Imagine you have just built a high-performance race car engine (your Large Language Model). It is powerful, loud, and capable of incredible speed. But an engine sitting on a stand in a garage is useless. To make it valuable, you need to decide where to put it. Do you put it in a Formula 1 car (Cloud GPU cluster) where it has a pit crew and unlimited fuel? Do you try to fit it into a family sedan (On-Premise server) for safety and reliability? Or do you somehow shrink it down to fit into a go-kart (Edge device) for agility and fun?
Deploying an LLM is exactly this challenge. Deployment is the bridge between a trained model and a usable product. It requires a carefully considered strategy to manage immense computational demands while delivering capabilities to users in a fast, reliable, and cost-effective manner.
This guide explores the critical strategies for LLM deployment, blending high-level intuition with technical rigor. It focuses on three pillars:
- Where the model lives (cloud, on-premise, edge)
- How the model is optimized (quantization, pruning, distillation)
- How the model is served (modern high-throughput inference frameworks)

This article lives mostly in the middle and bottom layers, helping you make principled trade-offs when you move from a trained checkpoint to a production system.
Part 1: The Deployment Landscape: Where Should Your Model Live?
The first major decision in deploying an LLM is choosing the right environment. This choice fundamentally impacts cost, scalability, latency, and data privacy. At a high level, there are three primary environments: cloud, on-premise, and the edge.
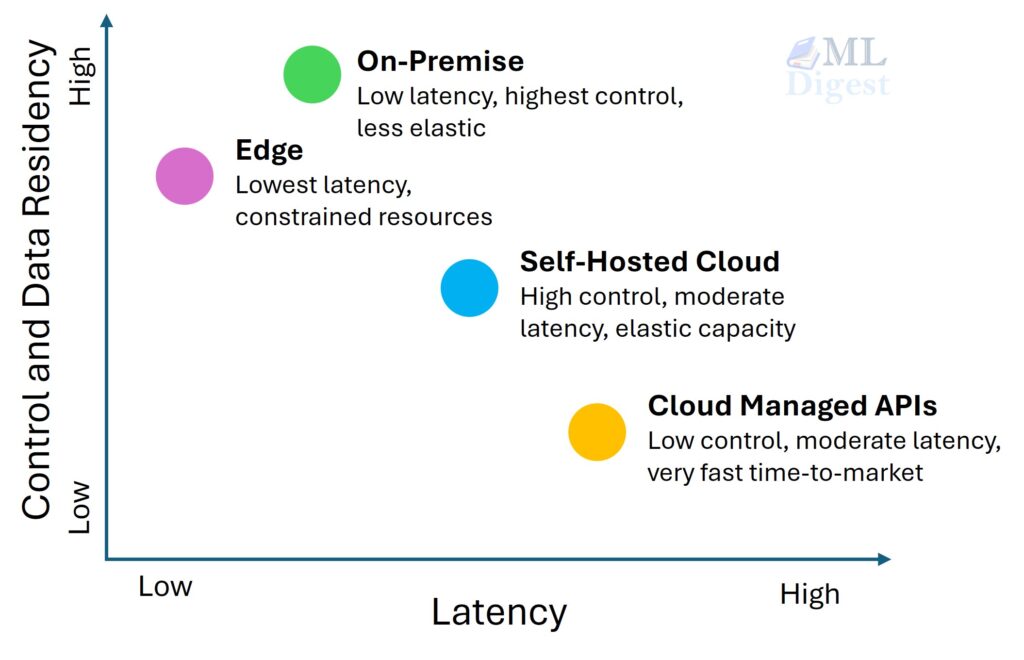
1. Cloud-Based Deployment
The cloud is the most common environment for LLM deployment, offering a balance of power and flexibility. It is further divided into two main approaches: managed services and self-hosting.
a) Managed Services (PaaS/SaaS)
Managed services are API-based solutions from major cloud providers that handle all the underlying infrastructure and model hosting for you.
- Representative platforms: OpenAI API, Amazon Bedrock, Google Vertex AI, Azure OpenAI.
- Pros:
- Zero infrastructure management.
- Instant scalability to millions of requests.
- Access to state-of-the-art, continuously improving models.
- Cons:
- Data privacy concerns because prompts and outputs are processed by third parties.
- Pay-per-token pricing can become expensive at scale.
- “Black box” models: limited visibility into architectures, weights, and serving stack; fewer customization options.
Managed APIs are ideal for early product validation, internal prototypes, and use cases where regulatory constraints are light and iteration speed is the main priority.
b) Self-Hosted on Cloud (IaaS)
This approach involves renting raw cloud infrastructure (such as virtual machines with GPUs) and deploying the model yourself.
- Leading platforms: AWS EC2 (P/G-series), GCP Compute Engine, Azure NC-series.
- Pros:
- Full control over model choice, fine-tuning strategy, and serving stack.
- Data stays within your VPC; you can integrate with existing security controls and logging.
- Potentially lower cost per token at high volume if utilization is high.
- Cons:
- Requires MLOps expertise (for example, CUDA drivers, container images, observability, autoscaling).
- Capacity planning is your responsibility; you pay for idle time.
Self-hosted cloud deployments are a natural second step once you have validated product–market fit and start caring deeply about unit economics and data control.
2. On-Premise Deployment
On-premise means hosting the LLM on your own physical servers. This is for those who need absolute control and security.
- Why choose on-premise?
- Data sovereignty: Essential for GDPR, HIPAA, or defense applications where data cannot leave a specific geography or building.
- Air-gapped environments: Necessary for government or defense applications that must operate without an internet connection.
- Integration with existing infrastructure: Reuse existing hardware, networking, and security controls.
- The trade-off:
- High upfront capital expenditure (CAPEX) for hardware and a slow procurement cycle.
- Scaling means buying, installing, and managing more physical boxes.
- Requires skilled DevOps and MLOps teams to manage hardware, networking, and the software stack.
On-premise deployments often look similar to self-hosted cloud deployments in terms of software (containers, orchestrators like Kubernetes, serving frameworks), but the hardware lifecycle and procurement model are very different.
3. Edge Deployment
Edge deployment involves running the LLM directly on an end-user’s device, such as a smartphone, laptop, or IoT device.
- Why choose the edge?
- Near-zero latency: No network round trip; responses are limited only by on-device compute.
- Privacy: Data never leaves the device, which can simplify compliance and user trust.
- Offline capability: Applications continue to work without a network connection.
- The trade-off:
- You are limited by memory, processing power, and battery life.
- Only highly optimized, smaller models can run on the edge, often with a trade-off in raw capability.
- Requires models and runtimes optimized for specific hardware such as Apple’s Neural Engine, Qualcomm’s AI Engine, or NVIDIA Jetson.
Part 2: Model Optimization – Making LLMs Lean and Efficient
Raw LLMs, often exceeding 100 billion parameters and hundreds of gigabytes in size, are too large and slow for practical deployment. Model optimization techniques are essential for shrinking these models to a manageable size while preserving as much quality as possible.
In practice, production systems often combine several of these techniques: for example, a distilled model that is also quantized and lightly pruned.
1. Quantization
Quantization is the process of reducing the numerical precision of a model’s weights (and sometimes activations).
- Intuition: Imagine representing a number with fewer decimal places. For example, changing
3.14159265to3.14. This makes the number take up less space. Quantization does something similar for the model’s parameters, often converting them from 32-bit floating-point numbers (FP32) to 16-bit floats (FP16), 8-bit integers (INT8), or even 4-bit integers (INT4). More formally, quantization maps a continuous range of values to a discrete set. - Technical details:
- Post-training quantization (PTQ): Converting weights after training. It is fast but can degrade performance if the quantization grid is too coarse or if outliers dominate the scale.
- Quantization-aware training (QAT): Simulating the quantization effect during training so the model learns to adapt to the lower precision. During training, fake quantization operators are inserted into the graph so gradients still flow while the forward pass mimics lower precision.
In deployment, quantization provides two main benefits: smaller model size (important for edge devices and cold-start times) and higher throughput (more parameters can be processed per unit of GPU or CPU memory bandwidth).
2. Pruning
Pruning involves identifying and removing redundant or unimportant weights from the model.
- Intuition: Think of it as trimming the dead branches off a tree. Many connections (weights) in a neural network have very little impact on the final output. Pruning sets these near-zero weights to exactly zero, effectively removing them.
- Technical details:
- Unstructured pruning: Individual weights are removed based on magnitude or other criteria. This leads to sparse weight matrices that require specialized kernels or hardware to realize speed-ups.
- Structured pruning: Entire groups of weights, such as channels, neurons, or attention heads, are removed. This creates a smaller, dense model that can run efficiently on standard hardware without any special libraries.
In LLMs, structured pruning of attention heads and MLP neurons is particularly attractive because it maps cleanly to smaller matrix multiplications and can be combined with standard libraries such as cuBLAS or TensorRT.
3. Knowledge Distillation
Knowledge distillation is a technique for training a smaller “student” model to mimic the behavior of a larger “teacher” model.
- Intuition: The large, powerful teacher model “teaches” a compact student model how to make predictions. The student learns from the teacher’s final outputs (the hard labels) as well as its internal reasoning (the soft labels, or probability distributions).
- Process:
- A large, pre-trained teacher model is used to generate predictions on a training dataset (often at a higher temperature to expose more of the “dark knowledge” in the distribution).
- A smaller student model is trained to not only predict the correct answer but also to replicate the probability distribution of the teacher’s output.
- The result is a small model that captures a significant portion of the teacher’s knowledge at a fraction of the computational cost.
Distilled models are especially attractive for edge and on-premise deployments where hardware is constrained but latency and throughput requirements are strict.
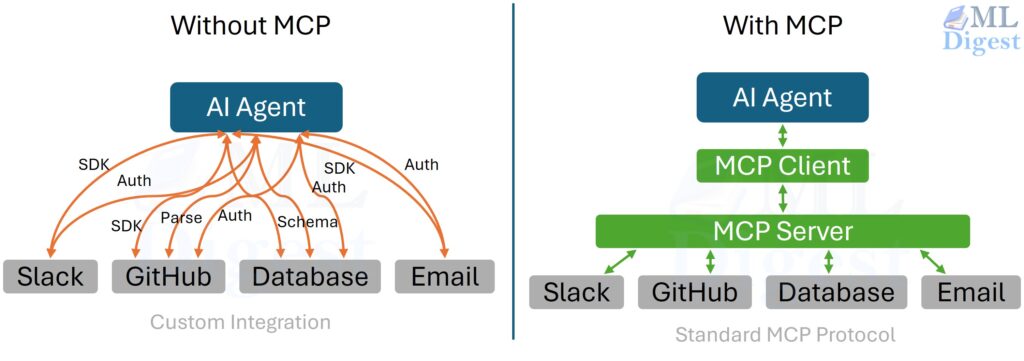
Part 3: Serving Frameworks: The Engine of LLM Delivery
An LLM serving framework is a specialized software stack designed to host an optimized model and serve inference requests with high throughput and low latency.
If you simply write a loop that calls model.generate() for each request, you end up with poor GPU utilization and long tail latencies. Modern frameworks solve this with two key innovations: continuous batching and PagedAttention, plus production features such as metrics, logging, and autoscaling hooks.
1. Continuous Batching: The “Tetris” of Inference
- The problem (static batching): In LLMs, if one request generates 1,000 tokens and another generates 10, static batching waits for the 1,000-token request to finish before freeing up the slot. GPUs sit partially idle every time a short request finishes early.
- The solution (continuous batching): This is like a conveyor belt. As soon as a short request finishes, its slot is immediately filled by a new request while the long request is still running. The GPU is constantly working at high capacity, maximizing throughput.
Internally, frameworks maintain a queue of incoming requests and dynamically form micro-batches on every decoding step. The challenge is to do this while respecting per-request limits (such as maximum tokens) and still providing predictable latency.
2. PagedAttention: Solving the Memory Fragmentation Puzzle
- The problem: LLMs need to store the “history” of the conversation (the key–value cache) to generate the next token. Traditionally, frameworks reserved a huge contiguous block of memory for each request, guessing how long the conversation might be. This is like booking a 10-bedroom mansion for every guest just in case they bring friends. It wastes a massive amount of memory (fragmentation) and limits batch sizes.
- The solution: PagedAttention – an algorithm inspired by virtual memory and paging in operating systems. It manages the memory for attention keys and values in non-contiguous blocks (pages), which significantly reduces memory waste and allows for much larger batch sizes.
Conceptually, each request is given a logical view of its cache, while physically the cache is stored in a pool of pages that can be reused across requests. This decouples maximum sequence length from contiguous memory allocations.
Leading Serving Frameworks
Below are three representative options. A full production system often combines them with an API gateway, authentication, rate limiting, and logging.
- vLLM: A fast and easy-to-use library for LLM inference and serving, developed by researchers at UC Berkeley. It is renowned for its high-throughput performance, largely due to its implementation of PagedAttention.
# Example: Basic vLLM server-style usage from vllm import LLM, SamplingParams # Load the model (replace with your own checkpoint) llm = LLM(model="facebook/opt-125m") # Define sampling parameters sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=64) # Generate text for a batch of prompts prompts = [ "The capital of France is", "An advantage of on-premise LLM deployment is", ] outputs = llm.generate(prompts, sampling_params) for output in outputs: print(output.outputs[0].text) - Text Generation Inference (TGI): A production-ready toolkit from Hugging Face. It is a comprehensive solution that includes continuous batching, token streaming, and built-in observability with Prometheus metrics. It is often deployed as a Docker container behind a load balancer.
# Example: Launching a TGI server with Docker docker run -p 8080:80 \ -v $PWD/data:/data \ ghcr.io/huggingface/text-generation-inference:latest \ --model-id meta-llama/Llama-2-7b-chat-hf - TensorRT-LLM: An open-source library from NVIDIA that optimizes and accelerates inference on NVIDIA GPUs. It compiles LLMs into highly efficient engines and includes components for building a serving solution. It offers state-of-the-art performance but can be more complex to set up than vLLM or TGI, and it is tightly coupled to NVIDIA hardware.
Ethical considerations and pre-deployment evaluation
Before moving a model into production, explicitly evaluate and mitigate ethical risks. This short checklist is actionable and intended to slot into any deployment workflow.
- Privacy and data residency: Verify that training, fine-tuning, and prompt data handling meet legal and contractual obligations (for example, GDPR, HIPAA). If using managed APIs, confirm data retention and telemetry policies with the provider.
- Bias and fairness: Evaluate the model across relevant demographic slices and task-specific groups. Run targeted tests for known failure modes and, where possible, adjust training data or apply post-hoc mitigation (for example, calibrated rerankers or fairness-aware filtering).
- Safety and misuse potential: Conduct red-teaming and adversarial tests to probe for toxic, deceptive, or privacy-leaking outputs. Define safe-fail behaviors (for example, graceful refusal, use of guardrails, or deferral to a human) for high-risk prompts.
- Evaluation datasets and metrics: Use both automated metrics (perplexity, accuracy, ROUGE, BLEU where appropriate) and human evaluation for fluency, factuality, and task success. When evaluating factuality, prefer targeted factuality suites and retrieval-augmented checks rather than only generic metrics.
- Monitoring and incident response: Plan real-time monitoring (latency, error rates) and behavioral logging (sampled prompts and outputs) with privacy-preserving controls. Define an incident response playbook for model failures, data leaks, or safety incidents.
These considerations should influence deployment choices: for example, strict data-residency rules may push you to on-premise or private-cloud self-hosting; high safety requirements argue for conservative guardrails and human-in-the-loop workflows.
Conclusion: Choosing Your Strategy
Deploying an LLM is not a one-size-fits-all problem. It is a series of strategic trade-offs between performance, cost, and control, and it depends entirely on your specific use case and constraints.
You can think of a simple decision flow:
- If you are validating an idea and need to ship something quickly, start with a managed API.
- If you have a clear product and expect significant volume or need stronger data controls, plan for a self-hosted cloud deployment with an optimized open-source model.
- If you operate in a highly regulated industry such as finance, healthcare, or defense, an on-premise deployment may be the only viable option.
- If your use case demands real-time, on-device features or offline operation, target the edge with heavily distilled and quantized models.
Across all of these options, the same core levers keep appearing:
- Latency: How quickly does the system respond for your users?
- Cost: What is your cost per 1,000 tokens at realistic utilization?
- Privacy and control: Where does data live, and who can see it?
The landscape of LLM deployment changes weekly. New quantization methods, distillation recipes, and serving engines appear constantly. However, the core principles of balancing latency, cost, and privacy remain the same. Start with a managed API to validate your idea, then progressively adopt optimization and self-hosting where it provides clear product and business value.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!