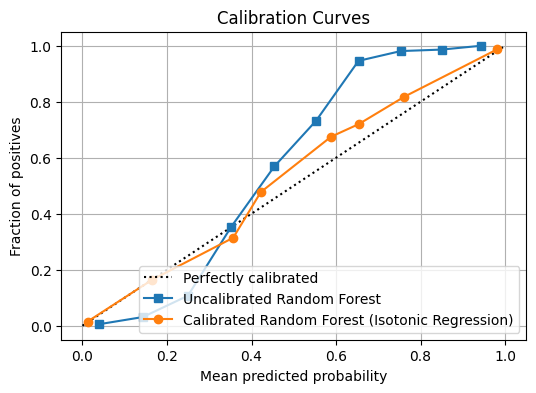
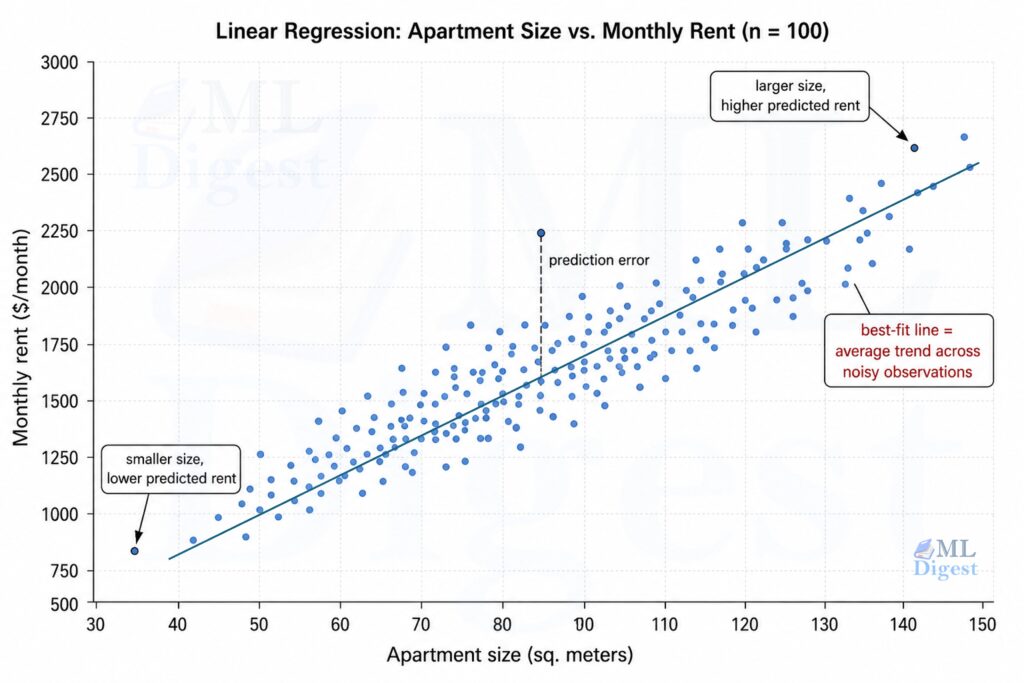
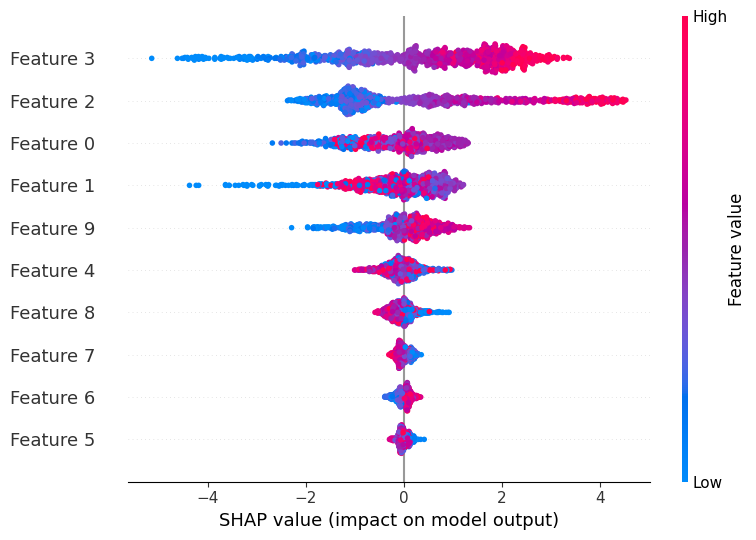
Large ML models often come with substantial computational costs, making them challenging to deploy on resource-constrained devices or in real-time applications. Pruning, a technique inspired by synaptic pruning in the human brain, offers a powerful solution by selectively removing less important connections or parameters from a trained model, resulting in a smaller, faster, and often more generalizable model.
Model pruning is an optimization technique that involves removing unnecessary or less significant components (such as weights, neurons, or entire layers) from a neural network to create a smaller, faster, and more efficient model.The primary goal is to reduce the computational and memory requirements of models, making them more suitable for deployment on resource-constrained devices like smartphones, embedded systems, and Internet of Things (IoT) devices.
Why Prune? The Benefits of Model Pruning
- Reduced Memory Footprint: Pruning decreases the number of parameters in a model, leading to a smaller memory footprint. This is crucial for deploying models on devices with limited storage capacity.
- Reduced Computational Cost: Smaller models require fewer computations during inference, leading to faster execution times and lower power consumption. This is crucial for deployment on mobile devices, embedded systems, and edge computing platforms.
- Lower Energy Consumption: Reduced computational demands translate to lower energy usage, extending battery life in portable devices and contributing to greener AI practices.
- Faster Inference: With fewer parameters and operations, pruned models can perform predictions more swiftly, enhancing responsiveness—especially important for real-time applications.
- Improved Generalization: Pruning can act as a form of regularization, potentially enhancing a model’s ability to generalize by removing noise and reducing overfitting.
- Interpretability: Pruning can sometimes reveal the most important features or connections in a model, providing insights into its decision-making process.
Pruning Techniques
Several specific pruning techniques are commonly used:
- Magnitude-based Pruning: This simple and widely used method removes connections with the smallest absolute weights. A threshold is set, and all weights below this threshold are pruned.
- Optimal Brain Damage (OBD) and Optimal Brain Surgeon (OBS): These methods use the Hessian matrix of the loss function to estimate the importance of each weight and remove the least important ones. They are theoretically sound but computationally expensive for large models.
- Lottery Ticket Hypothesis: This hypothesis suggests that within a randomly initialized neural network, there exists a subnetwork (a “winning ticket”) that can achieve comparable or even better performance than the original network when trained in isolation. Pruning can be used to identify these winning tickets.
- Regularization-based Pruning: Techniques like L1 regularization encourage sparsity in the weight matrix during training, effectively performing pruning.
- Sensitivity-based Pruning: This method evaluates the sensitivity of the model’s output to changes in weights and prunes those with the least impact on the output.
- Random Pruning: Randomly removes connections or parameters from the model, which can serve as a baseline for comparison with more sophisticated pruning methods.
- Iterative Pruning: Repeatedly prunes the model, fine-tunes it, and prunes again, iteratively improving the model’s efficiency and performance.
Types of Model Pruning (Based on Granularity)
Weight Pruning
Weight pruning focuses on removing individual connections (weights) in the network. The idea is to identify and eliminate weights that contribute minimally to the model’s output.
Steps:
- Identify Importance: Assign a metric to determine the importance of each weight (e.g., magnitude, gradient-based methods).
- Prune Weights: Remove weights that fall below a certain threshold based on their importance.
- Fine-Tune: Retrain the model to recover any lost accuracy.
Neuron Pruning
Neuron pruning involves removing entire neurons (and their associated connections) from a network layer. This reduces the dimensionality of the layer and simplifies the model.
Steps:
- Assess Neuron Importance: Determine the contribution of each neuron using activation values or other metrics.
- Remove Neurons: Eliminate the least important neurons.
- Retrain: Fine-tune the model to maintain performance.
Filter Pruning
Commonly used in convolutional neural networks (CNNs), filter pruning removes entire convolutional filters (kernels) from layers. This reduces the number of feature maps and the computational load.
Steps:
- Evaluate Filter Significance: Measure the importance of each filter (e.g., based on L1 norm, activation).
- Prune Filters: Remove filters deemed less significant.
- Retrain the Model: Restore any lost performance through fine-tuning.
Layer Pruning
Layer pruning entails removing entire layers from the network, typically those that contribute least to the model’s performance. This leads to a shallower network with fewer sequential operations.
Steps:
- Identify Redundant Layers: Determine which layers have minimal impact on the output.
- Remove Layers: Eliminate the selected layers.
- Adjust the Architecture: Ensure the remaining layers are compatible and retrain the model.
Global vs. Layer-wise Pruning
- Global Pruning: Considers all weights or structures across the entire network when deciding what to prune. This approach can achieve higher compression rates as it leverages the flexibility to prune from any part of the network.
- Layer-wise Pruning: Prunes a specific proportion of weights or structures within each layer independently. This ensures a balanced reduction across the network. It may result in lower overall compression compared to global pruning.
Types of Model Pruning (Based on Strategy)
Pruning strategies can be categorized based on what components are removed and how the pruning is applied:
- Structured Pruning removes entire structural elements of the network, such as neurons, filters, or layers. This approach maintains the regular structure of the network, making it compatible with standard hardware accelerators and efficient for deployment. It may lead to larger accuracy drops compared to unstructured pruning.
- Unstructured Pruning targets individual weights based on their importance, regardless of their position in the network’s structure. This leads to sparse models where many weights are zeroed out.
- Dynamic pruning adapts the pruning criteria or the pruned structures during training. Unlike static pruning, which permanently removes components, dynamic pruning can adjust which parts of the model are pruned as training progresses.
Types of Model Pruning (Based on Timing)
- Pre-training Pruning: Pruning is performed before or during the initial training of the model.
- Post-training Pruning: Pruning is applied to a pre-trained model. This is the more common approach due to its simplicity.
Tools and Frameworks Supporting Pruning
Several machine learning frameworks and tools provide built-in support for model pruning, simplifying the implementation for developers:
- TensorFlow Model Optimization Toolkit: Offers comprehensive pruning APIs that allow developers to perform both structured and unstructured pruning.
- Lightning: Integrates pruning methods into the training loop, enabling structured and unstructured pruning with ease.
- Torch.nn.utils.prune: A utility module that provides various pruning methods, including random, L1-unstructured, and more.
- ONNX Runtime: Supports model pruning through optimization passes, allowing pruned models to be executed efficiently across different platforms.
- TensorRT Pruning Support: Optimizes neural network models by integrating pruning techniques, enhancing performance on NVIDIA GPUs.
- Neural Compressor: Provides tools for model pruning, quantization, and other optimizations tailored for Intel hardware.
- SparseML: An open-source library for applying structured and unstructured pruning, providing state-of-the-art pruning algorithms and integrations with popular frameworks.
- DeepSparse: Developed by Neural Magic, this library leverages sparsity introduced by pruning to accelerate inference on CPU hardware.
Challenges and Limitations
- Balancing Pruning and Accuracy: Achieving the right balance between model compression and maintaining accuracy is critical. Excessive pruning can lead to substantial performance degradation, while insufficient pruning may not yield desired efficiency gains.
- Selection of Pruning Criteria: Choosing appropriate metrics to determine which weights or structures to prune is essential. Common criteria include weight magnitude, gradient information, and activation statistics, but selecting the most effective one depends on the specific model and task.
- Hardware Compatibility: Structured pruning is generally more compatible with existing hardware accelerators, while unstructured pruning may require specialized hardware or software support to fully leverage sparsity for speed-ups.
- Implementation Complexity: Advanced pruning techniques, especially those involving dynamic pruning or intricate criteria, can be complex to implement and may require substantial changes to the training pipeline.
Future Directions in Model Pruning
Research in pruning continues to explore several promising directions:
- Automated Pruning: Developing methods to automatically determine the optimal pruning strategy and hyperparameters.
- Hardware-aware Pruning: Designing pruning techniques that explicitly consider the target hardware architecture to maximize performance gains.
- Adaptive and Dynamic Pruning: Exploring methods to dynamically prune and adapt models during runtime based on input data or resource availability.
- Combining Pruning with other compression techniques: Integrating pruning with other model compression techniques like quantization and knowledge distillation.
- Pruning in Federated and Distributed Learning: Exploring pruning techniques in federated learning settings, where models are trained across decentralized devices, can lead to more efficient collaborative models without centralizing large parameter sets.
- Scalable Pruning Algorithms: Developing pruning algorithms that scale efficiently with model size can make pruning feasible for extremely large models, such as those used in cutting-edge natural language processing.
Closing Thoughts
As the demands for real-time performance and deployment on resource-constrained devices continue to grow, pruning will remain a vital tool for making advanced ML models more accessible and practical. It enables the creation of smaller, faster, and more efficient models suitable for a wide range of applications and deployment environments. By judiciously removing redundant or less significant components, pruning not only enhances computational efficiency but also contributes to sustainable AI practices through reduced energy consumption.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!