BERT (Bidirectional Encoder Representations from Transformers), introduced by Google in 2018, allows for powerful contextual understanding of text, significantly impacting a wide range of NLP applications.
This article explores what BERT is, how it works, its architecture, applications, advantages, limitations, and future developments in the field of NLP.
The Background of NLP Models
Before delving into BERT, it’s essential to understand the context of NLP prior to its introduction.
- Prior to BERT, most models (including RNN models) processed language in a unidirectional manner—either left-to-right or right-to-left. The limitation of unidirectionality meant that prior contexts were not fully utilized when making predictions or generating representations.
- The introduction of the Transformer laid the groundwork for BERT. The Transformer model consists of self-attention mechanisms that can process words in relation to one another, irrespective of their sequence. It enables the model to weigh the influence of different words in a sentence and to understand context more comprehensively.
The Need for a Bidirectional Approach
One of the critical innovations that BERT introduced was bidirectionality. Unlike previous models that processed text uniformly in one direction, BERT employs a bidirectional training approach. This means that during training, BERT considers the entire context of a word simultaneously from both the left and the right, capturing a deeper semantic understanding, regardless of the word order.
The BERT Architecture
The BERT architecture is built on the Encoder stack of the Transformer model. Here’s a closer look at its components:
- Input Representation: BERT uses a sophisticated input representation that combines:
- Token embeddings: Representing individual tokens or words.
- Segment embeddings: Distinguishing between multiple sentences (e.g., sentence A and sentence B).
- Position embeddings: Encoding the positional information of each token in the sequence.
- Self-attention Mechanism: The self-attention mechanism allows BERT to evaluate the relationships between all words in an input sequence, giving it a contextualized representation. Each token emulates the influence of others and creates a rich semantic mosaic.
- Multi-layered Architecture: BERT often employs multiple layers (12 for BERT Base and 24 for BERT Large). Each layer consists of self-attention and feed-forward networks that refine the representations at each step while incorporating information from the entire sequence.
- Output Layer: For specific tasks, BERT uses different types of output layers:
- For classification tasks, a softmax layer follows the hidden state of the [CLS] token.
- For token-level tasks (like named entity recognition), the output corresponds to every token in the input sequence.
Training BERT
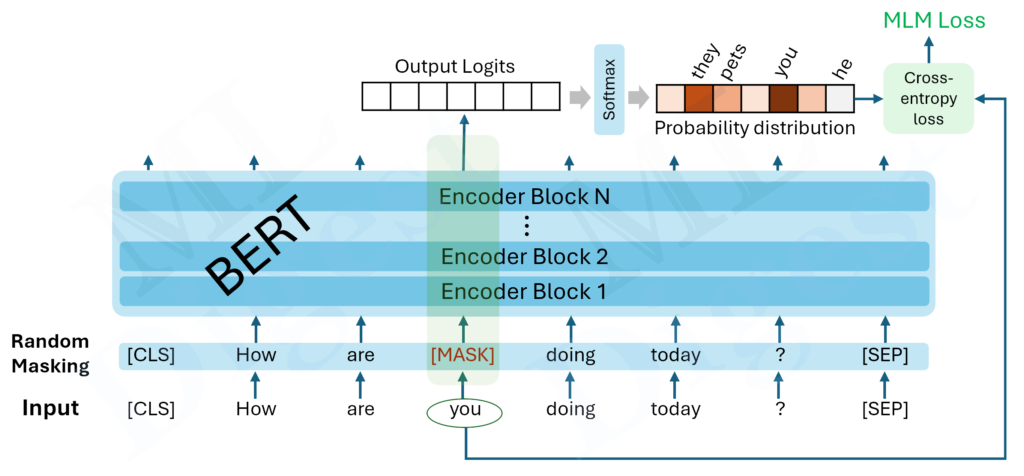


BERT is pre-trained on a massive text corpus (the Wikipedia and BookCorpus datasets). The training process can be broken down as follows:
- Tokenization: Text is first tokenized using WordPiece tokenization, which breaks down words into subword units. This is particularly helpful for handling out-of-vocabulary words.
- Embedding Representation: Each token is represented as a combination of: Token embeddings, Segment embeddings, and Positional embeddings.
- Pre-training: BERT is primarily pre-trained using two tasks:
- Masked Language Model (MLM): Unlike traditional language models that predict the next word in a sequence, MLM randomly masks some words in the input and predicts them based on their surrounding context. For instance, in the sentence “The cat [MASK] on the mat,” BERT attempts to predict “sat” based on the context provided by the other words.
- Next Sentence Prediction (NSP): In this task, BERT learns to predict whether a given sentence follows another one in a coherent manner. For example, it assesses the relationship between two sentences to determine if the second logically follows the first.
- Fine-tuning: After pre-training, BERT can be fine-tuned for specific tasks such as sentiment analysis, named entity recognition, or question answering by adding task-specific layers on top of the pre-trained BERT model.
Variants of BERT
BERT’s open-source nature has fostered numerous variations and improvements. Some notable examples include:
- RoBERTa (Robustly Optimized BERT Approach): Developed by Meta and Washington University, RoBERTa focuses on optimizing the pretraining process. It trains the model on a larger dataset with longer sequences and removes the next sentence prediction task. RoBERTa trains on a dataset ten times larger than the original BERT and employing dynamic masking instead of static masking. Dynamic masking involves duplicating training data and masking it ten times, each with a different masking strategy.
- DistilBERT: Recognizing the resource demands of LLMs, DistilBERT aims to create a more accessible version of BERT. It focuses on reducing size, increasing speed, and lowering computational cost. Based on the original BERT architecture, DistilBERT uses knowledge distillation during pre-training to achieve a 40% size reduction while retaining 97% of BERT’s language understanding capabilities and achieving a 60% speed increase.
- ALBERT (A Lite BERT): ALBERT was designed to enhance the efficiency of BERTlarge during pre-training. It introduces parameter reduction techniques like factorized embedding parameterization and cross-layer parameter sharing. These methods significantly reduce the number of parameters, leading to improved training speed and memory efficiency
- TinyBERT: As the name suggests, TinyBERT aims to create an extremely small yet effective BERT model. It employs a two-stage learning framework involving knowledge distillation and transfer learning. TinyBERT is significantly smaller and faster than BERT, making it suitable for mobile and embedded applications.
Limitations of BERT
While BERT is powerful, it does have some limitations:
- Compute Intensity: BERT’s architecture and training demands significant computational power, including large memory and processing requirements, which can be a barrier for smaller organizations or personal projects.
- Contextual Ambiguity: Although BERT captures context, it might still struggle with deeply nuanced contexts or sarcasm. It doesn’t possess real-world knowledge beyond its training corpus.
- Not Trained for Sequential Tasks: Despite its bidirectional nature, BERT’s training does not address sequential dependencies that might be important in longer text spans or sequences.
Closing Thoughts
By effectively capturing nuanced meanings, incorporating bidirectional context, and enabling transfer learning, BERT has demonstrated its capacity to significantly improve the performance of many NLP tasks. Despite its limitations, the journey of BERT underscores a pivotal point in understanding and working with human language computationally.
Since its release, the NLP community has seen several advancements building on BERT, such as RoBERTa, DistilBERT, and ALBERT, which focus on improving efficiency, reducing biases, or enhancing performance.
Resources
- Vaswani, A., et al. (2017). Attention is all you need.
- Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Medium post

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!