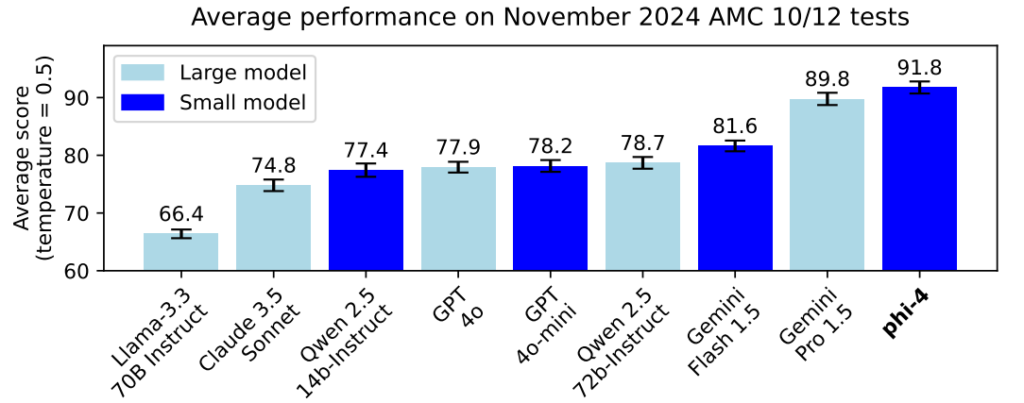
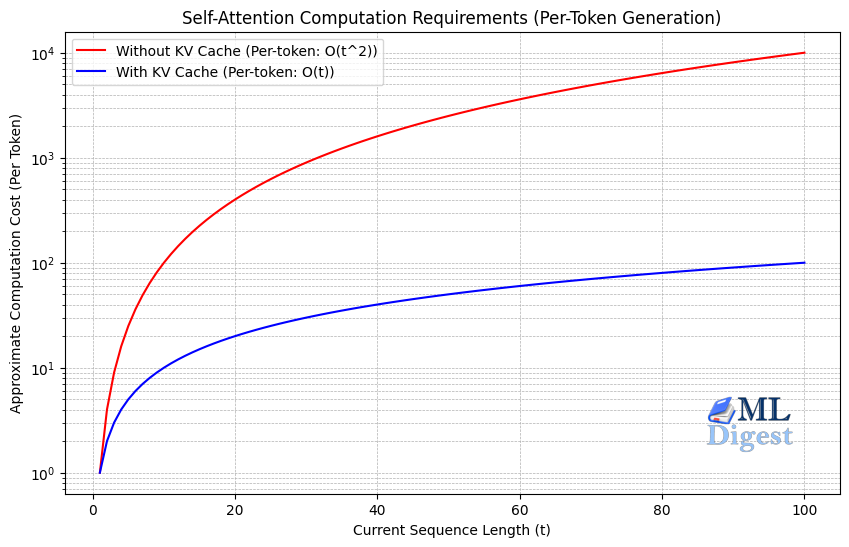
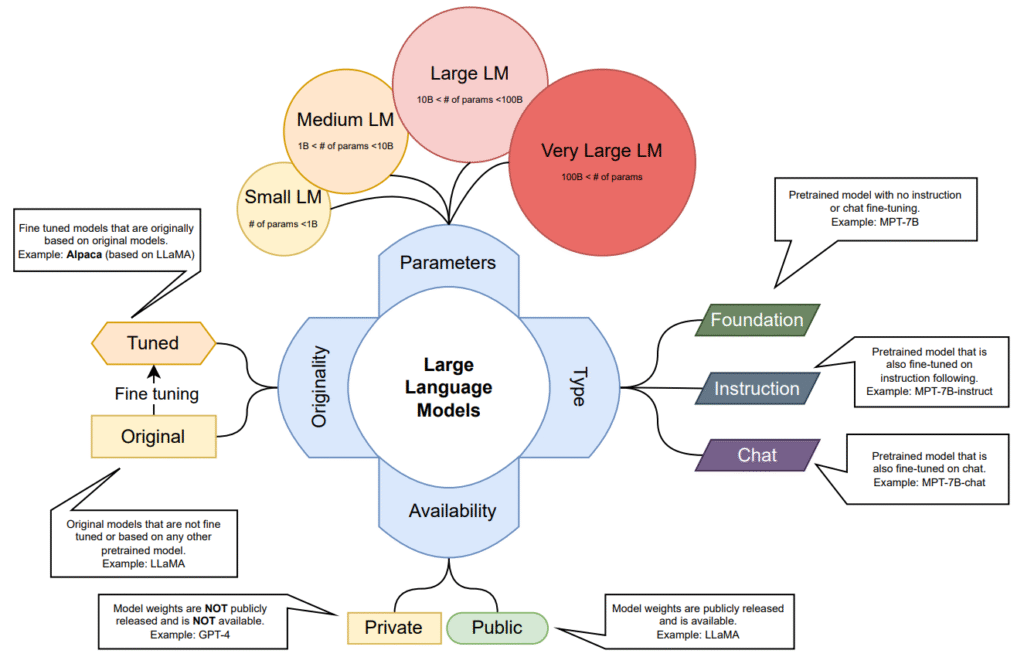
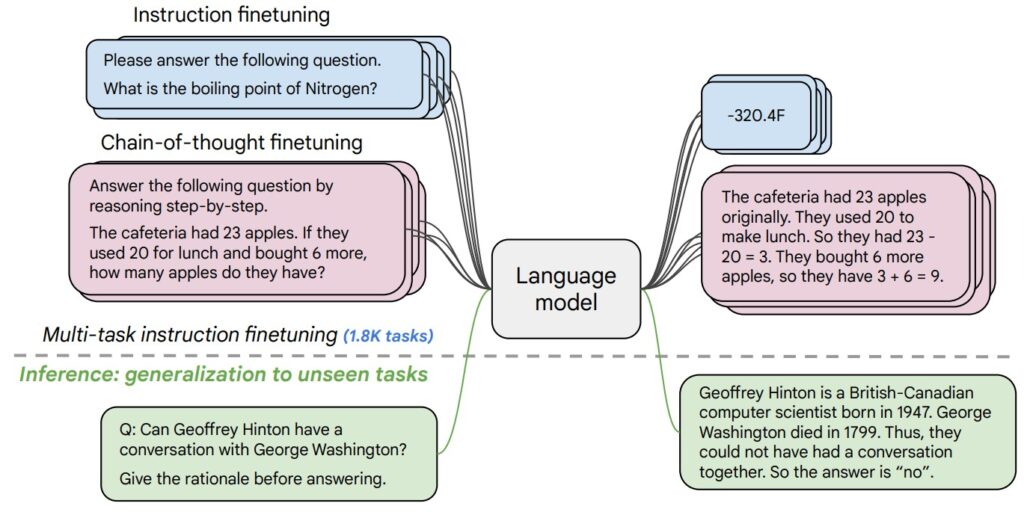
Large Language Models (LLMs) offer immense potential, but they also come with several challenges:
Technical Challenges
Accuracy and Factuality:
- Hallucinations: LLMs can generate plausible-sounding but incorrect or nonsensical information, especially when prompted with ambiguous or misleading queries.
- Factual Inaccuracies: Models may sometimes produce factually incorrect responses, particularly when dealing with specific details or recent events.
Bias and Fairness:
- Data Bias: LLMs trained on biased data can perpetuate and amplify societal biases in their outputs, leading to unfair or discriminatory results.
- Algorithmic Bias: The algorithms used to train and deploy LLMs can introduce biases, even if the training data is unbiased.
Control and Interpretability:
- Lack of Transparency: LLMs are often complex “black boxes,” making it difficult to understand how they arrive at their outputs and identify potential errors or biases.
- Controllability: It can be challenging to control the specific content or style of the generated text, leading to unintended consequences.
Resource Requirements:
- Computational Cost: Training and deploying LLMs requires significant computational resources, making them expensive and inaccessible to many organizations.
- Data Requirements: LLMs need large amounts of high-quality data to train effectively, which can be challenging to acquire and curate.
Other Technical Challenges
- Performance in Specialized Domains:
They may lack domain-specific expertise and provide less accurate responses for niche topics without fine-tuning. - Context Understanding:
Struggling with nuanced context, sarcasm, or ambiguity, leading to incorrect or irrelevant outputs. - Memory:
LLMs lack persistent memory across sessions, which hinders continuity in applications like chatbots or collaborative tools.
Ethical Considerations:
- Misinformation and Disinformation: LLMs can be used to generate misleading or false information, potentially harming individuals and society.
- Privacy Concerns: LLMs may inadvertently expose sensitive information or personal data if trained on datasets that contain such information.
- Toxic Content:
Without proper safeguards, LLMs can produce offensive or harmful content. - Misuse:
Potential for misuse in generating spam, deepfakes, phishing scams, and other malicious activities.
Operational Challenges
- Latency and Speed:
Ensuring low-latency response times for real-time applications, especially with large models, is challenging. - Cost of Inference:
Running large-scale models for end-user applications incurs significant operational costs. - Deployment Complexity:
Scaling across diverse platforms and integrating with existing software systems require advanced engineering.
Security Challenges
- Adversarial Attacks:
Vulnerability to attacks where inputs are deliberately crafted to exploit or fool the model. - Privacy Issues:
Risk of LLMs inadvertently revealing sensitive or personal information present in their training data.
Environmental Impact
- Energy Consumption:
Training and deploying LLMs contribute to high carbon emissions, raising concerns about sustainability.
Addressing these challenges is crucial for responsible and effective use of LLMs.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!