Neural networks are inspired by the human brain, where neurons communicate through synapses. Just as biological neurons are activated when they receive signals above a certain threshold, artificial neurons in neural networks utilize activation functions to determine if they should “fire” (send signals) based on the weighted sum of their inputs.
Activation functions introduce the non-linearity that gives neural networks their expressive power. Without them, even a deep network reduces to a linear mapping.
Without non-linear activation functions between layers, even a very deep network collapses into a single linear transformation. Depth alone is not enough.
What an Activation Function Does
For a single neuron, the pre-activation value is:
$$z = w_1x_1 + w_2x_2 + \, \dots \, + w_nx_n + b$$
where $w_{i}$ represents the weights, $x_{i}$ corresponds to the inputs, and $b$ is the bias term.
The activation function $f$ then produces the output:
$$a = f(z)$$
This output $a$ becomes the input to the next layer. That small step is what gives a network its expressive power.
Activation functions mainly help with three things:
- Introducing non-linearity: Real-world relationships are rarely purely linear. Activation functions let neural networks model curves, thresholds, and more complex feature interactions.
- Controlling signal flow: Some activations suppress small values, others keep negative values, and some produce normalized probabilities. This affects how information moves through the network.
- Influencing optimization: The choice of activation affects gradient flow during backpropagation, which in turn affects stability, convergence speed, and final performance.
Why Non-Linearity Matters
The importance of activation functions becomes clearer if we imagine stacking only linear layers.
Suppose a network has two linear layers:
- $y = W_1x + b_1$
- $z = W_2y + b_2$
Substituting the first equation into the second gives:
$$z = W_2(W_1x + b_1) + b_2 = (W_2W_1)x + (W_2b_1 + b_2)$$
This is still just a linear function of $x$. In other words, stacking linear layers does not increase the model’s ability to represent complex patterns. Activation functions break that limitation.
A Useful Mental Model
It helps to think about activation functions in two separate roles:
- Hidden-layer activations shape how intermediate features are formed. They affect gradient flow, sparsity, stability, and how easily the model can learn complex patterns.
- Output-layer activations enforce the form of the prediction. For example, sigmoid maps outputs to probabilities for binary classification, softmax produces a class distribution, and a linear output leaves regression predictions unconstrained.
That distinction matters because the “best” activation depends first on where it is used. A strong hidden-layer default such as ReLU or GELU may be a poor choice for the final layer if the prediction has to be bounded, normalized, or strictly positive.
Quick Reference Summary
| Activation Function | Output Range | Best For | Main Drawback |
|---|---|---|---|
| Sigmoid | $(0, 1)$ | Binary classification output | Vanishing gradients |
| Tanh | $(-1, 1)$ | Hidden layers (older models), RNNs | Vanishing gradients |
| ReLU | $[0, \infty)$ | Default for hidden layers | Dying ReLUs |
| Leaky ReLU | $(-\infty, \infty)$ | Replacing ReLU when neurons “die” | Hard to tune extra hyperparameter |
| Softmax | $(0, 1)$ (sums to 1) | Multi-class classification output | Computationally heavier |
| ELU | $(-\alpha, \infty)$ | Zero-centered negatives, faster convergence | Computationally expensive |
| GELU | Approx. $(-0.17, \infty)$ | Transformers, LLMs (hidden layers) | Computationally expensive |
| Mish | Approx. $(-0.31, \infty)$ | Modern deep architectures | Computationally expensive |
| SELU | $(-\lambda\alpha, \infty)$ | Self-normalizing networks | Requires specific architecture setup |
| Swish/SiLU | Approx. $(-0.28, \infty)$ | Deep modern architectures, CNNs | Computationally expensive |
| SwiGLU | Approx. $(-\infty, \infty)$ | Transformer feed-forward blocks | Requires feed-forward block redesign |
| Softplus | $(0, \infty)$ | Positive-valued outputs | Slower, rarely used in hidden layers |
Desirable Properties of an Activation Function
There is no universally ideal activation function, but the most useful ones tend to share a few practical properties:
- Differentiable: The function must be differentiable everywhere (or almost everywhere, like ReLU) so that the network can learn via backpropagation and gradient descent.
- Zero-centered: Outputs that are centered around zero help keep the gradients from skewing in a single direction, which speeds up convergence during training.
- Computational Efficiency: Because activation functions are applied millions (or billions) of times per forward pass, they must be extremely fast to compute.
- Non-saturating: Functions that squash inputs into a small bounded range (like sigmoid) can cause gradients to shrink to near zero. Non-saturating functions help prevent this vanishing gradient problem.
- Monotonic: A monotonic function ensures that the error surface is smoother, making optimization easier and more predictable. That said, this is a desirable property rather than a hard requirement — GELU and Swish are both non-monotonic yet perform very well in practice.
Common Types of Activation Functions
The evolution of deep learning has been closely tied to the discovery of better activation functions. Here is a look at the most common types, starting from the classics to modern, state-of-the-art choices.
1. Sigmoid
- Formula: $\sigma(x) = \frac{1}{1 + e^{-x}}$
- Output range: $(0, 1)$
The sigmoid function maps any real-valued input to a value between 0 and 1. Because of that, it is commonly used in the output layer for binary classification, where the output can be interpreted as a probability.
Its main drawback is saturation. When the input is very large or very small, the gradient becomes tiny, which slows learning in deep networks and contributes to the “vanishing gradient problem.”
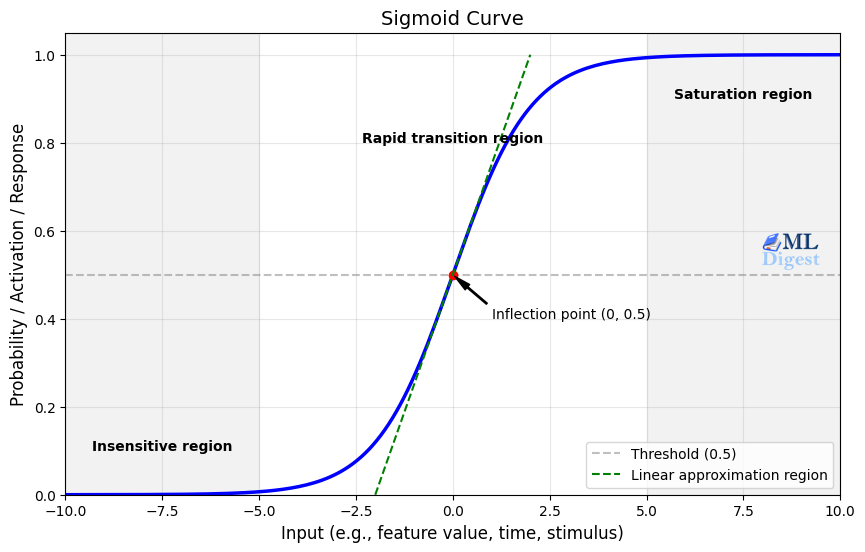
2. Hyperbolic Tangent (tanh)
- Formula: $\tanh(x) = \frac{e^x – e^{-x}}{e^x + e^{-x}}$
- Output range: $(-1, 1)$
The tanh activation is similar to sigmoid, but it is zero-centered. That often makes optimization easier because activations are distributed around zero rather than being strictly positive.
Even so, tanh still saturates for large positive or negative inputs, so it can also suffer from vanishing gradients in deeper networks.
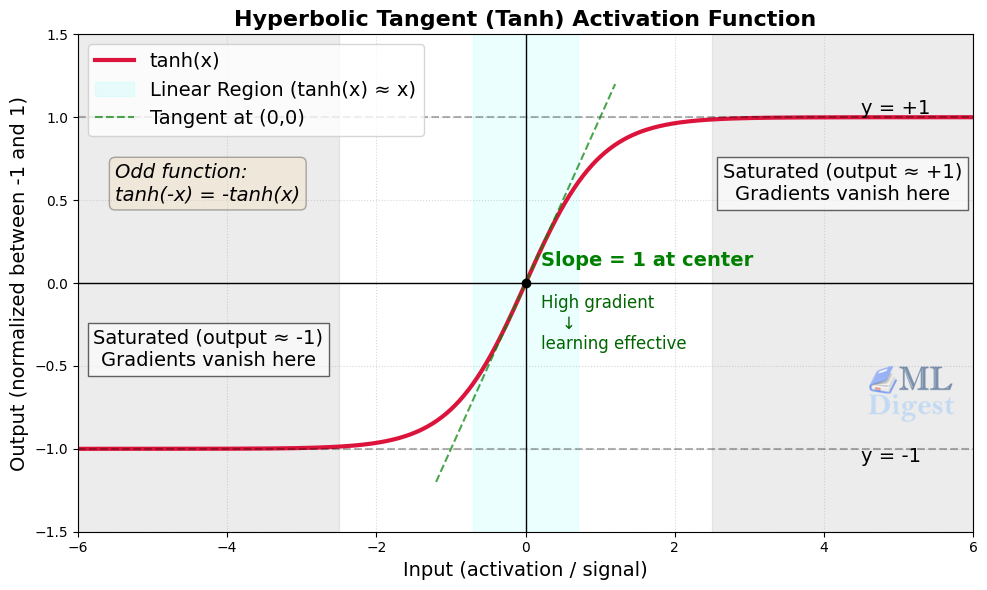
3. Rectified Linear Unit (ReLU)
- Formula: $f(x) = \max(0, x)$
- Output range: $[0, \infty)$
ReLU is one of the most widely used activation functions in hidden layers. It is simple, cheap to compute, and does not saturate on the positive side, which helps gradient-based training.
Its main weakness is the dying ReLU problem. If a neuron’s pre-activation value (the weighted sum z = Wx + b) is consistently negative, its output becomes permanently zero and its gradient is also zero, making it effectively inactive.

4. Leaky ReLU
- Formula:
$$
f(x) =
\begin{cases}
x & \text{if } x > 0 \\
\alpha x & \text{if } x \leq 0
\end{cases}
$$
- Output range: $(-\infty, \infty)$
Leaky ReLU is a variation of ReLU that keeps a small slope for negative inputs. Instead of outputting exactly zero for every negative value, it outputs $\alpha x$, where $\alpha$ is typically a small constant such as $0.01$.
This helps reduce the risk of neurons becoming permanently inactive.
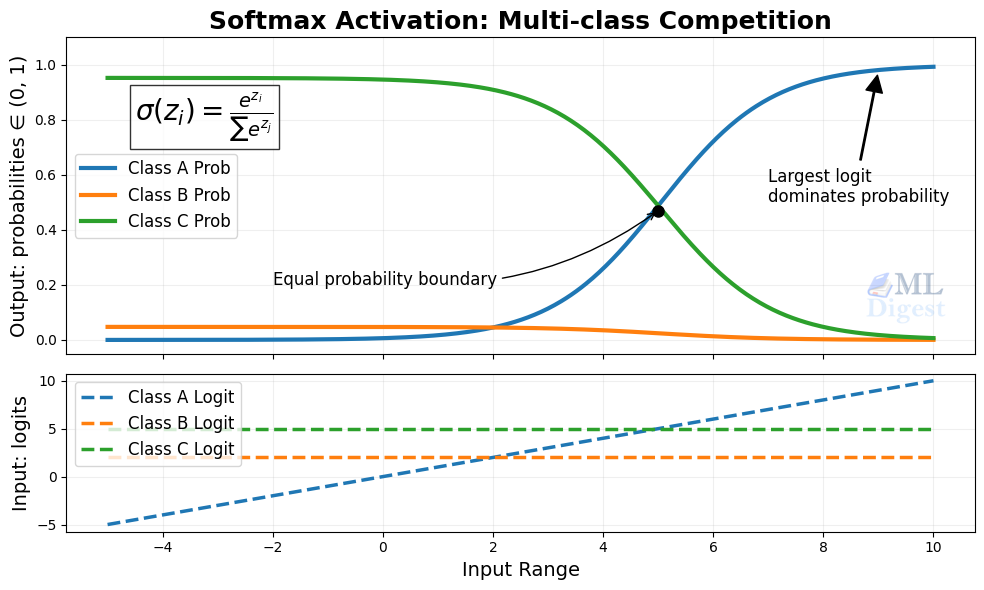
5. Softmax
- Formula:
$$
\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}
$$
- Output range: each value lies in $(0, 1)$, and all outputs sum to $1$
Softmax is typically used in the output layer for multi-class classification. It converts a vector of logits into a probability distribution across classes.
One important detail is that softmax is generally not used in hidden layers. Its main role is at the output, where the model must choose among mutually exclusive classes. In practice, many frameworks apply softmax implicitly inside a numerically stable cross-entropy loss, so the model may emit raw logits during training even though the conceptual output activation is still softmax.
6. ELU (Exponential Linear Unit)
- Formula:
$$
f(x) =
\begin{cases}
x & \text{if } x > 0 \\
\alpha(e^x – 1) & \text{if } x \leq 0
\end{cases}
$$
- Output range: $(-\alpha, \infty)$
ELU behaves like ReLU for positive inputs but produces smooth negative values instead of zeroing them out. That negative region can push mean activations closer to zero, which sometimes helps optimization converge faster than standard ReLU.
Its downside is computational cost. Because it uses an exponential for negative inputs, it is heavier than ReLU or Leaky ReLU.
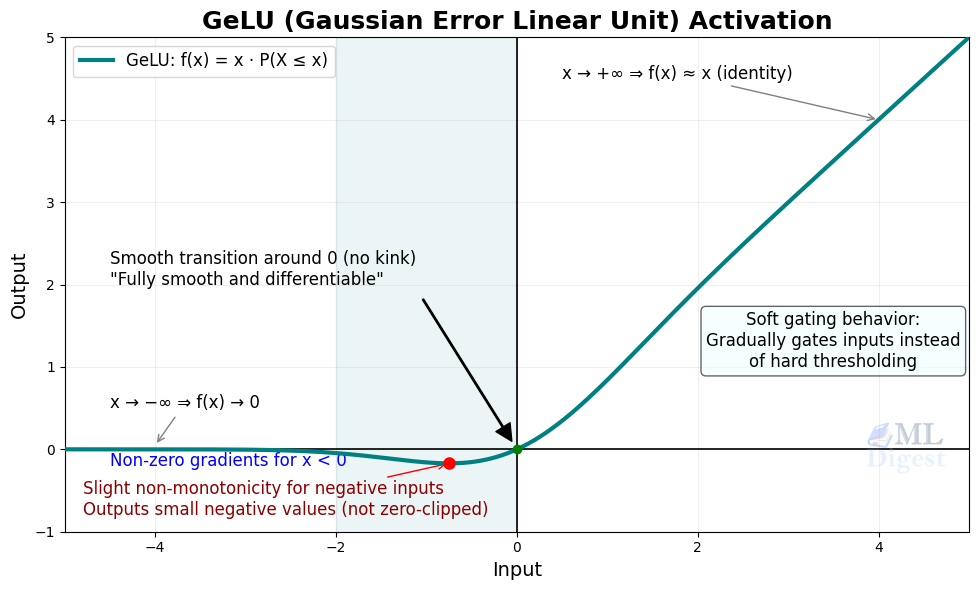
7. GELU (Gaussian Error Linear Unit)
- Formula: $f(x) = x \Phi(x)$, where $\Phi(x)$ is the cumulative distribution function of a standard normal distribution
- Output range: Approx. $(-0.17, \infty)$
GELU is a smooth activation that scales inputs by their magnitude instead of applying a hard cutoff. Small negative values are not fully discarded, and large positive values pass through almost unchanged.
Modern libraries such as PyTorch and TensorFlow compute GELU using the exact erf-based form: $f(x) = \frac{x}{2}\left(1 + \text{erf}!\left(\frac{x}{\sqrt{2}}\right)\right)$. A fast tanh approximation is also available for cases where speed is critical: $f(x) \approx 0.5x\left(1 + \tanh!\left(\sqrt{\tfrac{2}{\pi}}\,(x + 0.044715x^3)\right)\right)$, and delivers nearly identical results.
GELU became especially popular in transformer architectures and large language models (BERT, GPT-2, GPT-3) because it often works well in deep networks that benefit from smooth nonlinearities.
8. Mish
- Formula: $f(x) = x \cdot \tanh(\ln(1 + e^x))$
- Output range: Approx. $(-0.31, \infty)$
Mish is another smooth, non-monotonic activation that preserves small negative values rather than clipping them to zero. It was proposed as an alternative to ReLU-like activations for models that may benefit from smoother gradients.
In practice, Mish can work well, but it is less common than ReLU, GELU, or Swish in mainstream production models. The extra computation also makes it a less obvious default choice.
9. SELU (Scaled Exponential Linear Unit)
- Formula:
$$
f(x) = \lambda
\begin{cases}
x & \text{if } x > 0 \\
\alpha(e^x – 1) & \text{if } x \leq 0
\end{cases}
$$
where $\lambda \approx 1.0507$ and $\alpha \approx 1.6733$ are fixed constants derived analytically to achieve self-normalization.
SELU was designed for self-normalizing neural networks. Under the right conditions, it can help keep activations within a stable range — with zero mean and unit variance — as they move through many layers.
That benefit depends on the full setup, not just the activation itself. SELU is typically paired with LeCun normal weight initialization and AlphaDropout (instead of standard dropout), so it is not a drop-in replacement for ReLU in arbitrary architectures.
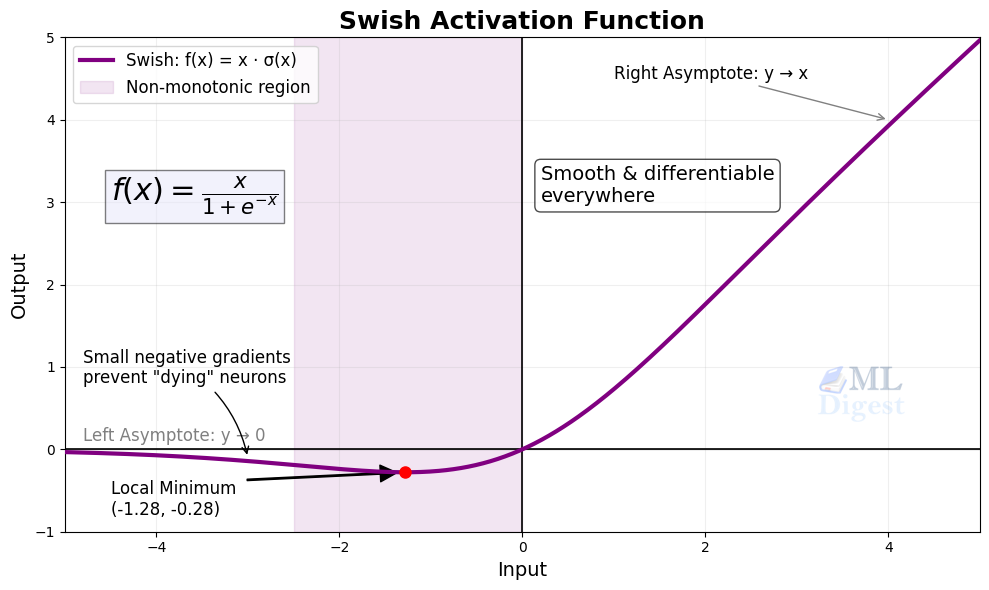
10. Swish (SiLU)
- Formula: $f(x) = x \cdot \sigma(x)$
- Output range: Approx. $(-0.28, \infty)$
Swish, also known as SiLU in many libraries, is a smooth activation that retains small negative values instead of sharply cutting them off like ReLU. In some modern architectures, it performs better than ReLU because the smooth shape can improve optimization.
The tradeoff is that it is slightly more expensive to compute than ReLU, so the best choice still depends on the model and deployment constraints.
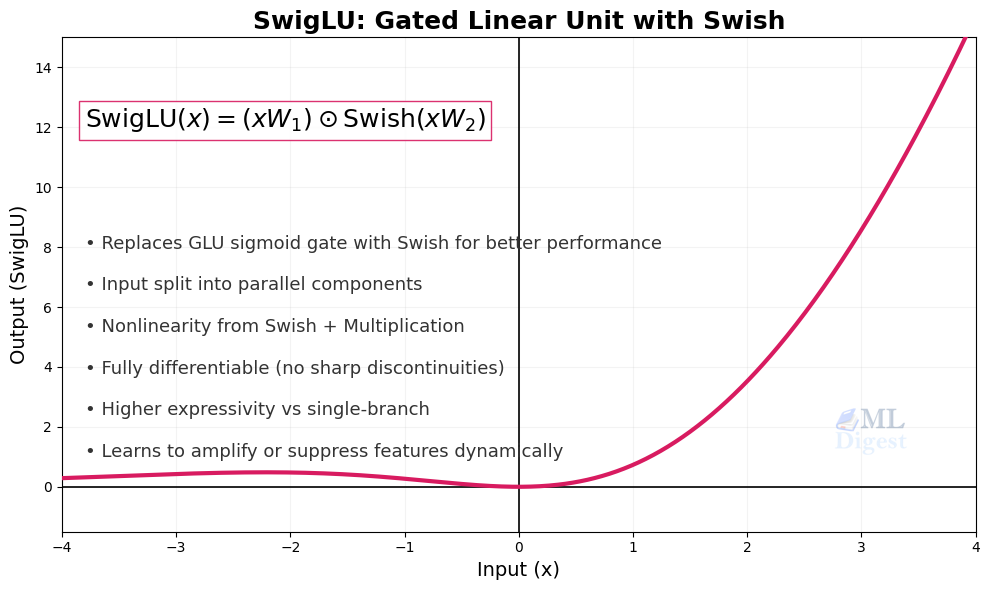
11. SwiGLU
- Formula: $\text{SwiGLU}(xW, xV) = \text{Swish}(xW) \odot (xV)$
SwiGLU is a gated activation used mainly inside transformer feed-forward blocks. Instead of applying a single pointwise nonlinearity to one tensor, it combines a Swish-transformed branch with a second linear branch through elementwise multiplication.
That distinction matters. SwiGLU is better thought of as a feed-forward design pattern than as a drop-in replacement for ReLU in a basic multilayer perceptron. It was popularized by Google’s PaLM and has since been adopted across a wide range of prominent open-source models, including LLaMA, LLaMA 2, LLaMA 3, and Mistral, due to consistent empirical gains over plain GELU or ReLU feed-forward layers.
12. Softplus
- Formula: $f(x) = \ln(1 + e^x)$
- Output range: $(0, \infty)$
Softplus is a smooth approximation of ReLU. It never has a hard corner and always produces positive outputs, which can be useful in settings where the model must predict strictly positive values.
In hidden layers, however, Softplus is less common than ReLU-family activations because it is slower and often does not provide enough practical benefit to justify the extra computation.
How to Choose the Right Activation Function
There is no single best activation for every model, but some rules of thumb are reliable:
- Hidden layers: ReLU is still the default starting point for many feedforward and convolutional networks because it is simple and effective.
- When ReLU causes inactive neurons: Leaky ReLU can be a safer alternative.
- Binary classification output: Sigmoid is a common choice in the final layer.
- Multi-class classification output: Softmax is usually the standard choice.
- Transformer-style architectures: GELU is widely used in transformers and large language models.
- Gated transformer feed-forward blocks: SwiGLU is common in newer large language models, but it is a block-level design choice rather than a simple one-line activation swap.
- Modern deep architectures: Swish, Mish, or related smooth activations may outperform ReLU in some settings, especially when training very deep models.
- If zero-centered negative activations help training: ELU can be worth testing.
- Self-normalizing networks: SELU is useful only when the architecture is designed around it.
- When outputs must stay positive and smooth: Softplus can be useful, especially near the output layer.
The best activation often depends on the task, the model family, and the training setup. In practice, the output layer activation is usually dictated by the learning objective, while hidden-layer activations are chosen based on training stability and empirical performance.
A Practical Selection Framework
If you want a simple decision process rather than a long list of options, use this one:
- Start with the architecture family: For standard MLPs and CNNs, ReLU is still a sensible baseline. For transformers, follow the reference architecture first, which usually means GELU or a gated variant such as SwiGLU.
- Choose the output activation from the prediction type: Binary classification usually points to sigmoid, multi-class classification to softmax, unconstrained regression to a linear output, and strictly positive predictions to something like Softplus when needed.
- Check optimization behavior before swapping activations: If training is unstable, the root cause may be initialization, normalization, learning rate, or loss configuration rather than the activation itself.
- Treat activation changes as experiments, not dogma: Smooth activations such as GELU, Swish, or Mish can help in some settings, but the gain is often architecture-dependent and not guaranteed.
As a rule, copying the activation choice from a strong baseline in the same model family is usually better than inventing a custom combination without a clear reason.
Common Pitfalls and Practical Considerations
Choosing an activation function is not only about the formula. It also affects how a network trains.
- Vanishing gradients:
Sigmoid and tanh can both saturate, meaning their gradients become very small for large-magnitude inputs. In deep networks, this can make learning in early layers painfully slow. - Dying ReLUs:
Some ReLU neurons can get stuck permanently outputting zero. This happens when a neuron’s pre-activation value (the weighted sum z = Wx + b) is consistently negative — often due to poor weight initialization, large learning rate updates that push biases deeply negative, or unlucky gradient updates early in training. Once a neuron is in that state, the gradient through it is also zero, so it receives no update and cannot recover. Careful initialization (such as He initialization), conservative learning rates, or switching to Leaky ReLU can reduce this risk. - Output interpretation:
The activation in the final layer should match the task: - Use sigmoid for binary outputs.
- Use softmax for mutually exclusive classes.
- Use a linear output for many regression tasks.
Using the wrong output activation can make training unstable or cause predictions to be interpreted incorrectly.
- Weight initialization and activation coupling:
Activation choice and weight initialization are closely linked. Using the wrong initialization for a given activation can cause activations to collapse or explode in the first forward pass, before training even begins. As a practical guide: - ReLU and its variants: use He (Kaiming) initialization, which accounts for the fact that ReLU zeroes out roughly half its inputs
- Sigmoid and tanh: use Glorot (Xavier) initialization, which is designed for activations that are approximately linear near zero
- SELU: use LeCun normal initialization, which is required for the self-normalization property to hold
Getting this pairing right is one of the easiest ways to prevent unstable training from the start.
Practical checks during training
When activation choice is hurting a model, the symptoms usually appear early:
- If a large fraction of ReLU activations are exactly zero for long stretches of training, inspect for dying ReLUs.
- If early layers learn very slowly in a deep network, check for saturation, poor initialization, or an activation-loss mismatch.
- If predicted probabilities look badly calibrated or inconsistent with the task, verify the final-layer activation and loss are paired correctly.
- If activation magnitudes explode or collapse across layers, inspect normalization, initialization, and architecture assumptions before blaming the activation alone.
Conclusion
Activation functions matter because they influence both representation power and trainability. They affect what kinds of patterns a network can express, how easily gradients flow, and whether outputs have the right semantics for the task.
The practical takeaway is straightforward: pick the output activation to match the prediction objective, start hidden layers with the standard choice for the model family, and only deviate when training behavior gives you a concrete reason. Activation functions are not a cosmetic detail. They are part of the optimization strategy and part of the model design.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!