Introduction: The Quest to Understand Language
Imagine a machine that could read, understand, and write text just like a human. This has been a long-standing dream in the field of AI. At its core, a language model (LM) is a tool that estimates the probability of the next token given the previous ones. Conceptually, it is similar to an autocomplete system, but engineered to capture long-range dependencies, semantics, and contextual nuance.
ℹ️Interested in only LLM Evolution!!
If you are interested in LLM evolution since 2017, then follow this post.
Early attempts, known as n-gram models, simply calculated the probability of a word appearing after a sequence of n previous words. They were statistically powerful for their time but lacked any real understanding of grammar, context, or meaning. To build true understanding, models needed to learn what words mean. This is where the journey into neural networks begins, starting with the concept of representing words not as text, but as multi-dimensional numbers called embeddings. These embeddings capture the semantic relationships between words, laying the foundation for all modern language models.

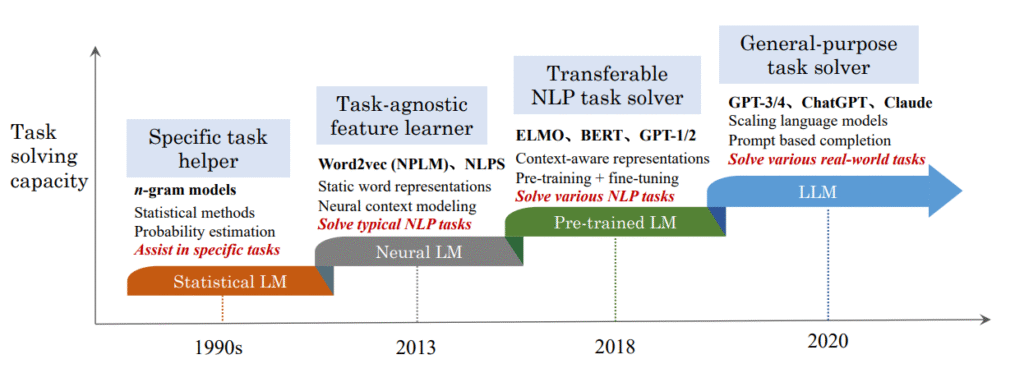
The Age of Recurrence: RNNs and LSTMs
The first major breakthrough in neural language modeling came with Recurrent Neural Networks (RNNs).
Intuition: A Network with Memory
An RNN was designed to mimic how humans process sequences. When you read a sentence, you understand each new word in the context of the ones that came before it. An RNN works similarly. It processes a sentence one word at a time, and at each step, it takes the current word’s embedding and the “memory” or “context” from the previous word to update its understanding.
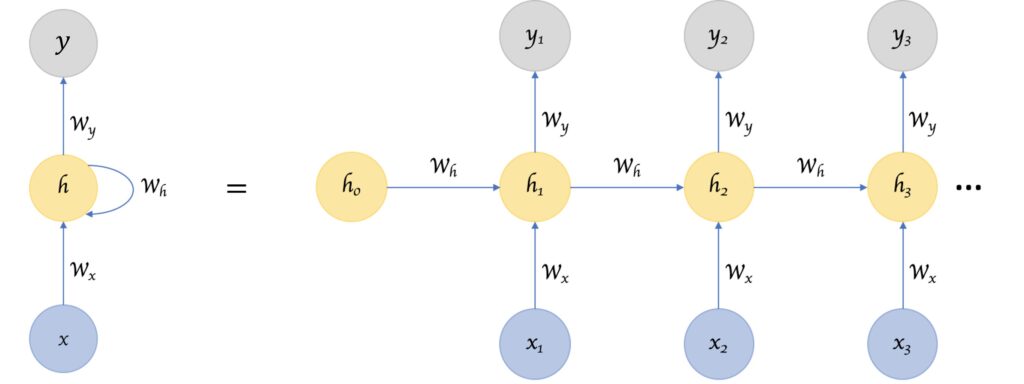
The Problem: Unstable Gradients and Short-Term Memory
While revolutionary, standard RNNs suffered from critical flaws related to how they learn over long sequences: the vanishing and exploding gradient problems.
- Vanishing Gradients: As the network processed longer sequences, the information from earlier words would fade. The network’s “memory” was too short-term to capture long-range dependencies, such as connecting a pronoun at the end of a paragraph back to the subject at the beginning.
- Exploding Gradients: Conversely, gradients could sometimes grow exponentially, leading to massive, unstable updates that would prevent the model from learning effectively. A common technique called gradient clipping was used to mitigate this by capping the gradients at a certain threshold.
The Solution: LSTM — A More Sophisticated Memory
To solve this, a more complex type of recurrent network called the Long Short-Term Memory (LSTM) network was introduced. LSTMs were specifically designed to remember information for long periods.
- Intuition: An LSTM cell is like a standard RNN cell but with a more advanced memory system. It has a dedicated “cell state” (the long-term memory) and a series of “gates” that control the flow of information.
- Forget Gate: Decides what information from the long-term memory is no longer relevant and should be discarded.
- Input Gate: Decides which parts of the new information are important enough to be stored in the long-term memory.
- Output Gate: Determines what part of the long-term memory should be used to generate the output for the current step.
For years, LSTMs and their slightly simpler cousin, the Gated Recurrent Unit (GRU), were the state-of-the-art for language tasks. However, they had one fundamental limitation: they still had to process information sequentially. This made them slow to train and still presented challenges for extremely long-range context. A new paradigm was needed.
The Transformer Revolution: Attention is All You Need
In 2017, researchers at Google introduced the Transformer architecture in a landmark paper titled “Attention Is All You Need.” This model did away with recurrence entirely and proposed a new mechanism that would become the bedrock of all modern LLMs.
Intuition: Processing in Parallel with “Attention”
The core innovation of the Transformer is self-attention. Instead of processing a sentence word by word, the self-attention mechanism allows the model to look at all the words in the sentence simultaneously. It weighs the importance of every other word to the meaning of the current word being processed.
- Analogy: When you read the sentence, “The cat sat on the mat, and it was asleep,” your brain instantly knows that “it” refers to “the cat.” Self-attention gives a model this same ability. For the word “it,” the model can “pay more attention” to “cat” than to “mat” or “sat,” allowing it to build a much richer understanding of the relationships within the text.
Because the model no longer relied on sequential processing, it could be trained much faster on massive datasets using parallel processing on modern GPUs.
The Core Components of the Transformer
- Self-Attention: This is the heart of the model. For each word, the model generates three vectors: a Query (Q), a Key (K), and a Value (V). Think of it like searching in a library. The Query is your question (the current word you are trying to understand). The Keys are like the titles of all the books in the library (all the other words in the sentence). The model compares your Query to all the Keys to find the most relevant ones. The Values are the contents of those books (the information those other words hold). The model then takes a weighted average of the Values from the most relevant words to create a new, context-rich representation of your original word. Mechanically, the model computes a score by taking the dot-product of the Query with each Key. These scores are then scaled and passed through a softmax function to create the attention weights, which determine how much of each Value vector contributes to the final output.
- Multi-Head Attention: The model does not just do this once. It runs the self-attention process multiple times in parallel, each with different, learned Q, K, and V transformations. Each “head” can focus on a different type of relationship (e.g., one head might focus on subject-verb agreement, while another focuses on pronoun references). The results are then combined to create a comprehensive representation.
- Positional Encodings: Since the model processes all words at once, it has no inherent sense of word order. To solve this, a “positional encoding” vector is added to each word’s embedding. This vector acts like a timestamp, giving the model information about the position of each word in the sequence.
- Encoder-Decoder Structure: The original Transformer was designed for machine translation and had two parts:
- The Encoder: A stack of Transformer blocks that “reads” the input sentence and builds a rich, contextual understanding of it.
- The Decoder: Another stack of Transformer blocks that generates the output sentence. Crucially, each decoder block has two types of attention layers:
- Masked Multi-Head Self-Attention: This layer allows the decoder to pay attention to the previous words it has already generated. It is “masked” to prevent it from looking ahead at words it has not yet predicted, which would be like cheating.
- Encoder-Decoder (Cross) Attention: This layer allows the decoder to look at the output of the entire encoder stack. Here, the Queries come from the decoder’s masked self-attention layer, while the Keys and Values come from the encoder’s final output. This is how the decoder knows what it is supposed to be translating or summarizing.
Post-Transformer Architectures: The Rise of Giants
The original Transformer was a complete encoder-decoder model. However, the AI community soon realized that for many tasks, you only needed one half of the architecture. This led to a branching evolution.
1. The GPT Family: The Power of the Decoder
The Generative Pre-trained Transformer (GPT) family, developed by OpenAI, uses only the decoder part of the Transformer architecture.
- Architecture: A GPT model is essentially a stack of decoder blocks. It is an “auto-regressive” model, meaning it is trained on one simple task: predicting the next word.
- Intuition: By training on a massive corpus of text from the internet, GPT models become masters of generation. They are like the ultimate autocomplete, capable of continuing any piece of text with remarkable coherence and creativity. The progression from GPT-1 to GPT-4 has been driven by a massive increase in scale—more parameters, more data, and more training—leading to emergent abilities like zero-shot and few-shot learning, where the model can perform tasks it was never explicitly trained on.
- Notable variants include GPT-2, which demonstrated the power of large-scale unsupervised learning, and GPT-3, which further pushed the boundaries with 175 billion parameters. The latest GPT models incorporate multimodal capabilities and improved alignment techniques.
2. The BERT Family: The Power of the Encoder
Bidirectional Encoder Representations from Transformers (BERT), developed by Google, uses only the encoder part of the Transformer.
- Architecture: A BERT model is a stack of encoder blocks. Unlike GPT, which can only look at previous words (left-to-right), BERT can look at the entire sentence at once (left and right), making it truly bidirectional.
- Intuition: BERT is not designed for generation but for understanding. It is trained on two main tasks:
- Masked Language Model (MLM): Random words in a sentence are hidden (masked), and the model’s job is to predict them based on the surrounding context.
- Next Sentence Prediction (NSP): The model is given two sentences and must predict if the second sentence logically follows the first.
This training process makes BERT incredibly powerful for tasks that require a deep understanding of a piece of text, such as classification, sentiment analysis, and question answering. It is worth noting that later research found the NSP task to be less impactful than MLM, and many subsequent encoder-only models have omitted it.
- Variants of BERT, such as RoBERTa (which improved training techniques) and DistilBERT (a smaller, faster version), have further expanded its applicability.
3. The T5 Family: Back to the Full Model
The Text-to-Text Transfer Transformer (T5), also from Google, returned to the full encoder-decoder architecture.
- Intuition: The T5 model frames every NLP task as a “text-to-text” problem. For translation, the input is “translate English to German: [sentence]” and the model generates the German sentence. For classification, the input is “sentiment: [sentence]” and the model generates the word “positive” or “negative.” This unified framework allows a single model to be fine-tuned to perform a wide variety of tasks with great proficiency.
- Other notable encoder-decoder models include BART (from Facebook), which combines bidirectional and auto-regressive training objectives, and mT5, a multilingual variant of T5.
4. Efficiency Innovations
Modern deployments require reducing latency and memory overhead without significantly harming quality.
- FlashAttention: A reordering and tiling of attention computations that reduces high-bandwidth memory operations, enabling longer context windows with improved throughput.
- Sparse / Linear Attention: Techniques (e.g., locality-sensitive sparsity, kernel-based transformations) approximate or constrain the O(T²) pattern to O(T log T) or O(T). They trade exact global interactions for scalable inference.
- KV Caching: For decoder-only inference, previously computed key-value pairs are stored to avoid recomputation on each new token, reducing per-token latency.
- Quantization: Post-training and quantization-aware training reduce precision (FP16 → INT8/INT4) to lower memory footprint and accelerate inference, with careful calibration to preserve accuracy.
- Distillation: A smaller student model learns behavior from a larger teacher, retaining capability with reduced serving cost.
5. Mixture-of-Experts (MoE) Architectures
To scale model capacity without proportional increases in computation, Mixture-of-Experts (MoE) architectures route different inputs to specialized sub-networks.
- Intuition: Imagine a team of specialists, each with expertise in a different area. When a complex problem arises, a coordinator assigns the task to the most suitable specialist, ensuring that each part of the problem is handled by someone with the right skills. In MoE architectures, the model acts as this coordinator, dynamically routing each input token to the expert network best equipped to process it. This allows the model to scale its capacity efficiently, as only a subset of experts is activated for each input, rather than the entire network. The result is a system that can handle diverse tasks and inputs with greater flexibility and computational efficiency.
- Benefit: Parameter capacity increases faster than per-token computation (sparse activation), improving scaling efficiency.
- Challenges: Load balancing, expert specialization drift, router instability, and added infrastructure complexity.
- Enterprise Consideration: Monitoring expert utilization and routing entropy becomes part of operational telemetry.
6. Alignment and Instruction Tuning
Raw pretrained models can be powerful yet misaligned with user intent.
- Supervised Fine-Tuning (SFT): Curated instruction-response pairs refine behavior toward helpfulness.
- Reinforcement Learning from Human Feedback (RLHF): A reward model trained from human preference comparisons guides policy optimization (e.g., PPO) to increase alignment, reduce toxicity, and improve adherence to instructions.
- Direct Preference Optimization / Alternatives: Emerging methods streamline alignment without full RL loops.
- System and Tool Integration: Structured prompting, tool invocation patterns, and guardrails (output filters, retrieval augmentation) layer on top for reliability.
7. Multimodality Extension
Integration of vision, audio, and other modalities combines modality-specific encoders (e.g., vision transformers) with language decoders via cross-attention, enabling captioning, visual QA, and unified reasoning over heterogeneous inputs.
Enterprise Considerations for Modern LLM Deployment
Operational success depends on balancing model capability with governance and resource constraints:
- Latency: Techniques include KV caching, batch adaptive scheduling, quantization, and attention window restriction for real-time applications.
- Cost Optimization: Model size right-sizing, distillation, mixed precision, on-demand scaling, and hardware-aware operator fusion.
- Observability: Structured logging of prompts, generated outputs, routing decisions (for MoE), and latency breakdown (embedding, attention, sampling). Anomaly detection over drift in token distributions.
- Governance and Compliance: PII redaction in prompts, audit trails, versioned model registries, reproducible deployment artifacts.
- Factuality and Hallucination Mitigation: Retrieval augmentation (injecting grounded context), constrained decoding (logit masking for restricted vocabularies), post-generation verification models, and iterative self-checking loops.
- Risk Management: Safety classifiers (toxicity, bias detection) in pre- and post-filtering pipelines; fallback strategies to smaller deterministic models for critical queries.
These considerations influence architectural selection: encoder-only for embedding services and semantic search, decoder-only for generative interfaces, encoder–decoder for structured transformation pipelines, and MoE variants where scaling efficiency is paramount.
Conclusion: A Continuing Evolution
The journey from simple RNNs to large-scale Transformer-based models marks a decisive shift from sequential recurrence to parallel contextualization and parameter scaling. The Transformer introduced a flexible attention mechanism that unlocked training efficiency and emergent capability. Subsequent specialization (decoder-only, encoder-only, and encoder–decoder) enabled targeted optimization for generation, understanding, and structured transformation.
The current frontier focuses on extending context length efficiently, reducing compute and memory overhead, aligning models with human intent, and integrating multiple modalities. Techniques such as FlashAttention, sparse and linear attention variants, Mixture-of-Experts routing, alignment frameworks (SFT, RLHF), and retrieval augmentation illustrate a maturation from raw capability to reliable, governed utility.
Looking forward, architectural choice should be guided by task profile: semantic embedding and retrieval (encoder-only), open-ended generation (decoder-only), structured input–output transformation (encoder–decoder), and cost-effective scaling (MoE). Reliability layers (factual grounding, observability, safety filtering) will continue to differentiate production-grade systems from research prototypes.
Despite ongoing innovation, the foundational concepts of attention-driven representation and scalable optimization remain the core pillars upon which future advances in multimodal and adaptive intelligence are likely to build.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!