Imagine trying to build a skyscraper without a blueprint. You might have the best materials and the most skilled builders, but without a plan, you’d end up with a chaotic, unstable structure. The world of data science is no different. In the quest to build powerful AI and machine learning models, brilliant algorithms and talented data scientists are like top-tier materials and builders. But to consistently deliver value and create robust, reliable solutions, they need a blueprint—a structured, collaborative process.
This is where data science process frameworks come in. They are the blueprints that guide teams through the complex journey of transforming raw data into impactful insights. Think of them as a shared language and a map that helps everyone on the team—from data engineers to business stakeholders—stay aligned, collaborate effectively, and navigate the inevitable twists and turns of a project.
Note: The data science lifecycle covers general process frameworks (e.g., CRISP-DM, OSEMN, TDSP) that guide team practices across analytics and modeling. Whereas, the ML project lifecycle focuses on the specific, end-to-end process for building, deploying, and maintaining production ML models, emphasizing operational rigor and governance.
In this article, we’ll embark on a journey through the most popular of these frameworks. We’ll start by exploring the foundational methodologies that shaped the field, and then we’ll dive deep into a modern, agile framework from Microsoft: the Team Data Science Process (TDSP). We’ll break down its components, see how it works in practice, and even look at some code to understand how to bring it to life.
What is a Data Science Process, Anyway?
At its heart, a data science process is a structured lifecycle for a project. It’s a series of stages that a team moves through to get from a business idea to a finished, working model. You can think of it like a recipe for a complex dish. Each step—from gathering your ingredients (data) to the final presentation (deployment)—is laid out to ensure a delicious and consistent result every time.
While every project has its unique flavor, most follow a similar path. Let’s look at some of the most well-known “recipes” that data science teams use.
Here are some prominent frameworks:
The Old Guard: Traditional Data Science Lifecycles
These are the frameworks that laid the groundwork for modern data science. They established the core idea that a structured process is essential for success.
- KDD Process (Knowledge Discovery in Databases)
- The Idea: Think of KDD as the original gold rush for data. The goal is to sift through mountains of raw, messy information (the “dirt”) to find valuable nuggets of insight (the “gold”). It’s a systematic process of cleaning, preparing, and then “mining” the data to uncover hidden patterns. While people often say “data mining,” they’re usually thinking of the whole KDD process, where data mining is just one crucial step—the moment you finally spot the gold.
- The Flow: The journey from dirt to gold follows a clear path: you get the data, clean it, integrate it from different sources, select the relevant parts, transform it into the right shape, and then you mine it. Finally, you evaluate what you’ve found and present your treasure.
- Pros: It’s a thorough, iterative process that’s great for finding customer trends and spotting anomalies.
- Cons: It’s a bit dated and doesn’t cover modern concerns like data ethics or team roles. It can also be slow if the business goals aren’t crystal clear from the start.
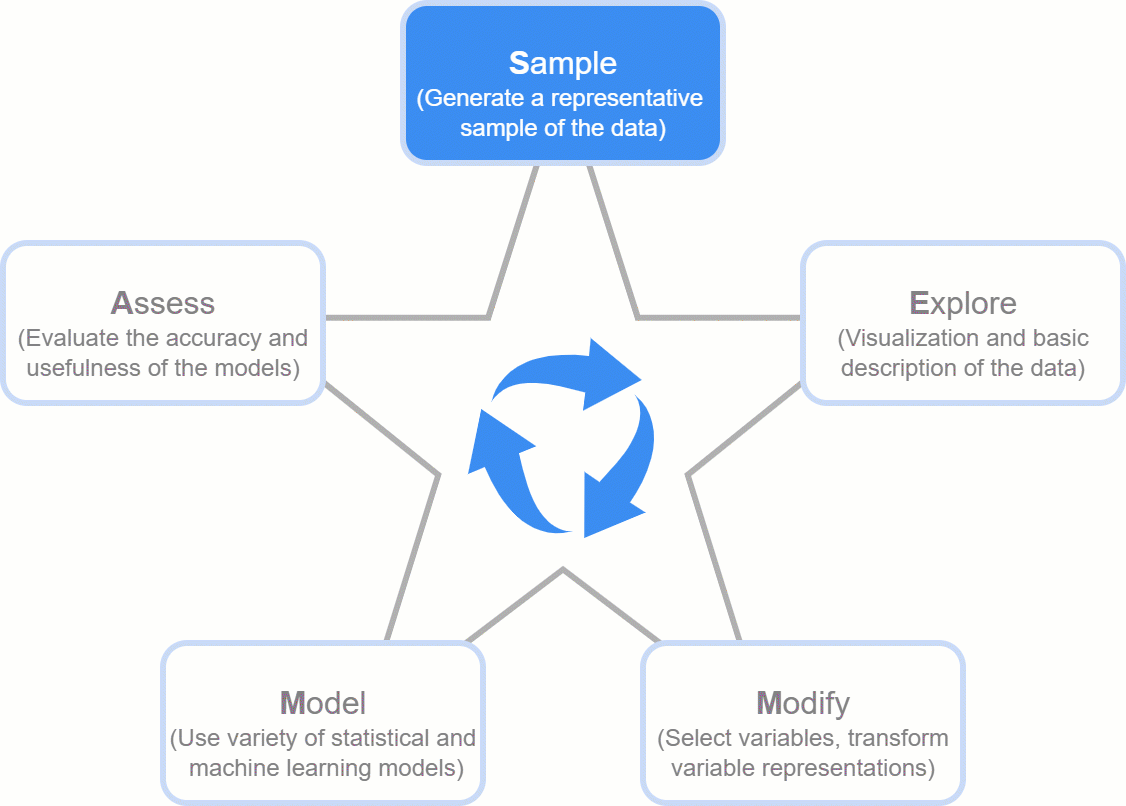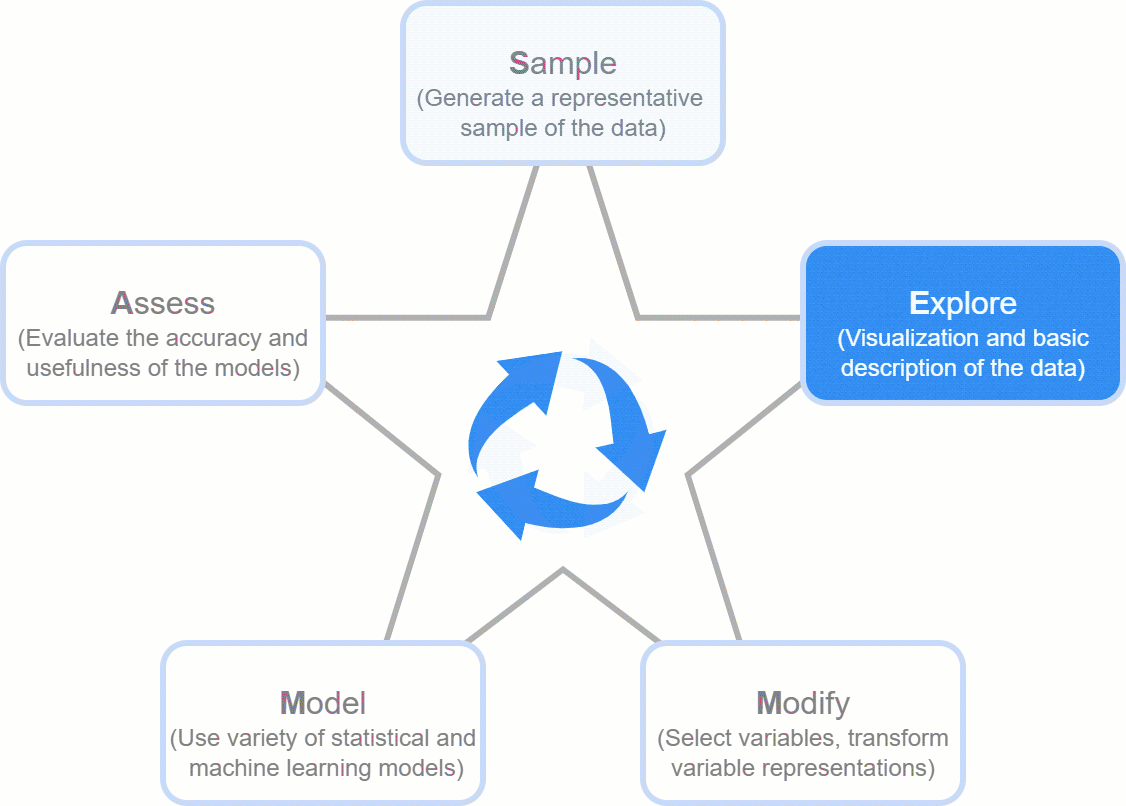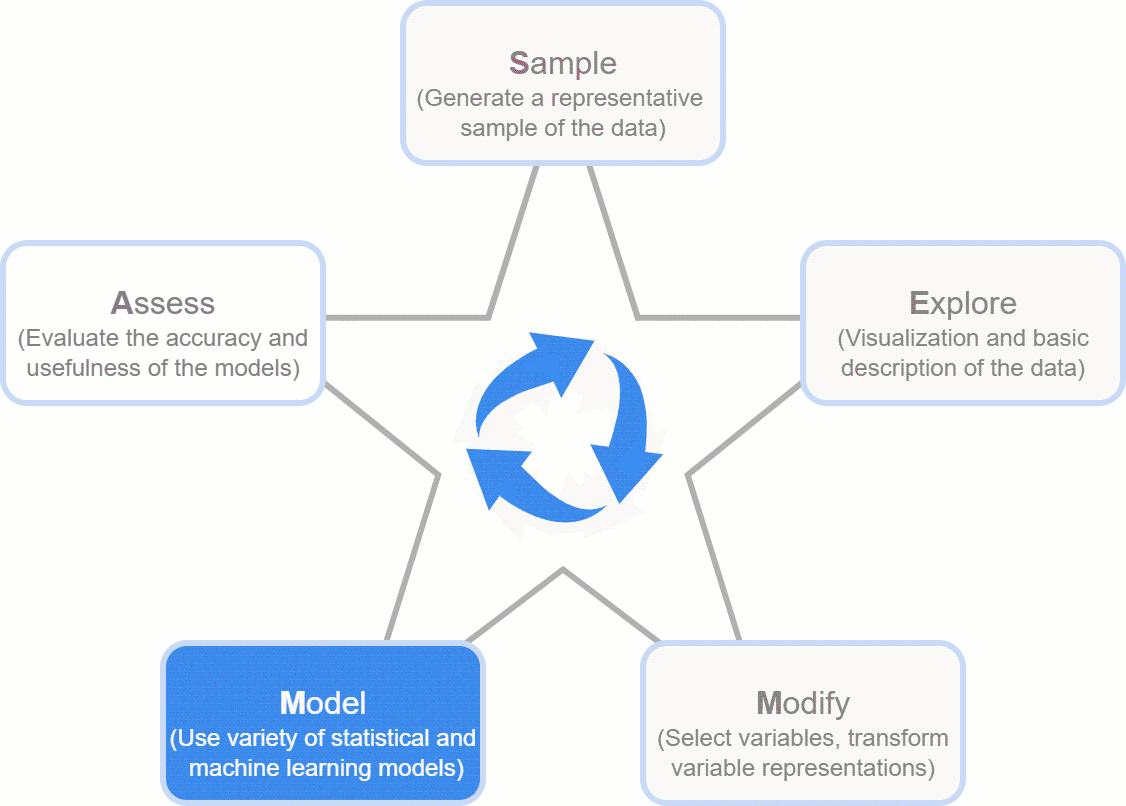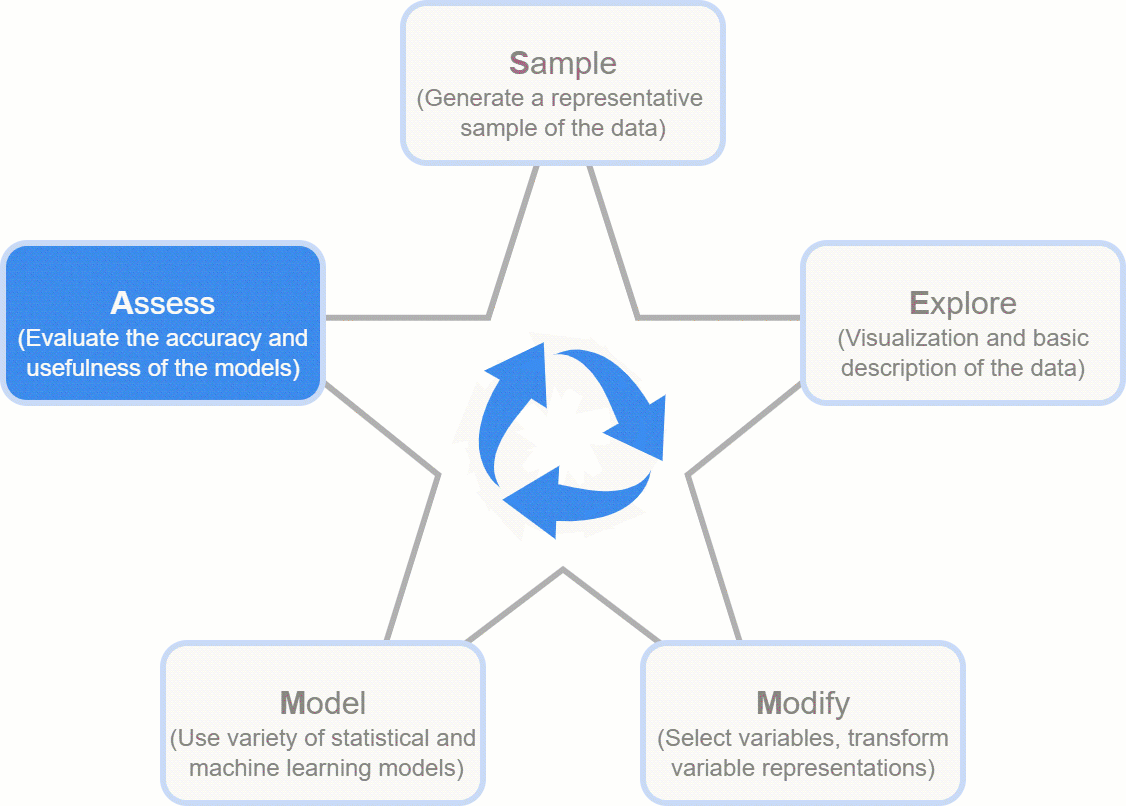
- SEMMA (Sample, Explore, Modify, Model, Assess)
- The Idea: Developed by the SAS Institute, it’s a logical, five-step recipe that guides you from a giant dataset to a working model. It’s less about the free-form discovery of KDD and more about a structured, repeatable workflow for building models.
- The Flow: The name itself is the process!
- Sample: Start with a manageable, representative slice of your data.
- Explore: Get to know your data, visualize it, and find its quirks.
- Modify: Clean and transform the data to get it ready for modeling.
- Model: Build and train your machine learning models.
- Assess: Test your models to see how well they perform and pick the winner.
- The Takeaway: SEMMA is essentially a more focused, user-friendly version of KDD, zeroing in on the core modeling tasks.
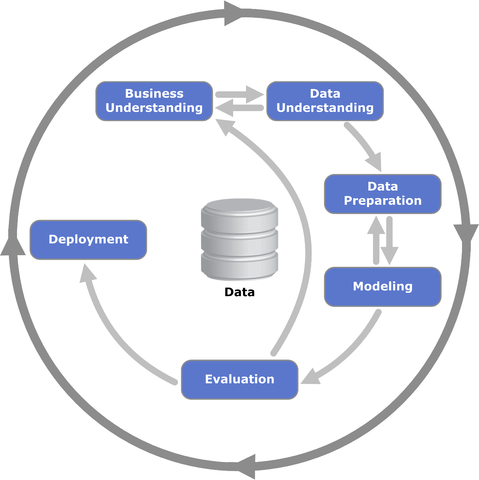
- CRISP-DM (CRoss Industry Standard Process for Data Mining)
- The Idea: CRISP-DM is the undisputed champion of data science frameworks. It’s been the go-to model for over two decades for a reason: it’s flexible, comprehensive, and it puts the business first. Imagine it as a circular journey, where you’re constantly looping back and refining your approach based on what you learn.
- The Flow: It’s a six-phase cycle that looks something like this:
- Business Understanding: This is the starting point and the most crucial phase. What problem are we really trying to solve? What does success look like for the business?
- Data Understanding: Now, let’s look at the data. Do we have what we need? Is it clean? What does it look like?
- Data Preparation: This is where the heavy lifting happens—cleaning, formatting, and engineering features. It often takes up to 70-80% of the project time!
- Modeling: Time to get creative. Build several models and see which ones work best.
- Evaluation: Before you deploy, you rigorously test the model to make sure it meets the business goals defined back in phase one.
- Deployment: The model goes live! But the journey isn’t over. You monitor its performance and gather feedback, which flows right back into the “Business Understanding” phase for the next iteration.
- Pros: It’s incredibly versatile and keeps the project grounded in business reality. Its iterative nature means you can start small and build knowledge as you go.
- Cons: The emphasis on documentation can sometimes slow things down, and some feel it’s not as nimble as more modern, agile approaches, especially for big data projects.
The New Wave: Modern Data Science Lifecycles
As data science has matured, new frameworks have emerged to handle the speed and scale of modern AI projects. These are built for agility, collaboration, and getting models into the real world.
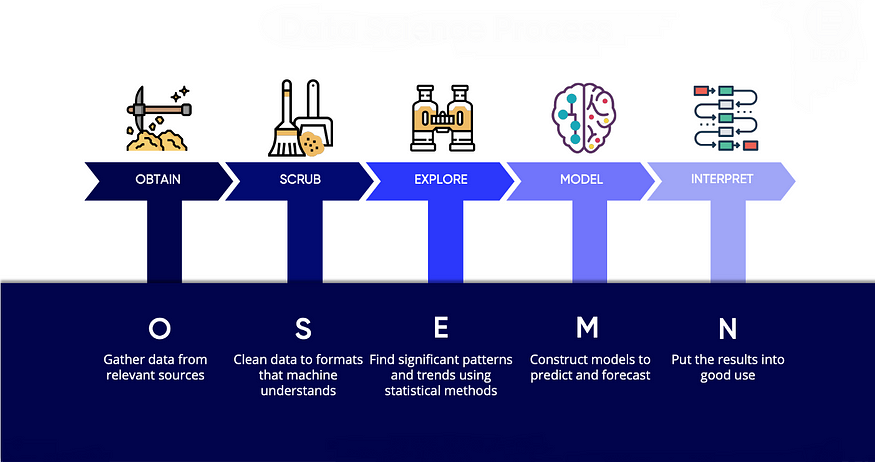
- OSEMN Process Framework
- The Idea: OSEMN (pronounced “awesome”) is less of a rigid process and more of a data scientist’s mantra. It captures the day-to-day reality of a data scientist’s work. If CRISP-DM is the grand strategy, OSEMN is the tactical, on-the-ground checklist.
- The Flow: Again, the name tells the story:
- Obtain: Get the data. This isn’t just about downloading a CSV; it’s about scripting APIs, querying databases, and automating the data flow.
- Scrub: Clean the data. This is the unglamorous but essential work of handling missing values, fixing inconsistencies, and getting rid of noise.
- Explore: This is the fun part! Make plots, run statistical tests, and use your intuition to really understand what the data is telling you.
- Model: Apply machine learning algorithms to the data. The focus is on building effective, predictive models.
- Interpret: This is the crucial last step. What do the results mean? How does the model actually work? It’s about turning predictions into insights.
- Microsoft’s TDSP (Team Data Science Process)
- The Idea: TDSP is Microsoft’s answer to building enterprise-grade AI solutions. It takes the iterative spirit of CRISP-DM and blends it with the discipline of modern software engineering (think Agile and DevOps). It’s designed for teams, providing not just a lifecycle but also a standardized project structure, recommended tools, and even defined team roles.
- The Components: It’s a full-package deal, covering four main areas:
- A data science lifecycle definition.
- A standardized project structure (so everyone knows where to find things).
- Recommended infrastructure and resources.
- Tools and utilities to make the process smoother.
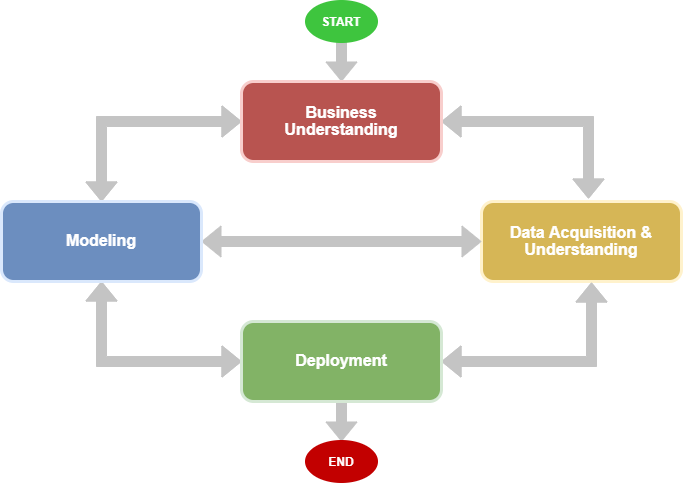
Deep Dive: Microsoft’s Team Data Science Process (TDSP)
If CRISP-DM is the philosophical guide to data science, think of TDSP as the detailed, opinionated instruction manual for building a data science factory. It’s not just about one project; it’s about creating a system for producing high-quality AI products reliably and at scale.
Microsoft forged TDSP in the fires of real-world customer projects. They took the battle-tested, iterative loop of CRISP-DM and fused it with the discipline and collaboration tools of modern software engineering—think Agile, Git, and DevOps. The result is a framework that’s both flexible and structured, designed for teams that need to ship production-ready models.
What makes TDSP special is that it’s a “batteries-included” framework. It doesn’t just tell you what to do; it gives you the tools and structures to do it. Let’s unpack the four key components that make up the TDSP toolkit.
1. The TDSP Lifecycle: A Familiar Journey with a Twist
The TDSP lifecycle will feel familiar to anyone who knows CRISP-DM, like listening to a cover of a classic song. The melody is the same, but the arrangement is new, with a modern, production-focused beat. It’s an iterative cycle designed to guide a project from a business question to a deployed solution.
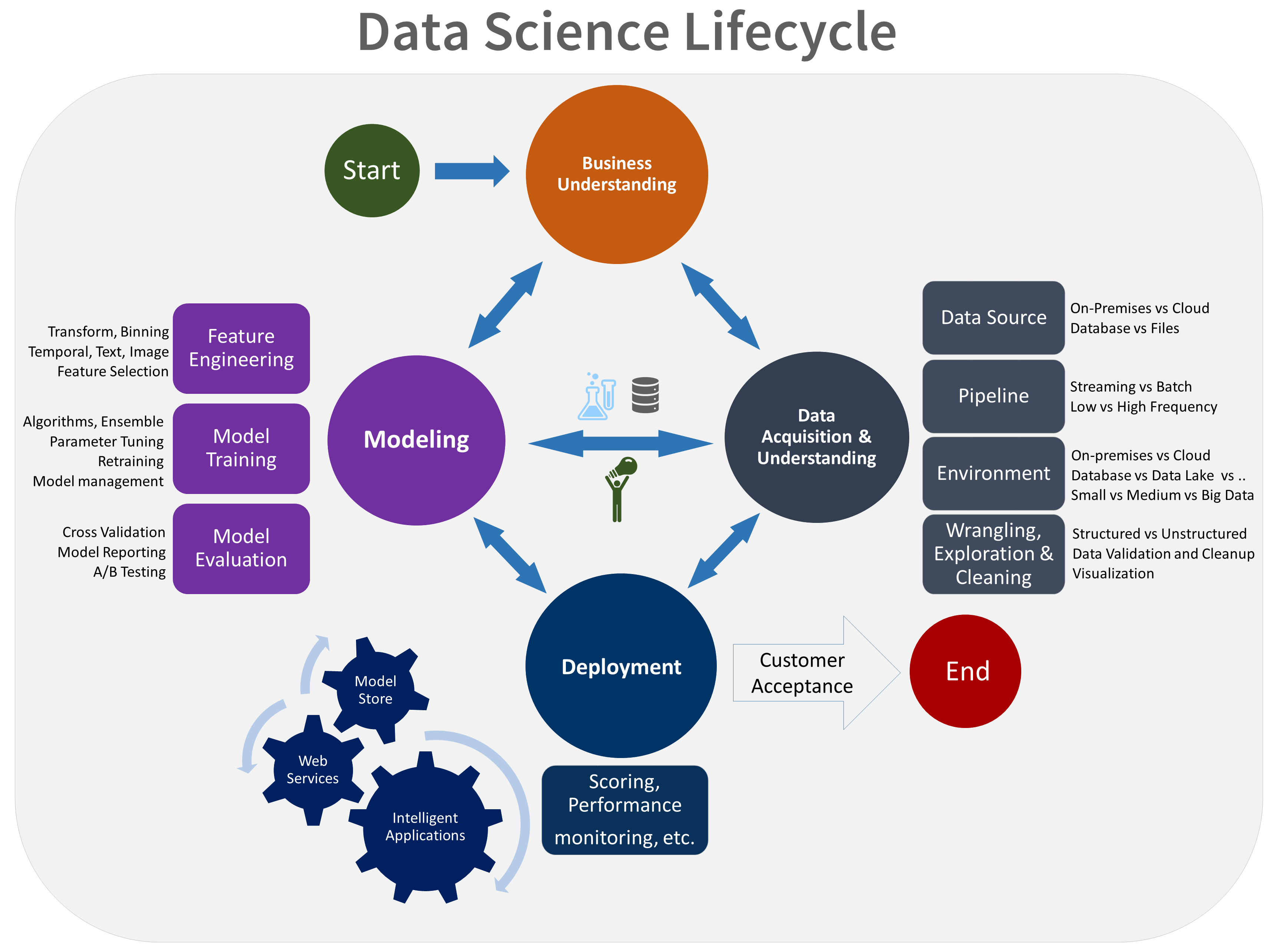
Let’s walk through each stage:
- Business Understanding: This is where it all begins. It’s about sitting down with stakeholders and asking, “What problem are we solving, and how will we know if we’ve succeeded?” The goal is to define clear, unambiguous questions and establish SMART (Specific, Measurable, Achievable, Relevant, Time-bound) success criteria. You’re not just defining a task; you’re defining the finish line.
- Data Acquisition and Understanding: With a clear goal, you go on a data hunt. This stage is about finding the right data to answer your questions. You’ll ingest it, explore it, and check its quality. The key output here is a clean, high-quality dataset and a plan for how to keep it fresh—a data pipeline.
- Modeling: Now for the magic. This is where you perform feature engineering—using your domain knowledge and statistical insights to create the signals that will make your model predictive. Then you build and train multiple models, evaluate them against each other, and select the champion that best solves the business problem. This stage effectively combines the “Modeling” and “Evaluation” phases of CRISP-DM into one focused effort.
- Deployment: A model isn’t useful until it’s in the hands of users. In this stage, you wrap your model in an API and deploy it to a production environment where it can start making predictions in real-time or in batches. This is where the data science product comes to life and starts delivering value.
- Customer Acceptance: This is the final checkpoint and a key differentiator from CRISP-DM. It’s about confirming with the customer that the deployed solution actually meets the goals defined way back in the Business Understanding phase. It also involves the official handover of the project, with documentation and an exit report, so the team that will operate the system knows exactly how it works.
2. The Blueprint: A Standardized Project Structure
TDSP brings order to the chaos of a typical data science project folder. It provides a standardized directory structure and document templates. Why? So that anyone on the team (or even a new person joining a year later) can easily find what they need, from code to documentation.
For example, a typical TDSP project repository might look like this:
project_root/
├── data/
│ ├── raw/
│ ├── processed/
│ └── final/
├── docs/
│ ├── data/
│ │ ├── data_sample.csv
│ │ ├── data_report.md
│ │ └── data_dictionary.md
│ ├── model/
│ │ ├── baseline/
│ │ │ └── baseline_models.md
│ │ ├── model1/
│ │ │ └── model1_results.md
│ │ ├── final_report.md
│ └── project_documents.md
├── notebooks/
│ ├── data_exploration.ipynb
│ ├── modeling.ipynb
│ └── deployment.ipynb
├── src/
│ ├── data_processing/
│ │ └── etl_scripts.py
│ ├── modeling/
│ │ ├── train.py
│ │ └── predict.py
│ └── deployment/
│ └── operationalization.py
└── README.mdThis clear, predictable structure means you don’t waste time hunting for things. You know exactly where to find the raw data, the exploratory notebooks, and the production-ready source code.
All of this is stored in a version control system (VCS) like Git. This is non-negotiable in TDSP. It allows for collaboration, tracking changes, and maintaining a history of the project. By creating a separate repository for each project, teams can work independently and securely. This brings the discipline of software engineering directly into the data science workflow.
3. The Workshop: Infrastructure and Resources
To build great things, you need a great workshop. TDSP provides recommendations for setting up and managing shared infrastructure for analytics and storage. This includes:
- Cloud file systems (like Azure Blob Storage or Amazon S3)
- Databases
- Big data clusters (like Spark)
- Machine learning services (like Azure Machine Learning)
By standardizing the infrastructure, teams can ensure their work is reproducible. A data scientist can write code on their machine, and it will run the same way for their colleague or on the production server. This avoids the classic “it works on my machine” problem and saves a huge amount of time and money.
4. The Power Tools: Utilities for Project Execution
Getting started with a new process can be tough. To make it easier, TDSP provides a set of tools, scripts, and utilities to automate common tasks in the data science lifecycle. Think of these as power tools that speed up your work and ensure consistency.
These tools can help with tasks like:
- Interactive data exploration
- Automated baseline modeling
- Model evaluation and reporting
Microsoft provides a repository of these tools on GitHub that teams can clone and use to jump-start their adoption of TDSP. This practical, hands-on approach is a core part of what makes TDSP so effective.
The Team: Assembling Your AI Crew
Unlike older frameworks, TDSP is explicit about the team. It recognizes that data science is a team sport and defines clear roles and responsibilities. While the specific titles might change, the functions are key:
- Group Manager: The head coach, overseeing the entire data science unit.
- Team Lead: The captain of a specific team of data scientists.
- Project Lead: The quarterback for a single project, managing the day-to-day plays.
- Project Individual Contributor: The players on the field—the Data Scientists, Data Engineers, and Analysts doing the hands-on work.
This structure ensures that everyone knows their role and how they contribute to the team’s success.
Why TDSP Wins (and Where It Might Stumble)
Pros:
- Built for the Real World: It’s agile, iterative, and designed for teams shipping production code.
- Familiar Feel: It uses concepts like Git, sprints, and backlogs, making it an easy transition for anyone with a software engineering background.
- Data Science First: While it borrows from software engineering, it’s fundamentally built for the unique challenges of data science.
- All-Inclusive: It’s a comprehensive package, from lifecycle definition to free templates on GitHub.
Cons:
- Can Feel Rigid: The use of fixed-length sprints can be a culture shock for data scientists accustomed to more research-oriented, exploratory work.
- Overkill for Small Projects: If you’re a solo data scientist working on a one-off analysis, the full TDSP might be more process than you need.
- Learning Curve: Teams new to structured processes may find the initial setup and discipline challenging.
Conclusion: Finding Your Blueprint
Choosing the right data science process is like choosing the right blueprint for a building. You need to consider the scale of your project, the size of your team, and your ultimate goal.
The traditional frameworks like KDD and CRISP-DM laid the foundation, giving us the core principles of a structured approach to finding insights in data. They are the classical architecture that still influences us today.
Modern frameworks like OSEMN and TDSP are the skyscrapers of the data science world. They are built for speed, scale, and collaboration. TDSP, in particular, stands out as a comprehensive, enterprise-ready blueprint for building a successful AI factory. It provides the structure, tools, and team-oriented approach needed to turn the promise of data science into real-world, production-level applications.
Ultimately, the best framework is the one your team will actually use. By understanding these different blueprints, you can pick the right one for your organization and customize it to build your own success story in the world of AI.

Happy is a seasoned ML professional with over 15 years of experience. His expertise spans various domains, including Computer Vision, Natural Language Processing (NLP), and Time Series analysis. He holds a PhD in Machine Learning from IIT Kharagpur and has furthered his research with postdoctoral experience at INRIA-Sophia Antipolis, France. Happy has a proven track record of delivering impactful ML solutions to clients.
Subscribe to our newsletter!