Imagine building a city: at first, you lay simple roads and bridges, but as the population grows and needs diversify, you add highways, tunnels, and smart traffic systems. The evolution of large language model (LLM) architectures follows a similar journey. Starting with the foundational Transformer—an elegant design that replaced old, slow routes with parallel self-attention—the field has rapidly expanded, layering new pathways for efficiency, adaptability, and scale.
Today, LLMs encompass a diverse range of innovations, including Multi-modal systems that integrate vision and audio, retrieval-augmented models for factual grounding, mixture-of-experts (MoE) architectures for efficient scaling, and emerging state-space hybrids designed for ultra-long context handling.
This articled provides a concept-driven exploration of how these architectures have evolved, highlighting the key breakthroughs and their practical implications for modern AI systems.
1. Why Architectures Keep Evolving
Scaling raw Transformers (more parameters + more tokens + more compute) worked extremely well early on, but pain points emerged:
- Inefficiency: Quadratic attention cost in sequence length (O(n²)).
- Long context: Vanilla self-attention struggles with >4K–8K tokens efficiently.
- Data/compute balance: Over-sized models under-trained (data bottleneck) waste compute.
- Specialization vs generalization: Single dense models vs sparsely activated expert networks.
- Multi-modality & tool use: Need to ingest images, audio, video, documents, APIs, and memory stores.
- Alignment & safety: Architecture + training strategies needed to reduce harmful, hallucinated, or ungrounded outputs.
- Edge deployment: Demand for small, efficient models (quantization, distillation, parameter sharing).
Architectural innovations target one or more of: efficiency, capacity, adaptability, context length, modality breadth, and controllability.
2. Baseline: The Original Transformer (Vaswani et al., 2017)
Core idea: Replace recurrence with parallelizable self-attention layers (queries, keys, values) + positional encodings.
Blocks:
- Encoder: Stacked layers (Multi-Head Attention + Feed Forward) with residual + layer norm.
- Decoder: Adds encoder–decoder cross-attention + causal masking for autoregressive generation.
Key properties:
- Full pairwise token interactions (rich context modeling).
- Positional encoding (sinusoidal) baked in early; later replaced/improved (learned, RoPE, ALiBi).
Limitation: Quadratic scaling with sequence length both in memory and compute.
3. Diverging Families of Transformer Use
| Family | Architectural Emphasis | Typical Use |
|---|---|---|
| Encoder-only | Bidirectional masked attention | Classification, embeddings, retrieval |
| Decoder-only | Causal (left-to-right) attention | Autoregressive generation (chat, code) |
| Encoder–Decoder | Full encoder + causal decoder with cross-attention | Translation, abstractive summarization, seq2seq tasks |
| Sparse / Efficient | Modified attention patterns | Long documents, resource-limited inference |
| Mixture-of-Experts (MoE) | Conditional parameter routing | Scaling capacity without proportional compute |
| Retrieval-Augmented | External memory / vector DB integration | Fact grounding, long-term memory |
| Multi-Modal | Multi-branch encoders fused into language decoder | Vision-language, speech, generalist agents |
| State-Space / Hybrid | SSM + attention combinations | Ultra-long context, linear scaling |
4. Encoder-Only Evolution
- BERT (2018): Masked Language Modeling (MLM) + Next Sentence Prediction. Fully bidirectional.
- RoBERTa: Removes NSP, trains longer, larger batch; more data-centric improvement than architectural.
- ALBERT: Parameter sharing across layers + factorized embedding to reduce memory.
- DistilBERT: Knowledge distillation to produce lighter models.
- XLNet: Permutation language modeling; hybridization of AR + AE; more complex training, less prevalent now.
- Longformer / BigBird: Sparse attention (local + global + random) to extend sequence length efficiently.
- Modern usage shift: Many tasks migrated to decoder-only LLM prompting; encoder-only models remain strong for fast embeddings & retrieval (e.g., sentence-transformers, GTE, Voyage, Cohere embed).
Architectural themes: Parameter sharing (ALBERT), sparse patterns (Longformer), permutation factorization (XLNet), distillation.
5. Decoder-Only (GPT Lineage and Beyond)
GPT (2018): Causal decoder stack without encoder; simpler pipeline.
GPT-2 (2019): Larger scale (up to 1.5B params), multi-head attention, learned positional embeddings, demonstrates emergent capabilities.
GPT-3 (2020): 175B dense parameters; introduced the era of few-shot prompting, highlighting scaling laws.
InstructGPT / ChatGPT (2022): Architectural base similar to GPT-3; difference comes from instruction tuning + RLHF (Reinforcement Learning from Human Feedback)—not structural changes but training/ alignment stack additions.
GPT-4 (2023) (details opaque): Believed to involve mixture techniques, multi-modal extensions, improved safety scaffolding.
Design patterns adopted widely:
- Layer normalization placement changes (Pre-LN vs Post-LN; modern trend: Pre-LN for stable deep training).
- Multi-Query / Grouped Query Attention (MQA/GQA) to reduce KV cache size at inference.
- Rotary Position Embeddings (RoPE) for improved extrapolation + continuous relative positioning.
- RMSNorm instead of LayerNorm in some open models (lighter, stable).
6. Encoder–Decoder Maintained Relevance
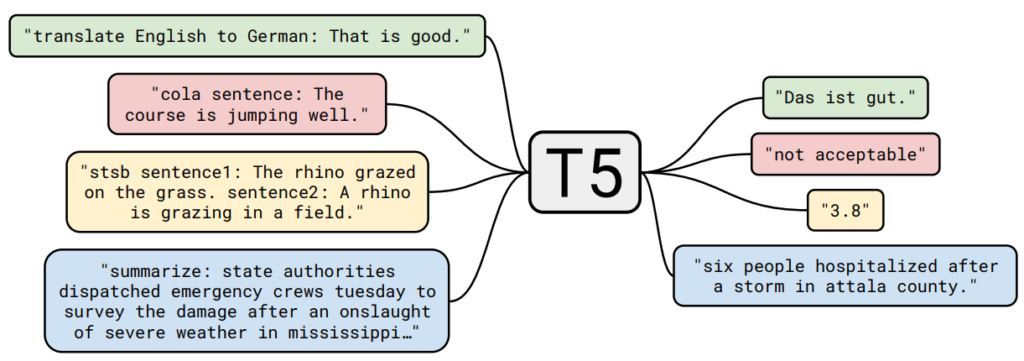
T5 (2020): Unified text-to-text framing; uses relative positional bias, large-scale span corruption objective.
BART: Denoising autoencoder (random noise + reconstruction) bridging encoder richness with decoder generation.
FLAN / Instruction Tuning: Applies broad mixture of supervised tasks to base architectures (e.g., FLAN-T5) for better zero-shot generalization.
Why still used? Cross-attention can more efficiently fuse multi-modal or structured sources; still strong for tasks requiring explicit input/output transformation (translation, summarization pipelines).
7. Efficiency & Sparse Attention Innovations
| Technique | Idea | Benefit |
|---|---|---|
| Sparse / Block / Local | Restrict attention to windows + select global tokens | Longer sequences with sub-quadratic cost |
| Reformer | LSH attention + reversible layers | Memory + compute reduction |
| Performer | FAVOR+ kernel approximations for linear attention | O(n) scaling in sequence length |
| Linformer | Low-rank projection of K/V | Approximate attention, reduced memory |
| FlashAttention | IO-aware fused kernels | Large speedups + less GPU memory pressure |
| Multi-Query / Grouped Query | Share K/V across heads | Smaller inference KV cache |
| Speculative Decoding / Medusa | Draft model or parallel heads propose tokens | Faster generation wall-clock |
These are often composable; modern open-source models (e.g., Mistral) integrate FlashAttention + RoPE + sliding window.
8. Long Context Strategies
- Segment-level recurrence: Transformer-XL caches hidden states across segments.
- Relative position embeddings: Better generalization beyond trained length (T5 bias, ALiBi, RoPE).
- Memory compression / selection: Retain salient tokens (e.g., Longformer global tokens, selective memory).
- Sliding window + dilation: Patterns preserve locality while injecting periodic global mixing.
- Retrieval augmentation: Offload long-term storage to vector DB (RAG) circumventing sequence length entirely.
- Ring / Distributed Attention (2024–2025): Partition sequence across devices for extremely long contexts (>1M tokens research prototypes).
- State Space Models (SSMs) like Mamba: Linear-time sequence processing with implicit long-range dependencies without explicit pairwise attention.
9. Scaling Laws and Data/Compute Balance
Early intuition: “Bigger is better.” Kaplan et al. (OpenAI) showed predictable loss improvements vs model size, data, and compute.
Chinchilla (DeepMind, 2022): Key insight—optimal training requires sufficiently scaling data with parameters; many large models were under-trained. Result: Smaller (70B) models trained on more tokens can outperform larger but under-trained ones.
Impact: Architectural focus shifted from sheer parameter count to effective utilization (token budgets, mixture routing, data diversity).
10. Mixture-of-Experts (MoE) Evolution
| Model | Routing Style | Notable Trait |
|---|---|---|
| GShard (2020) | Learned gating, distributed experts | Massive parallelization across TPU pods |
| Switch Transformer (2021) | Single expert per token (Top-1) | Simpler, reduces routing overhead |
| GLaM (2021) | Top-2 gating | Sparse activation, high quality per FLOP |
| Mixtral (2023–2024) | Top-2 gating; 8×7B / 8×22B experts | Strong open MoE, efficient inference vs dense |
| DeepSeek-MoE (2024) | Fine-grained expert partitioning | Aggressive efficiency; cost-optimized training |
| DBRX (2024) | 16 experts, improved load balancing | High throughput + quality combination |
Why MoE? Increase representational capacity without linearly scaling per-token compute. Only active experts contribute forward pass.
Challenges: Load balancing, expert collapse, communication overhead, memory fragmentation; improved by auxiliary loss, router Z-loss, capacity constraints.
11. Parameter Efficiency & Adaptation
| Technique | Idea | Use Case |
|---|---|---|
| Adapters | Insert small bottleneck MLP modules | Task adaptation without full fine-tune |
| Prefix / P-Tuning | Learn virtual tokens prepended to input | Lightweight steering of generation |
| LoRA | Low-rank updates to weight matrices | Memory-efficient fine-tuning on consumer GPUs |
| Q-LoRA | Quantized base (4-bit) + LoRA on top | Further reduces VRAM; democratizes fine-tuning |
| Delta / Diff tuning | Store only changes from base | Versioning multiple task adaptations |
These do not fundamentally alter core architecture; they wrap or partially replace layers to update fewer parameters.
12. Quantization & Compression Trends
Progression: 16-bit → 8-bit → 4-bit (QLoRA) → 3-bit, 2-bit, experimental 1-bit (research 2025, e.g., 1-bit LLM training studies).
Techniques: Post-training quantization, quantization-aware training, mixed precision, activation quantization, KV cache quantization.
Goal: Maintain accuracy while shrinking memory & increasing tokens/sec throughput; essential for edge and on-device AI.
13. Alignment & Reinforcement Layers
Architecture mostly unchanged; training pipeline evolved:
- Supervised fine-tuning (SFT) on instruction pairs.
- RLHF: Reward model + PPO (or variants) to optimize helpfulness/harmlessness.
- Constitutional AI (Anthropic): Rule-based self-critique (reduces reliance on human preference data).
- Direct Preference Optimization (DPO) / RRHF: Simplified objective without full RL loop.
Structural adjuncts: Tool / function calling head (structured output formats), system prompt scaffolding, safety filters integrated pre/post decoding.
14. Multi-Modal Expansion
| Component | Function | Example Models |
|---|---|---|
| Vision Encoder | Convert image/video to embeddings | CLIP, ViT, EVA |
| Fusion Layer | Project vision embeddings into language token space | Flamingo, BLIP-2, LLaVA |
| Audio Front-End | Spectrogram or raw waveform encoding | Whisper, SpeechT5 |
| Cross-Attention | Decoder attends to modality embeddings | Many VLMs (Vision-Language Models) |
| Unified Tokenization | Convert modalities to token-like units | Gemini 1.5, GPT-4o style systems |
Recent trend: Unified sequence processing of mixed modality tokens (images chunked into patches, audio into frames) using mostly standard decoder blocks + minor modality adapters.
15. Retrieval-Augmented Generation (RAG) & Memory Architectures
RETRO (DeepMind): Adds retrieved chunks into attention context before prediction—explicit conditioning.
Vector DB + LLM (Generic RAG):
- Step 1: Embed query.
- Step 2: Nearest neighbor retrieval.
- Step 3: Inject retrieved text into prompt context.
Architectural points: Model may include specialized retrieval tokens, gating, or separate encoder for queries. Core attention unchanged but receives externally curated context (effectively increases usable context without increasing raw attention window).
Memory Direction: Persistent structured memory stores (JSON / SQL / graph retrieval) plus “toolformer” style connectors.
16. Structured Outputs & Tool Use
- Function calling / tool use: Extra logits over a function schema token set, enabling the model to emit JSON-like tuples.
- Planning modules: Multi-pass decoding (draft → critique → final) leveraging internal chain-of-thought scaffolds.
- Agent frameworks wrap base architecture rather than changing its internals.
Architecture adaptation minimal (often just special tokens + system prompts + output parsers).
17. Recent Notable Models & Architectural Traits
| Model | Year | Key Architectural / Training Traits |
|---|---|---|
| LLaMA 2/3 | 2023–2025 | Efficient scaling, grouped-query attention, RoPE, open weighting philosophy |
| Mistral 7B / Mixtral MoE | 2023–2025 | Sliding window attention + FlashAttention + MoE (Mixtral) for sparse capacity |
| Gemini 1.5 | 2024–2025 | Unified multi-modal token space, long context (over 1M tokens claims) |
| Claude 3.5 | 2024–2025 | Strong constitutional alignment + large context + tool integration |
| Qwen2 | 2024–2025 | Versatile multilingual + multi-modal adapters; efficient inference focus |
| DeepSeek | 2024–2025 | Aggressive cost-efficient training, MoE + quantization optimizations |
| Grok (xAI) | 2024–2025 | Real-time retrieval integration (up-to-date context) |
| DBRX | 2024 | MoE with improved expert load balancing + throughput optimization |
| Phi-2 / Phi-3 | 2023–2025 | Small model series leveraging high-quality synthetic data curation |
| Mamba-based prototypes | 2024–2025 | SSM + attention hybrids for extreme sequence lengths |
Common thread: Efficient attention variants (FlashAttention), position handling ( ALiBi/RoPE adjustments), smaller VRAM footprints (8-bit/4-bit), modular multi-modal ingest.
18. Positional & Context Extensions
| Method | Principle | Outcome |
|---|---|---|
| Sinusoidal | Fixed trigonometric basis | Simple but poor extrapolation |
| Learned Absolute | Embedding vector per position | Tied to max length |
| Relative Bias (T5) | Learn distance-based bias matrix | Better generalization |
| ALiBi | Add linear distance penalty to attention logits | Scales to longer lengths gracefully |
| RoPE | Rotates Q/K in complex plane by position | Robust extrapolation; widely adopted |
| Long RoPE Scaling | Rescales frequencies to extend context | Enables 32K–512K token windows |
| Dynamic Position Interpolation | Interpolate embeddings for unseen lengths | Avoid retraining at new lengths |
19. Inference-Time Efficiency Tricks
- KV Cache Quantization / Compression: Reduce memory footprint (e.g., 16-bit → 8/4-bit) enabling higher batch concurrency.
- Multi-Query / Grouped Query Attention (MQA/GQA): Share K/V projections across many heads; shrinks cache from H separate matrices to 1 or few.
- FlashAttention v2 / v3 fused kernels: IO-aware tiling minimizes reads/writes; large speedups without algorithmic change.
- Speculative Decoding (draft model + verifier): A smaller draft proposes multiple tokens; main model accepts/rejects batches (wall clock reduction).
- Parallel decoding heads (Medusa): Predict branches of future tokens; accept longest valid prefix.
- Early-exit strategies: Confidence thresholds to stop further layers (research/edge scenarios).
- Batch Prefill + continuous streaming: Overlap prefill of new requests with decoding of existing ones (scheduler improvements).
- PagedAttention (e.g., vLLM): Virtual memory paging of KV cache segments allowing fragmentation-free reuse and high throughput for many concurrent sessions.
- Continuous Batching: Dynamically merges incoming requests mid-generation; reduces GPU idle cycles; requires uniform layer timing.
- Prefix Caching / Prompt Reuse: Store computed KV for common system + instruction prefixes so that new sessions start directly at first user token.
- Tensor Parallelism: Split individual matrix multiplications across devices (horizontal shard); increases cross-device bandwidth demands.
- Pipeline Parallelism: Partition layers into stages across devices; improves memory distribution but introduces bubble latency and requires micro-batching.
- Context Parallelism: Shard sequence dimension (tokens) across devices enabling extreme context lengths; demands efficient all-gather of attention outputs.
- Combined Strategies: Real systems mix tensor + pipeline + context parallelism plus paged KV for balanced memory, latency, and throughput.
System-Level Trade-Off Snapshot:
- PagedAttention → High concurrency; slight per-request latency overhead due to page handling.
- Continuous batching → Maximizes throughput; complicates deterministic timing and fairness.
- Prefix caching → Large gains for repeated long prompts; storage and invalidation complexity.
- Tensor parallel → Scales model width; susceptible to communication bottlenecks at high head counts.
- Pipeline parallel → Memory relief; latency bubble unless many micro-batches.
- Context parallel → Enables million-token experiments; increased synchronization cost.
20. Safety & Moderation Layers (Architectural Adjuncts)
Not core block changes; wrappers:
- Input classifiers (prompt screening).
- Output moderation (post-generation filtering with secondary model or rule engine).
- Chain-of-thought redaction (internal reasoning hidden, final answer shown).
- Tool gating (authorize function calls based on policy model).
Emerging trend: Multi-model safety sandwich pipelines.
21. Architectural Differences: Concise Summary
Bullet comparison of major evolutionary deltas:
- Transformer → Introduced full self-attention, removed recurrence.
- BERT (Encoder-only) → Bidirectional masked attention for deep semantic representations.
- GPT (Decoder-only) → Simplicity for autoregressive scaling; fosters in-context learning.
- T5 / BART (Encoder–Decoder) → Cross-attention fusion; robust for structured transformations.
- Sparse / Efficient (Longformer, BigBird, Reformer, Performer) → Adjust attention pattern or approximate kernels for longer sequences.
- Transformer-XL → Segment-level recurrence for extended context.
- FlashAttention → Kernel-level optimization; speeds training/inference without altering math semantics.
- MoE (Switch, Mixtral, DeepSeek, DBRX) → Conditional routing boosting capacity per FLOP.
- Chinchilla Insight → Data/parameter ratio optimization; architectural planning around token budgets.
- LoRA / Q-LoRA / Adapters (PEFT) → Fine-tuning compression; additive low-rank updates.
- Retrieval-Augmented (RETRO, RAG systems) → External memory integration instead of brute-force context window scaling.
- Multi-Modal (Flamingo, BLIP-2, Gemini) → Modality encoders + fusion into language backbone.
- SSM Hybrids (Mamba) → Linear-time sequence handling + selective memory.
22. Emerging Directions
- Hierarchical Attention: Multi-scale token grouping to reduce complexity.
- Benefits: Sub-quadratic interaction; semantic abstraction layers.
- Trade-Offs: Design complexity, potential loss of fine-grained token interactions.
- Neural Caches: Persistent latent memory outside raw sequence.
- Benefits: Longer-term knowledge retention, lower prompt costs.
- Trade-Offs: Staleness management, cache eviction strategy, privacy concerns.
- Hybrid Attention + SSM: Dynamic selection of mechanism per layer.
- Benefits: Linear scaling for long-range + precise local reasoning.
- Trade-Offs: Training instability, immature tooling, harder interpretability.
- On-Device Co-Processors: Architecture choices driven by specialized inference silicon (KV cache oriented layouts, sparsity accelerators).
- Benefits: Lower latency, energy efficiency, edge privacy.
- Trade-Offs: Hardware fragmentation, vendor lock-in, custom kernel maintenance.
- Automatic Tool Graph Construction: Model internally builds dependency graph of tools / APIs.
- Benefits: Autonomous orchestration, reduced manual prompt engineering.
- Trade-Offs: Reliability of tool selection, error recovery complexity, governance controls.
Risk Matrix (High-Level):
- Instability Risk: Hybrid SSM > Hierarchical Attention > Neural Caches.
- Operational Complexity: Automatic Tool Graph > Hybrid SSM > On-Device Co-Processors.
- Governance/Safety Challenge: Neural Caches (persistent data), Automatic Tool Graph (uncontrolled calls).
23. Practical Mental Model for Choosing an Architecture
| Goal | Preferred Base | Add-Ons |
|---|---|---|
| Fast embeddings | Encoder-only | Distillation, optimized pooling |
| General chat / reasoning | Decoder-only | Instruction tuning, RLHF, safety layers |
| Translation / summarization | Encoder–Decoder | Task-specific pretraining (span corruption) |
| Very long documents | Sparse / Hybrid / RAG | Retrieval index, memory selection |
| Cost-efficient scale | MoE decoder | Router balancing, expert load tuning |
| Multi-modal assistant | Decoder backbone + modality encoders | Cross-attention fusion, unified token adapters |
Executive Model Selection Cheat Sheet
| Business Goal | Recommended Core | Essential Add-Ons | Key Trade-Offs |
|---|---|---|---|
| Fast time-to-market general assistant | Mature dense decoder (LLaMA/Mistral class) | Instruction tuning + safety wrapper | Higher serving cost vs sparse MoE |
| Lowest cost per token at scale | MoE decoder (Mixtral / DBRX style) | Robust routing metrics + load balancing | Increased infra complexity (expert placement) |
| High factual reliability / compliance | Dense decoder + Retrieval layer (RAG) | Quality embedding model + re-ranking + audit logs | Extra latency; dependency on index freshness |
| Extreme long document analytics | Hybrid (Sparse + Retrieval + SSM research) | Positional scaling + memory store | Tooling immaturity; experimental stability |
| Edge / on-device deployment | Small dense (Phi, distilled) | Quantization + LoRA specialization | Capability ceiling vs large models |
| Rapid multilingual + multi-modal expansion | Decoder + modality encoders + adapters | Cross-attention fusion + tokenizer alignment | Higher integration effort; modality QA overhead |
| Strategic IP retention (private data) | Dense or MoE with secure on-prem retrieval | Encrypted index + access controls | Higher operational/security cost |
Executive Guidance:
- Prefer dense models for simplicity unless serving economics mandate MoE.
- Add retrieval when factual accuracy or up-to-date grounding is a core KPI.
- Use parameter-efficient fine-tuning (LoRA/Q-LoRA) to create product variants without branching base weights.
- Treat hybrid SSM approaches as exploratory R&D for future ultra-long context roadmaps.
Key Takeaways
- Core Transformer block remains central; evolution is increasingly around it (routing, efficiency kernels, retrieval, adapters).
- Scaling is no longer “just bigger”—it’s smarter: data ratios, sparse activation, high-quality synthetic training corpora.
- Long context solved via combination: improved positional schemes + retrieval + emerging SSM hybrids.
- Multi-modality favors modular front-ends projecting into a common language latent space.
- Efficient fine-tuning (LoRA, Q-LoRA) democratizes specialization; architecture flattening into universal base + lightweight deltas.
- MoE enables high capacity per dollar but demands careful routing + infra optimization.
- Retrieval and tool integration shift emphasis from memorization to orchestration.
Final Thought
Architectural progress in LLMs has shifted from inventing a new monolith to engineering a flexible ecosystem—where attention, routing, memory, retrieval, and modality fusion compose into adaptable intelligent systems. Understanding these layers lets practitioners design solutions that are cost-efficient, scalable, and grounded.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!