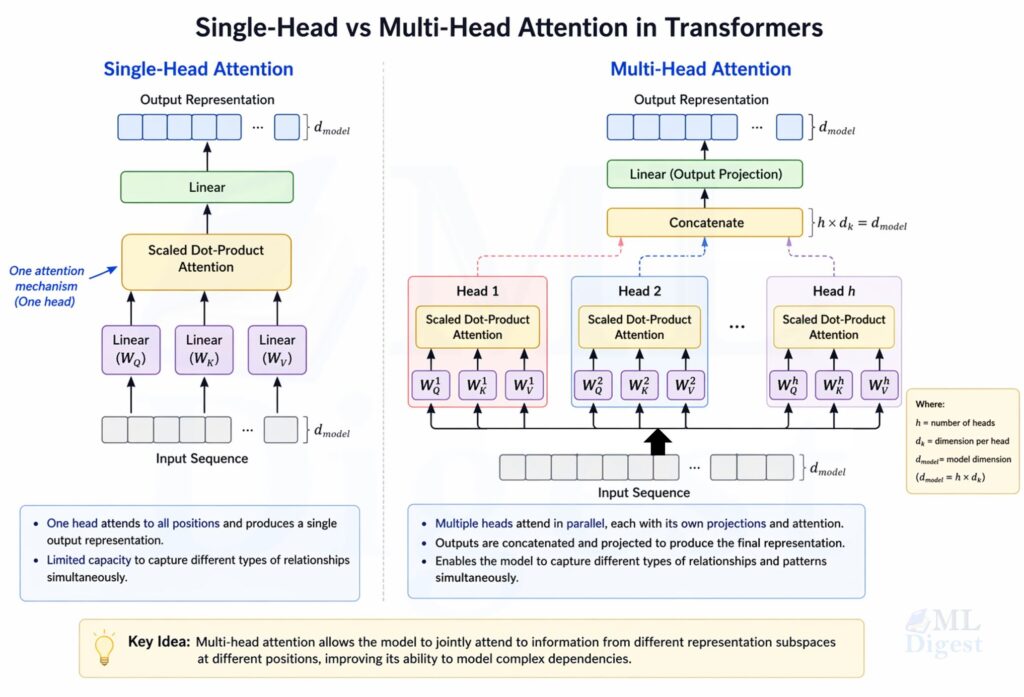
7. Multi-Head Attention: Why One View Is Not Enough
The original Transformer does not rely on a single attention computation. It uses multi-head attention.
Instead of one set of projections, we learn several heads:
$$
head_h = Attention(Q_h, K_h, V_h)
$$
Then the head outputs are concatenated and projected:
$$
MultiHead(Q, K, V) = Concat(head_1, \dots, head_H)W_O
$$
Why is this useful?
Different heads can specialize in different patterns:
- local syntax
- long-range agreement
- entity references
- positional relationships
- delimiter or separator tokens
In practice, heads do not always become neatly interpretable, but the multi-head design increases representational flexibility. It allows the model to capture multiple types of relationships in parallel, which can lead to better performance on complex tasks. The original Transformer used $H = 8$ heads with $d_{model} = 512$, and $d_k = d_v = 64$ per head.
8. Positional Information: Attention Alone Does Not Know Order
A pure self-attention operation without positional information is permutation-equivariant, not order-aware. If you shuffle the input tokens and their embeddings, the outputs shuffle in the same way, because the attention mechanism itself has no built-in sense of word order.
Transformers therefore add positional information. In the original paper, this was done with sinusoidal positional encodings:
$$
PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i / d_{model}}}\right)
$$
$$
PE(pos, 2i + 1) = \cos\left(\frac{pos}{10000^{2i / d_{model}}}\right)
$$
Modern models may use learned positional embeddings, relative position bias, RoPE, or ALiBi. For a broader comparison of these approaches, including absolute and relative schemes, see absolute vs relative position embeddings. The exact choice varies, but the goal is the same: inject order information into an attention-based architecture.
9. Computational Cost and the Main Limitation
Self-attention is elegant, but it is not free.
For a sequence of length $n$, the attention score matrix has shape $n \times n$. That leads to:
- time complexity of roughly $O(n^2 d)$ for the score computation
- memory cost that also grows quadratically with sequence length
This is manageable for short and medium-length sequences, but it becomes expensive for long documents, high-resolution images, or long-context language models.
That limitation motivated several lines of work. Some methods change the attention pattern or approximate it, including Longformer, Performer, and Linformer. Others, such as FlashAttention, keep exact attention but make the computation much more memory- and IO-efficient on modern hardware. The important point is this: standard self-attention quadratic scaling is a real systems concern.
10. Implementing Self-Attention from Scratch
Using NumPy
The best way to internalize self-attention is to implement it with small matrices.
import numpy as np
def softmax(x, axis=-1):
x = x - np.max(x, axis=axis, keepdims=True)
exp_x = np.exp(x)
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
def self_attention(x, w_q, w_k, w_v, mask=None):
"""
x: [seq_len, d_model]
w_q: [d_model, d_k]
w_k: [d_model, d_k]
w_v: [d_model, d_v]
mask: [seq_len, seq_len], values are 0 for keep and -1e9 for mask
"""
q = x @ w_q
k = x @ w_k
v = x @ w_v
scores = q @ k.T / np.sqrt(k.shape[-1])
if mask is not None:
scores = scores + mask
weights = softmax(scores, axis=-1)
output = weights @ v
return output, weights
np.random.seed(7)
seq_len = 4
d_model = 6
d_k = 4
d_v = 4
x = np.random.randn(seq_len, d_model)
w_q = np.random.randn(d_model, d_k)
w_k = np.random.randn(d_model, d_k)
w_v = np.random.randn(d_model, d_v)
output, weights = self_attention(x, w_q, w_k, w_v)
print("Attention weights shape:", weights.shape)
print(weights)
print("Output shape:", output.shape)
print(output)What this code demonstrates:
- the three linear projections
- scaled dot-product score computation
- row-wise softmax over source positions
- weighted value aggregation
If you print weights, each row tells you how much one token attends to all tokens in the sequence.
Using PyTorch Module
The following PyTorch module is small enough to read in one sitting, but close enough to production structure to be useful.
import math
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_model, d_k, d_v):
super().__init__()
self.w_q = nn.Linear(d_model, d_k, bias=False)
self.w_k = nn.Linear(d_model, d_k, bias=False)
self.w_v = nn.Linear(d_model, d_v, bias=False)
def forward(self, x, mask=None):
# x shape: [batch_size, seq_len, d_model]
q = self.w_q(x)
k = self.w_k(x)
v = self.w_v(x)
scores = q @ k.transpose(-2, -1)
scores = scores / math.sqrt(k.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = torch.softmax(scores, dim=-1)
output = weights @ v
return output, weights
batch_size = 2
seq_len = 5
d_model = 16
d_k = 8
d_v = 8
x = torch.randn(batch_size, seq_len, d_model)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0)
layer = SelfAttention(d_model, d_k, d_v)
output, weights = layer(x, mask=mask)
print("output shape:", output.shape)
print("weights shape:", weights.shape)There are three implementation details worth noticing:
- The matrix multiplication
q @ k.transpose(-2, -1)computes all pairwise query-key scores in parallel. - The scale factor uses the key dimension, not the model dimension.
- The causal mask is applied before softmax, not after.
From Single-Head to Multi-Head in Code
A production Transformer layer adds several pieces around self-attention:
- multiple heads
- output projection
- residual connection
- layer normalization
- feed-forward network
- dropout
Conceptually, multi-head attention looks like this:
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.qkv = nn.Linear(d_model, 3 * d_model, bias=False)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, d_model = x.shape
qkv = self.qkv(x)
q, k, v = qkv.chunk(3, dim=-1)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
scores = q @ k.transpose(-2, -1)
scores = scores / math.sqrt(self.head_dim)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = torch.softmax(scores, dim=-1)
output = weights @ v
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.out_proj(output)If you are learning Transformers, it is worth implementing this once from scratch. Many confusions about shapes, masking, and projections become much clearer after that exercise.
11. Practical Tips and Best Practices
- Check Tensor Shapes Aggressively:
Most bugs in attention code are shape bugs. Print shapes early, especially when splitting into heads and applying masks.
Common reference shapes:- input:
[batch_size, seq_len, d_model] - queries, keys, values after head split:
[batch_size, num_heads, seq_len, head_dim] - scores:
[batch_size, num_heads, seq_len, seq_len]
- input:
- Apply Masks Before Softmax:
This is easy to get wrong. The masked positions must receive very negative scores before softmax so they become zero-probability positions afterward. - Watch Numerical Stability:
- subtract the row-wise maximum before a manual softmax implementation
- use stable framework functions when possible
- be careful with half precision and very long sequences
- Use Visualization for Debugging:
Plotting an attention heatmap often reveals issues faster than reading tensor values line by line. If the heatmap is uniform when it should be selective, or if future tokens are visible in a causal model, something is wrong. - Do Not Over-Interpret Attention Maps:
Attention weights are informative, but they are not a perfect explanation of model reasoning. They show one part of the computation, not the entire causal story behind a prediction.
12. Common Misconceptions
Self-Attention Is Not the Same as Memory Lookup
The retrieval analogy is useful, but self-attention is a learned differentiable mechanism inside a neural network. It is not a literal symbolic database lookup.
More Heads Does Not Automatically Mean Better Performance
The number of heads interacts with head dimension, model width, data scale, and optimization. More heads can help, but beyond a point they may not add much.
Self-Attention Does Not Replace Everything
Modern architectures still rely on feed-forward layers, normalization, residual pathways, tokenizer design, optimization choices, and increasingly systems-level innovations such as fused kernels and memory-efficient attention implementations.
Closing Thoughts
If you remember only one idea, remember this: self-attention lets each token build its meaning by consulting the rest of the sequence.
That idea is simple, but its consequences are profound. It shortens the path between distant dependencies, makes sequence processing highly parallelizable, and gives models a flexible way to represent context. Once you understand queries, keys, values, scaling, masking, and multi-head structure, the rest of the Transformer becomes much easier to reason about.
Although self-attention became famous in language modeling, the pattern is now broader:
- vision, through models such as ViT
- speech recognition and audio modeling
- time-series forecasting
- recommender systems
- multimodal models that connect text, images, audio, and video
That broad adoption tells us something important. Self-attention is not just a language trick. It is a general mechanism for learning relationships within a set or sequence.
Suggested Reading and Tools
For a deeper dive, these are the most useful first references:
- Attention Is All You Need
- Transformer Model Deep Dive
- The Illustrated Transformer
- BERT Deep Dive
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- PyTorch MultiheadAttention documentation
- Hugging Face Transformers

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!