Tabular data, the backbone of countless scientific fields and industries, has long been dominated by gradient-boosted decision trees. However, TabPFN (Tabular Prior-data Fitted Network) [paper, github] is poised to redefine the landscape of tabular data analysis. This article delves into the key innovations and capabilities of TabPFN, exploring how this foundation model leverages the power of in-context learning to achieve unparalleled performance.
TabPFN (Tabular Prior-data Fitted Network) is a new type of deep learning model designed specifically for tabular data.
The Limitations of Traditional Tabular Data Models
Traditional machine learning models, particularly tree-based methods, have dominated tabular data for over two decades. While effective, these approaches suffer from limitations, such as:
- Poor out-of-distribution predictions: Difficulty generalizing to unseen data.
- Limited knowledge transfer: Challenges in applying knowledge learned from one dataset to another.
- Difficulties in integration with neural networks: Hindering the development of hybrid models.
Enter TabPFN: A Foundation Model for Tabular Data
TabPFN emerges as a transformative solution, addressing the shortcomings of conventional methods. It’s a foundation model trained on millions of synthetic datasets, enabling it to learn a generic learning algorithm applicable to a wide range of real-world datasets.
Key features of TabPFN:
- Trained on millions of synthetic datasets: It learns general problem-solving strategies from diverse, artificially created tables, making it readily applicable to new, real-world data.
- In-Context Learning (ICL): TabPFN utilizes ICL, the same mechanism that powers large language models, to generate a potent tabular prediction algorithm. It makes predictions by considering the entire dataset at once, allowing it to capture complex relationships between rows and columns.
- Superior Performance on Small Datasets: TabPFN demonstrates superior performance compared to state-of-the-art baselines, including gradient-boosted decision trees (e.g., CatBoost, XGBoost) even with extensive tuning, on datasets with up to 10,000 samples and 500 features. “In 2.8 s, TabPFN outperforms an ensemble of the strongest baselines tuned for 4 h in a classification setting.”
- Foundation Model Abilities: Foundation model abilities: Beyond predictions, it can also generate new data, estimate data density, learn reusable data embeddings, and can be fine-tuned for a specific task.
How TabPFN Works
TabPFN employs a unique approach that sets it apart from standard supervised deep learning models:
- Data Generation: A vast corpus of synthetic tabular datasets is generated using structural causal models (SCMs), capturing diverse relationships and data challenges.
- Pre-training: A transformer-based neural network is trained on these synthetic datasets, learning to predict missing target values. This pre-training process equips the model with a versatile learning algorithm.
- A novel two-way attention mechanism (relationships between rows and columns) within the transformer architecture captures relationships between features and samples in a tabular structure. This design allows efficient training and extrapolation to larger tables.
- Real-world Prediction: The pre-trained model is applied to real-world datasets, utilizing ICL to predict labels in a single forward pass.
TabPFN’s architecture
TabPFN’s architecture is specifically designed to effectively utilise the inherent structure of tabular data, departing from traditional transformer models that treat data as a single sequence. Here’s how it achieves this:
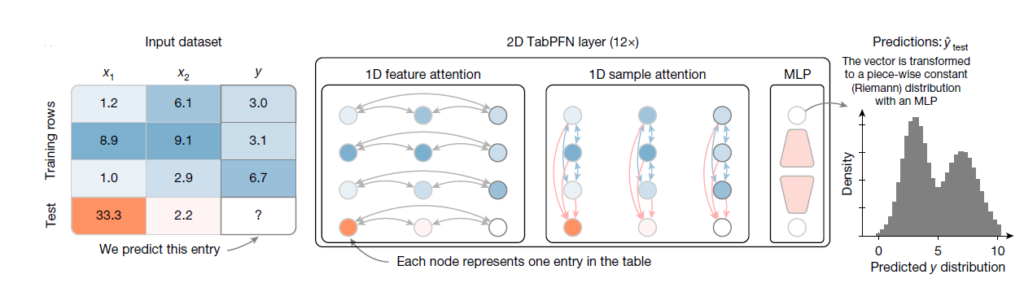
- Two-Dimensional Attention Mechanism: TabPFN employs a novel two-way attention mechanism that operates on both rows (samples) and columns (features) of the table.
- Feature Attention: Each cell in the table attends to all other features within its row (sample). This enables the model to capture relationships between features for a specific data point.
- Sample Attention: Subsequently, each cell attends to the same feature across all other rows (samples). This allows the model to understand the distribution and patterns of a specific feature across the entire dataset.
- Cell-Specific Representations: Instead of treating the input as a single sequence, TabPFN assigns a separate representation to each individual cell in the table. This approach, inspired by previous work on Prior-data Fitted Networks (PFNs), allows for a more granular understanding of the data and its underlying relationships.
- Invariance to Sample and Feature Order: The two-way attention mechanism ensures that the model is invariant to the order of both samples (rows) and features (columns). This is a crucial advantage for tabular data, where the arrangement of rows and columns often doesn’t carry inherent meaning.
TabPFN exhibits a high degree of robustness when dealing with missing data and outliers, which are common challenges in real-world tabular datasets. This robustness is primarily attributed to its unique training process and architectural design as discussed below:
Handling Missing Data:
- Exposure to Missing Values during Training: During the generation of synthetic training datasets, a random fraction of the data is designated as missing using the “missing completely at random” strategy. This means that each value has an independent probability of being masked, regardless of its actual value. By training on datasets with diverse patterns and fractions of missing values, TabPFN learns effective ways to handle them, enabling it to generalise well to real-world datasets with missing data.
- Missing Value Indicator: TabPFN’s architecture incorporates a specific input feature for each cell that indicates whether the corresponding value is missing. This allows the model to explicitly account for missing values during processing.
- Data Imputation: Although not explicitly stated as a built-in feature, the ability to learn from datasets with missing values suggests that TabPFN implicitly learns imputation strategies during its pre-training phase. This allows it to fill in missing values effectively during prediction.
Handling Outliers:
- Outlier Exposure during Training: Similar to missing values, the synthetic data generation process includes the introduction of outliers. This is achieved by multiplying a random subset of values with a random number between 0 and a predefined outlier factor. By training on datasets containing outliers, the model learns to recognise and mitigate their impact on predictions.
- Robust Architecture: The transformer-based architecture of TabPFN contributes to its robustness against outliers. The attention mechanism allows the model to focus on relevant information while downplaying the influence of extreme values that might skew predictions.
- Outlier Removal during Pre-processing: For specific ensemble members or during hyperparameter tuning, an outlier removal step can be employed. This step removes outliers that are more than 12 standard deviations from the mean. This targeted removal of extreme values can further enhance the model’s performance.
TabPFN’s reliance on synthetic data for training significantly enhances its performance and capabilities in several key ways:
- Exposure to Diverse Data Challenges: The synthetic datasets encompass data complexities that mimic real-world data including outliers, missing values, cateorical features, etc.
- Learning a Generic Learning Algorithm: It allows TabPFN to learn a generic learning algorithm rather than just fitting to a specific dataset, thus enabling adaption to a wider range of tasks and data distributions.
- Avoiding Data Limitations: Eliminates the need for collecting and curating massive real-world datasets, which can be time-consuming, expensive, and raise privacy concerns.
TabPFN’s training process diverges significantly from the conventional supervised deep learning paradigm. Here’s a breakdown of the key differences:
| Aspect | Standard Supervised Deep Learning | TabPFN |
|---|---|---|
| Training Across Datasets vs. Within Datasets | Models are trained on a single dataset. Optimises the model’s performance on this specific dataset. | Training occurs across millions of synthetic datasets, each representing a unique prediction task. Model learns a wider range of data distributions and problems. |
| Data Input at Inference Time | At inference time, the trained model is applied to individual test samples to make predictions. | The model receives an entire dataset, including both labelled training and unlabelled test samples, as input at inference time. It performs training and prediction on this dataset in a single forward pass, leveraging in-context learning. |
| Parameter Updates | Model parameters are updated iteratively during training that adjust weights based on errors observed on individual samples or batches. | The model is pre-trained once on the massive collection of synthetic datasets. At inference time, the model applies this learned algorithm to the new dataset in a single pass without further parameter updates. |
| Objective of Training | The objective is to minimise the prediction error on the specific training dataset. This often leads to models that overfit to the training data and struggle to generalise to unseen examples. | The goal is to learn a generic tabular learning algorithm capable of solving diverse prediction tasks. This approach promotes the learning of a more adaptable and generalisable algorithm. |
| Handling of Missing Data and Outliers | Standard models require explicit handling of missing data and outliers during pre-processing or training. | TabPFN is exposed to synthetic datasets with missing values and outliers during training, allowing it to implicitly learn effective strategies for handling these challenges. |
| Data Representation | Data is typically represented as a single sequence or image, depending on the model architecture. | TabPFN represents data in a tabular format, with each cell having its own representation. This cell-specific representation allows the model to capture fine-grained relationships within the data. |
Advantages and Limitations of TabPFN
Advantages:
- Learns a powerful, generalized algorithm: By training on a diverse set of synthetic datasets, TabPFN learns a robust algorithm that can generalize to a wide range of real-world data and tasks. This is in contrast to traditional machine learning models that are trained on a single dataset and may not perform well on unseen data.
- Fast and efficient: TabPFN's pre-training is computationally intensive, but it's done only once. Once pre-trained, the model can make predictions on new datasets in a single forward pass, which is significantly faster than training traditional models from scratch.
- Robust to data challenges: The use of synthetic data allows the model to be exposed to and learn from a variety of data complexities, making it more robust to challenges like uninformative features, outliers, missing values, and categorical features.
- No need for large real-world datasets: The reliance on synthetic data eliminates the need for collecting and curating large, real-world datasets, which can be time-consuming and expensive.
- Interpretability: Supports SHAP (Shapley Additive Explanations), providing insights into feature importance and contributing to model transparency.
- Foundation Model Capabilities: Facilitates data generation, density estimation, reusable embeddings, and fine-tuning, extending its utility beyond prediction tasks.
Limitations:
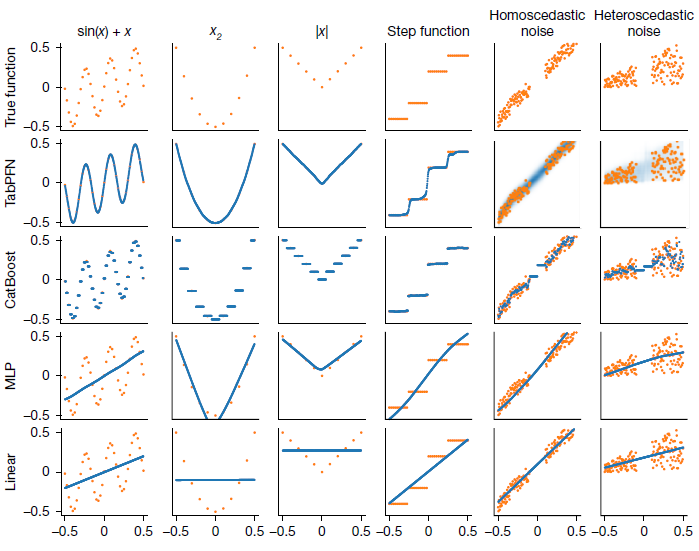
- Scalability: Currently, TabPFN has been primarily evaluated on datasets with up to 10,000 samples and 500 features. While efficient for small to medium datasets, scalability to very large datasets requires further research.
- Inference Speed: Although TabPFN trains significantly faster than traditional methods, it's not optimised for real-time inference. For a dataset with 10,000 rows and 10 columns, TabPFN requires 0.2 seconds to predict a single sample (0.6 seconds without a GPU). In comparison, CatBoost, with default settings, achieves the same in 0.0002 seconds.
- Memory Usage: Memory requirements scale linearly with dataset size, potentially limiting applicability to extremely large datasets.
Using TabPFN
TabPFN is designed to be user-friendly and readily integrable into data science workflows. Here's a general guide:
- Data Preparation: Handles raw data effectively with minimal pre-processing. Automatic handling of missing values, encoding of categorical variables, and feature normalization simplify data preparation.
- Hyperparameter Tuning: Delivers strong performance out of the box. Further optimization can be achieved through hyperparameter optimization or post hoc ensembling techniques.
- When to Use: Ideal for small to medium-sized datasets (up to 10,000 samples and 500 features). For larger or highly non-smooth regression datasets, traditional methods might be more suitable.
Future Directions
TabPFN has the potential to reshape tabular data analysis across diverse domains. Future research directions include:
- Scaling to larger datasets
- Handling data drift
- Expanding fine-tuning capabilities
- Exploring theoretical foundations
- Developing specialised priors for specific data types (e.g., time series, multi-modal data)
Closing Thoughts
TabPFN represents a paradigm shift in tabular data modelling, harnessing the power of ICL to outperform conventional approaches. Its efficiency, robustness, interpretability, and foundation model capabilities mark a significant advancement, paving the way for accelerated scientific discovery and enhanced decision-making across various fields.
Resources
- Hollmann et al. (2025). "Accurate predictions on small data with a tabular foundation model"

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!