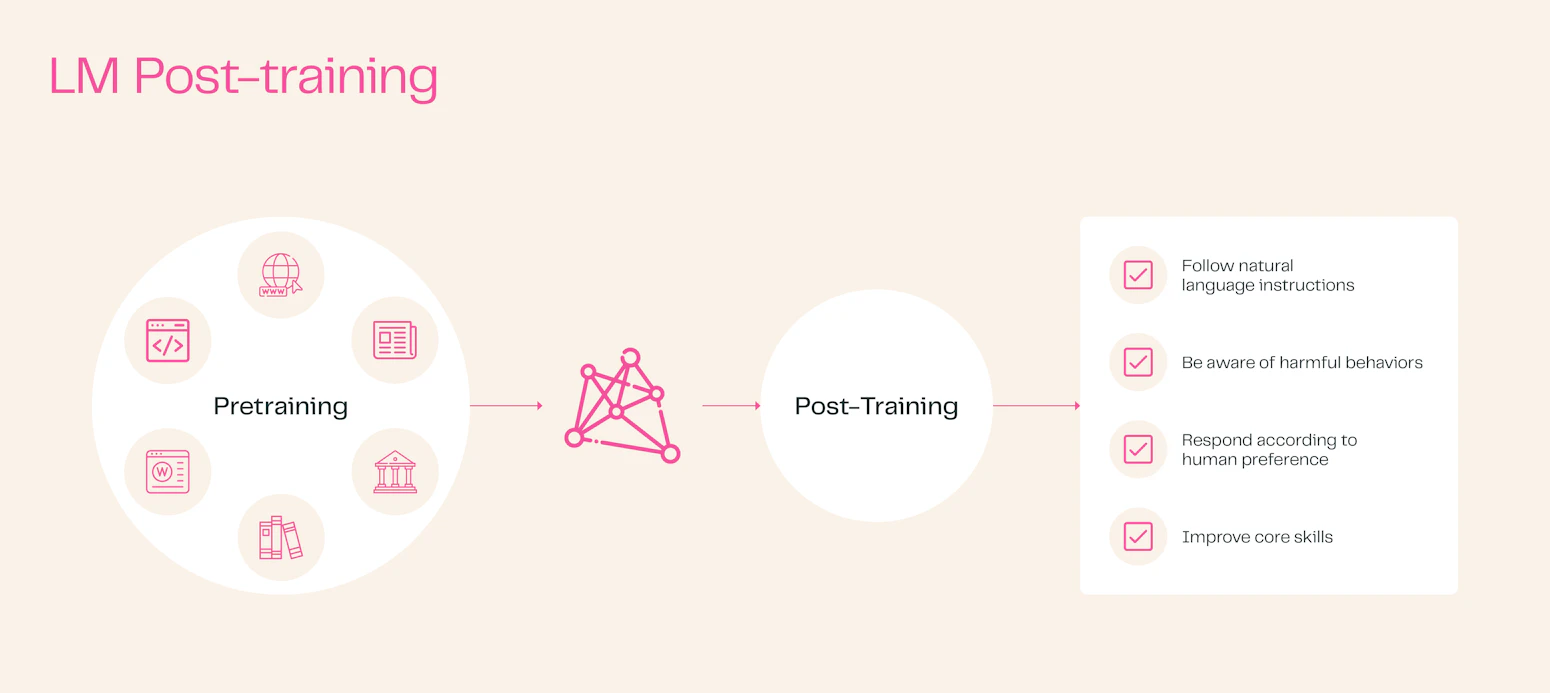
Tulu 3, developed by the Allen Institute for AI, represents a significant advancement in open language model post-training. It offers researchers, developers, and AI practitioners access to frontier-model post-training capabilities comparable to proprietary models such as GPT, Claude, and Gemini. The project pushes the boundaries of research in post-training and focuses on closing the performance gap between open and closed fine-tuning recipes.
What Makes Tulu 3 Different?
The Tulu 3 project is not just a model, but a comprehensive suite of resources, including:
- Open-source models: Tulu 3 offers various sizes of pre-trained models (8B and 70B) with checkpoints available at different training stages.
- Open data: Tulu 3 provides access to the datasets used for training, enabling researchers to experiment with different data mixes and recipes.
- Training code and infrastructure: The project releases code and infrastructure details, facilitating the replication of results and the adaptation of Tulu 3 to new use cases.
- Evaluation framework: A comprehensive evaluation framework helps developers assess their models and ensures reproducibility of evaluations.
Key Innovations in Tulu 3
- Novel post-training recipe: Tulu 3 introduces a novel recipe better suited for open-source fine-tuning, enabling the achievement of performance levels surpassing Meta’s instruction versions for Llama 3.1 8B and 70B.
- Scaling preference data: Tulu 3 tackles the limitations of the open community’s reliance on small preference datasets by scaling its pipelines to produce effective datasets with over 300k prompts.
- Reinforcement learning with verifiable rewards (RLVR): This novel method uses reinforcement learning without a reward model to boost specific skills, further enhancing Tulu 3’s capabilities.

Tülu 3’s Multi-Stage Post-Training Methodology
Tulu 3 model training involves a four-stage post-training process on top of pretrained language models:
- Data Curation: A variety of prompts are curated for allocation across multiple stages of optimization. New synthetic prompts are created or, when available, prompts from existing datasets are sourced to target specific capabilities. Care is taken to ensure that prompts are not contaminated with the evaluation suite.
- Supervised fine-tuning (SFT): Fine-tuning the model on a massive dataset of curated prompts targeting core skills such as reasoning, math, coding, instruction following, and safety.
- Preference fine-tuning (PreFT): Training the model to align with human preferences by using synthetic preference data generated from comparing Tulu 3 SFT completions against outputs from other language models.
- Reinforcement learning with verifiable rewards (RLVR): Enhancing specific skills with verifiable answers through a novel RL objective. Rigorous evaluation of the models at each stage using a comprehensive suite of benchmarks and a standardized evaluation framework.
Details on the four-stage post-training process
1. Data Curation
The foundation of Tülu 3’s success lies in the meticulous curation of its training data. This process involves:
- Identifying Core Skills: Tülu 3 focuses on enhancing a range of core skills, including knowledge recall, reasoning, mathematics, coding, instruction following, general chat, and safety.
- Sourcing Prompts: Prompts, which are diverse ways users interact with models, are sourced from existing public datasets and supplemented with synthetically generated prompts to target specific skills.
- Decontamination: The collected prompts are thoroughly decontaminated against the Tülu 3 evaluation suite to prevent data leakage and ensure fair evaluation of the models.
2. Supervised Fine-tuning (SFT)
In this stage, the pre-trained language model is fine-tuned using a massive dataset of carefully curated prompts and their corresponding completions.
- Data Mixing: A key challenge in SFT is balancing the proportions of datasets representing different skills. Tülu 3 tackles this by experimenting with various data mixtures to optimize performance across all core skills.
- Training: The model is trained on the selected data mix using optimized hyperparameters.
- Evaluation: The SFT model’s performance is rigorously evaluated using the Tülu 3 development evaluation suite to ensure improvements in the targeted skills.
3. Preference Tuning (PreFT)
Preference tuning, specifically Direct Preference Optimization (DPO), aligns the model with human preferences.
- Generating Preference Data: Tülu 3 generates preference data from both on-policy (Tülu 3 suite) and off-policy models. This involves creating (preferred, rejected) pairs of model responses for selected prompts.
- Data Scaling: Tülu 3 addresses the open community’s dependence on small preference datasets by scaling its pipelines to generate effective datasets exceeding 300k prompts.
- Training: The SFT model is further fine-tuned using the curated preference data and optimized hyperparameters.
4. Reinforcement Learning with Verifiable Rewards (RLVR)
This novel stage employs reinforcement learning without a reward model to enhance skills with verifiable answers, like math and precise instruction following.
- Verification Function: Instead of a reward model, RLVR uses a verification function that provides a reward only if the model’s output is verified as correct.
- Training: The model is trained using PPO on tasks with verifiable outcomes, leveraging a robust and scalable infrastructure.
- Evaluation: The performance of the RLVR-trained model is assessed on the Tülu 3 evaluation suite to measure its effectiveness in improving specific skills.
Impact of Tulu 3
Tulu 3 has achieved remarkable performance, surpassing state-of-the-art post-trained open-weight models like Llama 3.1 Instruct, Qwen 2.5 Instruct, and Mistral-Instruct. Tulu 3 70B even matches the performance of closed models like Claude 3.5 Haiku and GPT-4o mini. These results highlight the effectiveness of the Tulu 3 recipe and its contribution to closing the gap between open and closed post-training methods.
The Future of Tulu
The developers of Tulu 3 acknowledge areas for future development, including:
- Long context and multi-turn capabilities: Focusing on longer, more complex conversations, a key aspect of real-world language use.
- Multilinguality: Expanding Tulu 3’s capabilities beyond English to support a wider range of languages.
- Tool use and agents: Integrating Tulu 3 into systems where it can interact with tools and act as part of a larger agent framework, furthering its reasoning and problem-solving abilities.
Conclusion
Tulu 3 signifies a significant milestone in open language model post-training, empowering the community to explore new frontiers in AI development. The project’s commitment to open-source principles, its innovative recipe, and its robust evaluation framework contribute to a more transparent and accessible AI landscape. By democratizing access to state-of-the-art post-training techniques, Tulu 3 paves the way for groundbreaking research and applications in diverse domains.

Silpa brings 5 years of experience in working on diverse ML projects, specializing in designing end-to-end ML systems tailored for real-time applications. Her background in statistics (Bachelor of Technology) provides a strong foundation for her work in the field. Silpa is also the driving force behind the development of the content you find on this site.
Subscribe to our newsletter!