Measuring the performance of a Large Language Model (LLM) involves evaluating various aspects of its functionality, ranging from linguistic capabilities to efficiency and ethical considerations. Here’s a comprehensive overview of the primary methods and metrics used to assess LLM performance:
1. Quantitative Metrics
These metrics provide numerical values to evaluate specific aspects of an LLM’s performance:
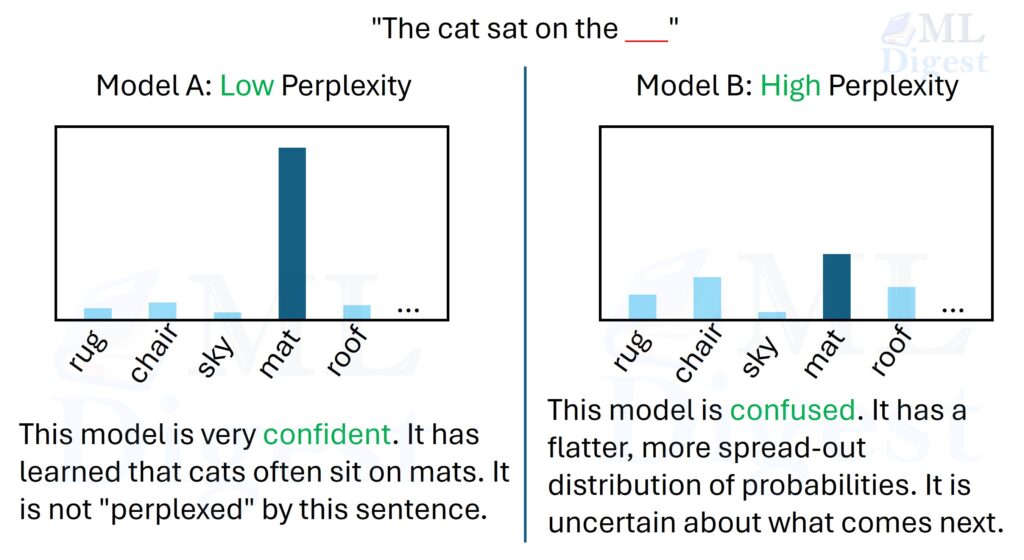
- Perplexity:
- Definition: Measures how well a probability model predicts a sample.
- Usage: Lower perplexity indicates better predictive performance, meaning the model is more confident in its predictions.
- Accuracy and Exact Match:
- Definition: Evaluates the percentage of correct predictions or exact responses, especially in tasks like question answering.
- Usage: Useful for classification tasks where there is a definitive correct answer.
- BLEU (Bilingual Evaluation Understudy):
- Definition: Assesses the quality of machine-translated text by comparing it to reference translations.
- Usage: Commonly used in translation and text generation tasks.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
- Definition: Measures the overlap of n-grams between the generated text and reference texts.
- Usage: Primarily used for evaluating summarization and translation tasks.
- F1 Score:
- Definition: The harmonic mean of precision and recall.
- Usage: Useful in tasks where both false positives and false negatives are important, such as named entity recognition.
2. Benchmark Datasets and Standardized Tests
LLMs are often evaluated against established benchmarks to compare their performance relative to other models:
- GLUE (General Language Understanding Evaluation): Assesses a model’s ability across multiple language understanding tasks.
- SuperGLUE: A more challenging extension of GLUE, designed to push the boundaries of language understanding.
- SQuAD (Stanford Question Answering Dataset): Measures reading comprehension by requiring models to answer questions based on given passages.
- MMLU (Massive Multitask Language Understanding): Tests models on a wide range of subjects and difficulty levels to assess general knowledge and reasoning.
3. Human Evaluation
While quantitative metrics are essential, human judgment remains crucial for assessing aspects that are hard to quantify:
- Fluency: How naturally and smoothly the text reads.
- Coherence: Logical flow and consistency of the generated content.
- Relevance: Appropriateness of the response in relation to the input prompt.
- Correctness: Accuracy and factual correctness of the information provided.
- Usefulness: Practical value of the response to the user’s needs.
4. Fine-Grained Analysis
Beyond general performance, specific attributes of LLMs are evaluated to ensure reliability and ethical use:
- Bias and Fairness: Identifying and mitigating any prejudiced or unfair representations in the model’s outputs.
- Safety and Toxicity: Ensuring the model does not produce harmful, offensive, or inappropriate content.
- Robustness: Model’s ability to handle noisy, ambiguous, or adversarial inputs without degradation in performance.
5. Efficiency Metrics
Performance isn’t solely about accuracy; operational efficiency is also vital:
- Latency:
- Time taken to generate a response.
- Critical for real-time applications where quick responses are necessary.
- Throughput:
- Number of tasks or requests a model can handle in a given time frame.
- Important for scaling applications to handle large volumes of queries.
- Resource Utilization:
- Computational resources (CPU, GPU, memory) required to run the model.
- Influences cost and feasibility of deployment, especially in resource-constrained environments.
6. Task-Specific Evaluations
- Dialogue and Conversation Quality: Turn-level coherence, relevance, and engagement.
- Creative Generation (e.g., Storytelling, Poetry): Originality, creativity, emotional impact.
- Code Generation: Correctness, efficiency, and adherence to best coding practices.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!