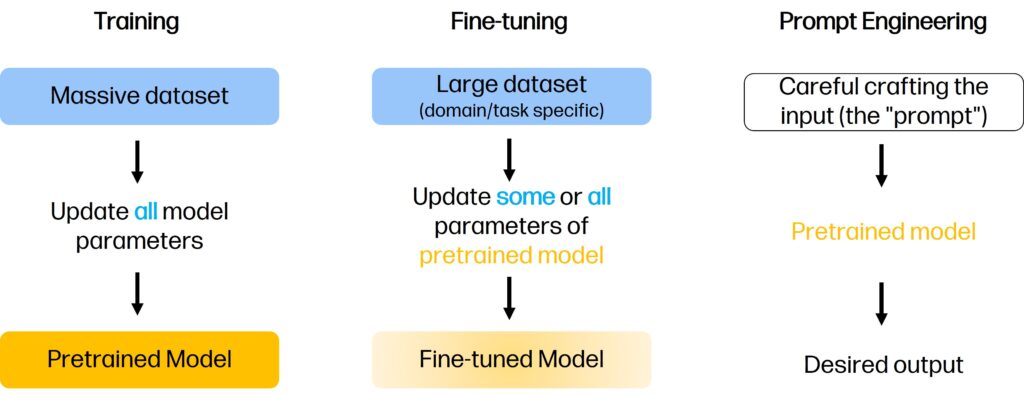
Imagine a master chef. This chef has spent years learning the fundamentals of cooking—how flavors combine, the science of heat, the texture of ingredients. This foundational knowledge is vast and deep. This is like training a large language model (LLM) from scratch.
Now, what if this chef wants to specialize in a new, niche cuisine, say, authentic Basque cheesecake? They don’t need to relearn how to cook from zero. They take their massive expertise and adapt it to this new style. This is fine-tuning.
Finally, imagine a diner at this chef’s restaurant. The diner can’t change the chef’s training, but they can place a very specific order: “a steak, medium-rare, with a side of grilled asparagus, and hold the salt.” The chef, using their existing skills, produces exactly what the diner wants. This is prompt engineering.
Just like our chef, LLMs can be built from scratch, specialized for new tasks, or skillfully guided to produce a specific output. Understanding the difference between training, fine-tuning, and prompt engineering is key to effectively working with them.
Let’s dive into what each of these approaches entails, when to use them, and how they compare.
1. Training from Scratch: Building the Master Chef
Training an LLM from scratch is like raising our master chef from their first taste of salt. It’s a monumental undertaking. You start with a “neural network architecture” – a blank slate, a model with billions of parameters that are essentially random numbers. Then, you feed it a colossal amount of text data from the internet, books, and other sources.
The model’s goal is simple: predict the next word in a sentence. By doing this billions of times, the model slowly adjusts its internal parameters, learning grammar, facts, reasoning abilities, and even a degree of common sense.
- The “What”: Initializing a model architecture and training it on a massive, general dataset.
- The “Why”: To create a foundational model with broad knowledge and language capabilities.
- The “How”: This requires immense computational resources (hundreds or thousands of GPUs), vast amounts of data (terabytes), and significant expertise in distributed systems and machine learning. It’s a process that can take months and cost millions of dollars.
This is the path taken by organizations that create foundational models like ChatGPT, Gemini, LLaMA, or Claude. For most of us, training a model from scratch is out of reach. We’ll instead build upon the work of these master chefs.
2. Fine-Tuning: Teaching an Old Chef New Tricks
Fine-tuning is where things get more accessible and interesting for many developers and businesses. Instead of starting from scratch, you take a powerful, pre-trained foundational model and adapt it to a specific task or domain.
This is our master chef learning that new cuisine. They already have the core skills; they just need to learn new recipes, ingredients, and techniques.
The Two Flavors of Fine-Tuning
a) Full Fine-Tuning
In full fine-tuning, you expose the pre-trained model to your new, smaller, task-specific dataset (e.g., a collection of legal documents, customer support chats, or medical research papers). As the model trains on this new data, all of its original parameters are updated.
- The “What”: Updating all the weights of a pre-trained model on a new dataset.
- The “Why”: To deeply embed a new skill or knowledge domain into the model.
- The “How”: You present the model with examples and adjust the weights through backpropagation, just like in initial training, but on a much smaller scale. While less expensive than training from scratch, this still requires significant computational power and creates a full, new copy of the model for each task.
b) Parameter-Efficient Fine-Tuning (PEFT)
What if our chef could learn the new cuisine by just adding a few new pages to their existing cookbook, instead of rewriting the whole thing? That’s the magic of PEFT.
PEFT is a collection of techniques that freezes the vast majority of the LLM’s original parameters and only updates a small, manageable number of new or existing ones. This is incredibly efficient.
One of the most popular PEFT methods is Low-Rank Adaptation (LoRA). LoRA works by inserting small, trainable “adapter” layers into the model’s architecture. The original weights remain frozen and untouched. We only train these tiny new layers. When we’re done, we have the original model plus a small “adapter” file that contains the new skill.
- The “What”: Updating only a small subset of a model’s parameters.
- The “Why”: To adapt a model to a new task with dramatically less computational cost, faster training times, and smaller storage requirements. You can have one base model and many small LoRA “skill” files.
- The “How”: Techniques like LoRA, QLoRA, or prompt tuning are used to isolate a small number of parameters for training.
Transfer Learning vs. Fine-Tuning
Transfer learning and fine-tuning are both powerful techniques in machine learning that leverage pre-trained models to solve new tasks. While closely related, they represent different levels of adaptation. Think of it like learning to drive:
- Transfer Learning is like learning to drive a car and then immediately being able to drive a similar car (e.g., a different brand or model) without needing to relearn everything from scratch. You already have the foundational skills (knowledge of the road, steering, pedals).
- Fine-Tuning is like already knowing how to drive a car and then learning to drive a high-performance race car. You use your existing driving skills, but you also adjust and refine them to handle the specific nuances and demands of the new vehicle and track.
Transfer learning, particularly in the context of “feature extraction,” involves using a pre-trained model as a fixed feature extractor. This means you take a model that has already been trained on a very large and general dataset (e.g., ImageNet for images, or a large text corpus for language models) and use its learned internal representations (features) for a new, related task.
Fine-tuning is a type of transfer learning that takes the adaptation process a step further. Instead of just using the pre-trained model as a fixed feature extractor, you unfreeze some or all of its layers and continue training them on your new, task-specific dataset.
| Feature | Transfer Learning | Fine-Tuning |
|---|---|---|
| Goal | Reuse knowledge | Adapt knowledge to a new task |
| Training Scope | Only new, final layers are trained; pre-trained layers are frozen. | Some or all pre-trained layers are unfrozen and trained, along with new layers. |
| Training Data | Small dataset required | Moderate to large domain-specific data needed |
| Compute Cost | Low | Higher |
| Flexibility | Limited to general tasks; less adaptive; uses pre-trained features as-is. | Highly adaptable; modifies pre-trained features to fit the new task. |
| Risk of Overfitting | Lower | Higher if not regularized properly |
3. Prompt Engineering: The Art of the Perfect Order
Prompt engineering is the most accessible way to customize an LLM’s output. It doesn’t involve any training or changing the model’s weights at all. Instead, it’s about carefully crafting the input (the “prompt”) to guide the existing, unchanged model to produce the desired result.
This is the diner telling the chef exactly how they want their steak. The chef’s skills aren’t changing, but the output is tailored to the specific request.
- The “What”: Designing the input text to guide a pre-trained model’s output.
- The “Why”: To control the model’s tone, format, and the content of its response without the need for any training. It’s fast, cheap, and can be surprisingly effective.
- The “How”: Through trial and error, and by using techniques like chain-of-thought prompting, you refine your input to get better output.
A prompt can be simple, like “Summarize this article.” Or it can be complex, including:
- Instructions: “You are a helpful assistant. Summarize the following text for a 5th-grade audience.”
- Few-shot examples: Providing a few examples of input and desired output to show the model what you want.
- Context: Giving the model relevant information to use in its response.
Which Approach Should You Use? A Scenario-Based Guide
So, which path should you choose? Here’s a simple guide based on common scenarios:
| Scenario | Best Approach | Why? |
|---|---|---|
| You are a large tech company creating a new foundational AI. | Training from Scratch | You have the resources and the goal is to create a general-purpose model that can serve as a base for many applications. |
| You need your model to learn a new, complex skill or a private knowledge domain (e.g., internal company documents). | Fine-Tuning (Full or PEFT) | The model needs to internalize new information or a new style of response that can’t be easily described in a prompt. |
| You need to adapt a model for a specific task, but have limited computational resources. | PEFT (e.g., LoRA) | PEFT gives you the power of fine-tuning without the high cost. It’s perfect for creating specialized “skill adapters.” |
| You want to control the output format, tone, or persona of the model for a specific application. | Prompt Engineering | This is the quickest and cheapest way to guide the model. Start here first. If prompting isn’t enough, then consider fine-tuning. |
| You need the model to answer questions based on information it wasn’t trained on, and the information changes frequently. | Prompt Engineering + RAG | Use a technique called Retrieval-Augmented Generation (RAG), where you fetch relevant information from a database and put it in the prompt. This is more flexible than fine-tuning for rapidly changing data. |
A Simple Rule of Thumb
- Always start with Prompt Engineering. It’s the low-hanging fruit.
- If you can’t get the quality or reliability you need through prompting, move to PEFT (like LoRA).
- If your task is highly complex and PEFT isn’t cutting it, you might consider Full Fine-Tuning.
- Training from scratch is for the model builders, not the model users.
By understanding the trade-offs between these approaches, you can choose the right tool for the job and effectively shape your LLM to meet your needs.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!