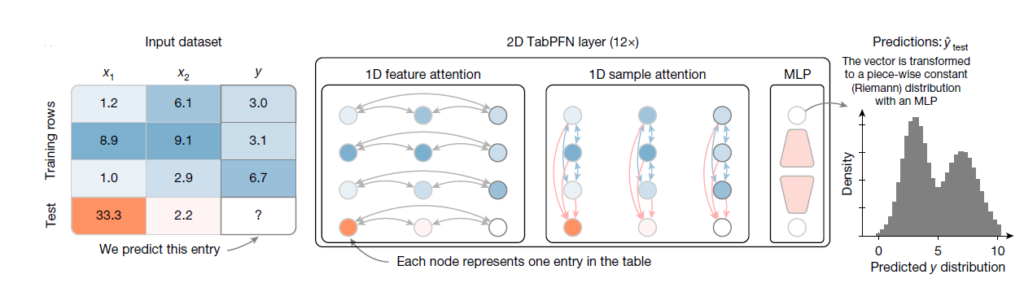
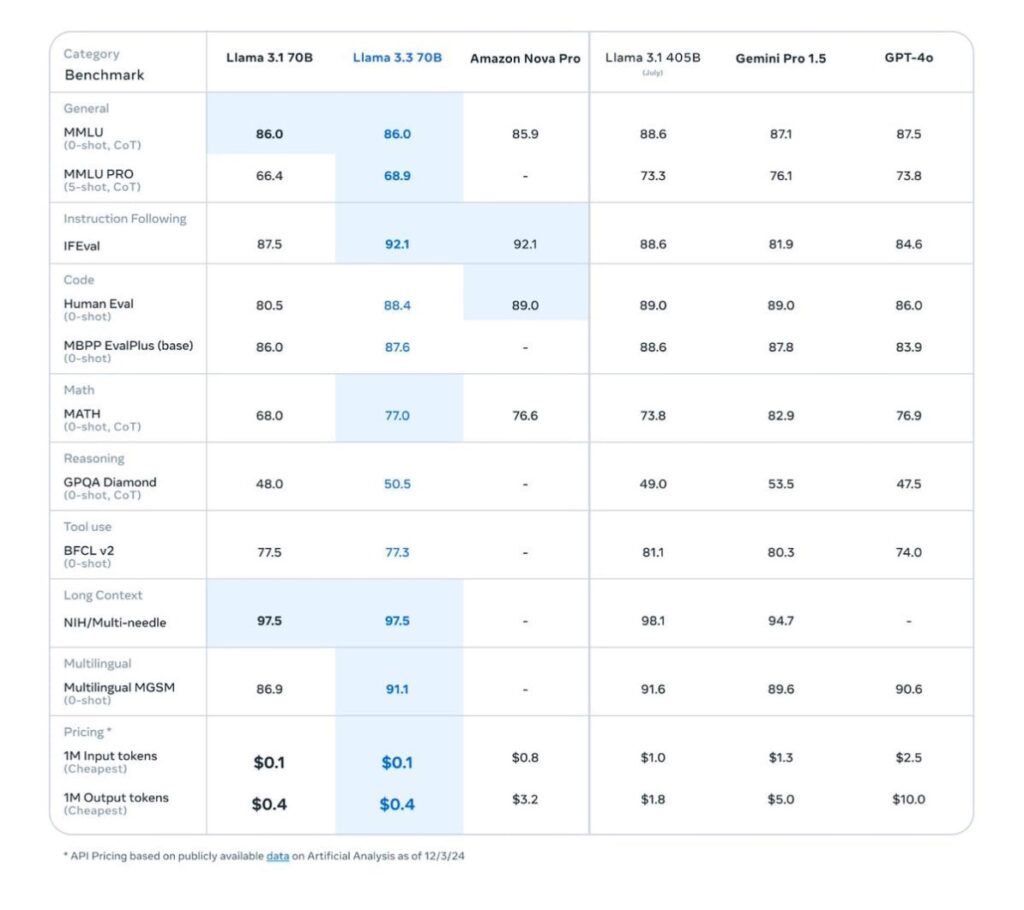
Continuous Learning for Models in Production: Need, Process, Tools, and Frameworks
Organizations are deploying ML models in real-world scenarios where they encounter dynamic data and changing environments. Continuous learning (CL) refers […]
Continuous Learning for Models in Production: Need, Process, Tools, and Frameworks Read More »