
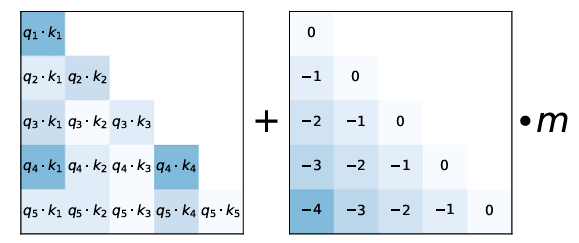
ALiBi: Attention with Linear Biases
Imagine you are reading a mystery novel. The clue you find on page 10 is crucial for understanding the twist […]
ALiBi: Attention with Linear Biases Read More »
Imagine you are reading a mystery novel. The clue you find on page 10 is crucial for understanding the twist […]
ALiBi: Attention with Linear Biases Read More »
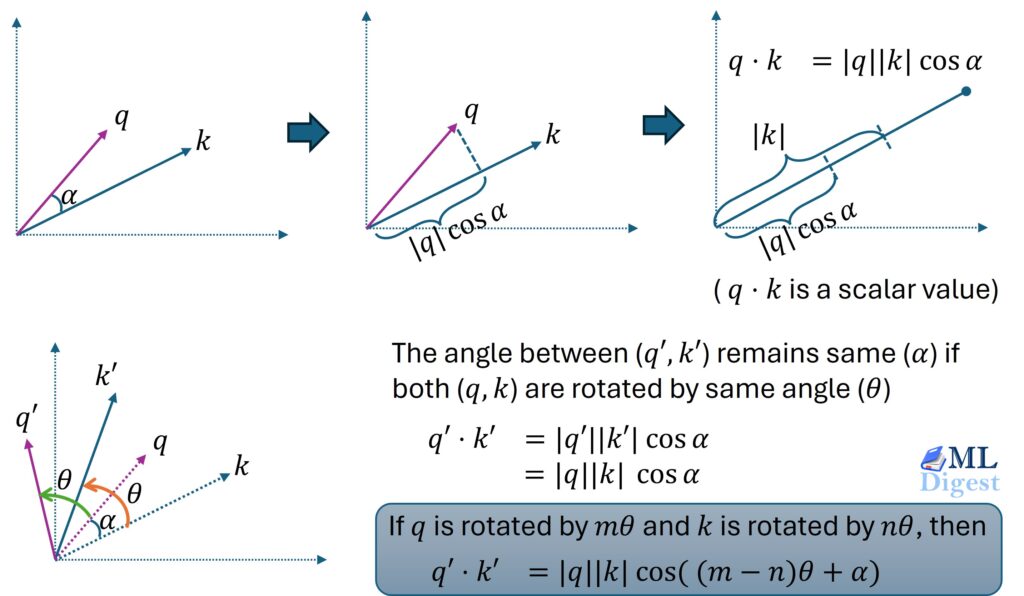
Rotary Positional Embeddings represent a shift from viewing position as a static label to viewing it as a geometric relationship. By treating tokens as vectors rotating in high-dimensional space, we allow neural networks to understand that “King” is to “Queen” not just by their semantic meaning, but by their relative placement in the text.
Rotary Positional Embedding (RoPE): A Deep Dive into Relative Positional Information Read More »
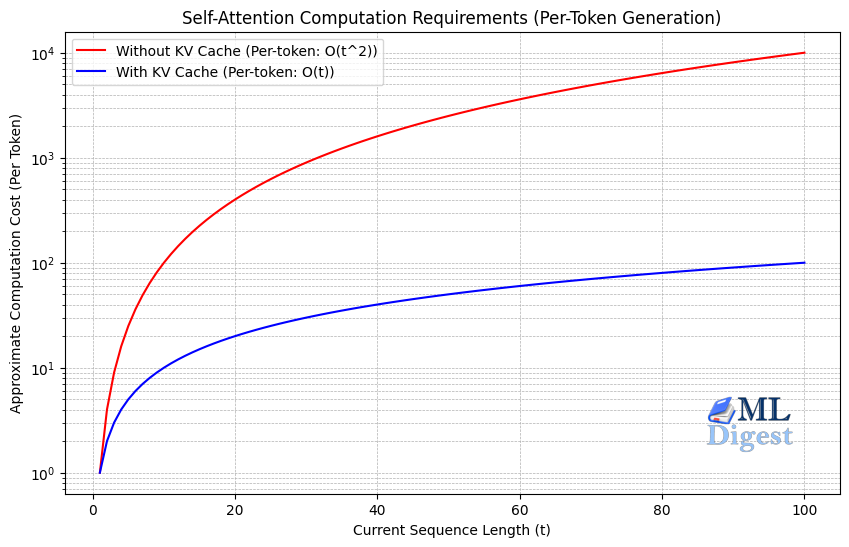
For Large Language Models (LLMs), inference speed and efficiency are paramount. One of the most critical optimizations for speeding up text generation is KV-Caching (Key-Value Caching).
Understanding KV Caching: The Key To Efficient LLM Inference Read More »
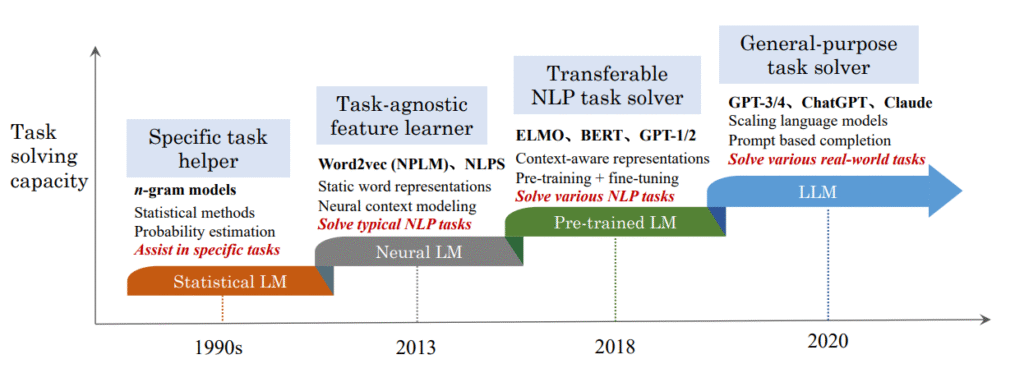
Introduction: The Quest to Understand Language Imagine a machine that could read, understand, and write text just like a human.
How Language Model Architectures Have Evolved Over Time Read More »
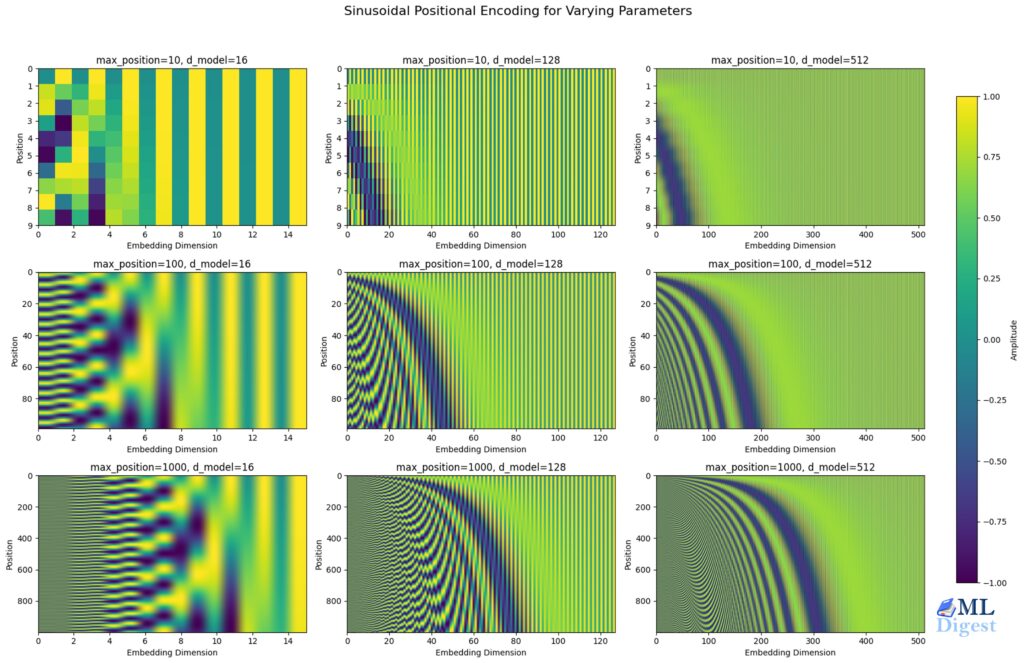
Think of a bookshelf versus a long hallway: absolute positional embeddings (APE) assign each token a fixed “slot” on the shelf, while relative positional embeddings (RPE) care only about the distance between tokens — like how far two people stand in a hallway. This article first builds intuition with simple analogies and visual descriptions, then dives into the math: deriving sinusoidal APE, showing how sin–cos interactions yield purely relative terms, and explaining how RPE is injected into attention (including T5-style relative bias). Practical PyTorch examples are provided so the reader can implement APE and RPE, understand their trade‑offs (simplicity and extrapolation vs. relational power), and choose the right approach for real-world sequence tasks.
A Guide to Positional Embeddings: Absolute (APE) vs. Relative (RPE) Read More »
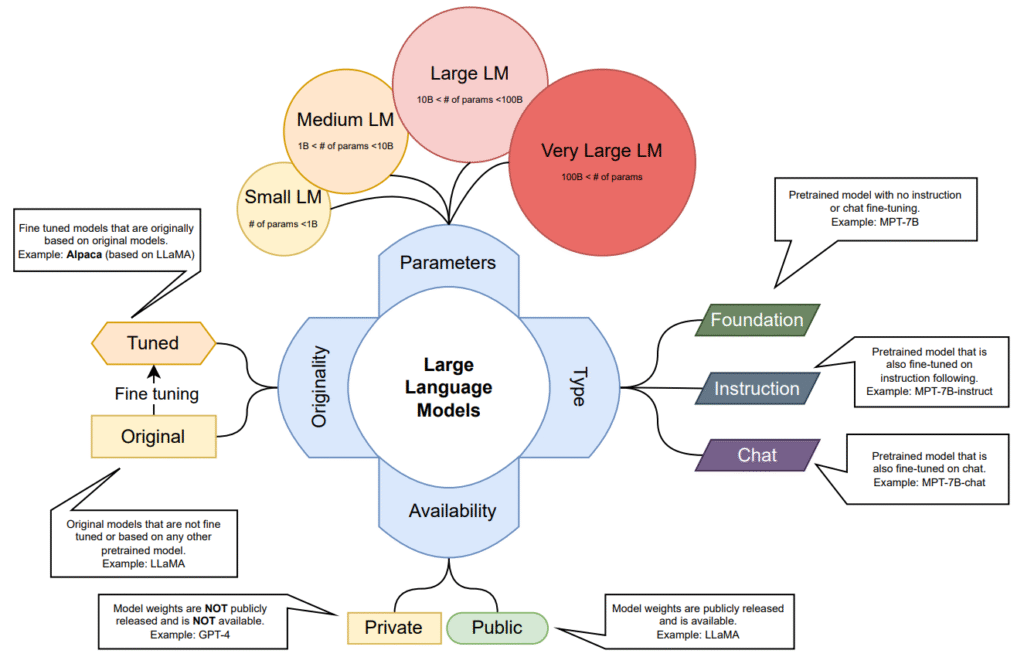
Imagine building a city: at first, you lay simple roads and bridges, but as the population grows and needs diversify,
How Large Language Model Architectures Have Evolved Since 2017 Read More »
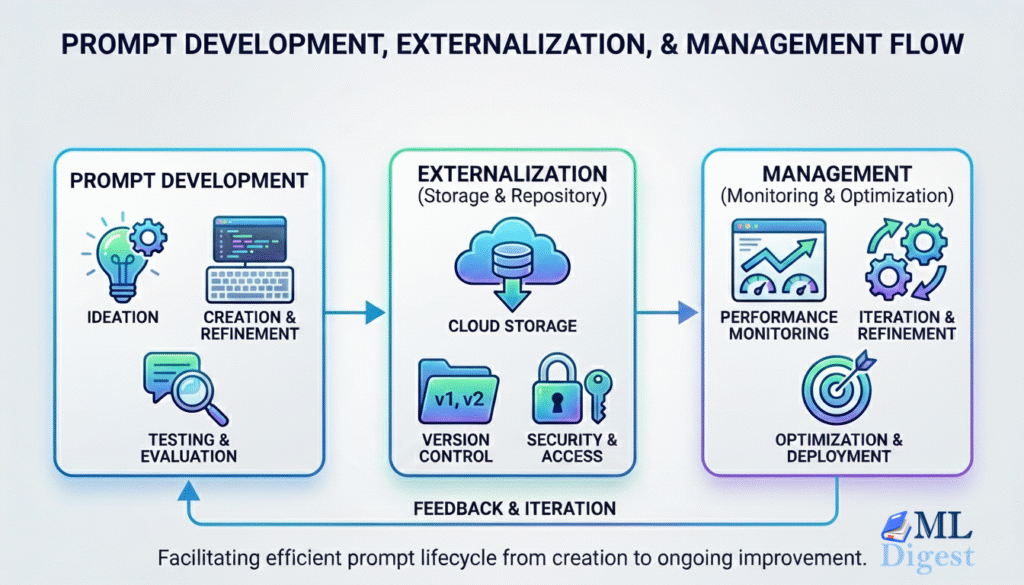
Imagine you’re a master chef. You wouldn’t just throw ingredients into a pot; you’d meticulously craft a recipe, organize your
From Prompts to Production: The MLOps Guide to Prompt Life-Cycle Read More »
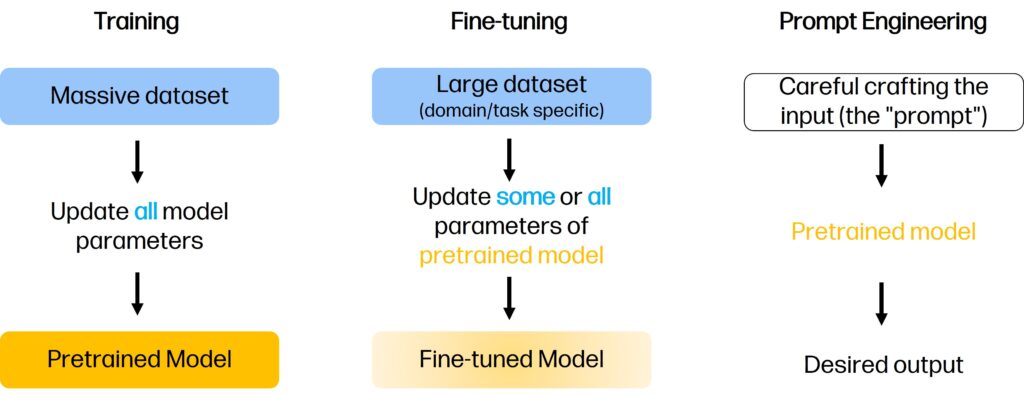
Imagine a master chef. This chef has spent years learning the fundamentals of cooking—how flavors combine, the science of heat,
The Ultimate Guide to Customizing LLMs: Training, Fine-Tuning, and Prompting Read More »
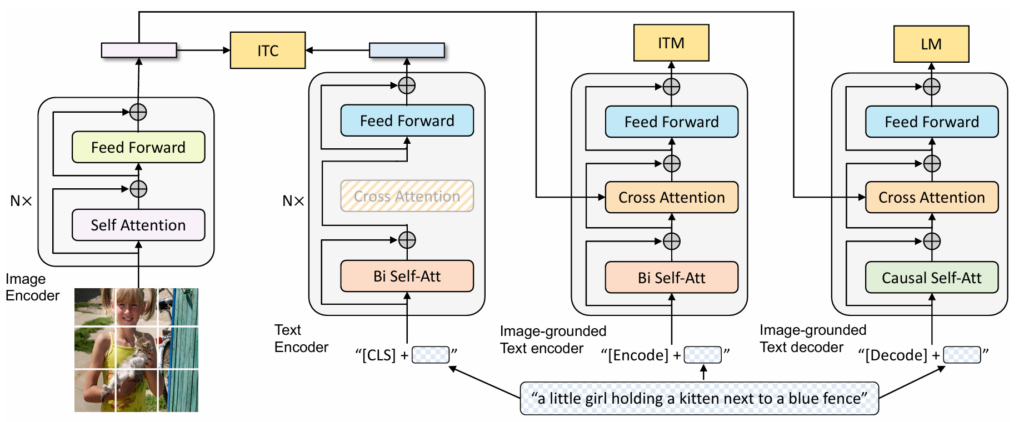
Imagine teaching a child to understand the world. You do not just show them a picture of a dog and
BLIP Model Explained: How It’s Revolutionizing Vision-Language Models in AI Read More »
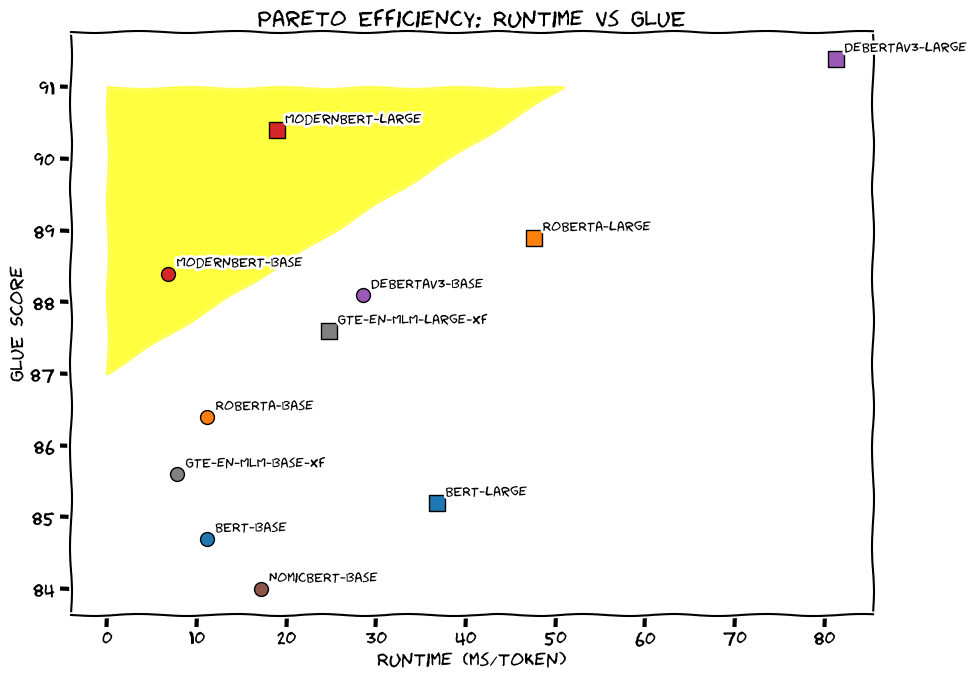
ModernBERT emerges as a groundbreaking successor to the iconic BERT model, marking a significant leap forward in the domain of
ModernBERT: A Leap Forward in Encoder-Only Models Read More »
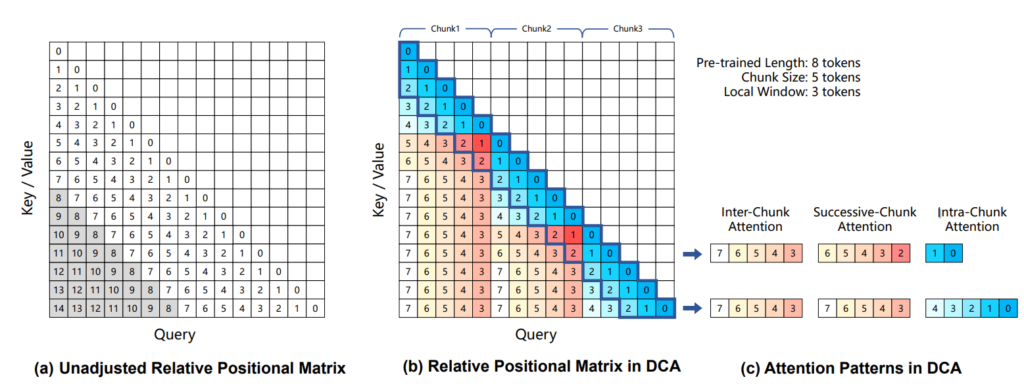
The Qwen2.5-1M series are the first open-source Qwen models capable of processing up to 1 million tokens. This leap in
Qwen2.5-1M: Million-Token Context Language Model Read More »

DeepSeek-R1 represents a significant advancement in the field of LLMs, particularly in enhancing reasoning capabilities through reinforcement learning (RL). This
DeepSeek-R1: How Reinforcement Learning is Driving LLM Innovation Read More »