
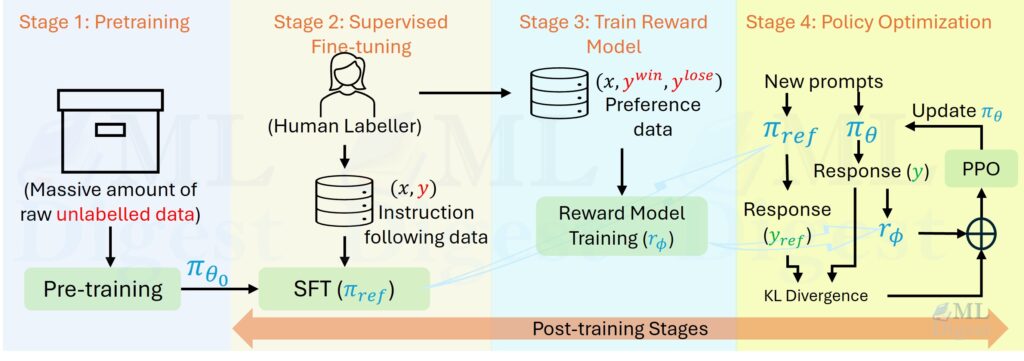
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a post-training recipe for turning a broadly capable language model into a more useful assistant. In practice, it […]
Reinforcement Learning with Human Feedback (RLHF) Read More »
RLHF is a post-training recipe for turning a broadly capable language model into a more useful assistant. In practice, it […]
Reinforcement Learning with Human Feedback (RLHF) Read More »
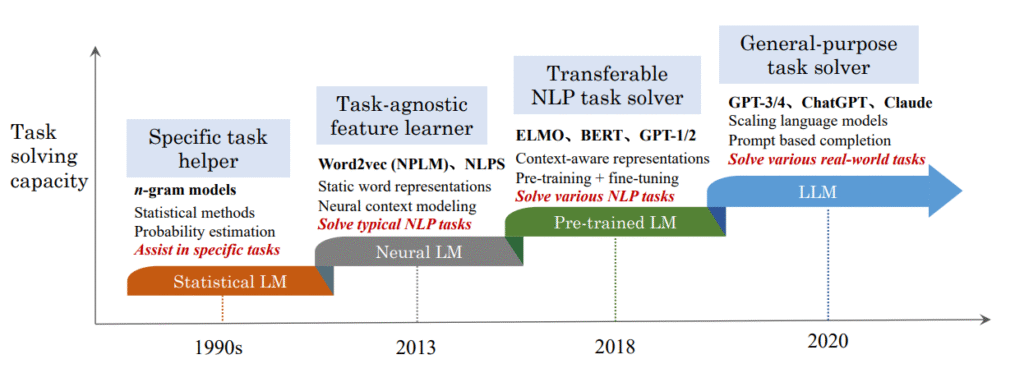
Introduction: The Quest to Understand Language Imagine a machine that could read, understand, and write text just like a human.
How Language Model Architectures Have Evolved Over Time Read More »
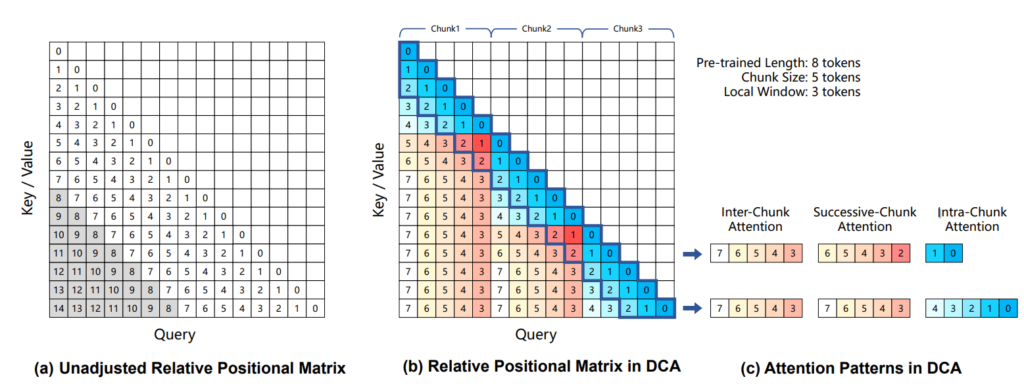
The Qwen2.5-1M series are the first open-source Qwen models capable of processing up to 1 million tokens. This leap in
Qwen2.5-1M: Million-Token Context Language Model Read More »

DeepSeek-R1 represents a significant advancement in the field of LLMs, particularly in enhancing reasoning capabilities through reinforcement learning (RL). This
DeepSeek-R1: How Reinforcement Learning is Driving LLM Innovation Read More »