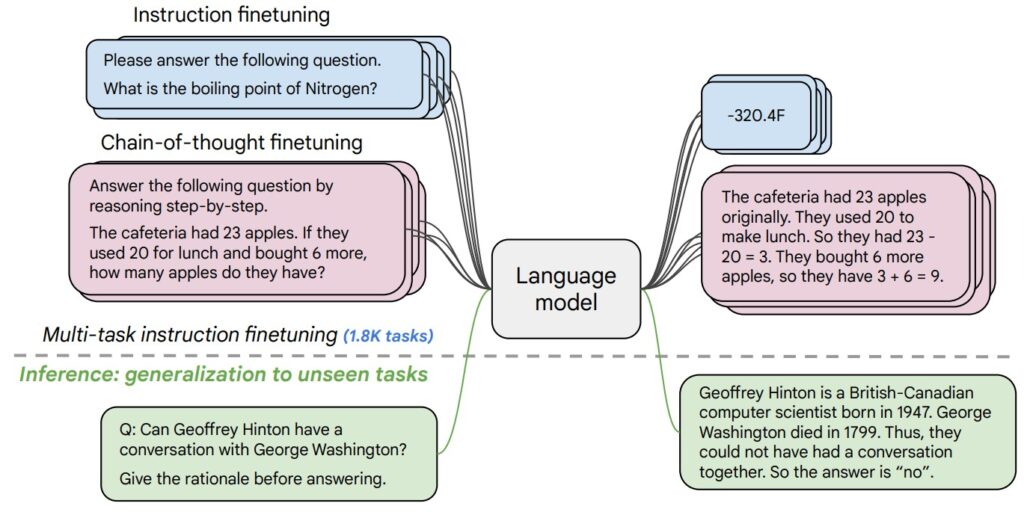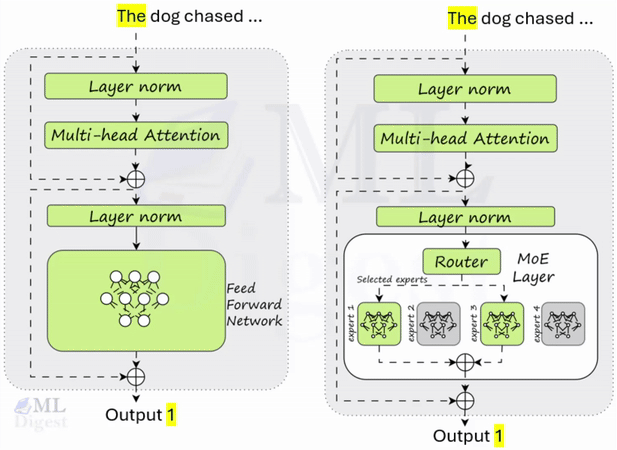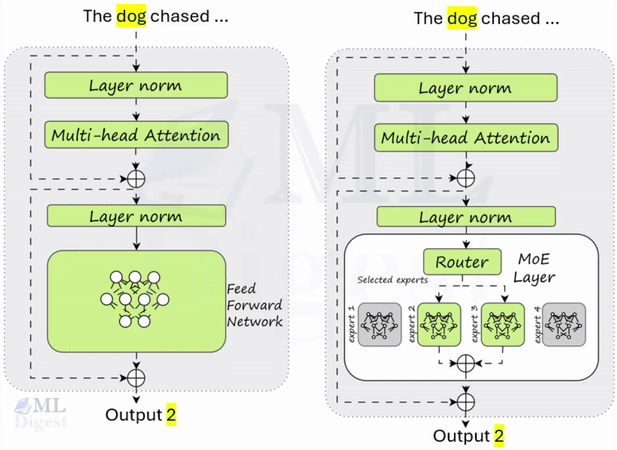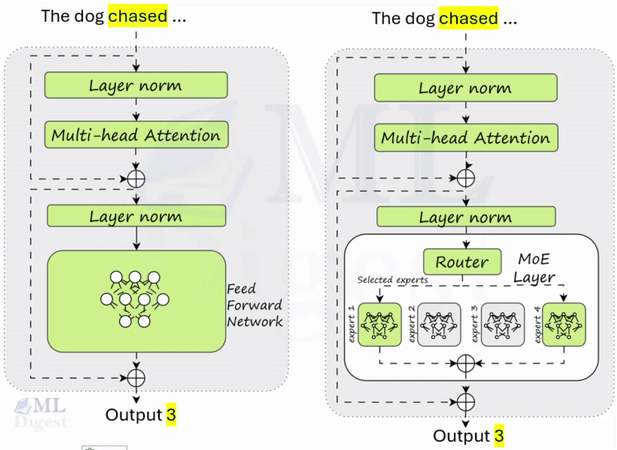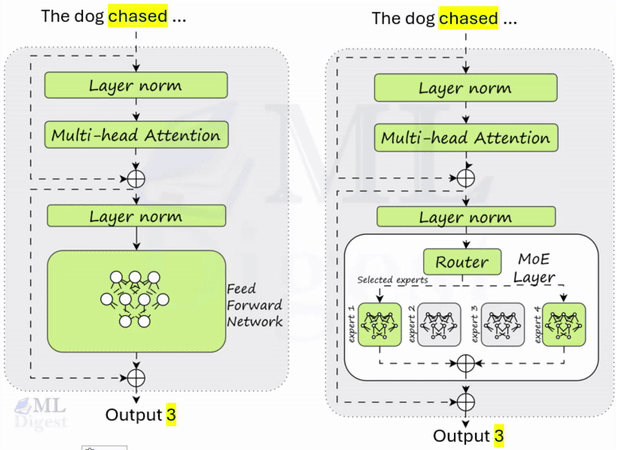
ReAct (Reasoning + Acting): A Practical Framework for Building Agentic AI
Imagine you are in a kitchen trying to cook a new, complex dish. You do not just grab random ingredients […]
ReAct (Reasoning + Acting): A Practical Framework for Building Agentic AI Read More »