
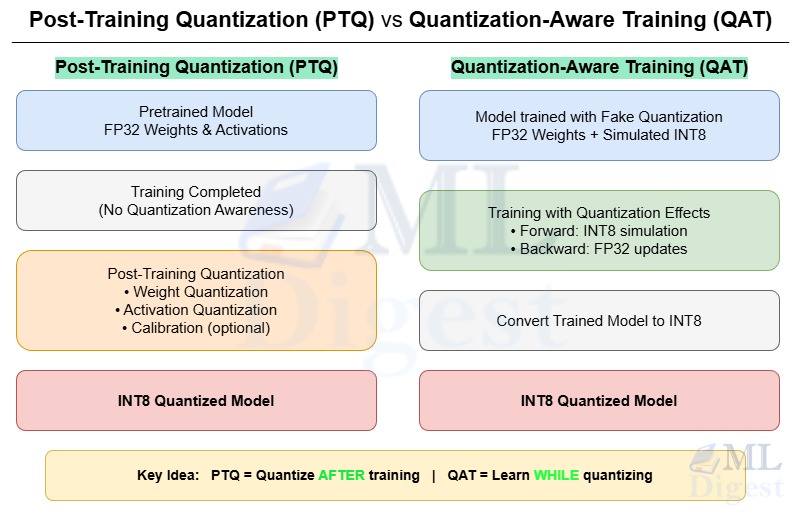
Post-Training Quantization Explained: How to Make Deep Learning Models Faster and Smaller
Large deep learning models are powerful but often too bulky and slow for real-world deployment. Their size, computational demands, and […]
Neural Network Fundamentals
Large deep learning models are powerful but often too bulky and slow for real-world deployment. Their size, computational demands, and […]
Imagine you are a master artist, renowned for creating breathtaking paintings with an infinite palette of colors. Your paintings are
Quantization-Aware Training: The Best of Both Worlds Read More »
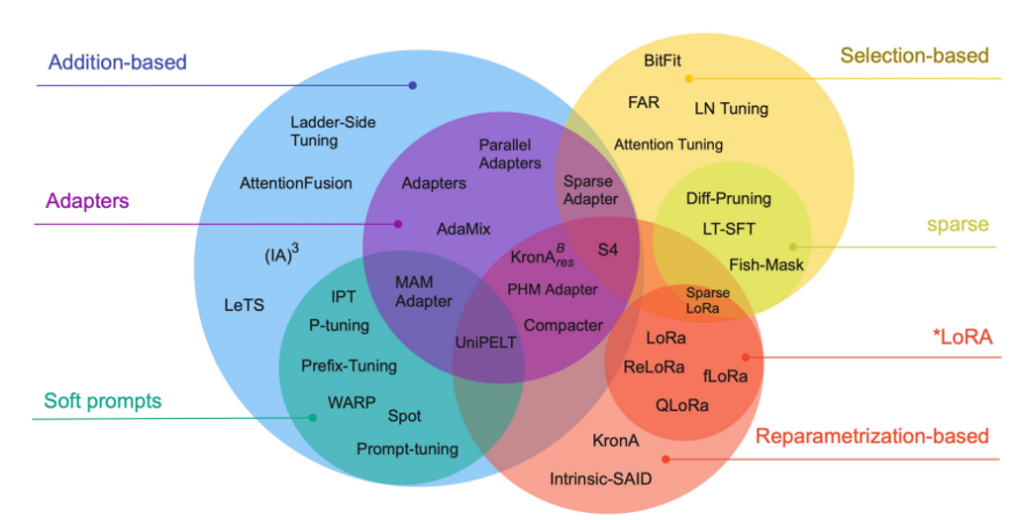
Imagine you’re trying to teach a world-class chef a new recipe. Instead of retraining them from scratch, you just show
Understanding PEFT: A Deep Dive into LoRA, Adapters, and Prompt Tuning Read More »
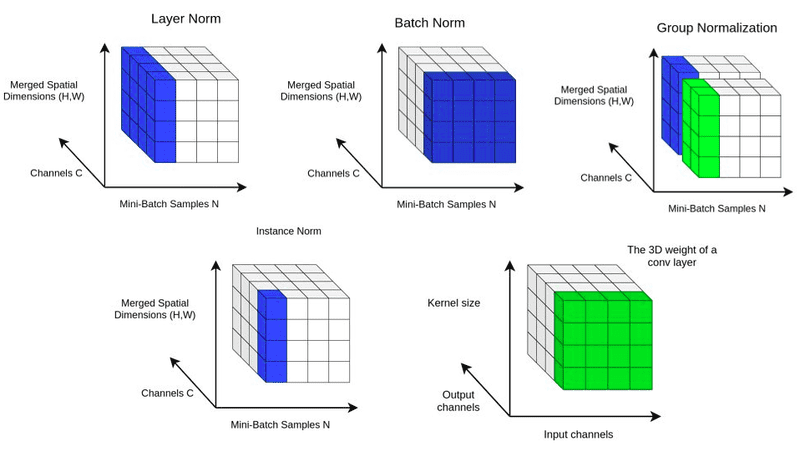
Batch normalization was introduced in 2015. By normalizing layer inputs, batch normalization helps to stabilize and accelerate the training process,
What is Batch Normalization and Why is it Important? Read More »
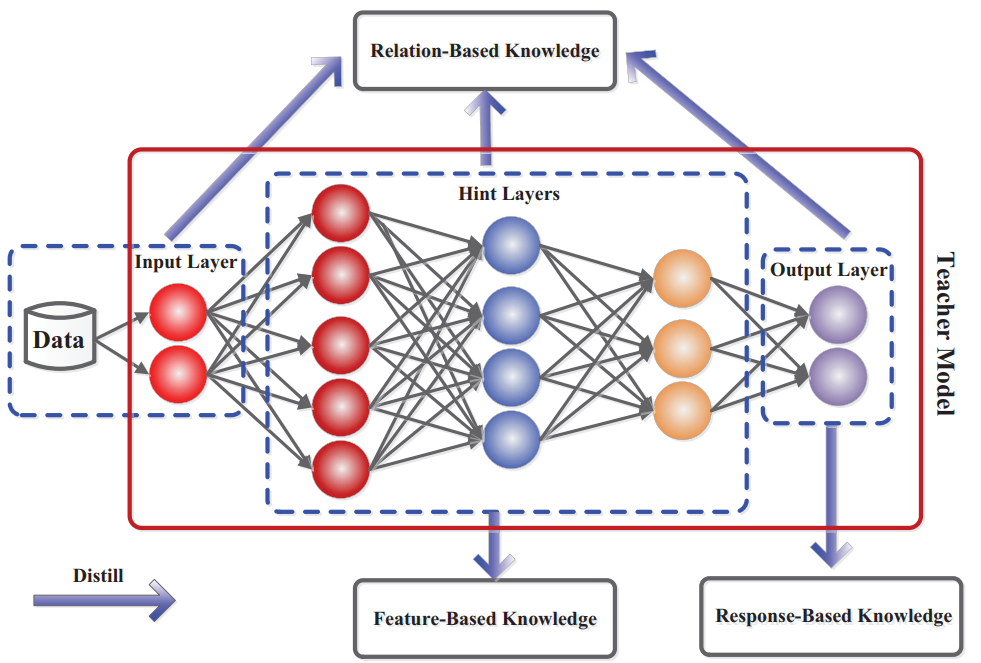
The sheer size and computational demands of large ML models, like LLMs, pose significant challenges in terms of deployment, accessibility,
Knowledge Distillation: Principles And Algorithms Read More »

Gradient scaling is a technique aimed at managing gradient magnitudes, primarily in the context of mixed-precision training. It involves adjusting the scale of gradients to prevent underflow or overflow during floating-point computations.
Gradient Scaling: Improve Neural Network Training Stability Read More »

Gradient clipping emerges as a pivotal technique to mitigate gradient explosion and gradient vanishing, ensuring that gradients remain within a manageable range and thereby fostering stable and efficient learning.
Gradient Clipping: A Key To Stable Neural Networks Read More »

One of the critical issues in neural networks is the problem of vanishing and exploding gradients as the depth of
Residual Connections in Machine Learning Read More »
Weight initialization in neural networks significantly influences the efficiency and performance of training algorithms. Proper initialization strategies can prevent issues
How to Initialize Weights in Neural Networks: A Deep Dive Read More »
Two critical issues that often arise in training deep neural networks are vanishing gradients and exploding gradients. These issues can
The Vanishing and Exploding Gradient Problem in Neural Networks: How to Overcome It Read More »
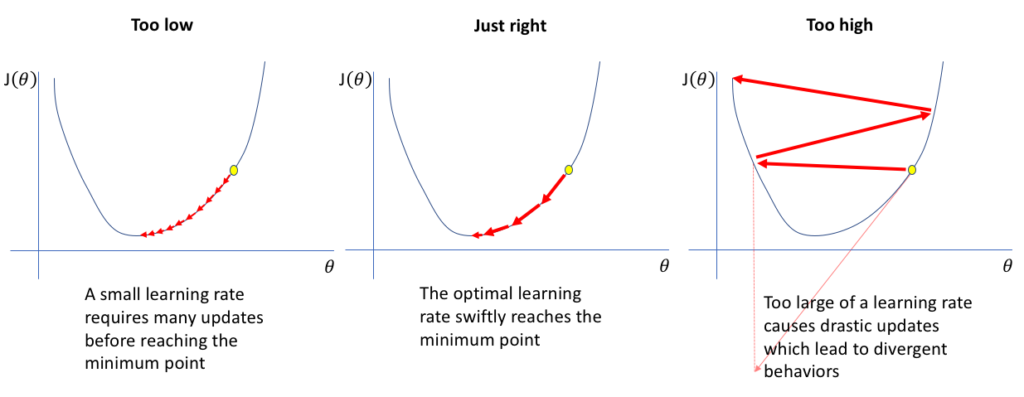
The training process involves optimizing a model’s parameters to minimize the loss function. One crucial aspect of this optimization is
How to Choose the Best Learning Rate Decay Schedule for Your Model Read More »

In ML and statistical modeling, the concept of bias-variance trade-off is fundamental to model performance. It serves as a guiding
Understanding the Bias-Variance Tradeoff: How to Optimize Your Models Read More »