This article summarizes the content of the source, “The Efficiency Spectrum of Large Language Models: An Algorithmic Survey,” focusing on methods used to increase the efficiency of LLMs.

Introduction
Large Language Models (LLMs) have significantly impacted the field of artificial intelligence. These models, such as ChatGPT and Claude, have shown remarkable capabilities in various tasks due to their massive size (tens or even hundreds of billions of parameters) and expertise in natural language understanding. The increasing computational and memory demands of LLMs present challenges, hindering research and practical applications. This article discusses algorithmic advancements aimed at improving LLM efficiency across the entire development pipeline. The focus is on optimizing computational and memory resources without sacrificing model performance.
Understanding Scaling Laws in LLMs
The performance of LLMs is significantly influenced by several factors, including:
- Training data
- Model size
- Architecture
- Computing resources
- Training methodology
Training LLMs is a resource-intensive process, making traditional trial-and-error approaches for optimizing these factors impractical. Therefore, predicting LLM performance before training is not just beneficial but often necessary. Scaling laws provide a framework for understanding and predicting LLM performance based on the interplay of these crucial factors.
Scaling law behavior in language models refers to the observed relationships between model performance and various factors like model size, dataset size, and compute resources. Language modeling performance improves smoothly as we increase the model size, dataset size, and amount of compute used for training. For optimal performance all three factors must be scaled up in tandem.
The Multifaceted Nature of LLM Efficiency
Efficiency of LLMs is not a singular concept, but rather a complex interplay of various factors that impact the entire lifecycle of these models, from training to deployment.
- The Number of Parameters plays a crucial role in an LLM’s ability to learn and generalize. A higher parameter count generally allows the model to capture more intricate data patterns and potentially develop emergent abilities. However, this increased capacity comes with the trade-off of heightened computational demands during both training and inference. Overly complex models with excessive parameters might also be prone to overfitting, especially when training data is limited. Techniques like regularization and early stopping can help mitigate this issue.
- Model Size, measured as the disk space required to store the model, is a significant consideration for practical deployment. Excessively large models might be impractical to store or run, particularly in resource-constrained environments such as edge devices. While the number of parameters is a major contributor to model size, other factors such as the data type used for parameters (e.g., float16, int8) and specific architectural choices also impact the overall size.
- Floating Point Operations (FLOPs) provide a theoretical measure of the computational complexity of an LLM. FLOPs represent the number of floating-point operations, such as addition, subtraction, multiplication, and division, performed during a single forward pass. While FLOPs offer insights into computational needs and potential energy consumption, they do not fully capture the model’s overall efficiency, as factors like system parallelism and architectural choices also play a role.
- Inference Time, also known as latency, quantifies the duration it takes for an LLM to process input and produce a response during the inference stage. This metric, often measured in milliseconds (ms) or seconds (s), is particularly important for real-time applications that require rapid responses or have stringent latency constraints. Tokens per Second, derived by normalizing inference time by time elapsed, signifies the number of tokens an LLM can process in one second, reflecting the model’s speed and efficiency. Striking a balance between fast inference time/tokens per second and maintaining high generalization capabilities is a crucial aspect of developing efficient LLMs.
- Carbon Emission, an increasingly important metric, assesses the environmental impact of training and operating these models. Measured in terms of kilograms or tons of CO2 equivalent emitted during the model’s lifecycle, the carbon footprint is influenced by the energy efficiency of the used hardware, the source of electricity powering the data centers, and the duration of model training and operation. High carbon emissions raise environmental concerns and ethical considerations regarding the deployment of LLMs. Optimizing models for energy efficiency through techniques like hardware acceleration, algorithmic improvements, and the choice of greener energy sources is vital in reducing the environmental impact.
Beyond these metrics, the sources highlight the multifaceted nature of LLM efficiency by exploring various dimensions:
- Budget Efficiency: The concept of scaling laws aims to predict LLM performance based on factors like model architecture, size, training compute budget, and data volume. This predictive approach is crucial for efficiently allocating resources, especially when working within computational limitations. Understanding scaling laws allows researchers to optimize the balance between model size and data volume to achieve optimal performance within a given compute budget.
- Data Efficiency: The sources emphasize the importance of efficient data utilization in LLM training and validation. Techniques like data filtering (including deduplication and data undersampling) aim to prioritize the most informative samples, reducing redundancy and mitigating data imbalance issues. Active learning and importance sampling techniques are crucial in prioritizing samples based on their significance to the learning process, further optimizing training efficiency. Additionally, curriculum learning, involving a gradual increase in the complexity of the training data, helps the model learn more efficiently by mastering simpler concepts before tackling more complex ones.
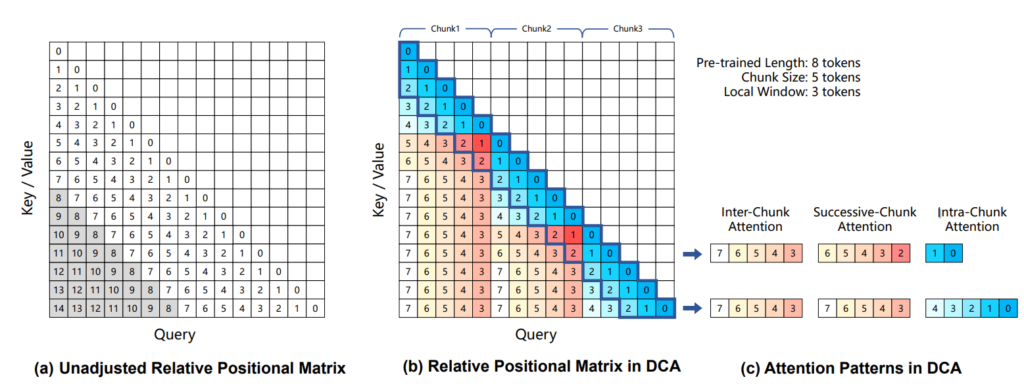
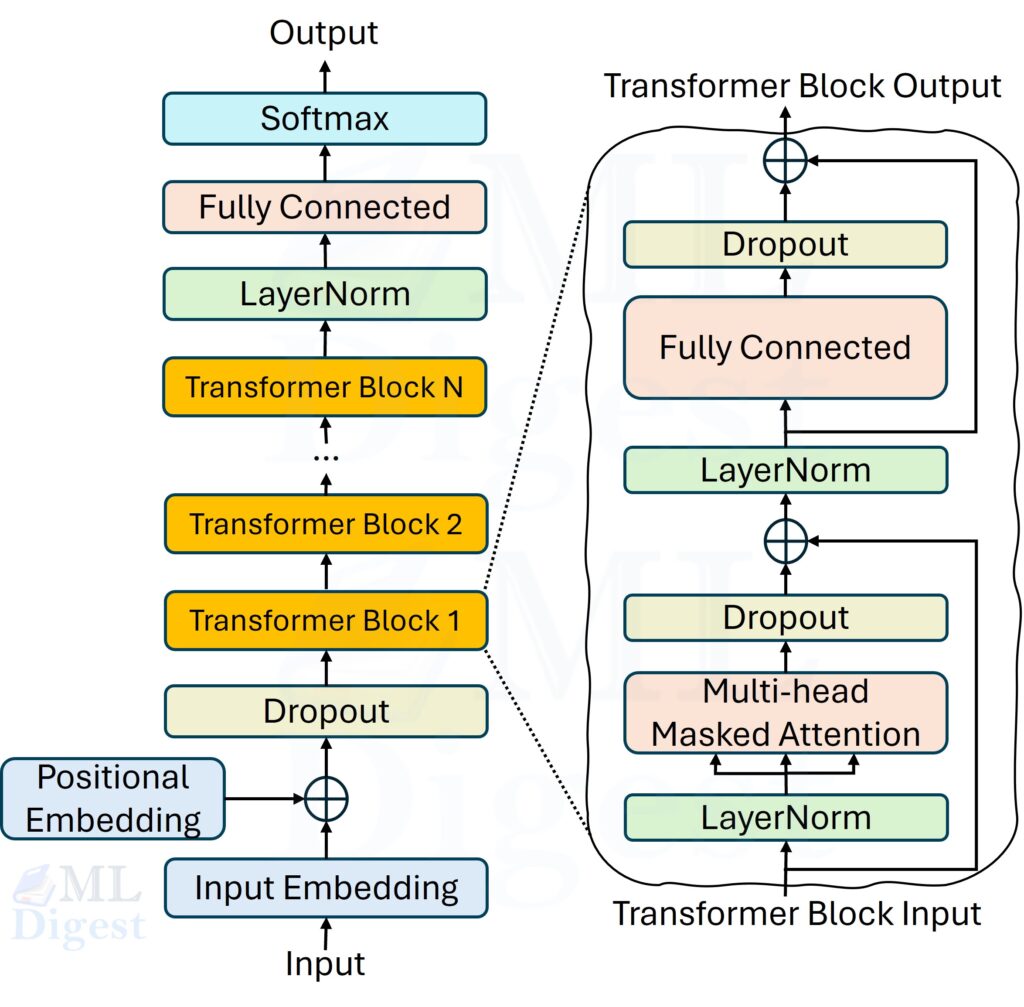
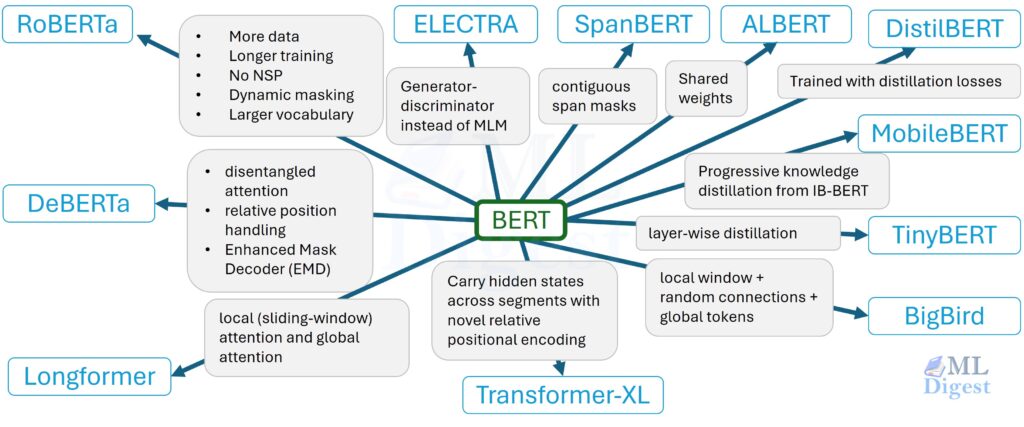
- Architecture Efficiency: The Transformer architecture, while dominant in language modeling due to its parallelism, faces challenges in efficiency, especially with long input sequences. Research is actively exploring ways to improve the efficiency of the attention mechanism, positional encoding, and the overall architectural design. These include developing efficient attention mechanisms (using techniques like attention factorization, frequency-based approaches, and hardware-co-design), exploring alternative positional encoding methods (such as relative positional encoding, rotary positional encoding, randomized positional encoding), leveraging sparse modeling techniques (like Mixture of Experts and Sparsefinder), and even experimenting with attention-free methods that entirely replace the attention mechanism with alternative architectures.
- Training and Tuning Efficiency: The sources outline various strategies for efficient training and tuning of LLMs, focusing on memory optimization, computation efficiency, and communication efficiency. These involve techniques like stable training strategies (including hyperparameter tuning and checkpoint restarting), mixed precision training (using reduced-precision formats), parallelism-based techniques (employing data parallelism, model parallelism, and automated parallelism for distributed training), memory optimization strategies (such as gradient checkpointing and offloading, parameter sharding, and zero redundancy optimizer), and scalable tuning methods (like parameter-efficient fine-tuning and data-efficient tuning through prompt engineering).
- Inference Efficiency: The sources discuss various methods to accelerate inference, which is crucial for deploying LLMs on both cloud services and resource-limited devices. These techniques include pruning (removing redundant components from the model), knowledge distillation (training a smaller ‘student’ model to mimic a larger ‘teacher’ model), quantization (representing floating-point numbers with fewer bits), and low-rank decomposition (approximating large weight matrices with smaller, low-rank matrices).
This article has summarized a spectrum of algorithmic innovations designed to enhance the efficiency of LLMs. It covered key areas including the use of scaling laws for optimal resource allocation, strategies for efficient data utilization, architectural innovations for improved processing, techniques for faster and less resource-intensive training and tuning, and methods for accelerating inference speed. The insights presented here aim to serve as a valuable resource for researchers and practitioners alike, paving the way for further advancements in LLM efficiency, enabling the development of even more powerful and accessible language models in the future.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!