
AI systems are becoming integral to our daily lives. However, the increasing complexity of many AI models, particularly deep learning, has led to the “black box” problem. Understanding how they make decisions and why they arrive at specific conclusions becomes increasingly challenging. This is where Explainable AI (XAI) comes into play.
Explainable AI refers to techniques and methods that make the behavior and decisions of AI systems understandable to humans. The primary goal of XAI is to create a transparent AI that provides clear and interpretable explanations for its outputs, ensuring trust and accountability. XAI focuses on answering questions like:
- Why did the model make this specific prediction?
- What are the most important factors influencing the model’s output?
- How can I understand the model’s overall behavior?
- What changes can I make to the input to get a different outcome?
The Need for Explainability in AI
As AI systems are deployed in critical sectors, the need for transparency becomes paramount. Decision-making processes in areas like healthcare, finance, and law enforcement require not just accurate outcomes but also understandable rationales.
Key Reasons for Explainable AI:
- Trust and Reliability: Users are more likely to trust AI systems when they understand how decisions are made.
- Accountability: In critical applications like healthcare or finance, understanding the rationale behind AI decisions is essential for accountability and error correction.
- Compliance and Regulation: Regulatory frameworks may require explanations for automated decisions.
- Debugging and Improvement: XAI can help identify biases, weaknesses, and errors in AI models, leading to improvements in their performance and reliability.
- Knowledge Discovery: XAI can reveal new insights and relationships within data, potentially leading to scientific discoveries or business innovations.
- Ethical Considerations: Ensuring AI decisions are fair and unbiased necessitates clear explanations.
Key Concepts and Definitions
Before delving deeper, it’s essential to understand some fundamental concepts related to Explainable AI:
- Transparency: The degree to which the internal workings of an AI system are open and clear.
- Interpretability: The extent to which a human can comprehend the cause of a decision.
- Explainability: The ability of an AI system to provide understandable explanations for its decisions.
- Post-hoc Explainability: Techniques applied after model training to provide explanations.
- Intrinsic Explainability: Designing models that are interpretable by nature, such as decision trees.
Types of Explainable AI
Explainable AI encompasses various approaches, each with its own strengths and applications. Broadly, they can be categorized into model-agnostic and model-specific methods.
Model-Agnostic Methods
These methods provide explanations for any machine learning model without requiring access to the model’s internal structure or parameters.
- Pros: Flexibility across different models.
- Cons: May not capture intricate model-specific nuances.
Model-Specific Methods
Tailored explanations that leverage the internal structure of specific models to provide insights.
- Pros: Can offer more detailed and accurate explanations.
- Cons: Limited to specific types of models.
Techniques for Explainability
LIME (Local Interpretable Model-agnostic Explanations)
LIME creates a simplified, interpretable model around a specific prediction to approximate the behavior of the complex model locally. It identifies the features that have the most significant impact on that particular prediction.
- How it Works:
- Purturbs the input and generates predictions locally around the instance being explained.
- Fits a simple, interpretable model (e.g., linear regression) to approximate the behavior.
- Weights the features based on their impact on the prediction.
- Use Cases: Text classification, image recognition.

SHAP (SHapley Additive exPlanations)
SHAP assigns each feature an importance value for a particular prediction by leveraging concepts from cooperative game theory. They explain how each feature contributes to the difference between the actual prediction and the average prediction.
- How it Works:
- Calculates the contribution of each feature by considering all possible feature combinations.
- Provides a unified measure of feature importance.
- Use Cases: Healthcare diagnostics, credit scoring.
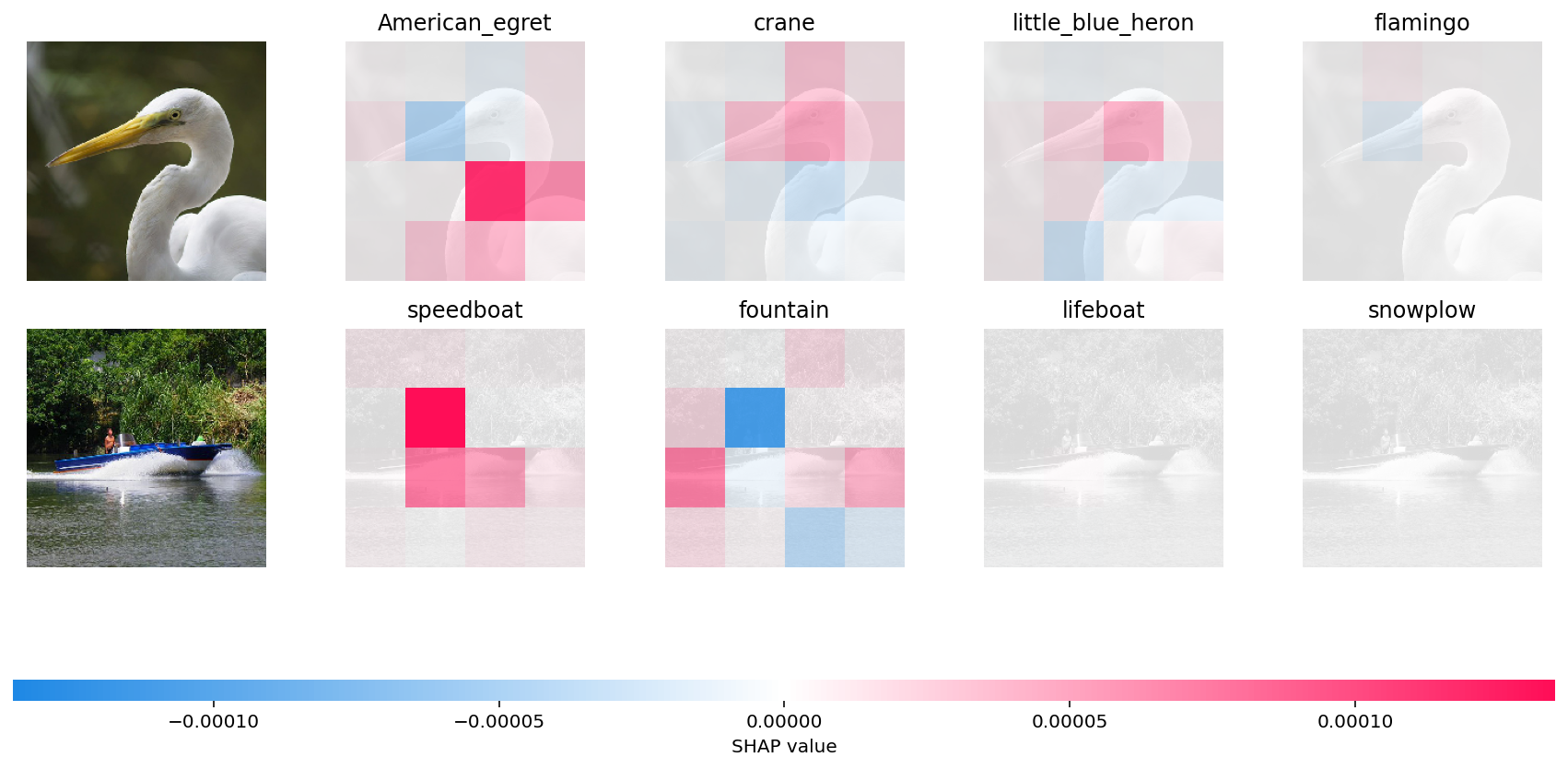
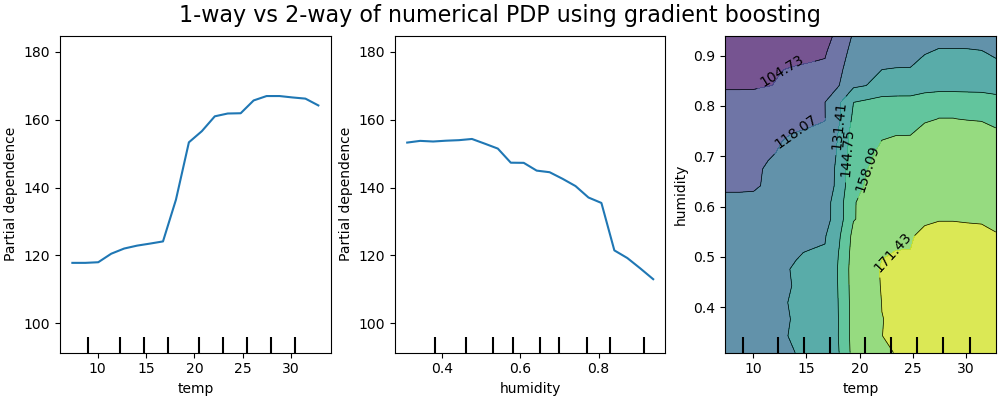
Partial Dependence Plots
These plots show the relationship between a subset of input features and the predicted outcome, averaging out the effects of other variables.
- How it Works:
- Vary one or two features systematically while keeping others constant.
- Plot the average predicted response.
- Use Cases: Understanding feature effects in regression models.
Miscellaneous Techniques
- Feature Importance: Ranking features based on their contribution to model predictions.
- Counterfactual Explanations: Providing inputs that would change the model’s prediction.
- Attention Mechanisms: Highlighting important parts of the input for deep learning models.
- Concept Activation Vectors: Visualizing feature importance in neural networks.
- Layer-Wise Relevance Propagation: Explaining deep learning models by backpropagation.
- Gradient-Based Methods: Analyzing model behavior by examining gradients.
- Rule-Based Explanations: Extracting human-understandable rules from complex models.
- Decision Trees: Hierarchical representation of decision-making processes.
- Anchors: High-precision rules that explain the behavior of complex models.
- Prototype-Based Explanations: Identifying representative instances for model decisions.
- Local Surrogate Models: Approximating complex models with simpler, interpretable models.
Evaluating Explainability
Evaluating the quality of explanations is crucial. Some key criteria include:
- Accuracy: Explanations should be consistent with the actual behavior of the model.
- Fidelity: Explanations should accurately reflect the underlying reasoning of the model.
- Comprehensibility: Explanations should be easy for humans to understand.
- Stability: Explanations should be consistent for similar inputs.
- Trustworthiness: Explanations should inspire trust in the AI system.
Explainable AI has diverse applications across various industries, enhancing the transparency and trustworthiness of AI systems.
Healthcare
In healthcare, AI models assist in diagnosis, treatment planning, and predicting patient outcomes.
- Benefits:
- Clinicians can understand and trust AI recommendations.
- Ensures compliance with medical regulations.
- Enhances patient-doctor communication.
- Example: An AI system recommending treatment plans with explanations based on patient data and medical history.
Finance
AI is extensively used in finance for fraud detection, credit scoring, and algorithmic trading.
- Benefits:
- Transparent decision-making fosters trust among customers.
- Meets regulatory requirements for financial institutions.
- Helps in identifying and mitigating biases in credit scoring.
- Example: A credit scoring model explaining why a loan was approved or denied based on credit history and income.
Autonomous Vehicles
Self-driving cars rely on AI for navigation, obstacle detection, and decision-making.
- Benefits:
- Enhances safety by providing understandable reasons for maneuvers.
- Facilitates troubleshooting and improvement of AI systems.
- Builds public trust in autonomous technology.
- Example: An autonomous vehicle explaining a sudden braking decision due to an unexpected pedestrian.
Challenges in Explainable AI
- Balancing Accuracy and Explainability: Complex models may sacrifice interpretability for performance.
- Complexity of Models: Understanding intricate deep learning models can be challenging.
- User Comprehension: Explanations must be tailored to different stakeholders' levels of expertise.
- Scalability Issues: Generating explanations for large-scale models can be computationally intensive.
- Misinterpretation Risks: Poorly designed explanations can lead to misunderstandings or misuse of AI systems.
Resources

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!



