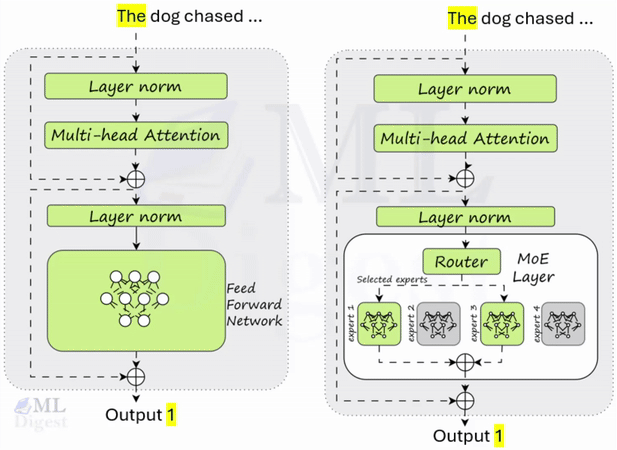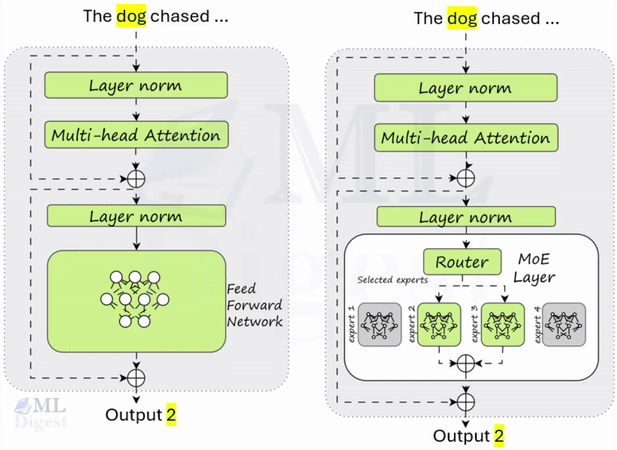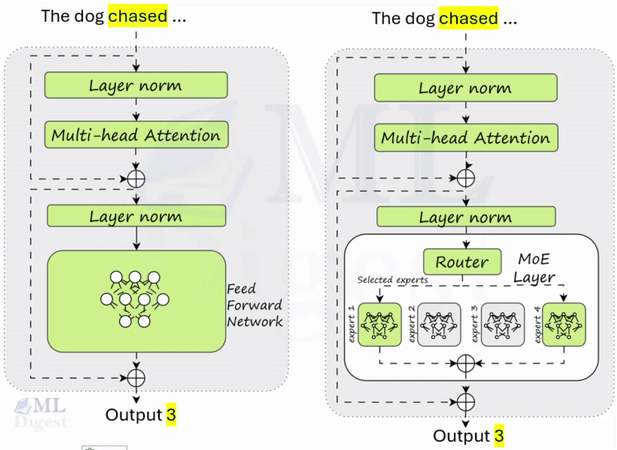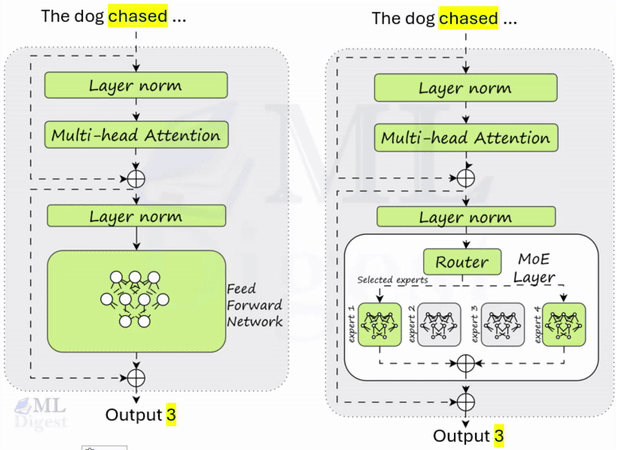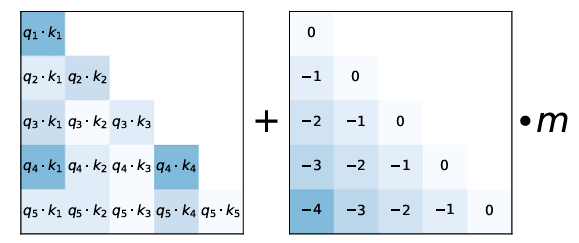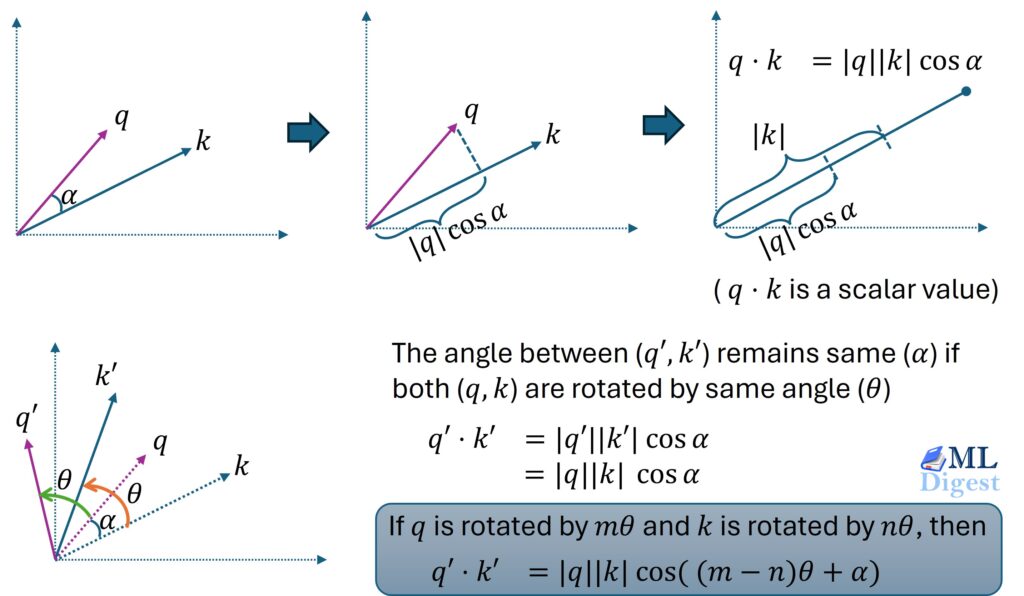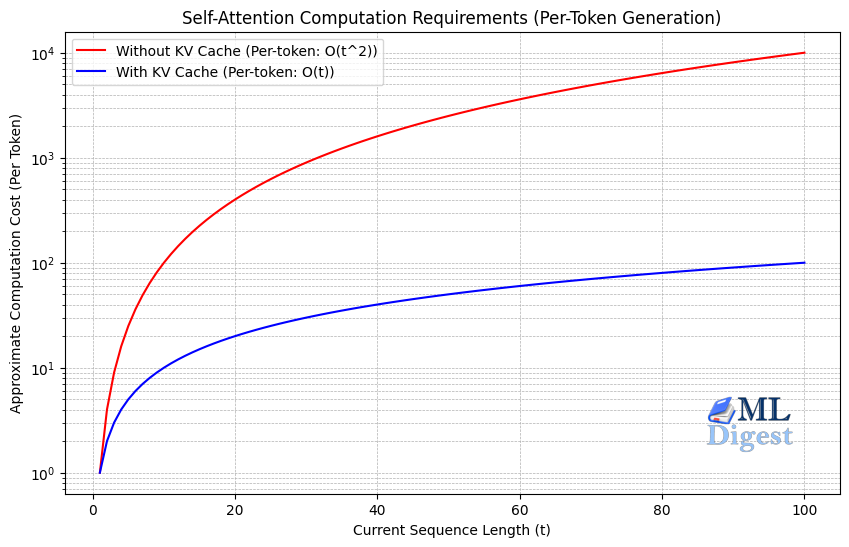
Guardrails for LLMs: A Practical, Technical Guide
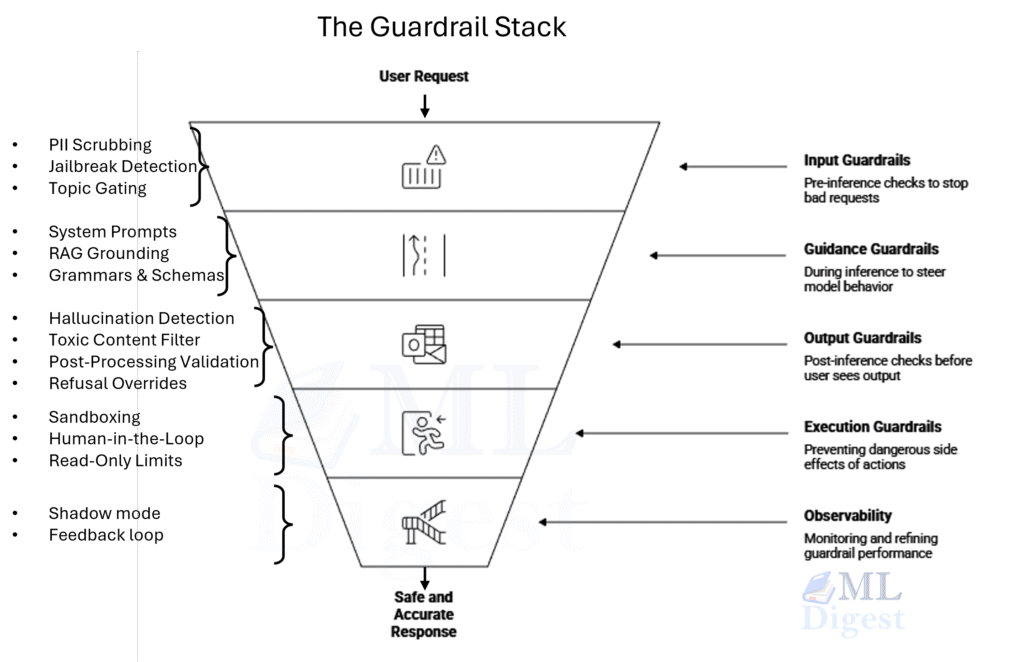
Guardrails are the technical and operational controls that reduce the chance an LLM system causes harm, violates policy, leaks sensitive […]
Guardrails for LLMs: A Practical, Technical Guide Read More »