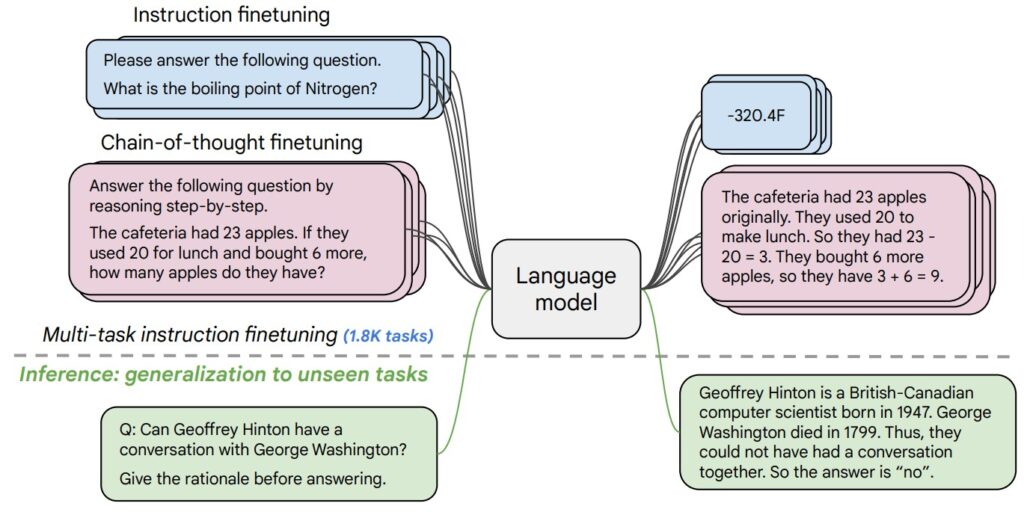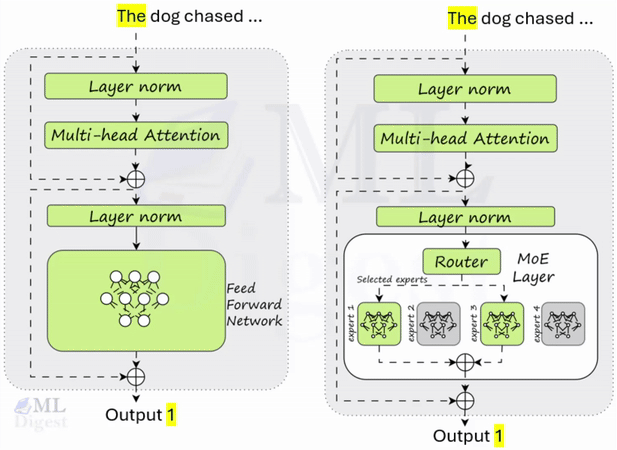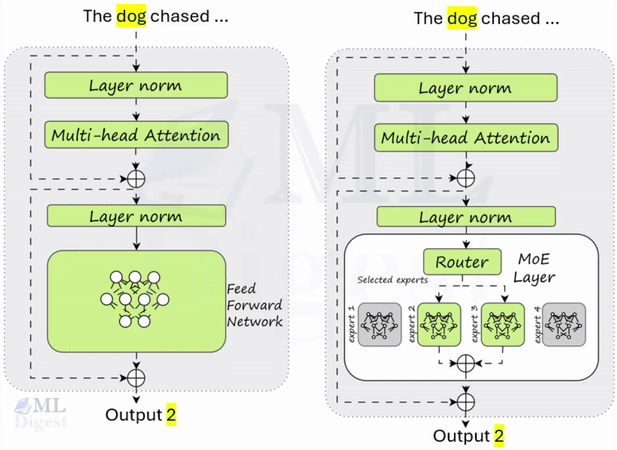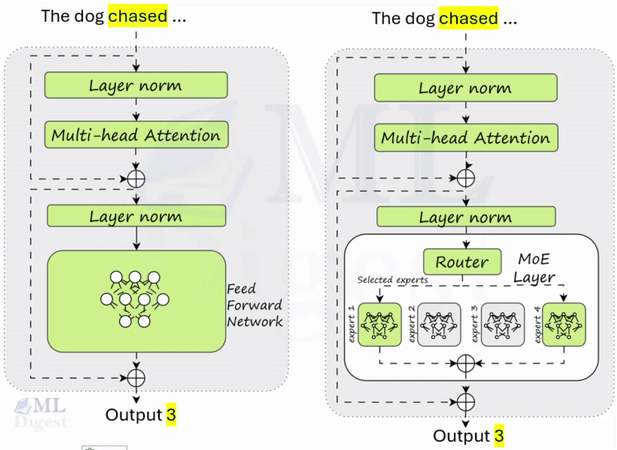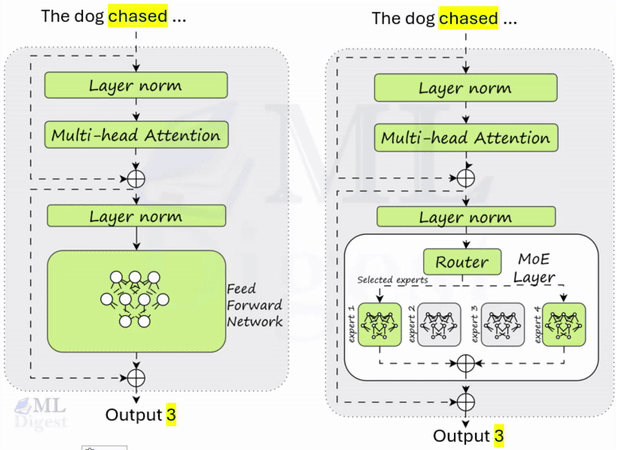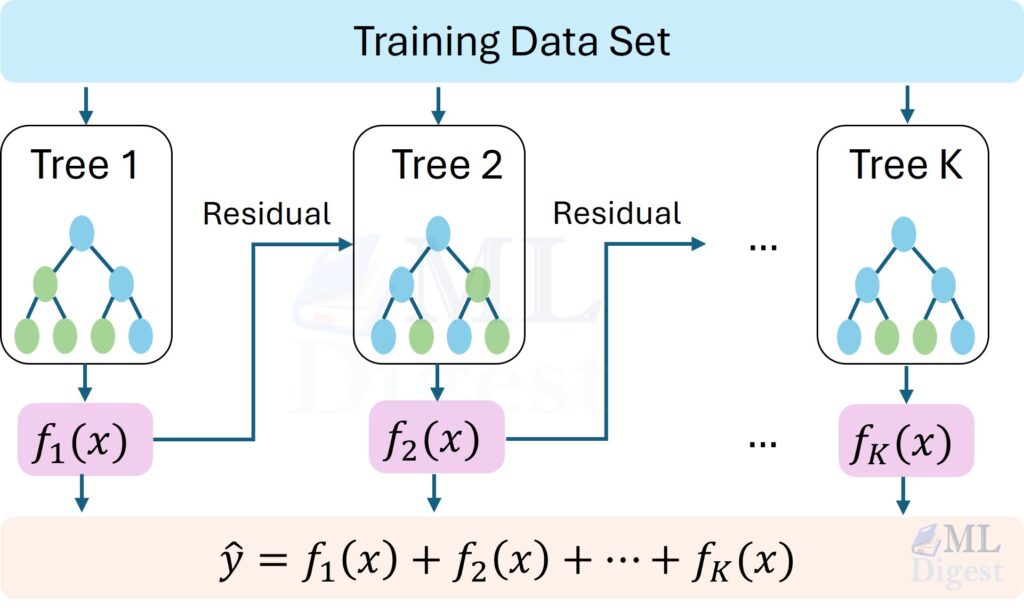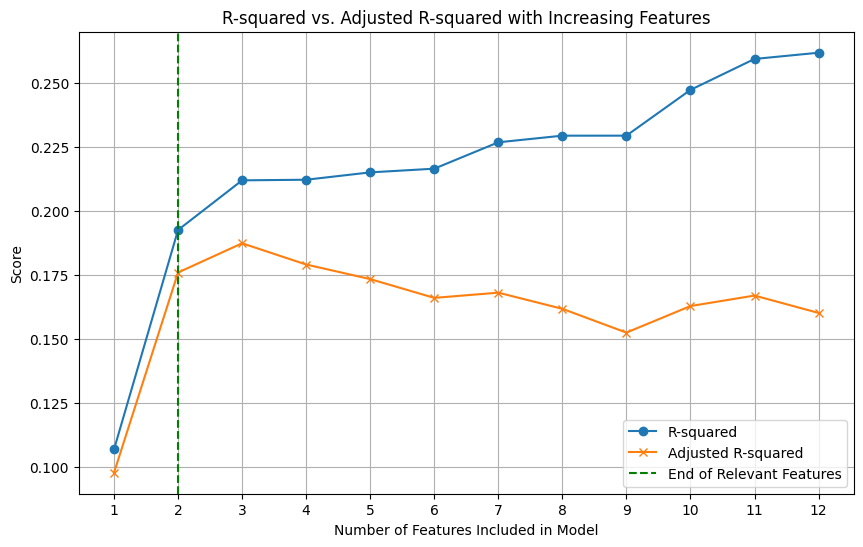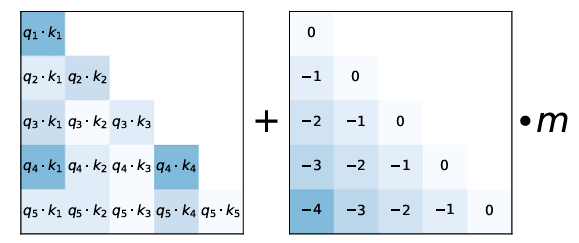
Retrieval-Augmented Generation (RAG): A Practical Guide
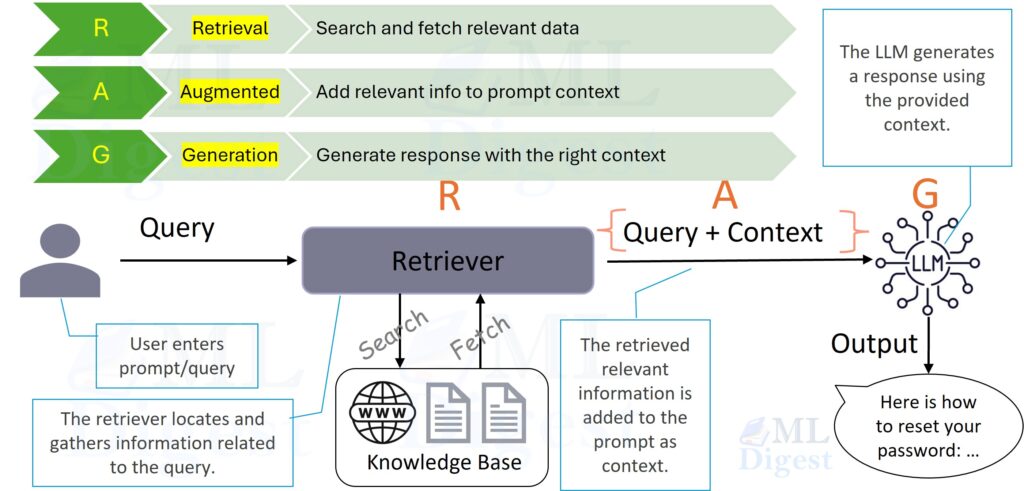
Retrieval-Augmented Generation (RAG) is a technique that acts as an open-book exam for Large Language Models (LLMs). It allows a […]
Retrieval-Augmented Generation (RAG): A Practical Guide Read More »