Generative Adversarial Networks (GANs) represent one of the most compelling advancements in ML. They hold the promise of generating high-quality content from random inputs, revolutionizing various applications, including image synthesis, video generation, text-to-image conversion, and even drug discovery. This article delves into the basic concepts behind GANs, illustrating their mechanisms and functioning in a way that is accessible for beginners and clear for practitioners.
The Concept of Generative Models
The Concept of Generative Models
Dive into Predictive vs. Generative Models
At the core of GANs lies the concept of generative modeling. Unlike discriminative models, which focus on identifying or classifying data (for example, classifying an image as a cat or dog), generative models are designed to generate new data instances that resemble a given dataset. To visualize this, consider the task of generating images of human faces. A generative model would learn the underlying distribution from a dataset of real human faces and then produce new instances that are indistinguishable from the original images.
Common examples of generative models include:
- Variational Autoencoders (VAEs): These use a probabilistic approach to generate new data points by learning a compressed representation of the input data.
- Recurrent Neural Networks (RNNs): Often used for generating text sequences based on historical context.
- GANs: This method employs a novel adversarial strategy to generate data and is typically more effective at generating high-quality, realistic outputs compared to other generative models.
The GAN Framework
GANs consist of two primary components: the Generator (G) and the Discriminator (D). These two neural networks are trained simultaneously, engaging in a game-theoretic contest where each network tries to outsmart the other.
1. The Generator (G)
The generator is tasked with producing fake data. It takes random noise (usually sampled from a uniform or normal distribution) as input and transforms it into data that resembles the target dataset. The generator’s goal is to synthesize data that is indistinguishable from real data.
In mathematical terms, the generator function can be represented as \( G(z) \), where \( z \) is a random vector (noise) from a prior distribution \( p_z(z) \).
2. The Discriminator (D)
The discriminator’s role is to distinguish between real data and the synthetic data generated by G. It outputs a probability value between 0 and 1, where a value closer to 1 indicates the input data is real, and a value close to 0 indicates it is fake.
The discriminator function is mathematically represented as: \( D(x) \), where \( x \) can be either real data from the training dataset or fake data generated by the generator.
The Adversarial Training Process
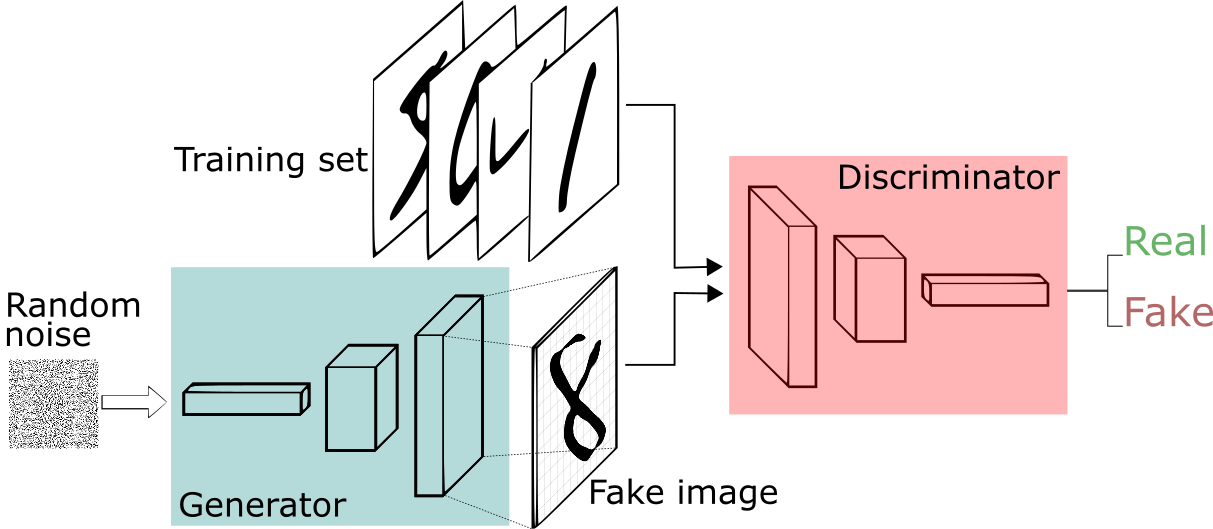
The training of GANs can be framed as a two-player minimax game:
- Maximizing the Discriminator: The discriminator seeks to maximize its ability to correctly classify real and fake data. Its objective is to maximize the following function:
- \[ \max_D \mathbb{E}_{x \sim p_{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log (1 – D(G(z)))] \]
where \(p_{data}\) is the distribution of the real data, and \(p_z\) is the distribution of random noise. - In simpler terms, the discriminator wants to correctly identify real data samples while minimizing the false positives it assigns to the generated (fake) data.
- \[ \max_D \mathbb{E}_{x \sim p_{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log (1 – D(G(z)))] \]
- Minimizing the Generator: The generator, conversely, aims to minimize the discriminator’s success. It does this by trying to generate samples that the discriminator falsely classifies as real:
- \[ \min_G \mathbb{E}_{z \sim p_z(z)} [\log (1 – D(G(z)))] \]
- This adversarial process creates a compelling dynamic: as the generator improves and produces more realistic samples, the discriminator must likewise enhance its accuracy to identify those samples as fake.
The Loss Function
The loss functions for both networks can be summarized as follows:
- For the discriminator, the loss function focuses on both real and generated data:
\[
L_D = -\mathbb{E}{x \sim p{data}(x)} [\log D(x)] – \mathbb{E}_{z \sim p_z(z)} [\log (1 – D(G(z)))]
\]
- For the generator, the focus is solely on maximizing the likelihood of the fake data being classified as real:
\[
L_G = -\mathbb{E}_{z \sim p_z(z)} [\log (D(G(z)))]
\]
- The objective can be mathematically defined as a minimax game:
\[
\min_G \max_D V(D, G) = \mathbb{E}{x \sim p{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 – D(G(z)))],
\]
The Training Loop
Training a GAN involves iterating between training the discriminator and the generator. Generally, the training process can be outlined in the following steps:
- Initialization: Both networks are initialized.
- Sample Real Data: Randomly select a batch of real data samples \( x \) from the training set.
- Generate Fake Data: Feed random noise \( z \) into the generator to produce fake data samples \( G(z) \).
- Train the Discriminator: Update the discriminator’s weights based on its ability to classify real and fake samples. This is done by minimizing the discriminator’s loss function \( L_D \).
- Train the Generator: Update the generator’s weights based on its ability to fool the discriminator into thinking the generated samples are real. This is achieved by minimizing the generator’s loss function \( L_G \).
- Iteration: Steps 2 to 5 are repeated for a predetermined number of iterations or until a certain convergence criterion is met.
- Convergence: Ideally, the GAN reaches a point where the generator produces data indistinguishable from real data, at which point the discriminator’s accuracy drops to 50%.
Challenges in Training GANs
In an ideal scenario, the generator produces data that the discriminator can no longer distinguish from real data. However, achieving this equilibrium is challenging. Several issues can arise during the training process:
- Mode Collapse: This occurs when the generator starts producing limited varieties of outputs rather than a wide range of unique samples. For instance, if a GAN trained on a dataset of images of cats learns to produce only grey tabby cats, it has suffered from mode collapse.
- Vanishing Gradients: If the discriminator becomes too good at its job early in training, it provides little gradient information for the generator to learn from, hampering its ability to improve.
- Instability: The adversarial nature of training GANs can lead to instability, where either the generator or discriminator overly dominates. This results in oscillating or divergent behavior instead of convergence. As one network improves, it can throw off the balance required for joint learning.
- Evaluation Metrics: Evaluating the performance of GANs is challenging due to the subjective nature of generated content. Metrics like Inception Score (IS) and Fréchet Inception Distance (FID) have been proposed, but they do not fully capture the quality of generated samples.
- Overfitting: Both the generator and discriminator can overfit to the training data, leading to poor generalization on unseen samples. Proper regularization and generalization techniques must be employed to address this issue.
- Resource Intensity: Training GANs can be resource-intensive, requiring significant computational power, memory, and time, especially for high-resolution datasets. This can limit their accessibility for smaller research groups or individual practitioners.
Strategies to Improve Stability
Several techniques have been proposed to enhance training stability and effectiveness of GANs:
- Mini-batch Discrimination: Instead of evaluating single samples, mini-batch discrimination allows the discriminator to consider relationships among a batch of inputs, helping to address mode collapse.
- Label Smoothing: Slightly modifying the labels for real data (for instance, changing the label from 1.0 to 0.9) prevents the discriminator from becoming too confident and provides smoother gradients for the generator.
- Feature Matching: Utilizing intermediate representations from the discriminator’s layers can provide valuable insights to the generator, making it easier to produce more realistic outputs.
- Normalizing Networks: Techniques such as Batch Normalization or Layer Normalization can help stabilize training by regulating the input distribution of activations in the network.
Types of GANs
Since their inception, numerous variants of GANs have been developed to address different types of problems and improve upon the original architecture. Here, we summarize several notable GAN architectures:
- Deep Convolutional Generative Adversarial Networks (DCGANs): Introduced by Radford et al. in 2015, DCGANs utilize convolutional neural networks (CNNs) in both the generator and discriminator. This architecture helps produce clearer and more coherent images, making it one of the most popular GAN variations.
- Conditional GANs (cGANs): Conditional GANs extend GANs by conditioning the generation process on additional information, such as class labels or other modalities. This allows for more controlled and specific data generation. For example, a cGAN could generate images of specific categories (like cats or dogs) based on the provided label.
- CycleGAN: CycleGAN, introduced by Zhu et al. in 2017, allows for image-to-image translation without paired examples. For instance, it can convert images of horses into zebras and vice versa, demonstrating coherent style transfer capabilities by enforcing cycle consistency.
- StyleGAN: Developed by NVIDIA, StyleGAN and its successor, StyleGAN2, offer unprecedented control over the generated images’ attributes. The architecture allows mixing and manipulating different image styles at various levels, leading to high-resolution and photorealistic image generation.
- Progressive Growing GANs: Progressive Growing GANs improve training stability and output quality by starting with low-resolution images and progressively increasing the resolution as training progresses. This method prevents issues such as mode collapse and allows the generator to learn detailed structures gradually.
Applications of GANs
The versatility and power of GANs extend across various fields. Below are some noteworthy applications of GANs:
- Image Generation: GANs have been famously used to generate images at high resolutions. One of the popular models, Progressive Growing GAN, enables the synthesis of facial images that can be nearly indistinguishable from real ones. This capability has also fueled the rise of deepfakes, where GANs are used to create hyper-realistic alterations of video content.
- Superresolution Imaging: GANs can enhance the resolution of low-quality images. Methods like Super Resolution GAN (SRGAN) can generate high-resolution images from low-resolution inputs, making it instrumental in medical imaging and satellite imagery.
- Data Augmentation: In domains where data is scarce (such as medical imaging), GANs can synthesize new training examples to augment existing datasets, allowing for better generalization in machine learning models. This is especially useful in training convolutional neural networks for tasks like object detection.
- Artistic Style Transfer: GANs can also be employed in style transfer applications, allowing the synthesis of images that combine the content of one image with the style of another. This creates unique pieces of art that blend various artistic styles seamlessly.
CycleGANs and Pix2Pix models (a type of conditional GAN) have demonstrated success in translating images from one domain to another. Applications include turning sketches into photographs, changing seasons in landscape images, and even altering facial expressions. - Text and Music Generation: Beyond visual data, GANs can be utilized in generating realistic sequences of text or music. For instance, models can generate melodies or lyrics that adhere to certain styles or genres. This opens pathways for creativity in the music industry or automated content generation.
- Video Generation: In addition to static images, GANs can generate video clips. Research has shown promising results in synthesizing coherent video sequences based on textual descriptions or low-resolution frames.
Conclusion
Generative Adversarial Networks embody a powerful framework for data generation, leveraging the interplay of two neural networks in an adversarial manner. Though the training process is sophisticated and often requires careful balancing, the versatility and potential applications of GANs extend into numerous domains.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!