
This guide provides a comprehensive overview of the machine learning (ML) project lifecycle, designed to align stakeholder expectations with the realities of ML development. Key takeaways include:
- Iterative, Not Linear: ML projects are cyclical and involve continuous refinement. Early stages are often revisited as the project evolves.
- Data is Foundational: A significant portion of project effort, typically 60-70%, is dedicated to data collection, cleaning, and feature engineering. The quality of the data directly determines the success of the model.
- Early Feasibility is Crucial: A preliminary study can de-risk projects by validating the approach and identifying data gaps before major resource commitment.
- Success is a Partnership: Clear communication, defined business metrics, and stakeholder involvement at each stage are critical for achieving project goals.
Note: The data science process lifecycle covers general process frameworks (e.g., CRISP-DM, OSEMN, TDSP) that guide team practices across analytics and modeling. The ML project lifecycle in this article focuses on the specific, end-to-end process for building, deploying, and maintaining production ML models, emphasizing operational rigor and governance.
Executive Summary
This document is an operating and alignment guide for machine learning initiatives. It enables faster, better-informed decisions about funding, scope, sequencing, and governance by making the lifecycle, effort distribution, deliverables, and risks explicit. It is intentionally focused on cross-functional alignment; deep algorithmic theory or domain-specific modeling tricks are out of scope. Use this summary to orient, then dive selectively using the Audience Matrix below.
At a Glance
| Dimension | Summary |
|---|---|
| Lifecycle Stages | 8 stages: Scoping → Feasibility → Data → Features → Model → Evaluation → Deployment → Monitoring (iterative loops, not linear) |
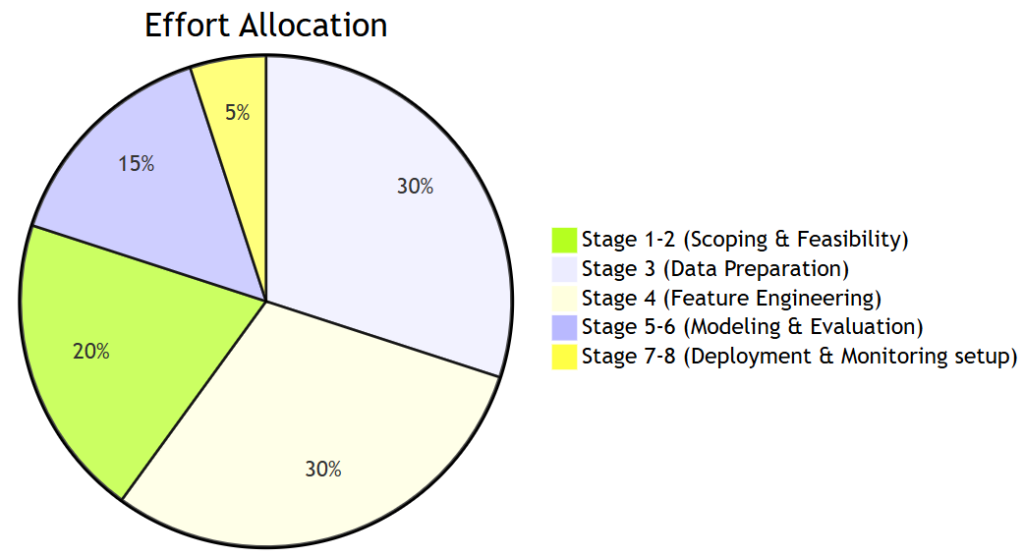
| Effort Distribution (Initial Build) | Data Preparation (~30%), Feature Engineering (~30%), Modeling & Training (~10%), Remaining stages (~30%) |
| Primary Success Drivers | Clear problem framing, high-quality labeled data, robust feature pipeline, disciplined experiment tracking, proactive production monitoring, and continuous stakeholder buy-in |
| Top Early Risks | Unstable upstream data contracts, ambiguous KPIs, unrealistic latency/cost expectations, underestimated labeling effort, regulatory/privacy blind spots |
| Governance Essentials | Version everything, model & data registry, risk register, fairness audits, reproducible pipelines, incident runbooks |
| Value Realization | Business KPI uplift tied to intermediate and foundational metrics hierarchy (see Section 5.16) |
| Generative/LLM Additions | Prompt evaluation, hallucination & toxicity audits, retrieval grounding checks, red-teaming workflow |
ROI and Payback Formulas
Let:
- Incremental Annual Benefit (B) = (Baseline KPI outcome difference × Economic value per unit)
- Total Annual Cost (C) = (People + Infrastructure + Data Acquisition + Tooling + Maintenance)
Return on Investment (ROI): \( ROI = \frac{B – C}{C} \)
Payback Period (months): \( Payback\ Period = \frac{Initial\ Investment}{Monthly\ Net\ Benefit} \)
Example (Churn Reduction):
- Baseline annual churned customers: 50,000; model reduces churn 8% ⇒ retained = 4,000
- Value per retained customer: $120 ⇒ B = 4,000 * 120 = $480,000
- Annual cost C = $300,000 ⇒ ROI = (480,000 − 300,000)/300,000 = 0.6 (60%)
- Initial investment = $150,000; monthly net benefit = (480,000 − 300,000)/12 ≈ $15,000
⇒ Payback ≈ 10 months
Audience Matrix (Selective Reading Guide)
| Role | Primary Objectives | Focus Sections |
|---|---|---|
| Executive Sponsor / Business Owner | Approve funding, monitor value realization | Executive Summary, Stage 1, ROI formulas, Success Metrics Hierarchy, Risk Register |
| Product Manager | Scope, KPI alignment, stakeholder communication | Stages 1-2, Metrics Hierarchy, Deployment, Monitoring |
| Data Scientist / ML Engineer | Experimentation, modeling rigor | Stages 2-6, Feasibility Study, Feature Engineering, Modelling, Evaluation |
| Data Engineer | Data pipelines, contracts, quality | Stage 3, Data Governance, Monitoring |
| MLOps / Platform Engineer | Reliable deployment & monitoring | Stage 7-8, Deployment, Monitoring & Maintenance, Incident Response, Cost Mgmt |
| QA / Test Engineer | Robustness, validation, regression safety | Stage 6 & 8, Model Testing, Monitoring, Incident Response |
| Security / Compliance | Privacy, regulatory adherence | Stage 7-8, Privacy & Compliance, Risk Register, Documentation Artifacts |
| Fairness / Ethics Reviewer | Bias assessment, responsible AI | Stage 7-8, Fairness, Evaluation explainability, Success Metrics Hierarchy |
| Domain SME | Validate domain relevance, edge cases | Collaboration in all stages, key questions, Feature Engineering, Failure Mode Analysis |
What Is Out of Scope
- In-depth modeling algorithms and architectures
- Vendor-specific platform configuration guides
- Detailed cost accounting spreadsheets
- Comprehensive regulatory legal interpretation (consult compliance)
How to Use This Guide
- Anchor on Executive Summary and Audience Matrix.
- Complete Stage 1 Mandatory Core items before expanding scope.
- Timebox Stage 2 feasibility; apply go/no-go criteria.
- Prioritize data and feature quality (≥60% effort) before hyperparameter hunts.
- Establish tracking, governance, and risk register early (do not retrofit).
- Use monitoring metrics table (later section) to seed dashboards.
- Review incident runbook prior to production launch.
1. Introduction
Embarking on a ML project is much like building a custom-designed house. It begins not with laying bricks, but with a blueprint—a shared vision between the architect and the future homeowner. Just as the blueprint ensures the house meets the owner’s needs, the initial phase of an ML project is about defining the business problem and success metrics to ensure the final model delivers real value.
This document outlines the end-to-end lifecycle of a ML project. Its purpose is to provide engineers, leaders, and stakeholders with a clear understanding of the iterative and complex nature of ML development. Like constructing a building, an ML project is a structured process with distinct stages, yet it requires the flexibility to revisit and revise the plan as new information comes to light. This framework is intended to enable more accurate time and effort estimations, foster realistic expectations, and ensure successful project outcomes.
2. The ML Project Lifecycle
A ML project is not a straight road but a winding path with feedback loops. Think of it as a series of sprints in an agile process. Insights gained in a later stage often require us to circle back and refine earlier decisions. The diagram below illustrates this cyclical flow, where continuous improvement is key.
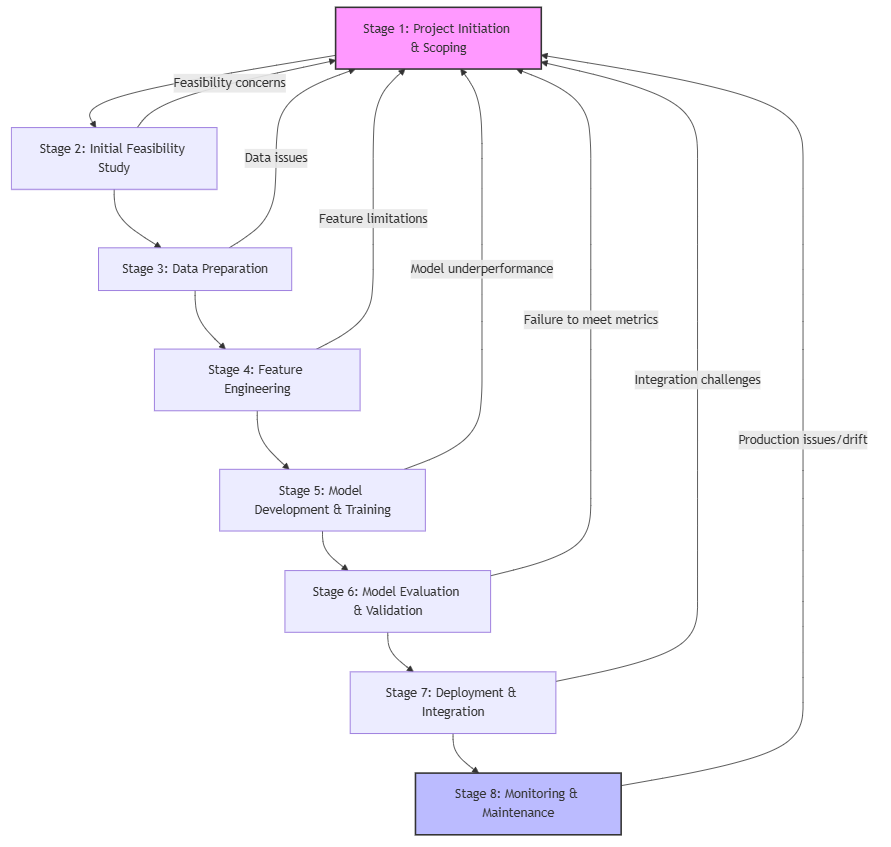
Summary of Stages
| Stage | Primary Objective | Key Deliverables | Estimated Effort |
|---|---|---|---|
| 1. Project Initiation & Scoping | Define the business problem, KPIs, and project scope. | Project Charter, Success Metrics | 5% |
| 2. Initial Feasibility Study | Quickly validate the viability of an ML approach with a small-scale prototype. | Feasibility Report, Prototype Model | 15% |
| 3. Data Preparation | Collect, clean, and explore the data. | Clean & Versioned Dataset, EDA Report | 30% |
| 4. Feature Engineering | Transform raw data into meaningful features for the model. | Engineered Feature Set, Documentation | 30% |
| 5. Model Development & Training | Build, train, and tune ML models. | Trained Models, Experimentation Logs | 10% |
| 6. Model Evaluation & Validation | Assess model performance against business and technical metrics. | Performance Report, Stakeholder Sign-off | 5% |
| 7. Deployment & Integration | Integrate the model into the production environment. | Deployed Model, API Documentation | 5% |
| 8. Monitoring & Maintenance | Monitor performance, retrain as needed, and maintain the system. | Monitoring Dashboard, Retraining Pipeline | Ongoing |
3. Detailed Breakdown of ML Project Stages
Before diving into the specifics, it is important to note that the detailed activities and deliverables outlined for each stage are intended as a comprehensive reference. Not every step will be relevant for every ML application. You should carefully select and adapt the activities that best fit the requirements, constraints, and context of your particular project. This tailored approach ensures that resources are focused where they will have the greatest impact, while maintaining flexibility to address unique challenges as they arise.
Stage 1: Project Initiation and Scoping
- Objective: Establish a precise, value-linked problem definition and confirm ML is justified over simpler alternatives while creating only the minimal artifacts required to proceed to feasibility with clarity.
- Activities:
- Mandatory Core (Complete before feasibility):
- Stakeholder Alignment (problem framing and desired outcomes).
- Problem Definition (specific, measurable prediction or decision target). For example, instead of “improve customer retention,” a better goal is “predict which customers are likely to churn within the next 30 days.”
- Success Metrics (Business + Technical KPIs, latency/throughput budgets). Define clear, measurable Key Performance Indicators. These should include both business metrics (e.g., reduce churn by 15%) and technical metrics (e.g., achieve 90% prediction accuracy with a latency of less than 0.5 seconds).
- Baseline Definition: Identify the current state (e.g., existing heuristic, manual process performance) to quantify uplift. Document baseline KPIs.
- Data Availability & Quality Snapshot (sources, approximate volume of data, key gaps). Conduct an initial inventory of available data sources and assess their quality and relevance.
- High-Level Risks (top 5 with impact/likelihood draft scores).
- Go/No-Go Feasibility Criteria (minimum uplift or signal expectations).
- Extended Due Diligence (Timeboxed; only if complexity or regulatory profile demands):
- Business Case & ROI Estimate: Outline projected value (revenue uplift, cost savings, risk reduction) versus expected investment (people, infrastructure, data acquisition, labeling). Include a simple ROI or payback period estimate.
- Alternative Solutions Assessment (rule-based, analytics, deterministic workflow comparison).
- Regulatory & Policy Review (privacy regimes, data residency, consent constraints).
- High-Level Architecture Sketch (data ingress, feature pipeline, model train/eval, serving, monitoring).
- Resourcing Plan: Map required skill sets (data engineering, MLOps, annotation, domain SME) to available capacity; highlight gaps.
- RACI Draft: Outline preliminary Responsible, Accountable, Consulted, Informed mapping for major deliverables.
- Data Contract Needs (upstream teams, schema stability expectations, cadence).
- Preliminary Compliance & Ethics Considerations (sensitive attributes, fairness review trigger points).
- Mandatory Core (Complete before feasibility):
- Deliverables:
- Project Charter: A formal document outlining the problem statement, goals, scope, and stakeholders.
- Documented Thought Process: A record of initial ideas, assumptions, and the reasoning behind the chosen approach.
- Stakeholder Feedback Loop: A process for incorporating feedback throughout the project.
- Baseline and Business Case Summary: Clear articulation of expected uplift vs current state.
- KPI Definition Sheet: A detailed list of business and technical metrics.
- Data Availability Snapshot: An overview of data sources, quality, and gaps.
- Risk and Compliance Register (Initial Draft).
- High-Level Architecture Diagram.
- RACI Matrix (Initial).
- Initial Risk Register.
- Feasibility Go/No-Go Criteria.
- Architecture Diagram (initial).
- A Note on Planning: This initial plan is not set in stone. It is a living document that will evolve as the team uncovers new insights and challenges. Flexibility is a key component of a successful ML project.
Ensuring Solution Alignment: All requirements from product, engineering, and architecture teams must be explicitly documented. Anything not written down is considered out of scope. - Key Questions to Address:
- Model Type: Is a deterministic, rule-based system more appropriate than a probabilistic ML model?
- Performance: What are the latency and throughput requirements?
- Risks: What are the known and unknown risks? What are the edge cases?
- Feasibility: What are the success criteria for the initial feasibility study?
- Ethics and Privacy: What are the ethical considerations, data privacy requirements, and potential biases? How will we ensure fairness?
- Interpretability: How important is it to understand why the model makes a certain prediction?
- Deployment: What is the target deployment environment? How will the model be monitored?
- Resources: What are the constraints on compute, budget, and team skills?
- Timeline: What is the expected project timeline?
- Baseline: What is the current benchmark performance and process cost?
- Value Realization: How will improvement be measured financially or operationally? What is the payback expectation?
- Alternatives: Why is ML preferred over simpler automation or rules?
- Compliance: Which regulatory frameworks apply and what constraints do they impose?
- Data Contracts: Which upstream teams must guarantee data availability and schema stability?
- Scope Discipline: What will be explicitly deferred to later phases (e.g., advanced personalization, multi-country rollout)?
Pitfalls (Stage 1):
- Vague problem statement leading to metric drift later.
- Over-engineering early artifacts before confirming data sufficiency.
- Ignoring baseline measurement causing inflated perceived uplift.
- Underestimating labeling cost or data acquisition lead time.
- Missing early regulatory or privacy constraint discovery causing later rework.
Stage 2: Initial Feasibility Study
- Objective: To quickly test the waters before diving in. This stage is about validating the viability of a ML approach with a limited dataset and simple features, de-risking the project before committing significant resources. Think of it as building a small-scale model bridge to see if the materials and design can withstand the load. By building a rapid, small-scale prototype—akin to an architect’s model or a single-span test bridge—we aim to answer one critical question: ‘Is there a strong enough signal in the data to justify the investment?‘ This stage protects the business from costly over-commitment to unviable projects.
- Activities:
- Data Sampling: Collect a small, representative sample of data.
- Rapid Feature Engineering: Create an initial set of simple, intuitive features.
- Prototype Modeling: Develop and train a basic model (e.g., a simple logistic regression or decision tree).
- Initial Assessment: Analyze the prototype’s performance to determine if the approach is promising.
- Risk Identification: Pinpoint major risks, data gaps, or technical hurdles early on.
- Stakeholder Communication: Document and share identified corner cases and potential risks that could impact the final model’s feasibility or performance.
- Baseline Comparison: Evaluate against the Stage 1 baseline (heuristic/manual process) to quantify potential uplift.
- Timeboxed Execution: Limit feasibility to a defined window (e.g., 1–2 weeks) with clear exit criteria to prevent scope creep.
- Labeling Cost Estimation: Roughly estimate annotation effort and cost (hours, rate, tooling) for full-scale data.
- Data Sufficiency Analysis: Determine approximate minimum viable dataset size for target performance (learning curve sketch).
- Compute Viability: Assess required resources (CPU/GPU hours) and whether existing infrastructure can support scale-up.
- Deliverables:
- Prototype Model: A working but basic model with preliminary performance metrics.
- Feasibility Report: A document summarizing the findings and providing a clear “go/no-go” recommendation for proceeding to the next stage.
- Baseline Uplift Summary: Quantified improvement over current process.
- Labeling Effort Estimate: Hours/cost ranges for full dataset preparation.
- Error Taxonomy (Initial).
Pitfalls (Stage 2):
- Extending feasibility indefinitely instead of enforcing timebox.
- Overfitting prototype to tiny sample, misreading true signal potential.
- Ignoring baseline comparison, reporting raw accuracy without context.
- Underestimating annotation complexity discovered only later.
- Skipping early infrastructure viability (memory/latency) checks.
Stage 3: Data Preparation
- Objective: To gather, clean, and prepare the high-quality data that will serve as the foundation for the model. This is often the most time-consuming and labor-intensive phase of the project. If the model is a high-performance engine, then data is its fuel. Poor quality fuel will lead to poor performance, no matter how sophisticated the engine is.
- Activities:
- Data Collection: Gather raw data from all relevant sources, such as databases, APIs, and logs.
- Data Cleaning: Address common data quality issues, including handling missing values, correcting inconsistencies, and removing outliers.
- Data Labeling: In supervised learning, this involves accurately annotating the data (e.g., labeling images as “cat” or “dog,” or transactions as “fraud” or “not fraud”).
- Exploratory Data Analysis (EDA): Analyze the dataset to uncover its underlying structure, identify patterns, and detect biases.
- Data Contracts: Establish explicit contracts with upstream data providers specifying schema, update cadence, quality thresholds, and escalation paths.
- Catalog Registration: Register datasets and tables in a data catalog with ownership, sensitivity classification, and lineage.
- Security Classification: Tag fields containing PII, PHI, PCI, or confidential business data; apply masking/anonymization as required.
- Class / Imbalance Handling: Assess and address label imbalance (resampling, class weighting, synthetic minority over-sampling) while monitoring for distribution distortion.
- Augmentation / Synthesis (Where Appropriate): Generate additional training samples (e.g., image transforms, text paraphrasing, tabular simulation) with clear labeling of synthetic origin.
- Data Quality SLAs: Define thresholds for completeness, freshness, duplication rate, and acceptable drift prior to model training cycles.
- Schema and Drift Checks: Implement automated validation to detect breaking changes or significant distribution shifts on ingestion.
- Label Quality Audits: Review of annotation accuracy, inter-annotator agreement, and error categories feeding back into guidelines.
- Metadata Enrichment: Store descriptive metadata (creation date, source system, transformation steps) and maintain version identifiers.
- Leakage Review: Detect potential target leakage (features derived from future information or other data which won’t be available at prediction time) and quarantine suspect columns.
- Deliverables:
- Clean, Versioned Dataset: A well-documented and reliable dataset ready for modeling.
- Data Quality Report: A summary of the data cleaning process and the final state of the data.
- EDA Report: A report with key insights and visualizations from the data exploration phase.
- Data Contract Documents.
- Catalog Entries and Lineage Mapping.
- Imbalance Handling Summary and Rationale.
- Augmentation Strategy (If Applied).
- Label Quality Audit Summary.
- Leakage Assessment Report.
Caution on Synthetic / Augmented Data: When using synthetic or augmented data, explicitly separate synthetic examples from held-out evaluation sets. Do not allow synthetic examples derived from real test samples (or their close variants) into training without clear tagging, because this can lead to over-optimistic evaluations. When synthetic generation is used to balance classes or expand rare-event coverage, validate performance on purely real holdout data and report both “with-augmentation” and “real-only” evaluation numbers.
Pitfalls (Stage 3):
- Hidden target leakage via timestamp-aligned or future-derived fields.
- Inconsistent labeling guidelines causing low inter-annotator agreement.
- Over-aggressive augmentation distorting minority class semantics.
- Delayed detection of upstream schema changes breaking pipelines.
- Neglecting data versioning leading to irreproducible experiments.
Stage 4: Feature Engineering
- Objective: To transform raw data into a language the model can understand and learn from. This is where art meets science, as we create features that expose the underlying patterns in the data to the model. Think of this as a translator converting a complex novel into simple, clear sentences for a student to analyze.
- Activities:
- Feature Creation: Generate new, informative features from existing data. For example, extracting the day of the week from a timestamp or calculating the distance between two locations.
- Feature Transformation: Scale, normalize, or encode features to make them suitable for the model (e.g., using one-hot encoding for categorical variables).
- Feature Selection: Identify and select the most relevant features to reduce noise, simplify the model, and improve performance.
- Dimensionality Reduction: Apply techniques (PCA, autoencoders, embeddings) to reduce feature space complexity where beneficial, documenting variance explained.
- Interaction and Composite Features: Systematically test feature interactions (ratios, differences, cross features) guided by domain intuition.
- Feature Leakage Screening: Re-validate that engineered features do not incorporate future or target-derived information.
- Automated Feature Validation: Implement checks for missing rate spikes, cardinality explosions, unexpected category emergence before training runs.
- Feature Store Registration: Publish stable, reusable features to a feature store with ownership, refresh cadence, and serving latency classification.
- Explainability Planning: Tag critical features for later SHAP / permutation importance analysis and define interpretability requirements.
- Scalability Assessment: Evaluate computational cost of feature transformations for real-time vs batch contexts.
- Deliverables:
- Engineered Feature Set: The final set of features that will be used for modeling.
- Feature Documentation: Clear documentation of each feature, its source, and the logic behind its creation.
- Dimensionality Reduction Report (If Applied).
- Feature Store Catalog Entries.
- Leakage Screening Log.
- Explainability Tag List and Rationale.
- Automated Validation Rules (Checklist / Config).
Pitfalls (Stage 4):
- Creating high-cardinality features that explode memory/latency.
- Failing to re-run leakage checks after new composite features.
- Engineering features not aligned with eventual serving constraints.
- Lack of documentation causing future reuse friction and duplication.
- Overuse of dimensionality reduction obscuring interpretability needs.
Stage 5: Model Development and Training
- Objective: To select the right algorithm and train a robust model that can learn from the prepared data. This is an iterative process of experimentation, much like a chef testing different recipes and cooking techniques to create the perfect dish.
- Activities:
- Algorithm Selection: Choose the most appropriate algorithms based on the problem type (e.g., classification, regression, clustering) and the nature of the data.
- Model Training: Train one or more models on the prepared dataset. This involves feeding the data to the algorithm and letting it learn the underlying patterns.
- Hyperparameter Tuning: Fine-tune the model’s parameters to optimize its performance. This is like adjusting the knobs on a complex machine to get the best possible output.
- Baseline Model Training: Establish a simple baseline (e.g., majority class, linear model) for uplift comparison.
- Structured Experimentation: Systematically vary architectures, feature subsets, and hyperparameters under controlled protocols.
- Incremental Evaluation: Continuously evaluate on validation folds; monitor learning curves for overfitting or diminishing returns.
- Refinement Cycle: Apply targeted adjustments (feature pruning, regularization, architecture tuning) guided by diagnostic metrics.
- Efficiency Profiling: Measure training/inference latency, memory footprint, and cost; identify bottlenecks for optimization.
- Hardware / Acceleration Utilization: Leverage GPUs, mixed precision, vectorization, or model parallelism where beneficial.
- Mixed-Precision and Numerical Variability: Mixed-precision training (AMP, bfloat16, float16) and some hardware-specific optimizations can change training dynamics and introduce small nondeterministic differences. When enabling these optimizations, validate candidate stability against full-precision baselines and record these checks in the experiment log.
- Early Stopping Criteria: Define objective conditions (plateau in validation metric, rising generalization gap) to halt training.
- Reproducible Pipelines: Automate data loading, feature assembly, training, and evaluation via scripts or workflow orchestrators.
- Experiment Tracking & Versioning: Log parameters, code commit, data snapshot IDs, and results (refer to Section 5 for governance).
- Stakeholder Checkpoints: Share interim performance summaries and trade-off discussions (accuracy vs latency, complexity vs interpretability).
- Ethical / Fairness Screening: Preliminary bias checks on validation predictions; flag concerning deviations early.
- QA Collaboration: Align on test case design for edge conditions and failure mode detection.
- Documentation: Capture rationale for chosen model families, discarded alternatives, and optimization decisions.
- Deliverables:
- Trained Models: One or more trained models ready for evaluation.
- Experimentation Logs: A detailed record of all experiments, including the algorithms, parameters, and results.
- Baseline vs Candidate Comparison Table.
- Performance and Efficiency Profile (latency, memory, cost).
- Early Stopping Criteria Documentation.
- Pipeline Automation Script / Workflow Definition.
Pitfalls (Stage 5):
- Chasing marginal metric gains without cost/latency awareness.
- Untracked experiments leading to unverifiable claims.
- Ignoring fairness indicators until late evaluation.
- Over-tuning on validation folds—generalization collapse on test.
- Skipping reproducibility (seeds, environment capture) early on.
Stage 6: Model Evaluation and Validation
- Objective: To rigorously evaluate the model’s performance against the predefined success metrics and ensure it generalizes well to new, unseen data. This is the final exam for the model before it graduates to production.
- Activities:
- Offline Evaluation: Test the model on a held-out test set using statistical metrics (e.g., accuracy, precision, recall, F1-score, RMSE). This provides an unbiased estimate of its performance.
- Cross-Validation / Resampling: Perform k-fold or stratified validation to assess stability and variance of metrics.
- Calibration Assessment: Evaluate probability calibration (reliability curves, Brier score, ECE) and apply recalibration if necessary.
- Stress / Adversarial Testing: Expose model to perturbed, noisy, or adversarial inputs to evaluate robustness boundaries.
- Ablation Studies: Remove feature groups or architectural components to quantify their contribution.
- Threshold / Operating Point Selection: Optimize decision thresholds using cost curves, ROC, PR analysis aligned to business trade-offs.
- Explainability Artifacts: Generate SHAP values, permutation importance, partial dependence plots for key features; document interpretation caveats.
- Failure Mode Analysis: Categorize recurring error clusters to inform targeted remediation (data augmentation, feature engineering, model choice).
- Business Validation: Present the model’s results to stakeholders to confirm that it meets the business objectives and delivers tangible value.
- Bias and Fairness Audits: Scrutinize the model for any unintended biases in its predictions to ensure it is fair and ethical.
- Rigorous QA Testing: The QA team should develop a comprehensive testing strategy to validate the model’s robustness, including testing for edge cases and potential failure points.
- Deliverables:
- Model Performance Report: A detailed report on the model’s performance, including all relevant metrics.
- Stakeholder Sign-off: Formal approval from stakeholders to proceed with deployment.
- Model Documentation: Comprehensive documentation covering the model’s architecture, features, and limitations.
- Calibration Report and Plots (If Applicable).
- Stress Test Outcomes and Robustness Boundaries.
- Ablation Study Findings.
- Threshold Selection Rationale.
- Explainability Artifact Bundle.
- Failure Mode Catalog.
Pitfalls (Stage 6):
- Selecting thresholds optimistically without cost curve alignment.
- Over-relying on a single test split—misjudging variance.
- Misinterpreting SHAP artifacts without domain SME review.
- Ignoring calibration defects leading to poor downstream decisioning.
- Failure mode clusters left undocumented, slowing remediation.
Stage 7: Deployment and Integration
- Objective: To deploy the model into a production environment where it can start making predictions and delivering value. This is where the model goes from a research project to a real-world application.
- Activities:
- Model Packaging: Package the model and all its dependencies into a deployable format.
- Deployment Strategy: Choose the most appropriate deployment method, such as a REST API for real-time predictions, a batch prediction job for offline processing, or an on-device deployment for mobile applications.
- Integration: Integrate the model into the existing application or business workflow.
- Environment Parity: Ensure training, staging, and production environments are aligned (libraries, hardware class) to reduce inference discrepancies.
- CI/CD Pipeline: Automate build, test (unit, integration, smoke), security scan, and deployment stages with gating metrics.
- Infrastructure as Code (IaC): Define model-serving infrastructure (containers, serverless functions, load balancers) declaratively.
- Secrets and Configuration Management: Securely manage credentials (DB/API keys), model version config, and feature endpoint addresses.
- Load and Performance Testing: Validate latency, throughput, and resource utilization under realistic and peak load scenarios.
- Observability Instrumentation: Embed structured logging, tracing, and metrics emission (request counts, error codes, timing).
- Security Hardening: Apply container scanning, dependency vulnerability checks, network policy restrictions.
- Compliance Gates: Verify model card, risk register updates, and fairness review completion before production promotion.
- Rollback Strategy: Predefine conditions and mechanism for swift reversion to prior stable model.
- Deliverables:
- A Deployed Model: A live model serving predictions in the production environment.
- API Documentation: Clear documentation for the model’s API, if applicable.
- Deployment Pipeline Definition (CI/CD).
- Performance Test Report.
- Observability and Logging Specification.
- Security and Compliance Checklist (Signed Off).
- Rollback / Recovery Plan.
Pitfalls (Stage 7):
- Missing rollback plan causing prolonged degraded service.
- Environment mismatch creating inference drift vs training behavior.
- Insufficient load testing leading to latency SLO breaches at peak.
- Opaque logging hindering incident triage.
- Secrets mismanagement introducing security exposure.
Stage 8: Monitoring and Maintenance
- Objective: To monitor the model’s performance in production and maintain it over time. A deployed model is not a “fire and forget” solution; it requires ongoing care and attention to ensure it remains accurate and reliable.
- Activities:
- Performance Monitoring: Continuously track the model’s performance and monitor for concept drift (when the statistical properties of the target variable change over time) and data drift (when the properties of the input data change).
- Retraining: Periodically retrain the model with new data to keep it up-to-date and maintain its accuracy.
- Bug Fixing and Updates: Address any issues that arise in production and update the model as needed.
- Champion–Challenger Framework: Run candidate models in parallel against the production champion to evaluate potential promotion.
- Retraining Triggers: Define automatic triggers (performance degradation, drift score threshold, data freshness window) initiating retraining pipelines.
- Continuous Validation: Execute scheduled validation on fresh holdout slices and critical cohorts to detect silent regressions.
- SLO/SLA Enforcement: Formalize service and prediction quality objectives (latency p95, uptime %, minimum precision) with alerting.
- Explainability Drift Checks: Monitor changes in feature importance distribution to detect shifts in decision rationale.
- Security Scanning: Regularly scan dependencies, containers, and infrastructure for vulnerabilities; patch promptly.
- Dependency and License Review: Track library versions and license compliance for legal and operational risk management.
- Drift Taxonomy Maintenance: Classify drift events (data source shift, feature engineering change, population shift) and link to mitigation playbooks.
- Cost Optimization Review: Periodically assess inference cost per request and adjust autoscaling or model compression strategies.
- Feedback Loop Integration: Incorporate user / analyst corrections back into labeling and feature improvement.
- Shadow Traffic Analysis: For new candidate models, route a sample of real requests for evaluation without impacting users.
- Deliverables:
- Monitoring Dashboard: A dashboard for tracking the model’s key performance metrics in real-time.
- Retraining Pipeline: An automated pipeline for retraining and deploying updated model versions.
- Updated Model Versions: A log of all model versions and their performance over time.
- SLO/SLA Definition Document.
- Drift and Performance Alert Configuration.
- Champion–Challenger Evaluation Reports.
- Retraining Trigger Criteria Specification.
- Security and Dependency Scan Logs.
- Explainability Drift Monitoring Report.
- Cost Optimization Assessment.
Pitfalls (Stage 8):
- Alert fatigue from noisy, poorly tuned thresholds.
- Silent performance decay due to lack of cohort-level monitoring.
- Drift detected but no automated retraining trigger path.
- Ignoring inference cost growth until budget overrun.
- Champion–challenger promotions without historical performance audit.
4. The Foundational Role of Data
A common misconception in ML is that the majority of effort is spent on crafting and fine-tuning complex algorithms. The reality is quite different. The success of any ML project is built on a foundation of high-quality, relevant data.
Typically, 60-70% of the total project effort is dedicated to Data Preparation and Feature Engineering.
This significant investment is not just a preliminary step but the very bedrock of the project. The principle of “garbage in, garbage out” holds true: a model is only as good as the data it is trained on. No amount of algorithmic sophistication can compensate for poor data.
Data as a Strategic Asset, Not a Project Input
Before delving into data preparation, it is critical to adopt a modern mindset: data is not merely an input to be consumed by the project; it is a strategic asset to be curated, managed, and improved over time. The most successful ML initiatives treat their core datasets as products in their own right, with dedicated owners, quality SLAs, and a roadmap for enrichment. This perspective shifts the focus from a one-time data cleaning effort to building a sustainable, high-quality data foundation that can fuel not just one, but a portfolio of future models.
Strategic Data Considerations
Effective data management extends beyond initial preparation.
- Ownership and Stewardship: Each critical dataset should have an accountable owner responsible for quality and availability.
- Data Contracts: Formalize expectations for upstream producers—schema stability, delivery schedule, and quality thresholds.
- Ongoing Quality Monitoring: Automate checks for drift, anomaly spikes, freshness breaches, and unexpected null rate increases.
- Scalability and Storage Strategy: Plan for volume growth (partitioning, tiered storage, compression) while maintaining query performance.
- Cost Optimization: Evaluate storage class usage (hot vs warm vs archive), pruning obsolete intermediate artifacts, and leveraging columnar formats.
- Metadata Standards: Enforce consistent naming, typing, and semantic tags to accelerate discoverability and reuse.
- Access Governance: Implement role-based access controls and audit logs for sensitive datasets.
- Data Lifecycle Management: Define retention, archival, and deletion policies aligned with regulation and business need.
- Observability Integration: Expose data health metrics (freshness, completeness) alongside model metrics on centralized dashboards.
- Change Management: Introduce a formal review process for schema changes with impact assessment on downstream features and models.
Integrating Data Efforts into the Low-Level Design (LLD)
To ensure that all stakeholders have a clear and realistic understanding of the project timeline and resource requirements, the effort for data preparation and feature engineering will be explicitly documented and communicated during the Low-Level Design (LLD) phase.
This includes:
- A Detailed Data Plan: A comprehensive blueprint outlining data sources, collection methods, cleaning procedures, and labeling strategies.
- Resource Allocation: A clear assignment of personnel and tools dedicated to data-related tasks.
- A Realistic Timeline: A timeline that accounts for the iterative and often unpredictable nature of data preparation and feature engineering.
By bringing these critical data-related activities to the forefront, we can set realistic expectations, mitigate risks, and build a solid foundation for project success from the very beginning.
5. Cross-Cutting Practices, Governance, and Operational Excellence
While the staged lifecycle describes the sequential (and iterative) flow of work, a set of cross-cutting practices must be applied throughout to ensure the solution is sustainable, compliant, ethical, reproducible, and cost-effective. These practices reduce risk, accelerate iteration, and improve trust among stakeholders.
5.1 Roles and Responsibilities
Clear ownership avoids ambiguity and accelerates decision making.
- Product Owner / Business Sponsor: Defines business value, approves scope changes, signs off on success metrics.
- Data Scientist / ML Engineer: Owns experimentation, feature engineering, model training, and evaluation.
- Data Engineer: Owns data pipelines, ingestion, transformation, quality controls, and lineage tracking.
- ML Platform / MLOps Engineer: Owns model packaging, CI/CD, deployment automation, monitoring tooling, and infrastructure.
- Domain Expert / SME: Provides contextual validation of features, edge cases, and output plausibility.
- QA / Test Engineer: Designs and executes functional, performance, robustness, and regression tests for data and models.
- Security / Compliance Officer: Ensures adherence to data governance, privacy regulations, and audit requirements.
- Ethics / Fairness Reviewer (where applicable): Reviews bias, fairness, and ethical impact assessments.
5.2 Reproducibility and Versioning
Reproducibility underpins scientific rigor and auditability.
- Version Everything: Code, data snapshots, feature definitions, model artifacts, environment (containers / conda env), and configuration.
- Deterministic Pipelines: Use fixed random seeds where appropriate; log library versions and hardware context.
- Immutable Artifacts: Store trained model binaries and associated metadata (training data hash, feature schema, git commit) in a registry.
- Experiment Templates: Standardize notebooks / scripts for consistent evaluation protocols.
5.3 Experiment Tracking
Maintain a system-of-record for model evolution.
- Metadata Logged: Parameters, hyperparameters, dataset identifiers, feature set version, evaluation metrics, training duration, resource cost.
- Comparability: Enforce consistent train/validation/test splits (or stratified folds) for fair comparison.
- Promotion Criteria: Define quantitative thresholds (e.g., lift over baseline, calibration quality) before advancing a candidate.
5.4 Data Governance and Security
- Lineage: Track upstream sources, transformation steps, and ownership.
- Quality Gates: Schema validation, null rate thresholds, drift detection on key distributions pre-training and pre-inference.
- Access Controls: Principle of least privilege; segregate PII; tokenize or anonymize where possible.
- Retention Policies: Define archival and deletion policies tied to regulatory requirements.
5.5 Privacy and Regulatory Compliance
- Regulations: Assess applicability of GDPR, CCPA, HIPAA, PCI, etc.
- Data Minimization: Collect only what is necessary; justify each sensitive attribute.
- Consent and Purpose Limitation: Ensure usage aligns with user consent.
- Audit Trails: Log access and transformations for compliance review.
5.6 Fairness, Bias, and Ethical Considerations
- Sensitive Attributes: Document which are used, excluded, or proxied.
- Bias Metrics: Evaluate parity across relevant cohorts (e.g., demographic parity, equal opportunity, calibration error).
- Mitigation Strategies: Reweighting, adversarial debiasing, post-processing adjustments, feature review.
- Model Cards / Fact Sheets: Publish limitations, intended use, out-of-scope scenarios.
5.7 Human-in-the-Loop (HITL)
- Feedback Capture: Integrate mechanisms for users or reviewers to correct outputs.
- Active Learning: Prioritize uncertain or high-impact samples for labeling.
- Escalation Paths: Define when predictions trigger manual review.
5.8 Labeling Operations
- Guidelines: Create an annotation handbook with examples, edge cases, and conflict resolution rules.
- Quality Control: Inter-annotator agreement monitoring (e.g., Cohen’s kappa), spot audits, gold-standard inserts.
- Tooling: Use platforms that preserve provenance and version labels.
5.9 Deployment Strategies
- Patterns: Batch scoring, real-time APIs, streaming inference, edge/on-device.
- Release Strategies: Shadow (dark) deployment, canary, blue-green, phased rollout.
- Performance Budgets: Define latency, throughput, memory, and cost SLOs.
- Safety Nets: Fallback heuristics or last-stable model route when anomalies detected.
5.10 Monitoring Dimensions
Comprehensive monitoring extends beyond a single accuracy metric.
- Model Performance: Accuracy, precision/recall, ranking metrics (AUC, NDCG), calibration (Brier score), business KPIs (conversion lift, churn reduction).
- Data Health: Feature distribution drift (e.g., KL divergence, population stability index), missing value rates, schema violations.
- Operational Metrics: Latency percentiles (p50/p95/p99), throughput, error rates, resource utilization.
- Economic Metrics: Cost per prediction, GPU/CPU hours, cloud spend vs budget.
- Fairness Metrics: Group-wise error differentials, disparate impact ratio.
- User Feedback: Qualitative error reports, dissatisfaction codes.
5.11 Incident Response and Rollback
- Runbooks: Predefined steps for degraded performance, drift threshold breach, or ethical/legal escalation.
- Automated Alerts: Triggered on SLO/SLA violations or sudden metric deltas.
- Rollback Policy: Criteria for reverting to a previous model (e.g., >X% KPI regression sustained over Y minutes).
- Postmortems: Blameless analysis with remediation actions tracked.
Incident Runbook Template (YAML-Like):
incident_id: <auto-generated>
title: <short description>
severity: {SEV1|SEV2|SEV3}
trigger:
metric: <name>
observed_value: <value>
threshold: <value>
timestamp: <UTC>
timeline:
T+0m: <Initial detection; page on-call; freeze promotions>
T+5m: <Validate metric; check recent deployments / data ingestion logs>
T+15m: <Classify root-cause hypothesis (data drift, feature pipeline, infra, model behavior, safety)>
T+30m: <Mitigation action (rollback model version, switch to fallback heuristic, throttle traffic)>
T+45m: <Confirm KPI stabilization; gather log artifacts>
T+60m: <Stakeholder update; schedule postmortem>
roles:
incident_commander: <name/role>
data_scientist: <name/role>
mlops_engineer: <name/role>
product_owner: <name/role>
compliance_officer: <name/role optional>
rollback:
previous_model_version: <id>
rollback_command_ref: <script / pipeline reference>
validation_post_rollback: <checklist>
communication_channels:
slack: <channel>
email: <distribution list>
status_page: <link>
artifacts_to_collect:
- logs: <paths>
- metrics_snapshot: <dashboard export>
- diff: <model config differences>
postmortem:
schedule: <date>
owner: <name>
action_items_due: <date>5.12 Cost and Resource Management
- Budget Forecasting: Estimate training and inference cost early; track variance.
- Optimization: Use right-sized instances, mixed precision training, autoscaling, model pruning or distillation.
- Usage Policies: Idle resource reclamation; enforce maximum experiment runtime.
5.13 Documentation Artifacts
- Model Card / Fact Sheet: Purpose, data sources, metrics, fairness analysis, limitations.
- Data Dictionary: Feature definitions, units, allowed ranges, lineage notes.
- Feature Store Catalog: Owners, transformation logic, refresh cadence.
- Decision Logs: Rationale for major architectural or methodological choices.
- Change Log: Model version changes, dates, metrics deltas.
5.14 Risk Register
Maintain a living register capturing: risk description, impact, likelihood, owner, mitigation, residual risk. Categories: data availability, regulatory change, concept drift speed, dependency fragility, talent gaps.
Sample Risk Register Extract (Illustrative):
| ID | Description | Impact | Likelihood | Owner | Mitigation | Residual |
|---|---|---|---|---|---|---|
| R-001 | Upstream transaction schema change breaks ingestion | High | Medium | Data Engineer | Data contract + schema diff alerts + staging canary | Low |
| R-002 | Labeling throughput insufficient for model improvement timeline | Medium | High | Product / Data Scientist | Add active learning + outsource vendor ramp plan | Medium |
| R-003 | Concept drift due to seasonal behavior shift | High | Medium | MLOps / Data Scientist | Drift monitors (PSI/KL) + scheduled retraining trigger | Medium |
| R-004 | Regulatory update alters permissible feature usage (privacy) | High | Low | Compliance Officer | Quarterly compliance review + feature audit | Medium |
| R-005 | GPU cost overrun from uncontrolled large model experiments | Medium | Medium | Tech Lead / MLOps | Quota limits + experiment budgeting dashboard | Low |
Residual risk should be reassessed at governance cadences; aging risks without owner action are escalated.
5.15 Model Lifecycle and Decommissioning
- Retirement Triggers: Outperformed by successor, business objective retired, unacceptable maintenance cost, regulatory shift.
- Archival: Preserve final artifacts, metadata, and evaluation reports for audit.
- Sunset Plan: Communicate timelines, update dependent systems, revoke access tokens, clean unused feature pipelines.
5.16 Success Metrics Hierarchy
Link technical metrics to business outcomes.
- Business KPIs: Revenue uplift, cost reduction, retention improvement.
- Intermediate Metrics: Precision@K, churn recall, fraud recall at fixed false positive rate.
- Foundational Metrics: Data completeness %, labeling agreement, pipeline SLA adherence.
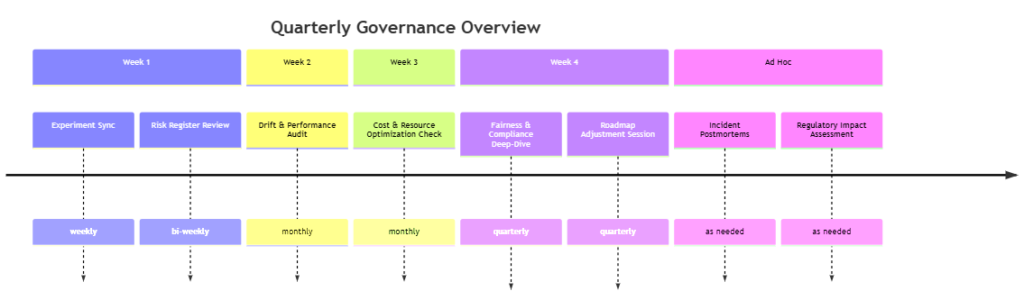
5.17 Governance Cadence
- Weekly: Experiment review, risk updates.
- Monthly: Model performance and drift audit.
- Quarterly: Fairness and compliance deep-dive, roadmap adjustments.
- Ad Hoc: Incident review, regulatory change response.
Governance Calendar (Illustrative):
5.18 Tooling Recommendations (Illustrative)
- Version Control: Git + branching strategy aligned to deployment environments.
- Experiment Tracking: MLflow / Weights & Biases / Vertex Experiments.
- Data Versioning: Delta Lake, LakeFS, DVC.
- Feature Store: Feast or platform-native equivalent.
- Model Registry: Central repository with promotion stages (Staging, Production, Archived).
- Monitoring: Prometheus + Grafana, plus ML-specific drift tools.
- Documentation: Central knowledge base or internal portal.
Principle: Embedding these cross-cutting practices early prevents costly retrofits later and elevates confidence in the system’s reliability and governance posture.
Classical ML vs. Generative / LLM Lifecycle Additions
While the core lifecycle stages remain applicable, generative and large language model (LLM) projects introduce additional artifacts, controls, and evaluation loops:
| Dimension | Classical ML Focus | LLM / Generative Extension |
|---|---|---|
| Data Sources | Tabular, structured, labeled examples | Unstructured corpora (text, code, images), retrieval indexes |
| Feature Engineering | Transformations, aggregations, encodings | Prompt templates, retrieval augmentation (RAG), embedding generation |
| Feasibility Metrics | Accuracy, AUC uplift vs baseline | Hallucination rate, toxicity, groundedness, factuality scores |
| Evaluation | Test set metrics, calibration, robustness | Multi-dimensional eval: relevance, factual correctness, style adherence, safety filters, prompt effectiveness |
| Bias & Fairness | Group performance parity | Sensitive content filtering, prompt bias mitigation, output detoxification |
| Explainability | SHAP, permutation importance | Prompt trace, attention / token-level attribution, retrieval provenance logging |
| Monitoring | Drift, performance decay, cost per prediction | Prompt lifecycle management, hallucination drift, prompt effectiveness decay, embedding index freshness, per-token cost monitoring |
| Incident Response | Performance/SLO regression, data drift | Harmful content incidents, jailbreak attempts, retrieval failure modes |
| Additional Artifacts | Model card, risk register | Prompt library, grounding evaluation report, red-teaming playbook, safety filter configuration |
| Promotion Gates | Metric thresholds, fairness audit | Safety benchmarks, hallucination ceiling, jailbreak resistance tests |
Safety & Governance Additions:
- Red-Teaming Cycles: structured adversarial prompt sets with pass/fail tracking.
- Output Filtering: layered filters (profanity, PII leakage, disallowed categories) with latency budget.
- Retrieval Provenance Logging: store document IDs and timestamps used for answer grounding for audit.
- Prompt Versioning: maintain semantic diff history; roll back on regression.
Cost Management Considerations:
- Token Budgeting: track average tokens per request; apply compression or prompt minimization strategies.
- Cache Strategy: leverage embedding or response caching for high-frequency queries.
- Distillation / Fine-Tuning vs. Prompt Engineering Trade-Off: cost-benefit analysis for additional adaptation steps.
Promotion Checklist (LLM):
- Hallucination rate below threshold.
- No critical safety filter bypasses in red-team results.
- Groundedness score meets target.
- Cost per 1K tokens within budget envelope.
- Prompt library documented and versioned.
- Retrieval index freshness SLAs green.
Consolidated Deliverables Registry
| Deliverable | Primary Stage of Creation | Owner (Initial) | Update Cadence | Purpose |
|---|---|---|---|---|
| Project Charter | 1 (Scoping) | Product Owner | Revise on major scope change | Align stakeholders on problem, KPIs, boundaries |
| Baseline & KPI Sheet | 1 | Product / Data Scientist | Quarterly or metric definition change | Anchor uplift measurement & evaluation criteria |
| Feasibility Report | 2 | Data Scientist | One-off (archive) | Go/No-Go decision, early de-risking |
| Data Availability Snapshot | 1 → refreshed in 3 | Data Engineer | Monthly / on source change | Visibility into source readiness & gaps |
| Clean Versioned Dataset | 3 | Data Engineer | Per data refresh cycle | Reproducible, stable training foundation |
| EDA Report | 3 | Data Scientist | Refresh if significant data shift | Guide feature strategies & risk awareness |
| Imbalance Handling Summary | 3 | Data Scientist | Re-evaluate after major data distribution change | Justify resampling / weighting choices |
| Feature Documentation | 4 | Data Scientist | Each new feature / quarterly audit | Interpretability, reuse, governance |
| Leakage Screening Log | 4 & 5 | Data Scientist | Each modeling cycle | Prevent future/target leakage, preserve integrity |
| Experimentation Logs | 5 | Data Scientist | Continuous | Reproducibility, audit trail, model comparison |
| Baseline vs Candidate Comparison Table | 5 | Data Scientist | Each candidate evaluation | Quantify uplift vs baseline and operational trade-offs |
| Performance & Efficiency Profile | 5 → 6 | Data Scientist / MLOps | Each promoted candidate | Inform deployment SLO feasibility |
| Model Performance Report | 6 | Data Scientist | Each evaluation cycle | Holistic metric view (technical + business) |
| Explainability Artifact Bundle | 6 | Data Scientist | Each major model release | Stakeholder trust, fairness & accountability |
| Failure Mode Catalog | 6 → evolves 8 | Data Scientist / QA | Continuous | Targeted remediation and data/feature improvements |
| API / Serving Docs | 7 | MLOps Engineer | On interface change | Integration clarity and operational support |
| Deployment Pipeline Definition | 7 | MLOps Engineer | Continuous improvement | Reliable, standardized promotion workflow |
| Observability & Logging Spec | 7 | MLOps Engineer | Review quarterly | Ensure monitoring coverage & signal quality |
| Security & Compliance Checklist | 7 | Security Officer | Release gating | Assurance of privacy/regulatory alignment |
| Monitoring Dashboard | 8 | MLOps Engineer | Continuous | Operational & performance visibility |
| Drift & Alert Configuration | 8 | MLOps Engineer | Tune on false positives/negatives | Timely detection of degradation |
| Champion–Challenger Reports | 8 | Data Scientist | Each challenger cycle | Safe incremental improvement pathway |
| Retraining Trigger Criteria | 8 | Data Scientist / MLOps | Adjust as KPIs evolve | Automate maintenance, avoid stale models |
| Risk Register | 1 → evolves all | Product Owner | Weekly quick review / monthly deep dive | Proactive mitigation and transparency |
| Model Card / Fact Sheet | 6 / 7 | Data Scientist | Each production promotion | Standardized disclosure (purpose, data, fairness) |
| Data Dictionary | 3 / 4 | Data Engineer / Data Scientist | Quarterly audit | Shared semantic understanding & lineage |
| Feature Store Catalog Entries | 4 | Data Scientist | Each feature promotion | Reuse acceleration & governance |
| Decision Logs | All | Tech Lead / Product | On major decisions | Traceability of architectural/methodological choices |
| Change Log (Model Versions) | 7 / 8 | MLOps Engineer | Each deployment | Historical audit and rollback support |
6. Summary
Delivering value with ML requires more than optimizing algorithms. It demands disciplined data foundations, structured iteration, transparent governance, rigorous monitoring, and collaborative alignment across roles. By integrating the staged lifecycle with the cross-cutting practices outlined above, organizations can accelerate time-to-value while managing risk, controlling cost, and preserving trust.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!


