Imagine a personal curator who sifts through millions of tweets, understands your evolving interests, and assembles a tailored feed. That is the goal of Twitter’s (now X) “For You” timeline.
When Twitter partially open sourced components of its recommendation stack, it provided a window into how this curator operates. It is not a single monolithic algorithm. It is a sophisticated, multi-stage, distributed pipeline balancing relevance, discovery, safety, and diversity under tight latency constraints.
Let’s walk through this process, starting with the big picture and then diving into the nitty-gritty details of each stage.
TL;DR
Your “For You” timeline is produced by a funnel: (1) Gather ~1500 candidate tweets from accounts you follow and related communities (follow graph, engagement graph, embedding clusters). (2) Score each candidate with a multi-task neural ranker predicting engagement probabilities. (3) Apply post-ranking rules for quality, safety, diversity, and freshness, then blend with ads and other modules. The system optimizes engagement while limiting fatigue and negative experiences via heuristics and learned models. Exploration vs exploitation trade-offs ensure occasional novel content beyond your usual interests.
Why Recommendation Quality Matters
- User experience: Reduces cognitive load by prioritizing high-signal content.
- Platform health: Drives retention, session length, creator reach, and ad revenue.
- Content discovery: Surfaces new authors and topics beyond the echo chamber of only followed accounts.
- Safety and trust: Filters policy-violating, spammy, or repetitive content and attenuates fatigue.
Problem Framing: Defining the “Best” Timeline
Before building a system, we must clearly define its goal. For a recommendation engine, the goal is to create the “best” possible timeline for each user. But what does “best” actually mean?
Imagine our personal curator again. Their job is not just to find tweets you will enjoy, but to create a balanced and engaging experience. They need to weigh several competing factors:
- Maximize the Good: Find tweets you are likely to interact with positively. This includes actions like liking, replying, retweeting, or even just spending a few extra seconds reading a tweet (dwell time).
- Minimize the Bad: Avoid showing you content that leads to negative experiences. This includes actions like reporting a tweet, blocking an author, or seeing too many repetitive or uninteresting posts that cause you to close the app (fatigue).
- Work Under Pressure: The curator has to do all of this in the blink of an eye, every single time you refresh your feed. This is the latency constraint.
- Keep it Fresh: They must also ensure the timeline is not an echo chamber. It should introduce you to new topics and creators, balancing familiar content (exploitation) with new discoveries (exploration). This is the diversity constraint.
In machine learning terms, this is framed as a multi-objective optimization problem. The system’s goal is to select and rank a small list of tweets that maximizes a “utility score.” This score is a calculated value that rewards predicted positive engagement (likes, replies) while penalizing predicted negative outcomes (reports, mutes) and applying rules to ensure diversity and freshness.
Intuitive High-Level View: A Three-Stage Funnel
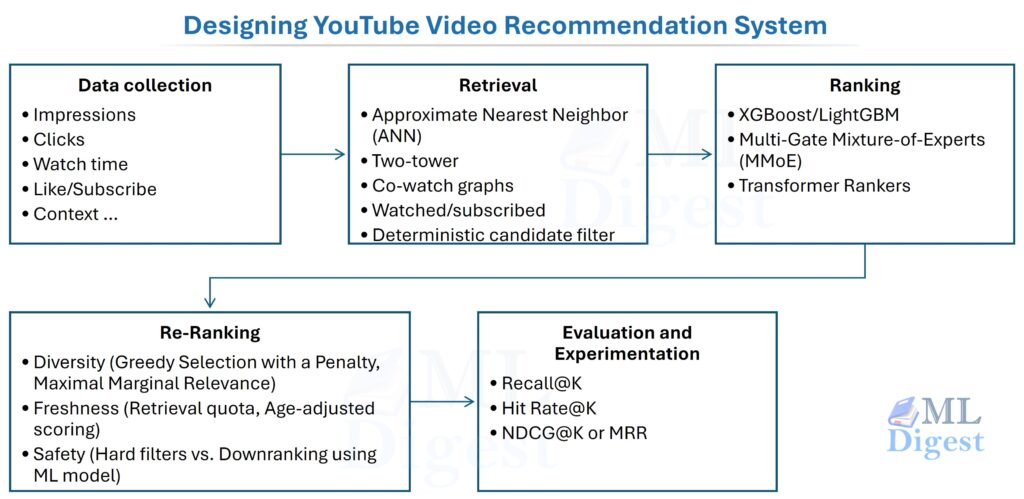
At its core, the Twitter recommendation system is a giant funnel, orchestrated by a service called Home Mixer. Built on a custom Scala framework, Home Mixer is the backbone that connects different candidate sources, scoring functions, and filters to construct your timeline. It starts with a massive pool of candidates and progressively filters and ranks them until only a few hundred of the “best” tweets are left to display.
The Tweet Refinery: Imagine a massive refinery. At the top, a huge hopper is filled with raw, unsorted tweets—hundreds of millions of them. This is the Candidate Sourcing stage. Then, these tweets go through a series of complex sorting and grading machines, where each one is scored and ranked based on its potential value to you. This is the Ranking stage. Finally, the highest-graded tweets are passed through a final quality control check, where any unwanted or repetitive content is filtered out before being delivered. This is the Filtering & Serving stage.
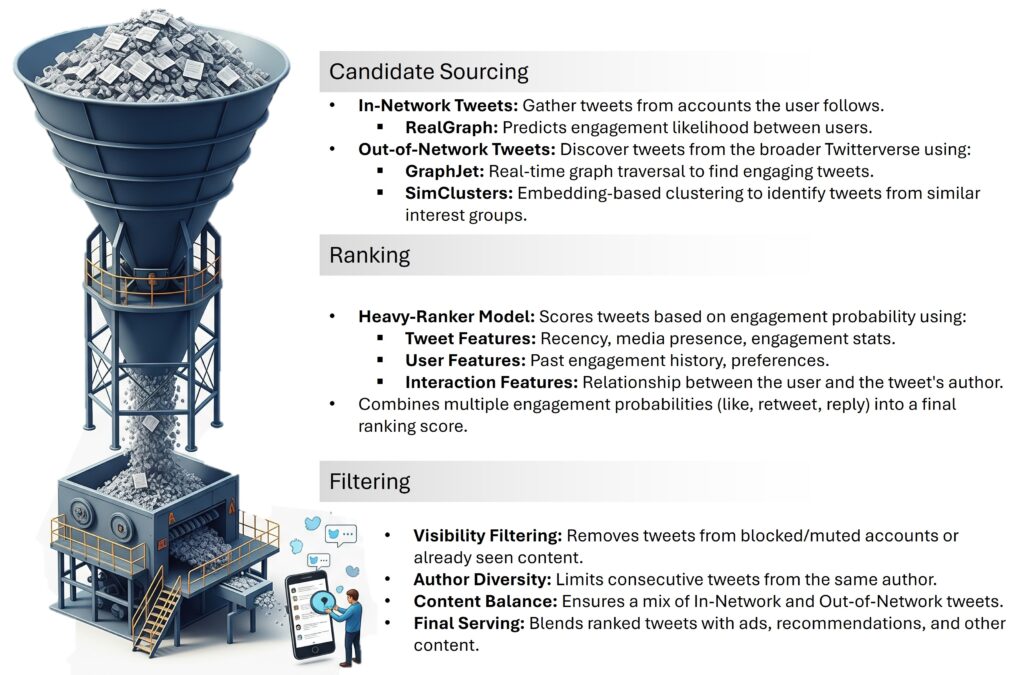
- Candidate Sourcing: The system begins by compiling a collection of potential tweets tailored to you. On average, the “For You” timeline is evenly split, featuring 50% tweets from accounts you follow (In-Network) and 50% from accounts you don’t follow (Out-of-Network). However, this ratio can vary depending on individual user behavior. This initial pool typically consists of around 1500 tweets, sourced from two primary categories:
- In-Network: Tweets from people you explicitly follow.
- Out-of-Network: Tweets from the wider Twitterverse that the algorithm thinks you might like. This is where the real discovery happens, finding new accounts and content.
- Ranking: Taking the ~1500 candidate tweets, a powerful machine learning model scores each one. The score represents the probability that you will engage with a tweet in a meaningful way (like, reply, retweet, etc.). This model, 48M parameter neural network, is the brain of the operation. It considers thousands of features, such as:
- About the Tweet: Is it recent? Does it have a video or image? How many likes and retweets does it already have?
- About You: What topics have you engaged with in the past? What kind of tweets do you usually spend time on?
- About the Author & You: How often do you interact with this author? Do you have mutual connections?
- Filtering and Serving: After ranking, a final set of rules and heuristics are applied. This stage is like the editorial review. It ensures you don’t see:
- Tweets from accounts you’ve muted or blocked.
- Content you’ve already seen.
- Too many tweets from the same person in a row.
- NSFW (Not Safe for Work) or other content that violates policies.
The remaining tweets, now ranked and filtered, are what finally appear in your “For You” timeline.
Diving Deeper: The Technical “How”
Now that we have the intuitive overview, let’s put on our engineering hats and look at the machinery inside each stage.
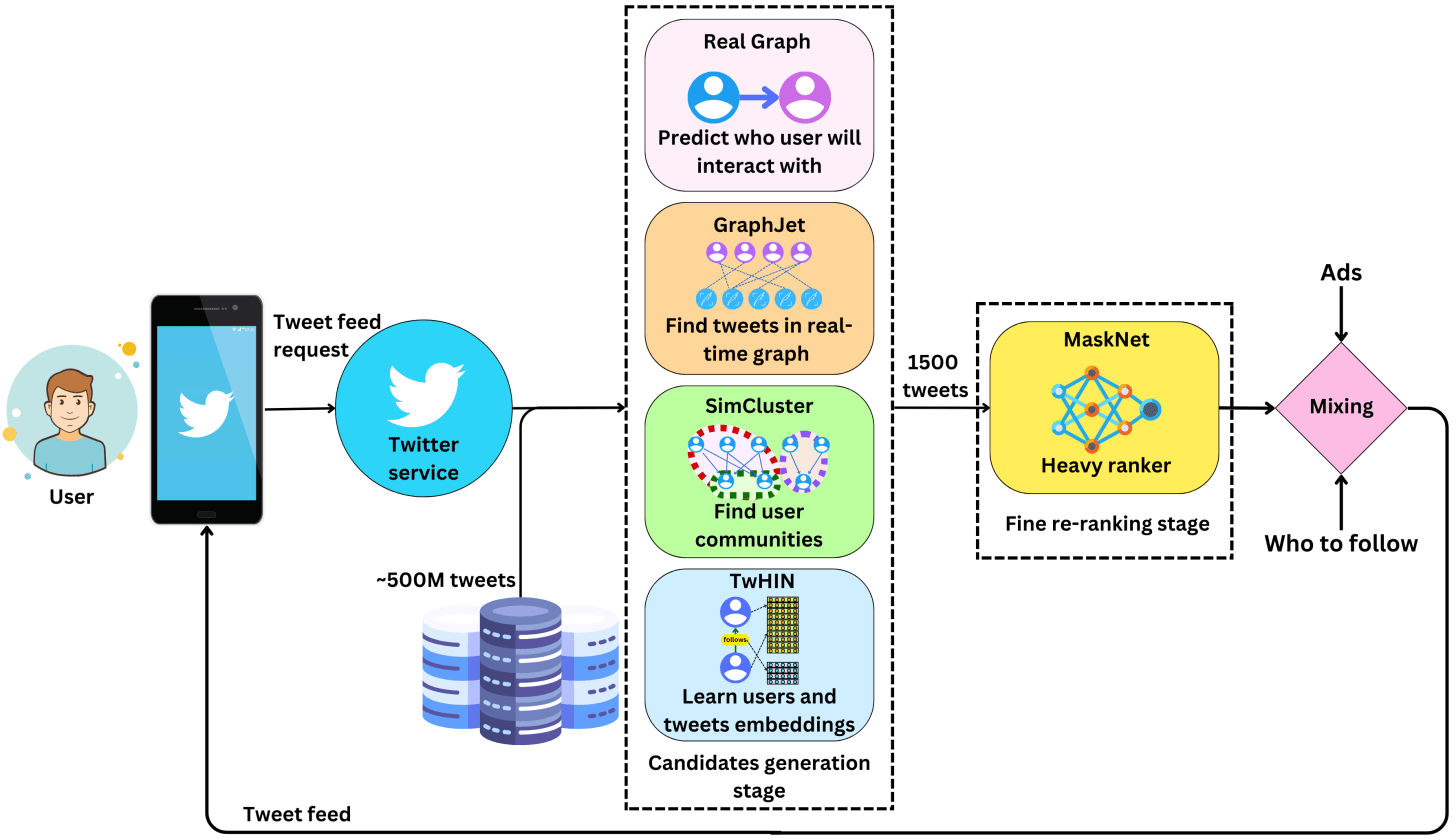
Stage 1: Candidate Sourcing — Casting a Wide, Intelligent Net
The first challenge is to reduce the firehose of millions of tweets published every minute to a manageable pool of roughly 1500 candidates. This is not a random sample; it is a highly targeted selection from two main pools: In-Network and Out-of-Network.
A. Social Graph (In-Network and Out-of-Network)
This is the digital equivalent of “word of mouth.” Think of the social graph as the network of explicit connections you have built: who you follow, and who follows you. The system uses this graph to find relevant content, much like getting a recommendation from a friend.
- For In-Network tweets, it uses a model called RealGraph, which continuously calculates the likelihood of engagement between you and another user. The higher the RealGraph score between you and an author you follow, the more likely their tweets are to be included.
- For Out-of-Network tweets, the system traverses the graph of engagements to find content beyond your immediate circle, the “second-degree” network. It asks questions like, “What tweets did the people I follow recently engage with?” This graph traversal is powered by GraphJet, a real-time graph processing engine that serves about 15% of the timeline’s tweets. It is a powerful way to discover content that is already vetted by people with similar tastes.
Imagine your social circle as a spiderweb. You are at the center. RealGraph strengthens the threads to the people you interact with most. GraphJet then “crawls” along these strong threads to see what they are connected to, bringing back interesting items you might have missed.
B. Embedding Spaces (SimClusters): Finding Your “Content Twin”
This is where the system moves from explicit connections to implicit similarities. It is the primary method for discovering novel content and is arguably the most powerful part of the sourcing stage.
The core technology here is SimClusters, a system that groups users and tweets into 145,000 “communities” or clusters based on shared interests. These are not manually defined groups but are discovered algorithmically by analyzing user engagement patterns. A cluster might represent “fans of generative art,” “data science practitioners,” or “Formula 1 enthusiasts.”
Here is how it works:
- Representation: Both you and every tweet are represented as a vector (a list of numbers) that indicates your affinity for each of the 145,000 clusters. This vector is your “embedding” — your unique location in Twitter’s vast “interest space.”
- Similarity Search: To find Out-of-Network tweets, the system looks for tweets whose embedding vectors are “close” to your user embedding vector. This geometric closeness signifies a high probability of shared interest.
This is the largest source of Out-of-Network tweets because it can connect you with content from anyone, regardless of your social graph, based purely on the merit and topic of the tweet itself.
Stage 2: Multi-Task Ranking
With ~1500 candidates sourced, the next step is to score and rank them. This is the job of a 48-million parameter neural network, which Twitter calls Heavy Ranker. This model is the core intelligence of the timeline.
Instead of predicting a single “relevance” score, Heavy Ranker is a multi-task learning model. Think of it as a specialist that, for each tweet, simultaneously predicts the probability of several different outcomes:
- Will you Like it?
- Will you Retweet it?
- Will you Reply to it?
- How long will you Dwell on it?
- Will you click on the author’s profile?
- Will you take a Negative Action, like reporting the tweet or blocking the author?
These individual predictions are then combined into a single utility score. This is a weighted sum, where positive interactions add to the score and predicted negative interactions subtract from it. The formula looks conceptually like this:
Utility_score = (w_like * P_like) + (w_reply * P_reply) + ... - (w_report * P_report)
The weights (w_like, w_reply, etc.) are business-critical parameters that Twitter’s engineers can tune. For example, if they want to encourage more conversation on the platform, they can increase the weight for the reply probability (w_reply). This allows the platform to align the ranking algorithm with its strategic goals.
This ranking is fueled by thousands of features, or signals, about the user, the tweet, and the interaction between them. These include:
- Tweet Features: The text of the tweet itself (via embeddings), its age, its language, and whether it contains an image or video.
- User Features: Your historical engagement patterns, the clusters you belong to (from SimClusters), and your language preferences.
- Interaction Features: The RealGraph score between you and the author, whether you follow each other, and your past interactions.
- Global/Context Features: Time-of-day engagement baselines, trending topic indicators.
Stage 3: Post-Rank Filtering and Mixing
After ranking, a final set of rules and heuristics are applied. This stage is like the editorial review, ensuring a balanced and diverse feed. Some examples include:
- Visibility Filtering: Remove blocked, muted, previously seen, or policy-violating items.
- Author Diversity: Limit sequential tweets per author to avoid feed domination.
- Content Balance: Keep approximate in-network/out-of-network ratio adaptively per user state.
- Feedback Fatigue: Downrank clusters or authors after negative feedback or rapid repeated impressions.
- Social Proof: Require second-degree connection (follower engaged or mutual follow) for most out-of-network items.
- Safety and Quality: Integrate abuse, spam, and NSFW classifiers; remove unsafe predictions regardless of engagement score.
- Diversity Regularization: Promote topical or cluster variety to mitigate echo chamber risk.
Mixing and Serving
At this point, Home Mixer has a set of ranked and filtered tweets. In the final step, the system blends this content with other items like Ads, Follow Recommendations, and Onboarding or nudge modules. This entire pipeline, from sourcing to serving, runs approximately 5 billion times a day and completes in under 1.5 seconds on average. Incredibly, a single timeline request requires about 220 seconds of CPU time—nearly 150 times the latency you perceive on the app!
One Request Journey (Narrative Example)
User opens app → System loads follow graph subset → RealGraph scores edges → GraphJet fetches recent engagements → SimClusters adds affinity-near tweets → Features (recency, text embeddings, edge metrics) computed → DeepRank predicts probabilities → Utility scores computed → Diversity and safety filters applied → Ads and recommendations inserted → Timeline returned.
Simplified Pseudocode
def build_for_you_timeline(user):
candidates = []
candidates += get_in_network(user, model="RealGraph")
candidates += traverse_graphjet(user)
candidates += retrieve_simcluster_neighbors(user)
candidates = deduplicate(candidates)
enriched = feature_enrichment(candidates, user)
scores = {}
for tweet in enriched:
probs = deep_rank_predict(tweet, user) # returns dict of probabilities
utility = (W_LIKE*probs['like'] + W_RT*probs['retweet'] +
W_REPLY*probs['reply'] + W_DWELL*probs['dwell'] -
W_NEG*probs['negative'] - diversity_penalty(tweet, user) -
fatigue_penalty(tweet, user))
scores[tweet.id] = utility
ordered = sort_by_score(enriched, scores)
filtered = post_rank_filters(ordered, user)
blended = mix_with_other_modules(filtered, user)
return blended[:FEED_LIMIT]Conclusion: A Symphony of Systems
Twitter’s recommendation algorithm is not a single entity but a symphony of interconnected systems. It combines the explicit connections of the social graph with the implicit connections discovered through embedding spaces. It uses the raw power of deep learning to predict user behavior while applying a final layer of human-centric rules to ensure a balanced and healthy timeline.
By open-sourcing this complex machinery, Twitter has not only provided a valuable resource for the ML community but has also given us a deeper appreciation for the incredible engineering that goes into crafting the personalized, real-time information streams we consume every day. With promises of greater transparency and new features on the horizon, the platform continues to evolve. It’s a constant dance between exploration and exploitation, between showing you what you love and helping you discover what you will love next.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!