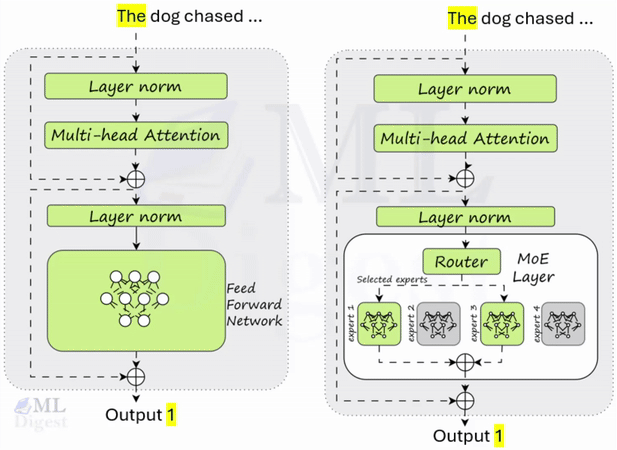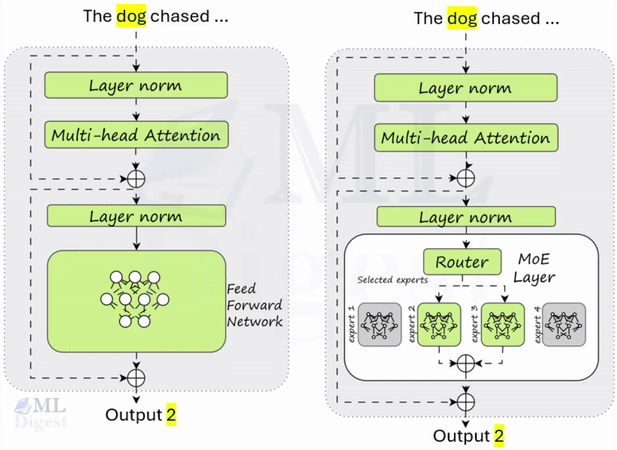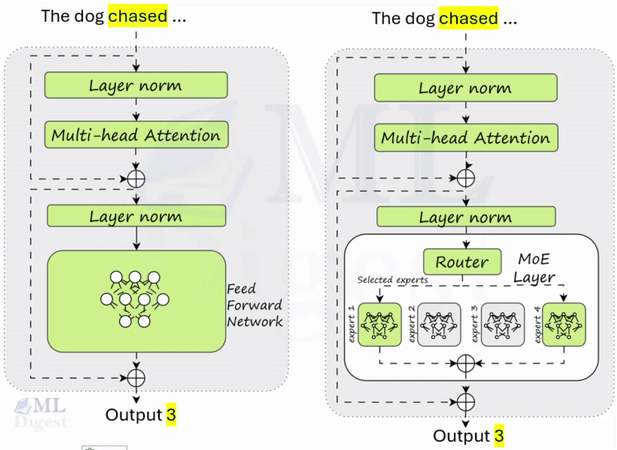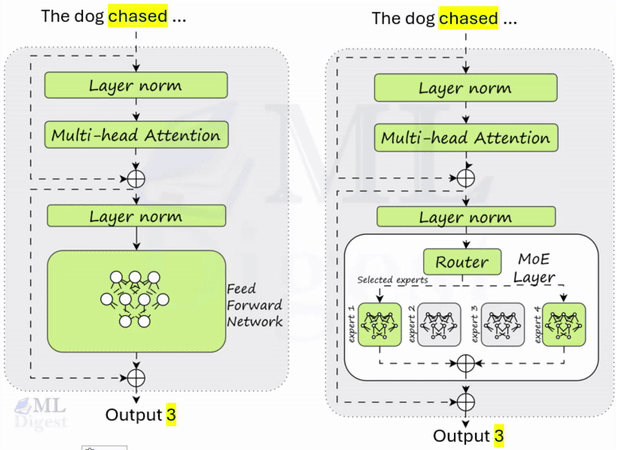
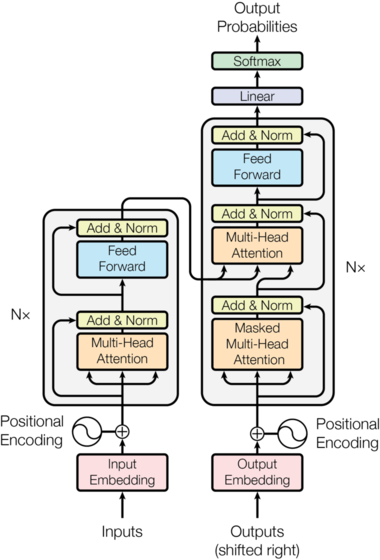
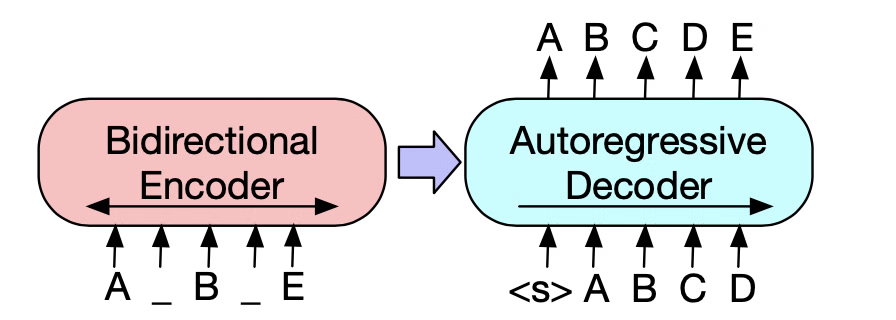
An intuitive way to view T5 (Text-to-Text Transfer Transformer) is as a multi-purpose, precision instrument that configures itself to each natural language task without changing its internal architecture. Earlier approaches often required separate model heads or distinct training pipelines for classification, translation, summarization, and question answering. T5 reframes all of these as a single transformation: input text sequence to output text sequence.
Developed by researchers at Google AI, T5 [paper] treats every NLP problem as a “text-to-text” problem—it takes text as input and produces new text as output. This elegant approach simplifies the entire process, allowing for incredible versatility and state-of-the-art performance across a wide range of applications.
The Need for a Unified Approach
Prior to the introduction of T5, many NLP models were built for specific tasks. Models tended to be optimized for either text classification, sequence labeling, or machine translation, among other tasks. This specialization could lead to redundancies in training procedures and the requirement for different models for different tasks.
T5, on the other hand, puts forth a unified framework, treating all NLP tasks as variances of a text-to-text format. For instance, summarization, translation, and even question answering can all be formulated as turning an input text into a different output text. Such an approach simplifies both the model development process and the deployment of NLP systems.
The text-to-text formulation provides several practical advantages:
- Unified Interface: Tasks that traditionally required custom heads (classification logits, token tags) now share a single generation interface with task-specific prefixes (e.g., “summarize:”).
- Simplified Multi-Task Training: A common input/output representation allows batching heterogeneous tasks, improving generalization and sample efficiency.
- Transfer Learning Efficiency: Representations learned from one task (e.g., summarization) can immediately benefit another (e.g., question answering) without architectural surgery.
- Deployment Consistency: Production systems can expose one API shape (text in → text out) reducing maintenance complexity.
- Extensibility: New tasks are added by defining a prompt pattern or prefix rather than modifying architecture.
This unification was a strategic response to the fragmentation of earlier NLP pipelines and anticipated later instruction tuning trends.
The Architecture of T5
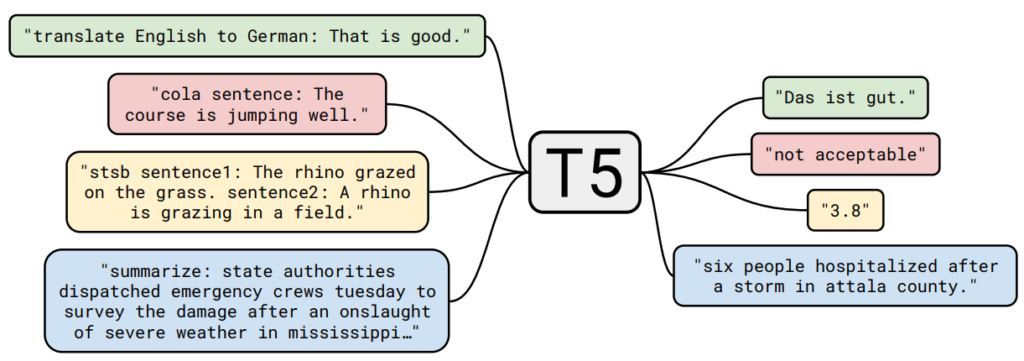
T5’s standout feature, as its name suggests, is its text-to-text formulation. This means that all model inputs and outputs are sequences of text. For example:
- For translation, the input might be “translate English to French: Hello, how are you?” and the output would be “Bonjour, comment ça va?”
- For summarization, the input might be “summarize: [full text]” and the output would be a concise summary of the original text.
By treating every task in this manner, T5 leverages a common architecture and allows one trained model to handle an array of diverse tasks.
Text-to-text framework of T5, where all tasks are formulated as converting one text sequence to another. This allows us to use the same model, loss function, hyperparameters, etc. across our diverse set of tasks.
Transformer Backbone

The T5 model is built on the transformer architecture, which consists of an encoder-decoder framework. Below are the essential components:
- Encoder: The encoder comprises a stack of identical layers, each containing a multi-head self-attention mechanism followed by a feed-forward neural network. The self-attention mechanism allows the encoder to weigh the significance of different words within the input, effectively representing the entire context.
- Decoder: Analogous to the encoder, the decoder also consists of a stack of layers that include masked self-attention, allowing predictions to consider only the already generated tokens. Additionally, there is a cross-attention layer that enables the decoder to focus on the relevant parts of the input generated by the encoder.
- Positional Encoding: As transformers do not inherently understand the order of tokens, positional encodings are added to the input embeddings, imparting information about the sequence of the text.
Pre-training and Fine-tuning
Tokenization
T5 employs a variant of the SentencePiece tokenizer, which helps convert words and subwords into tokens that the model can understand. This method enables T5 to handle a vast vocabulary while reducing the challenges associated with out-of-vocabulary words. SentencePiece tokenizes text into smaller pieces, learning a fixed-size vocabulary from the data.
Pre-training
The T5 model is pre-trained on a supervised dataset, C4 (Colossal Clean Crawled Corpus), leveraging a “fill-in-the-blank” style objective known as the “Span Corruption” objective. It involves randomly corrupting spans of text within the input sequence and then training the model to reconstruct the original text.
How Span Corruption Works:
- Span Selection: A span of contiguous tokens is randomly selected from the input sequence.
- Corruption: The selected span is replaced with a special token, such as “[MASK]” or “[SPAN]”.
- Reconstruction: The model is trained to predict the original span of tokens given the corrupted input.

In the above example, the words “for”, “inviting” and “last” (marked with an ×) are randomly chosen for corruption. Each consecutive span of corrupted tokens is replaced by a sentinel token (shown as <X> and <Y>). Since “for” and “inviting” occur consecutively, they are replaced by a single sentinel <X>. The output sequence then consists of the dropped-out spans. Sentinel tokens are assigned unique token IDs. The decoder target sequence is the concatenation of sentinel tokens followed immediately by the original span contents in order. This differs from BERT-style masking by generating the missing spans explicitly rather than classifying masked tokens.
This mechanism not only helps the model to learn semantic representations but also addresses the challenges posed by variability in language.
Fine-tuning
Upon completion of the pre-training phase, T5 requires fine-tuning on task-specific datasets to adapt its generalized knowledge to specialized tasks like translation or summarization. This fine-tuning uses sequence-to-sequence objectives with beam search evaluation and is done using gradient descent optimizers, typically Adam or Adafactor, on labeled datasets of varying sizes.
Workflow
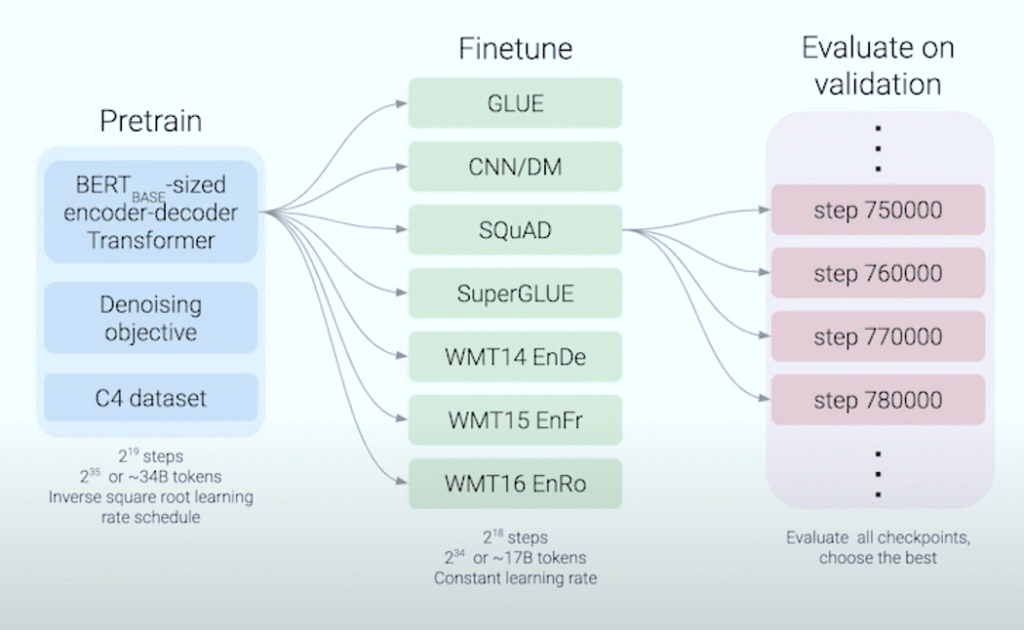
To establish a solid baseline for their experiments, the researchers began with a standard encoder-decoder Transformer model, comparable in size to BERT-Base. This model was pre-trained on the C4 dataset using the denoising objective previously described. The pre-training process involved approximately 524,000 (2¹⁹) steps, processing a total of about 34 billion (2³⁵) tokens, and utilized an inverse square root learning rate schedule.
After pre-training, the model’s performance was evaluated through fine-tuning on a diverse set of downstream tasks. These tasks included:
- GLUE: A collection of natural language understanding tasks.
- CNN/Daily Mail: A text summarization task.
- SQuAD: A question-answering dataset.
- SuperGLUE: A more challenging benchmark for language understanding.
- Translation Tasks: Specifically, WMT14 English to German (EnDe), English to French (EnFr), and English to Romanian (EnRo).
Variants of T5
The T5 architecture is not one-size-fits-all. It comes in several configurations, allowing researchers and developers to choose a model that fits their computational resources and application needs. The most common variants include:
- T5-Small: ~60 million parameters
- T5-Base: ~220 million parameters
- T5-Large: ~770 million parameters
- T5-3B: ~3 billion parameters
- T5-11B: ~11 billion parameters
These variants allow for a trade-off between model size, computational cost, and performance.
T5 in Action: A Code Example
T5 summarization
One of the best ways to understand T5 is to see it in action. Thanks to the Hugging Face transformers library, using a pre-trained T5 model for a task like summarization requires just a few lines of Python code.
Below is a summarization example using the t5-small model. The task is indicated via a prefix.
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
# Load the tokenizer and model
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
# Prepare the text for summarization
# T5 requires a prefix for each task. For summarization, it's "summarize: "
text_to_summarize = """
Scientific research in artificial intelligence (AI) has been developing rapidly in recent years.
The field is focused on creating intelligent agents, which are systems that can reason, learn, and act autonomously.
One of the most significant breakthroughs has been the development of deep learning, a subset of machine learning,
which uses neural networks with many layers (deep neural networks) to analyze various forms of data.
These models have achieved remarkable success in tasks such as image recognition, natural language processing, and speech recognition.
However, the progress also raises important questions about the ethical implications of AI, including issues of bias,
privacy, and the future of work. Researchers are actively working on creating more transparent, fair, and accountable AI systems.
"""
input_text = "summarize: " + text_to_summarize
# Tokenize the input text
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
# Generate the summary
summary_ids = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
# Decode the summary
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(summary)Translation Example
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small").to(device)
source_sentence = "The model learns by reconstructing masked spans."
prefixed = "translate English to German: " + source_sentence
inputs = tokenizer(prefixed, return_tensors="pt", max_length=128, truncation=True).to(device)
translation_ids = model.generate(**inputs, max_length=80, num_beams=4)
translation = tokenizer.decode(translation_ids[0], skip_special_tokens=True)
print(translation)Advantages of T5
- Unified Framework: By treating all NLP tasks through a consistent input-output text format, T5 simplifies the complexity associated with deploying models for different tasks.
- Versatile Applications: T5 can be fine-tuned for a plethora of NLP tasks, making it an invaluable resource in environments where multiple applications are necessary.
- Transfer Learning: T5’s text-to-text approach with extensive pre-training allows it to leverage knowledge gained from one task and apply it to another, improving performance across datasets of varying quality and sizes.
- Performance: T5 showcases exceptional performance and generalization abilities due to effective pre-training and fine-tuning processes.
- Robustness to Input Variability: The model’s design makes it resilient against variations in input text, allowing it to understand and respond to paraphrasing or restructured question forms effectively.
Challenges and Considerations
- Overfitting Risk: Without carefully curated datasets, fine-tuning the model on small datasets may lead to overfitting, wherein the model performs well on training data but poorly generalizes to unseen data.
- Bias in Data: Like many NLP models, T5 is susceptible to biases present in the training data, which may result in biased outputs, making consideration for ethical implications critical during deployment.
- Accuracy of Generative Responses: While T5 excels at generating coherent text, there are concerns regarding the accuracy of generated content, particularly in critical applications where factual correctness is paramount.
Conclusion
By effectively unifying disparate tasks into a common text-to-text format, T5 not only facilitates simpler model architectures but also enhances performance across the board. The successful pre-training on extensive datasets and the seamless transition to specific tasks exemplify the robustness of this approach.
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!